









看到西瓜书上有些东西写的不是特别清楚,结合李航的《统计学习方法》,把软间隔与正则化知识点重新整理了一下。
先给出支持向量机的基本形式:
min
w
,
b
1
2
∥
w
∥
2
s
.
t
.
 
y
i
(
w
T
x
i
+
b
)
≥
1
,
 
i
=
1
,
2
,
.
.
.
,
m
\begin{aligned} &\min \limits_{w,b} \frac{1}{2} \left\|w\right\|^2\\s.t.\, &y_i(w^Tx_i+b)\ge 1,\:i=1,2,...,m \end{aligned}
s.t.w,bmin21∥w∥2yi(wTxi+b)≥1,i=1,2,...,m
之前支持向量机的普通形式都是假设样本点是线性可分的,也就是说存在一个超平面能将不同类的样本完全划分开,而现实世界中往往很难达到这种要求。我们的解决办法是允许支持向量机在一些样本上出错。由此引出了“软间隔”的概念。如下图:也就意味着某些样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)不能满足函数间隔大于等于1的约束条件,有些正样本的点会跑到负样本的区间,有些负样本的会跑到正样本的区间范围。
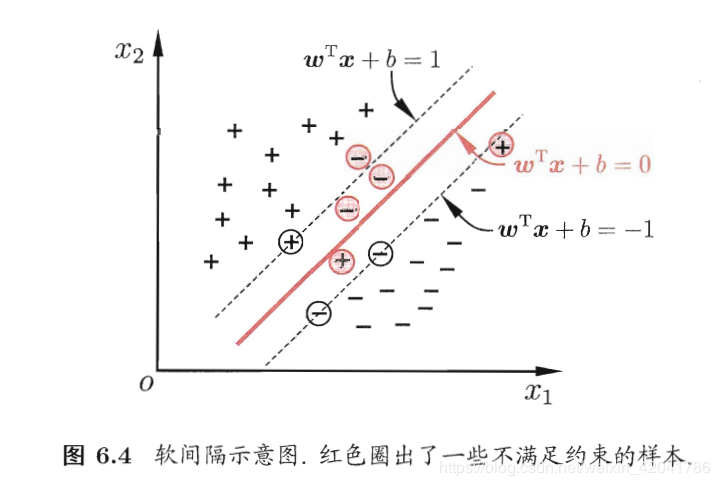
为了解决这个问题,可以对每个样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)引进一个松弛变量
ξ
i
≥
0
\xi_i\ge0
ξi≥0,使函数间隔加上松弛变量大于等于1.也就是
y
i
(
w
T
x
i
+
b
)
+
ξ
i
≥
1
y_i(w^Tx_i+b)+\xi_i\ge 1
yi(wTxi+b)+ξi≥1
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
y_i(w^Tx_i+b)\ge 1-\xi_i
yi(wTxi+b)≥1−ξi同时,对每个松弛变量
ξ
i
\xi_i
ξi,支付一个代价
ξ
i
\xi_i
ξi.目标函数由原来的
1
2
∥
w
∥
2
\frac{1}{2} \left\|w\right\|^2
21∥w∥2变成了:
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
\frac{1}{2} \left\|w\right\|^2+C\sum\limits_{i=1}^{N}\xi_i
21∥w∥2+Ci=1∑Nξi,这里的
C
>
0
C>0
C>0称为惩罚参数,变大时对误分类的惩罚增大,减小时对误分类的惩罚减小。上面的最小化目标函数包含两层含义:使
1
2
∥
w
∥
2
\frac{1}{2} \left\|w\right\|^2
21∥w∥2尽可能小也就是间隔尽量大,同时使误分类点的个数尽量小,
C
C
C是调和二者的系数,线性不可分的问题就可转化成下面的凸二次规划:
min
w
,
b
,
ξ
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
,
 
i
=
1
,
2
,
.
.
.
,
N
ξ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned}&\min\limits_{w,b,\xi}\qquad \frac{1}{2} \left\|w\right\|^2+C\sum\limits_{i=1}^{N}\xi_i\\&s.t.\qquad y_i(w^Tx_i+b)\ge 1-\xi_i,\:i=1,2,...,N\\&\qquad\qquad\xi_i\ge0,i=1,2,...,N\end{aligned}
w,b,ξmin21∥w∥2+Ci=1∑Nξis.t.yi(wTxi+b)≥1−ξi,i=1,2,...,Nξi≥0,i=1,2,...,N上述问题可转化成朗格朗日函数:
L
(
w
,
b
,
α
,
ξ
,
μ
)
=
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
+
∑
i
=
1
m
α
i
(
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
)
−
∑
i
=
1
m
μ
i
ξ
i
①
L(w,b,\alpha,\xi,\mu)=\frac{1}{2} \left\|w\right\|^2+C\sum\limits_{i=1}^{N}\xi_i+\sum\limits_{i=1}^{m}\alpha_i(1-\xi_i-y_i(w^Tx_i+b))-\sum\limits_{i=1}^{m}\mu_i\xi_i\qquad①
L(w,b,α,ξ,μ)=21∥w∥2+Ci=1∑Nξi+i=1∑mαi(1−ξi−yi(wTxi+b))−i=1∑mμiξi①
α
i
≥
0
\alpha_i\ge0
αi≥0,
μ
i
≥
0
\mu_i\ge0
μi≥0是朗格朗日乘子.令
L
(
w
,
b
,
α
,
ξ
,
μ
)
L(w,b,\alpha,\xi,\mu)
L(w,b,α,ξ,μ)对
w
,
b
,
ξ
i
w,b,\xi_i
w,b,ξi的偏导为0可得:
w
=
∑
i
=
1
m
α
i
y
i
x
i
0
=
∑
i
=
1
m
α
i
y
i
C
=
α
i
+
μ
i
w=\sum\limits_{i=1}^{m}\alpha_iy_ix_i\\0=\sum\limits_{i=1}^{m}\alpha_iy_i\\C=\alpha_i+\mu_i
w=i=1∑mαiyixi0=i=1∑mαiyiC=αi+μi,将上面三个式子代入①式得到原问题的对偶问题:
max
α
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
0
≤
α
i
≤
C
,
i
=
1
,
2
,
.
.
.
,
m
\begin{aligned}&\max\limits_{\alpha}\sum\limits_{i=1}^{m}\alpha_i-\frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j\\&s.t.\sum\limits_{i=1}^{m}\alpha _iy_i=0\\&0\leq\alpha_i\leq C,i=1,2,...,m\end{aligned}
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t.i=1∑mαiyi=00≤αi≤C,i=1,2,...,m
还需满足KKT条件:
{
α
i
≥
0
,
μ
i
≥
0
,
y
i
f
(
x
i
)
−
1
+
ξ
i
≥
0
,
α
i
(
y
i
f
(
x
i
)
−
1
+
ξ
i
)
=
0
,
ξ
i
≥
0
,
μ
i
ξ
i
=
0
\begin{cases}\alpha_i\ge0,\mu_i\ge0,\\y_if(x_i)-1+\xi_i\ge0,\\\alpha_i(y_if(x_i)-1+\xi_i)=0,\\\xi_i\ge0,\mu_i\xi_i=0\end{cases}
⎩⎪⎪⎪⎨⎪⎪⎪⎧αi≥0,μi≥0,yif(xi)−1+ξi≥0,αi(yif(xi)−1+ξi)=0,ξi≥0,μiξi=0,之后的情况就和线性可分一样了,可用SMO或者其它方法进一步求解。
















07-26
 363
363
363
10-18
3687
3687
04-03
3258
3258
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











