







 本文介绍了数据预处理中的离散化和one-hot编码技术。离散化通过pandas的cut和qcut函数将连续数据转换为区间,简化数据结构。one-hot编码则用于将分类特征转化为多个二进制列,便于机器学习模型处理。示例展示了如何使用Python对年龄数据进行离散化和one-hot编码操作。
本文介绍了数据预处理中的离散化和one-hot编码技术。离散化通过pandas的cut和qcut函数将连续数据转换为区间,简化数据结构。one-hot编码则用于将分类特征转化为多个二进制列,便于机器学习模型处理。示例展示了如何使用Python对年龄数据进行离散化和one-hot编码操作。
一、离散化
1、为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
2、什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
3、离散化操作
通常对于我们不想要连续的数值,我们可将其离散化,离散化也可称为分组、区间化。
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的。下面简单介绍一下这两个函数的用法:
pandas.qcut函数:是均匀分配,每个区间的样本数相同
import pandas as pd
ages = [20, 19, 30, 34, 23, 40, 50] #需要离散化的数组
se_ages = pd.Series(ages)
bin = [0, 18, 25, 35, 60] #分组的依据
se1 = pd.qcut(se_ages, q=4, labels=['Youth', 'YoungAdult', 'MiddleAge', 'Senior'])
print(se1)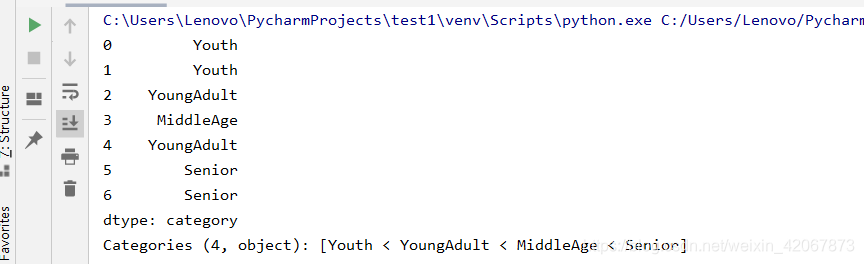
Pandas为我们提供了方便的函数cut():
pd.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
参数解释:
- x:需要离散化的数组、Series、DataFrame对象
- bins:分组的依据
- right:传入False则指定左边为闭端
import pandas as pd
ages = [20, 19, 30, 34, 23, 40, 50] #需要离散化的数组
se_ages = pd.Series(ages)
bin = [0, 18, 25, 35, 60] #分组的依据
se1 = pd.cut(se_ages, bin)
print(se1)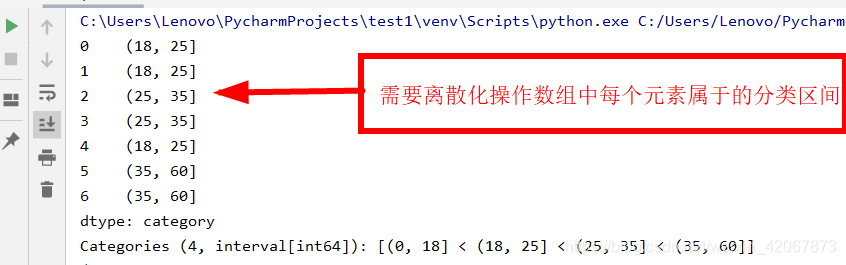
4、对分组计数
count = pd.value_counts(se1)
print(count)
5、指定左边为闭区间
se2 = pd.cut(se_ages, bin, right=False)
print(se2)
6、为区间指定名称
import pandas as pd
ages = [20, 19, 30, 34, 23, 40, 50] #需要离散化的数组
se_ages = pd.Series(ages)
bin = [0, 18, 25, 35, 60] #分组的依据
se1 = pd.cut(se_ages, bin, labels=['Youth', 'YoungAdult', 'MiddleAge', 'Senior'])
print(se1)
二、one-hot编码
1、什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
把下图中左边的表格转化为使用右边形式进行表示:
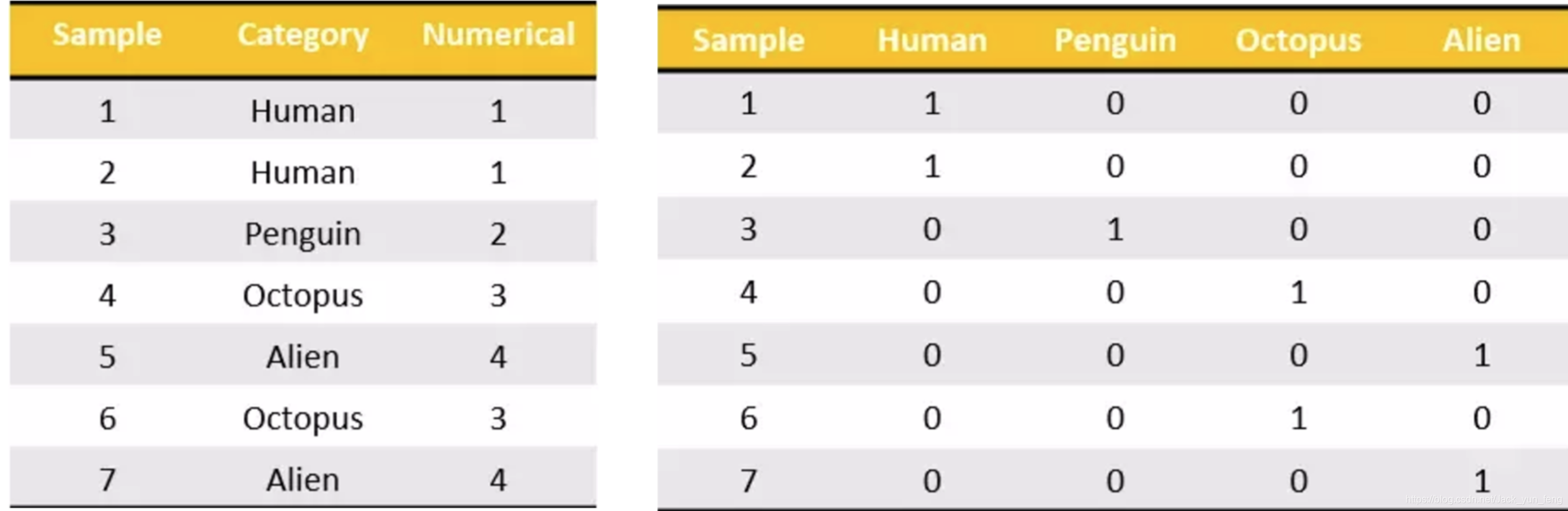
2、得出离散化数据的one-hot编码矩阵
pd.get_dummies(data,prefix=None)
- data:离散化后的数据
- prefix:分组名字
import pandas as pd
ages = [20, 19, 30, 34, 23, 40, 50] #需要离散化的数组
se_ages = pd.Series(ages)
bin = [0, 18, 25, 35, 60] #分组的依据
se1 = pd.cut(se_ages, bin, labels=['Youth', 'YoungAdult', 'MiddleAge', 'Senior'])
print(se1)
#获得one-hot编码
dummies = pd.get_dummies(se1, prefix=None)
print(dummies)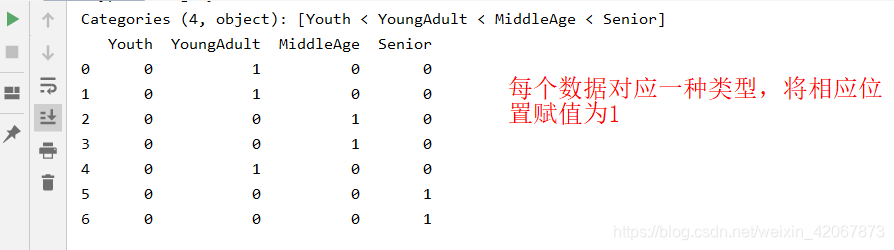


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











