






项目介绍
对于刚入门深度学习的萌新来说,常常迷惑于如何搭建一个深度学习模型,怎样选择合适的模型,模型到底学到了什么东西。笔者在参加CV方面比赛的时候,对于backbone的选择,往往是哪个网络新就选哪个网络作为backbone,至于为什么这个网络好,到底好在哪?笔者也说不清,所谓只知其然而不知其所以然。调参的时候往往是一顿操作猛如虎,至于其效果好不好,全看天意。作为一名严谨的科研萌新,不仅要知道如何调参冲榜,还要知道这个参数背后的故事。本文以图像分类网络为例结合visualdl来带大家逐步揭开网络神秘的面纱,通过本文,你可以学到
- 使用visualdl可视化模型loss曲线和acc曲线,帮助针对分类任务快速搭建一个深度学习网络
- 使用visuald可视化不同模型的输出曲线,帮助快速选择合适的深度学习模型
- 使用visualdl配合模型调参,并可视化不同学习率下模型loss曲线和acc曲线变化
- 使用visualdl可视化网络各层的feature map,直观感受随着训练的进行,各层网络学到了什么信息
在本文中,以手势分类任务为例,从最简单的DNN开始,配合visualdl一步一步搭建一个好的分类模型。你将学会如何选用合适的网络,合适的优化器,合适的学习率,以及了解feature map随着训练的变化、
visualdl介绍
VisualDL的Github地址:https://github.com/PaddlePaddle/VisualDL
VIsualDL的Gitee地址:https://gitee.com/PaddlePaddle/VisualDL
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
VisualDL是百度PaddlePaddle和Echart团队联合推出的深度学习可视化工具,方便我们观察模型的输入输出、网络权重、loss、准确率变化等关键信息,有助于我们更好地理解模型的行为,加快debug进度。在Github开源
其主要支持的可视化数据类型有:
-
Scalar
以图表形式实时展示训练过程参数,如loss、accuracy。让用户通过观察单组或多组训练参数变化,了解训练过程,加速模型调优。具有两大特点: -
动态展示
在启动VisualDL Board后,LogReader将不断增量的读取日志中数据并供前端调用展示,因此能够在训练中同步观测指标变化,如下图:
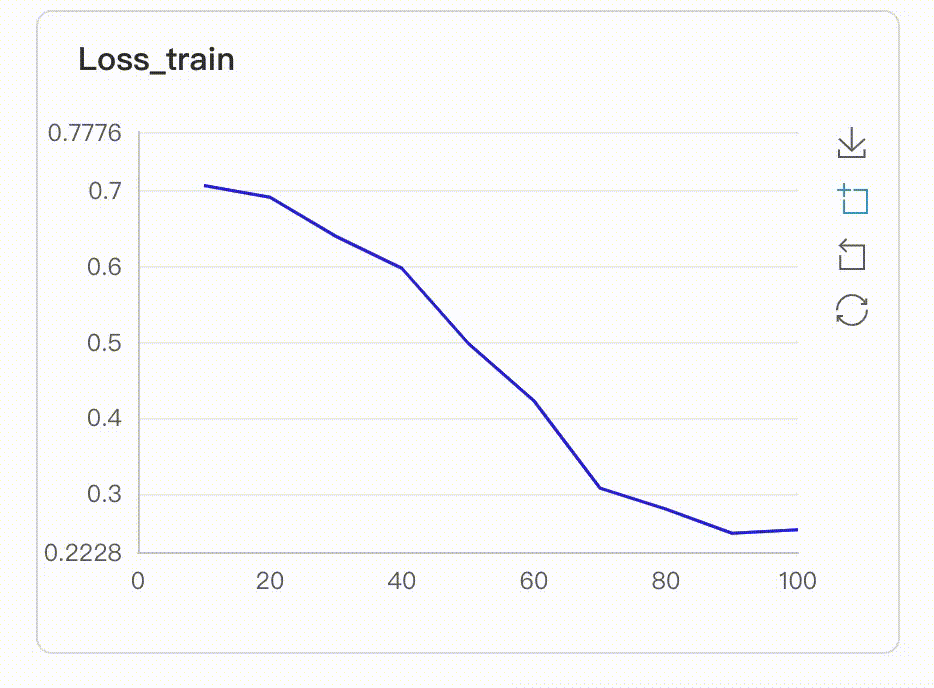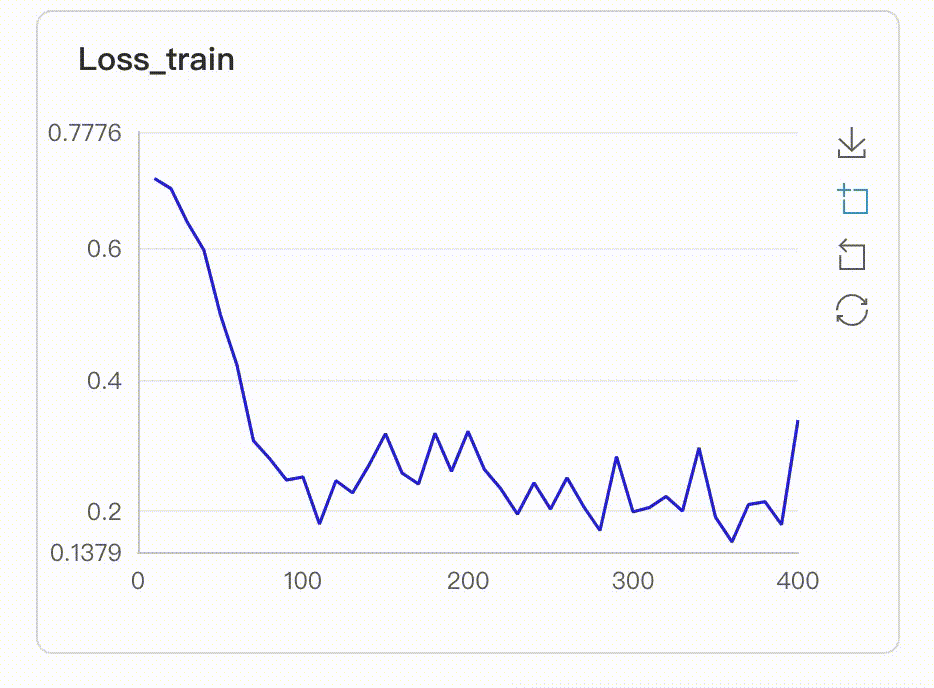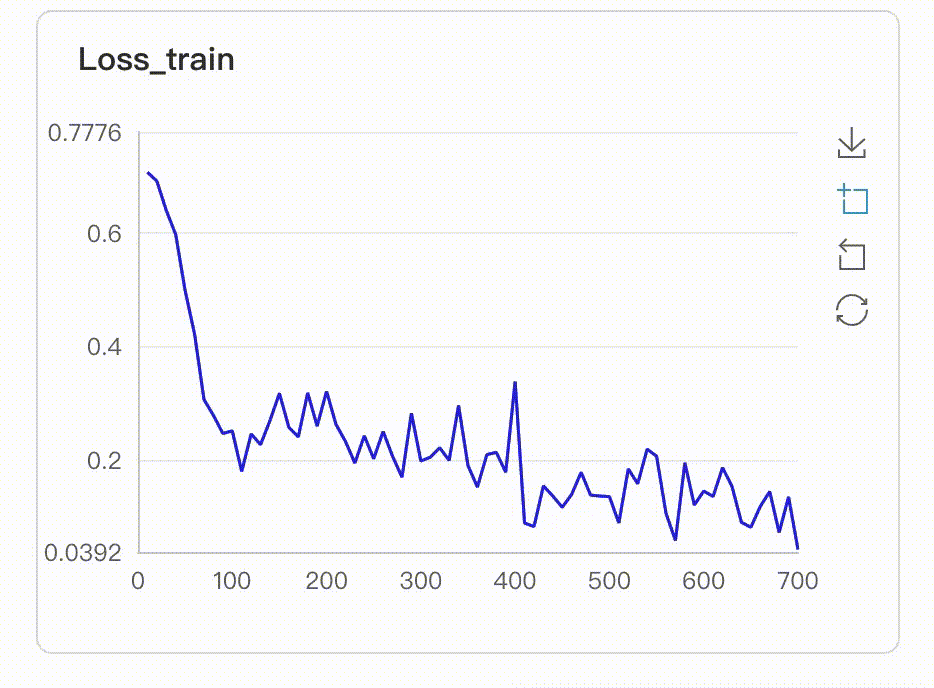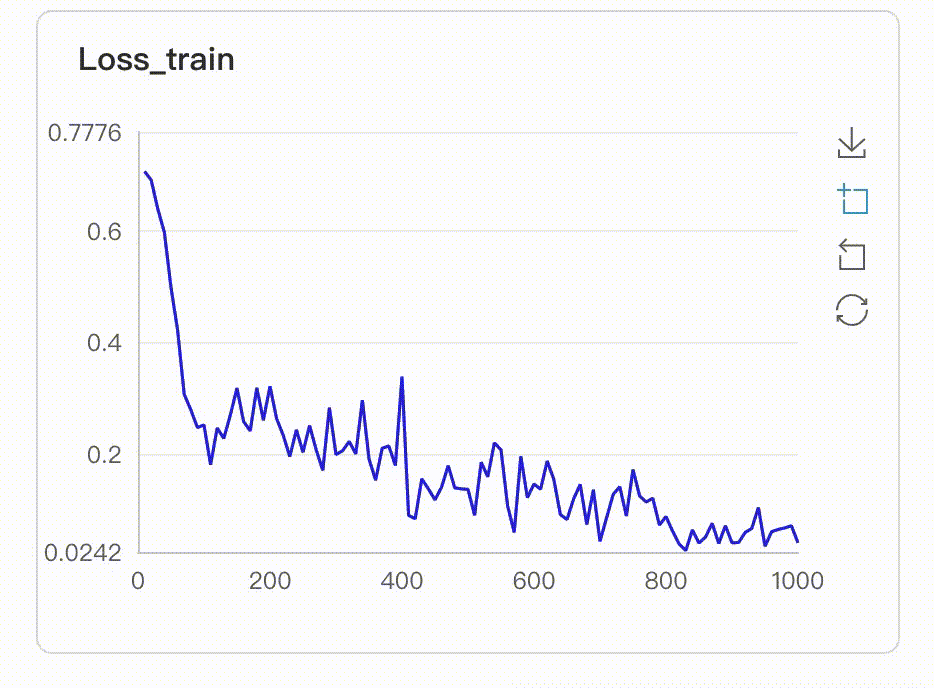
- 多实验对比
只需在启动VisualDL Board的时将每个实验日志所在路径同时传入即可,每个实验中相同tag的指标将绘制在一张图中同步呈现,如下图:
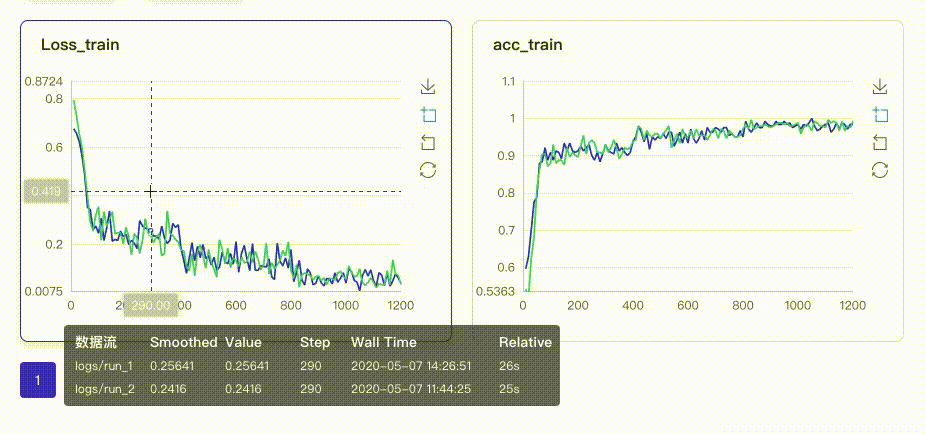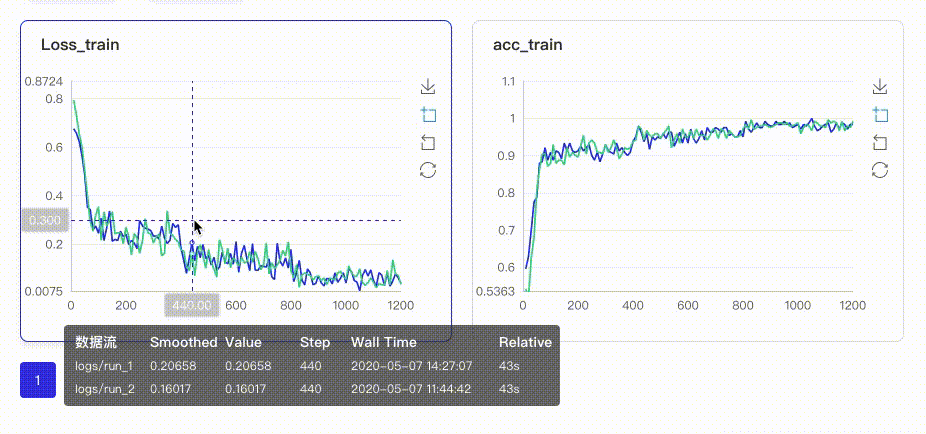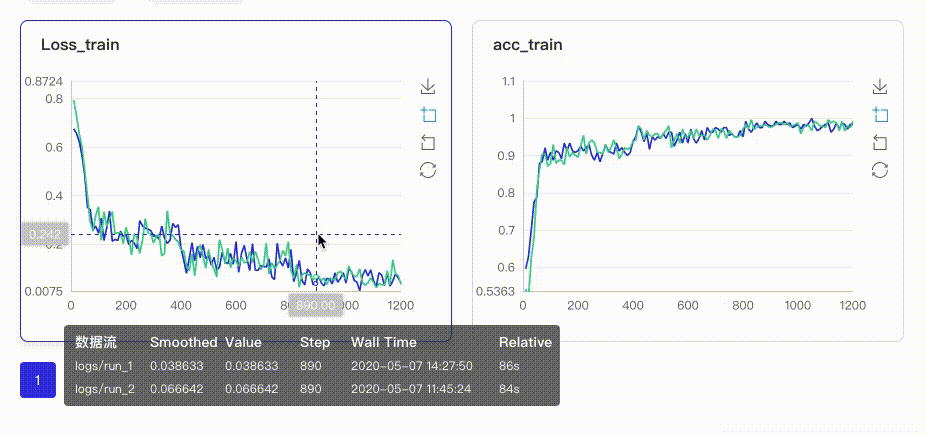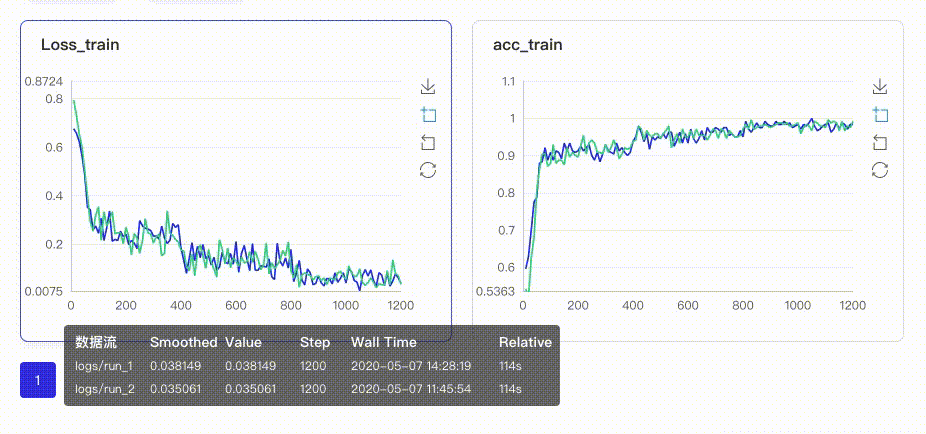
- Image
实时展示训练过程中的图像数据,用于观察不同训练阶段的图像变化,进而深入了解训练过程及效果。

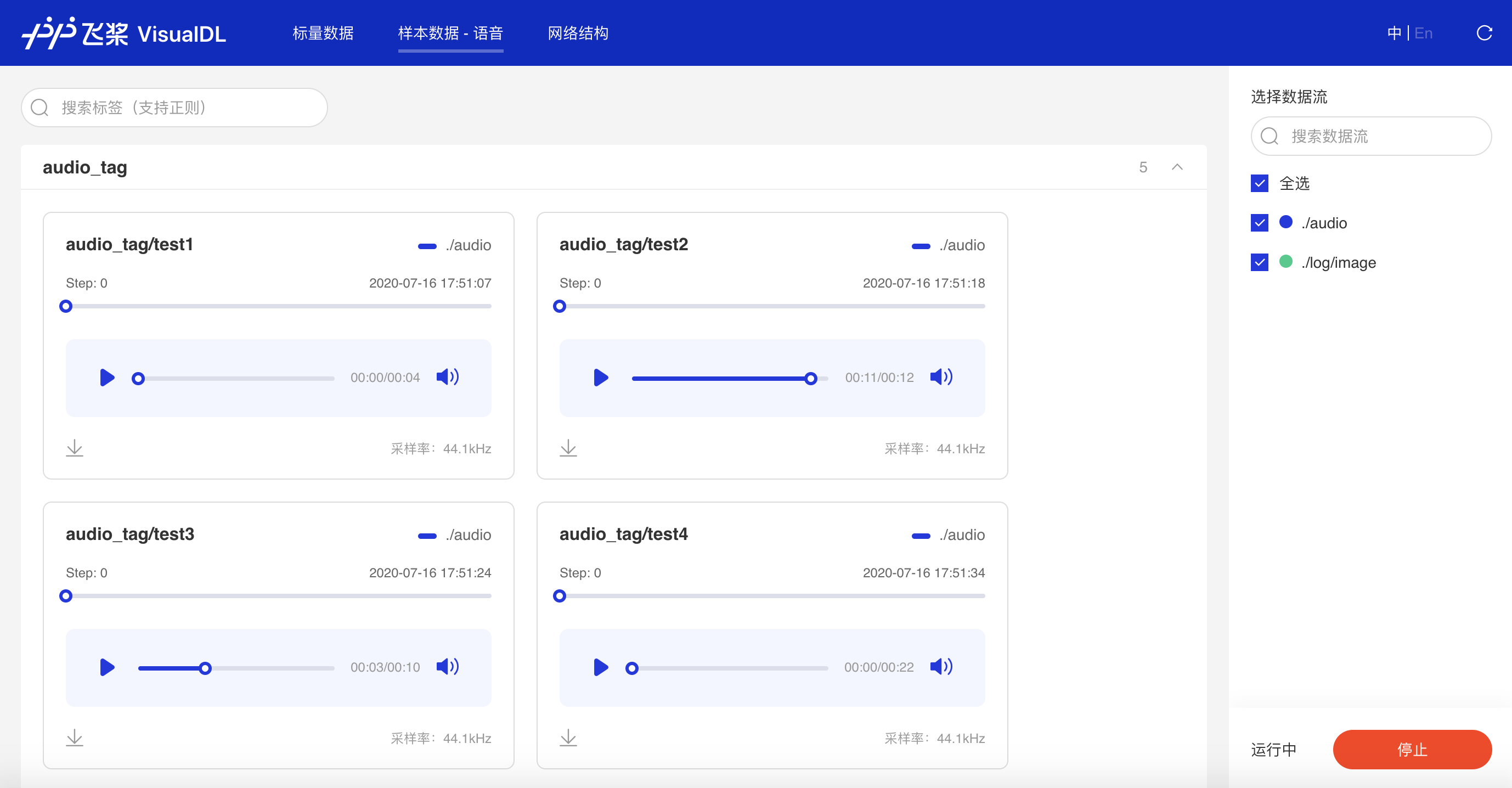
- Audio
实时查看训练过程中的音频数据,监控语音识别与合成等任务的训练过程。
- Graph
一键可视化模型的网络结构。可查看模型属性、节点信息、节点输入输出等,并支持节点搜索,辅助用户快速分析模型结构与了解数据流向。

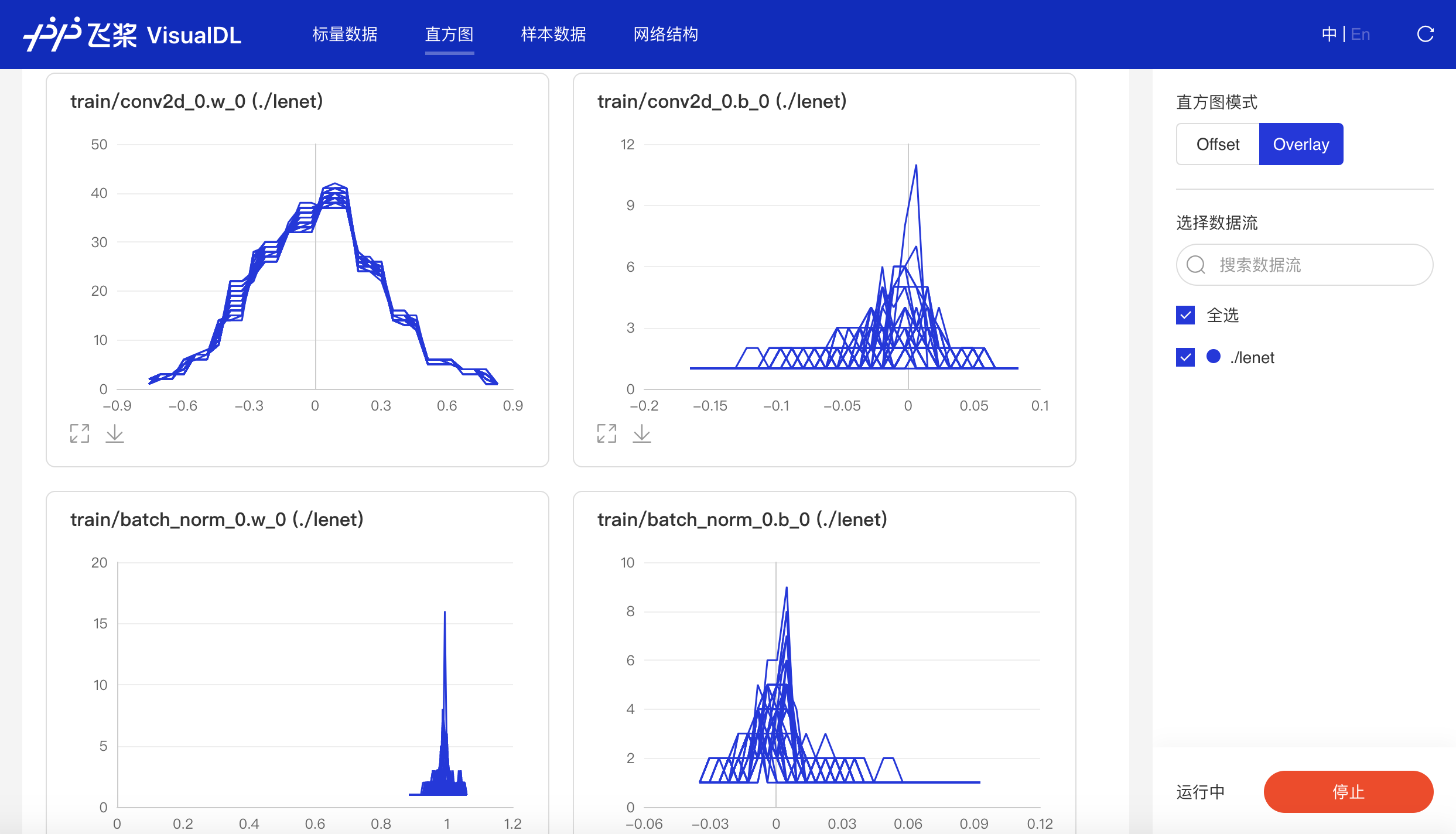
- Histogram
以直方图形式展示Tensor(weight、bias、gradient等)数据在训练过程中的变化趋势。深入了解模型各层效果,帮助开发者精准调整模型结构。
- Offset模式

- Overlay模式
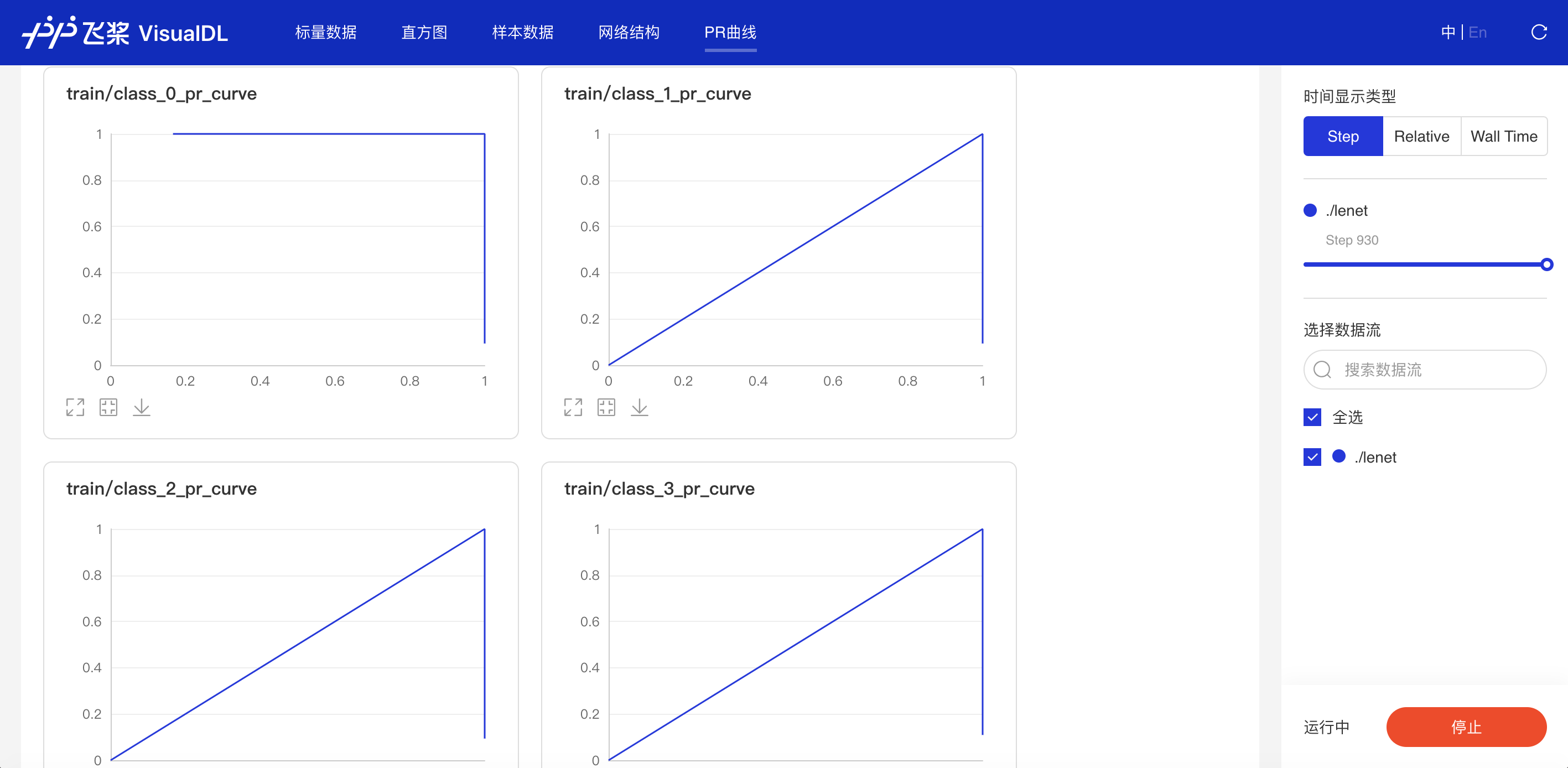
- PR Curve
精度-召回率曲线,帮助开发者权衡模型精度和召回率之间的平衡,设定最佳阈值。
- High Dimensional
将高维数据进行降维展示,目前支持T-SNE、PCA两种降维方式,用于深入分析高维数据间的关系,方便用户根据数据特征进行算法优化。

- VDL.service
VisualDL可视化结果保存服务,以链接形式将可视化结果保存下来,方便用户快速、便捷的进行托管与分享。

#导入需要的包
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
数据准备
# 生成图像列表
data_path = 'data/dataset/Dataset'
character_folders = os.listdir(data_path)
# print(character_folders)
if(os.path.exists('data/dataset/train_data.list')):
os.remove('data/dataset/train_data.list')
if(os.path.exists('data/dataset/test_data.list')):
os.remove('data/dataset/test_data.list')
for character_folder in character_folders:
with open('data/dataset/train_data.list', 'a') as f_train:
with open('data/dataset/test_data.list', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path,character_folder))
count = 0
for img in character_imgs:
if img =='.DS_Store':
continue
if count%10 == 0:
f_test.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
count +=1
print('列表已生成')
```python
# 定义训练集和测试集的reader
def data_mapper(sample):
img, label = sample
img = Image.open(img)
# print(img.size)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
np.random.shuffle(lines)
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('data/dataset/train_data.list'), buf_size=256), batch_size=32)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('data/dataset/test_data.list'), batch_size=32)
搭建深度学习模型
DNN网络
对于任何一种深度学习任务,我们最开始都是先搭建一个简单的基线,看看效果如何,下面我们首先搭建一个最简单的深度神经网络DNN来进行测试使用visualdl来进行训练的可视化
对于深度神经网络DNN,网上有各种叫法,有的称为全连接网络,也有文章称它叫多层感知机,下图是一个DNN的基本结构,从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。使用DNN做图像分类时,我们需要将图像的像素张开成一维,然后将其作为DNN的输入,经过多层网络之后,输出一个与类别数大小相同的一维向量,一般使用softmax作为激活函数,每一个输出代表该图片属于某一个类别的概率

import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear,Dropout
from paddle.fluid.layer_helper import LayerHelper
#定义DNN网络
class MyDNN(fluid.dygraph.Layer):
def __init__(self):
super(MyDNN,self).__init__()
self.fc1 = Linear(100, 300, act='relu')
self.fc2 = Linear(300, 500, act='relu')
self.fc3 = Linear(500, 100, act='relu')
self.fc4 = Linear(3*100*100, 10, act='softmax')
def forward(self, input):
x = self.fc1(input)
x = self.fc2(x)
x = self.fc3(x)
x = fluid.layers.reshape(x, shape=[-1, 3*100*100])
y = self.fc4(x)
return y
from visualdl import LogWriter
log_writer = LogWriter("./log/DNN")
#用动态图进行训练
with fluid.dygraph.guard():
model=MyDNN()
model.train() #训练模式
epochs_num=300 #迭代次数
base_lr = 0.01
# lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=epochs_num) #动态学习率
opt=fluid.optimizer.AdamOptimizer(learning_rate=base_lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
# predict,acc=model(image,label)#预测
predict=model(image)
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
# log_writer.add_image(tag='train/input', img=np.reshape(dy_x_data[0][0], (224, 224, 3)) * 255, step=batch_id)
log_writer.add_scalar(tag='train/loss',step=pass_num,value=avg_loss)
log_writer.add_scalar(tag='train/acc',step=pass_num,value=acc)
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'Mymodel')#保存模型
从visualdl上展示的图来看,效果简直一言难尽,loss曲线一点下降的趋势都没有,acc曲线也一直在震荡,难道是我们的网络不行吗?

遇到这种问题先不要慌,我们可以尝试一下对模型的一些参数进行调整。比如尝试一下别的优化器。下面我们使用SGDOptimizer作为优化器,仍然选择DNN网络进行训练,从visualdl可视化的训练结果来看,训练的结果符合我们对于一个深度学习模型的期待(即loss曲线呈下降趋势,acc是上升趋势):

#DNN训练代码
from visualdl import LogWriter
log_writer = LogWriter("./log/MyDNN_SGD")
#用动态图进行训练
with fluid.dygraph.guard():
model=MyDNN()
# model=VGGNet('VGG_16',class_dim=10) #模型实例化
model.train() #训练模式
epochs_num=50 #迭代次数
base_lr = 0.01
# lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=epochs_num) #动态学习率
# opt=fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
opt=fluid.optimizer.SGDOptimizer(learning_rate=base_lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
# predict,acc=model(image,label)#预测
predict=model(image)
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
# log_writer.add_image(tag='train/input', img=np.reshape(dy_x_data[0][0], (224, 224, 3)) * 255, step=batch_id)
log_writer.add_scalar(tag='train/loss',step=pass_num,value=avg_loss)
log_writer.add_scalar(tag='train/acc',step=pass_num,value=acc)
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'MyDNN')#保存模型
VGG网络
以下部分内容引用自知乎:一文读懂VGG网络
VGG是Oxford的Visual Geometry Group的组提出的。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。VGG的网络结构如下:

下图是VGG网络的训练结果,可以看到,相对于DNN网络,VGG网络的收敛曲线变平滑很多,说明对于图像分类任务来说,卷积神经网络相比于深度神经网络具有更大的优势:

#定义VGG网络
class ConvBlock(fluid.dygraph.Layer):
"""
卷积+池化
"""
def __init__(self, name_scope, num_channels, num_filters, groups):
"""构造函数"""
super(ConvBlock, self).__init__(name_scope)
self._conv2d_list = []
init_num_channels = num_channels
for i in range(groups):
conv2d = self.add_sublayer(
'bb_%d' % i,
fluid.dygraph.Conv2D(
init_num_channels, num_filters=num_filters, filter_size=3,
stride=1, padding=1, act='relu'
)
)
self._conv2d_list.append(conv2d)
init_num_channels = num_filters
self._pool = fluid.dygraph.Pool2D(
pool_size=2, pool_type='max', pool_stride=2
)
def forward(self, inputs):
"""前向计算"""
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool(x)
return x
class VGGNet(fluid.dygraph.Layer):
"""
VGG网络
"""
def __init__(self, name_scope, layers=16, class_dim=1000):
"""
构造函数
:param name_scope: 命名空间
:param layers: 具体的层数如VGG-16、VGG-19等
"""
super(VGGNet, self).__init__(name_scope)
self.vgg_spec = {
11: ([1, 1, 2, 2, 2]),
13: ([2, 2, 2, 2, 2]),
16: ([2, 2, 3, 3, 3]),
19: ([2, 2, 4, 4, 4])
}
assert layers in self.vgg_spec.keys(), \
"supported layers are {} but input layer is {}".format(self.vgg_spec.keys(), layers)
nums = self.vgg_spec[layers]
self.conv1 = ConvBlock(self.full_name(), num_channels=3, num_filters=64, groups=nums[0])
self.conv2 = ConvBlock(self.full_name(), num_channels=64, num_filters=128, groups=nums[1])
self.conv3 = ConvBlock(self.full_name(), num_channels=128, num_filters=256, groups=nums[2])
self.conv4 = ConvBlock(self.full_name(), num_channels=256, num_filters=512, groups=nums[3])
self.conv5 = ConvBlock(self.full_name(), num_channels=512, num_filters=512, groups=nums[4])
fc_dim = 4096
self.fc1 = fluid.dygraph.Linear(input_dim=4608, output_dim=fc_dim, act='relu')
self.fc2 = fluid.dygraph.Linear(input_dim=fc_dim, output_dim=fc_dim, act='relu')
self.out = fluid.dygraph.Linear(input_dim=fc_dim, output_dim=class_dim, act='softmax')
def forward(self, inputs, label=None):
"""前向计算"""
out = self.conv1(inputs)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = fluid.layers.reshape(out, [-1, 4608])
out = self.fc1(out)
out = fluid.layers.dropout(out, dropout_prob=0.5)
out = self.fc2(out)
out = fluid.layers.dropout(out, dropout_prob=0.5)
out = self.out(out)
return out
ResNet
以下部分内容引用自博客:卷积神经网络的网络结构——ResNet
ResNet由微软研究院的kaiming He等4名华人提出,通过使用Residual Unit成功训练152层深的神经网络,在ILSVRC 2015比赛中获得了冠军,取得3.57%的top5错误率,同时参数量却比VGGNet低,效果非常突出。ResNet的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。Resnet的核心在于它的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差。
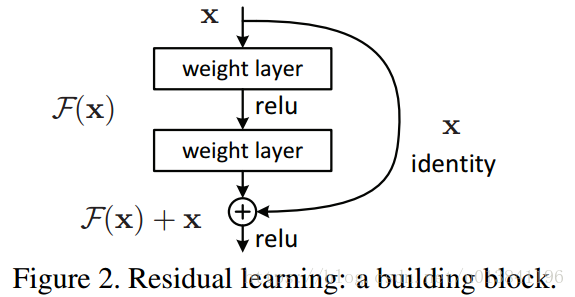
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。下面是常用的Resnet网络结构:

下图是使用Resnet50的训练结果,从图中可以看出,resnet收敛速度也很快,只不过在训练初期有一点小波动,在训练后期很快稳定下来:

#定义Resnet网络
class ConvBNLayer(fluid.dygraph.Layer):
def __init__(self,
name_scope,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None):
super(ConvBNLayer, self).__init__(name_scope)
self._conv = Conv2D(
num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
bias_attr=False)
self._batch_norm = BatchNorm(num_filters, act=act)
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
class BottleneckBlock(fluid.dygraph.Layer):
def __init__(self,
name_scope,
num_channels,
num_filters,
stride,
shortcut=True):
super(BottleneckBlock, self).__init__(name_scope)
self.conv0 = ConvBNLayer(
self.full_name(),
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act='relu')
self.conv1 = ConvBNLayer(
self.full_name(),
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu')
self.conv2 = ConvBNLayer(
self.full_name(),
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None)
if not shortcut:
self.short = ConvBNLayer(
self.full_name(),
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = fluid.layers.elementwise_add(x=short, y=conv2)
layer_helper = LayerHelper(self.full_name(), act='relu')
return layer_helper.append_activation(y)
class ResNet(fluid.dygraph.Layer):
def __init__(self, name_scope, layers=50, class_dim=5):
super(ResNet, self).__init__(name_scope)
self.layers = layers
supported_layers = [50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 50:
depth = [3, 4, 6, 3]
elif layers == 101:
depth = [3, 4, 23, 3]
elif layers == 152:
depth = [3, 8, 36, 3]
num_filters = [64, 128, 256, 512]
self.conv = ConvBNLayer(
self.full_name(),
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act='relu')
self.pool2d_max = Pool2D(
pool_size=3,
pool_stride=2,
pool_padding=1,
pool_type='max')
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
self.full_name(),
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
self.pool2d_avg = Pool2D(pool_size=7, pool_type='avg', global_pooling=True)
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
self.out = Linear(input_dim=num_channels,
output_dim=class_dim,
act='softmax',
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv)))
def forward(self, inputs, label=None):
y = self.conv(inputs)
y = self.pool2d_max(y)
for bottleneck_block in self.bottleneck_block_list:
y = bottleneck_block(y)
y = self.pool2d_avg(y)
y = fluid.layers.reshape(x=y, shape=[-1, y.shape[1]])
y = self.out(y)
return y
下面是上述三种网络的训练代码:
from visualdl import LogWriter
config_list=[(MyDNN(),"./log/DNN_SGD"),(VGGNet('VGG_16',class_dim=10),"./log/VGG_SGD"),(ResNet('Resnet',class_dim=10),"./log/Resnet_SGD")]
for model,log_dir in config_list:
log_writer = LogWriter(log_dir)
model_save_dir=log_dir.split('/')[-1]#模型保存路径
#用动态图进行训练
with fluid.dygraph.guard():
# model=MyDNN()
model=model #模型实例化
model.train() #训练模式
epochs_num=50 #迭代次数
base_lr = 0.01
# lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=epochs_num) #动态学习率
# opt=fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
opt=fluid.optimizer.SGDOptimizer(learning_rate=base_lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
# predict,acc=model(image,label)#预测
predict=model(image)
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
# log_writer.add_image(tag='train/input', img=np.reshape(dy_x_data[0][0], (224, 224, 3)) * 255, step=batch_id)
log_writer.add_scalar(tag='train/loss',step=pass_num,value=avg_loss)
log_writer.add_scalar(tag='train/acc',step=pass_num,value=acc)
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),model_save_dir)#保存模型
对比不同学习率下loss曲线与acc曲线的收敛速度
对比Resnet网络不同学习率下loss曲线与acc曲线的收敛速度,为了方便对比,将采样频率提高到10个batch采样一次
lr0.1

lr0.01

lr0.001

从上面的曲线变化可以看出,当学习率为0.1的时候,网络很快就能达到收敛,随着网络的学习率的减小,收敛逐渐变慢
from visualdl import LogWriter
lr_list=[0.1,0.01,0.001,0.0001]
for lr in lr_list:
log_writer = LogWriter("./log/Resnet_lr"+str(lr))
#用动态图进行训练
with fluid.dygraph.guard():
# model=MyDNN()
model=ResNet('Resnet',class_dim=10) #模型实例化
model.train() #训练模式
epochs_num=100 #迭代次数
base_lr = lr
# lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=epochs_num) #动态学习率
# opt=fluid.optimizer.AdamOptimizer(learning_arate=lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
opt=fluid.optimizer.SGDOptimizer(learning_rate=base_lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
step=0
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
# predict,acc=model(image,label)#预测
predict=model(image)
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
step=step+1
if batch_id!=0 and batch_id%10==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
# log_writer.add_image(tag='train/input', img=np.reshape(dy_x_data[0][0], (224, 224, 3)) * 255, step=batch_id)
log_writer.add_scalar(tag='train/loss',step=step,value=avg_loss)
log_writer.add_scalar(tag='train/acc',step=step,value=acc)
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'Resnet_SGD')#保存模型
查看特征图
在训练的时候,我们想要知道特征图是如何随着训练而改变的,visualdl可以很方便地进行特征图的可视化,我们在搭建网络的时候,需要对网络的输出进行一些改变,下面以VGGNet为例:
- 1.将我们想要查看的特征图添加到网络的输出

- 2.定义绘图函数,该部分参考GT的一篇文章,代码见draw()函数

- 3.对于输出特征图使用visualdl进行保存

- 4.使用visualdl查看特征图,建议直接打开visualdl查看,在visualdl中可以通过拖动进度条查看不同训练步数时特征图的变化

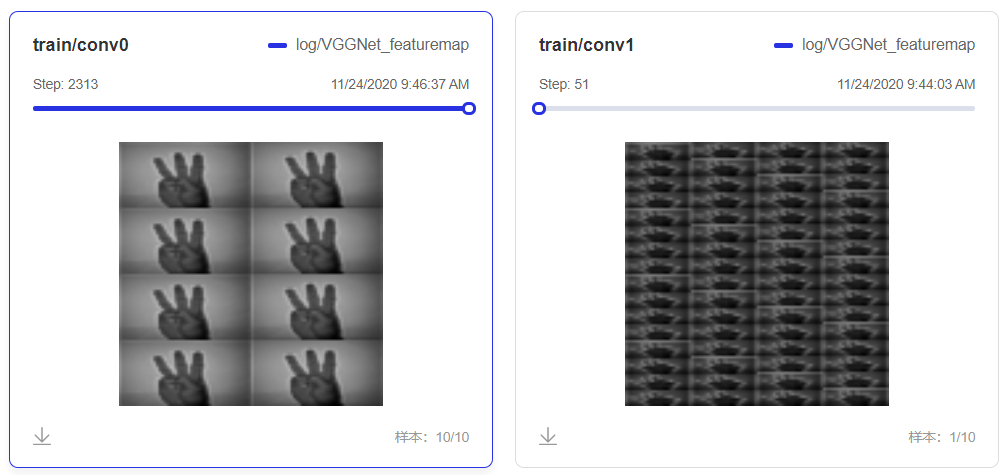
 \
\
从输出的特征图来看,卷积层越接近输入层,特征图与原图越接近,卷积层离得输入层越远,特征图与原图差距越大,到了第三个conv block(图中conv2)之后输出的特征已经很难看出它与原图的关系了。其次,离输入层越近的手势越少,越远的越多,我认为这个和每一层的输入输出通道数相关,前一层接受的输入经过卷积池化等操作会作为多个通道的输出,而不使用drop的情况下,每个卷积核都将学到上一层卷积的所有通道的输出,随着这样不断地叠加,后面学到的特征将越来越丰富。本文的这个只能算是把每层输出的feature map进行可视化,并不能完全展示出网络每层学习到了什么,想要深入研究的小伙伴可以参考论文:https://link.springer.com/chapter/10.1007/978-3-319-10590-1_53
class VGGNet(fluid.dygraph.Layer):
"""
VGG网络
"""
def __init__(self, name_scope, layers=16, class_dim=1000):
"""
构造函数
:param name_scope: 命名空间
:param layers: 具体的层数如VGG-16、VGG-19等
"""
super(VGGNet, self).__init__(name_scope)
self.vgg_spec = {
11: ([1, 1, 2, 2, 2]),
13: ([2, 2, 2, 2, 2]),
16: ([2, 2, 3, 3, 3]),
19: ([2, 2, 4, 4, 4])
}
assert layers in self.vgg_spec.keys(), \
"supported layers are {} but input layer is {}".format(self.vgg_spec.keys(), layers)
nums = self.vgg_spec[layers]
self.conv1 = ConvBlock(self.full_name(), num_channels=3, num_filters=64, groups=nums[0])
self.conv2 = ConvBlock(self.full_name(), num_channels=64, num_filters=128, groups=nums[1])
self.conv3 = ConvBlock(self.full_name(), num_channels=128, num_filters=256, groups=nums[2])
self.conv4 = ConvBlock(self.full_name(), num_channels=256, num_filters=512, groups=nums[3])
self.conv5 = ConvBlock(self.full_name(), num_channels=512, num_filters=512, groups=nums[4])
fc_dim = 4096
self.fc1 = fluid.dygraph.Linear(input_dim=4608, output_dim=fc_dim, act='relu')
self.fc2 = fluid.dygraph.Linear(input_dim=fc_dim, output_dim=fc_dim, act='relu')
self.out = fluid.dygraph.Linear(input_dim=fc_dim, output_dim=class_dim, act='softmax')
def forward(self, inputs, label=None):
"""前向计算"""
out1 = self.conv1(inputs)
out2 = self.conv2(out1)
out3 = self.conv3(out2)
out4 = self.conv4(out3)
out5 = self.conv5(out4)
out = fluid.layers.reshape(out5, [-1, 4608])
out = self.fc1(out)
out = fluid.layers.dropout(out, dropout_prob=0.5)
out = self.fc2(out)
out = fluid.layers.dropout(out, dropout_prob=0.5)
out = self.out(out)
return [out,out1,out2,out3,out4,out5]
def draw(results, img_num: int = 10):
"""
可视化对应层结果
:param results: 经卷积/池化层后的运算结果,格式为NCHW - 例: 128(batch size), 32(num_filters=16), 30(H), 15(W)
:param img_num: 采样数
"""
def fix_value(ipt):
pix_max = np.max(ipt)
pix_min = np.min(ipt)
base_value = np.abs(pix_min) + np.abs(pix_max)
base_rate = 255 / base_value
pix_left = base_rate * pix_min
ipt = ipt * base_rate - pix_left
ipt[ipt < 0] = 0.
ipt[ipt > 255] = 1.
return ipt
im_list = None
result=results[0]
result = np.sum(result, axis=0)
im = fix_value(result)
return im
# for result_i, result in enumerate(results):
# if result_i == img_num - 1:
# break
# print(result.shape)
# result = np.sum(result, axis=0)
# im = fix_value(result)
# if im_list is None:
# im_list = im
# else:
# im_list = np.append(im_list, im, axis=1)
# return im_list
from visualdl import LogWriter
log_writer = LogWriter("./log/VGGNet_featuremap")
#用动态图进行训练
with fluid.dygraph.guard():
# model=MyDNN()
# model=LeNet('Lenet',class_dim=10)
# model=AlexNet('AlexNet',class_dim=10)
model=VGGNet('VGG_16',class_dim=10) #模型实例化
# mdoel=GoogLeNet('Googlenet',class_dim=10)
# model=ResNet('Resnet50',class_dim=10)
model.train() #训练模式
epochs_num=50 #迭代次数
base_lr = 0.01
step=0
# lr = fluid.layers.cosine_decay( learning_rate = base_lr, step_each_epoch=10000, epochs=epochs_num) #动态学习率
opt=fluid.optimizer.SGDOptimizer(learning_rate=base_lr, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
# predict,acc=model(image,label)#预测
out=model(image)
predict=out[0]
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
step+=1
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
for id,results in enumerate(out[1:]):
conv=draw(results.numpy())
conv=np.resize(conv,(100,100))
# print(conv.shape)
log_writer.add_image(tag='train/conv'+str(id), img=np.reshape(conv, (1,100, 100)).transpose((1, 2, 0)), step=step)
# log_writer.add_image(tag='train/conv'+str(id), img=np.reshape(conv, (100, 100, 1)).transpose((1, 2, 0)), step=step)
# log_writer.add_image(tag='train/input', img=np.reshape(images[0], (100, 100, 3)) * 255, step=step)
log_writer.add_image(tag='train/input', img=images[0].transpose((1, 2, 0)) * 255, step=step)
log_writer.add_scalar(tag='train/loss',step=step,value=avg_loss)
log_writer.add_scalar(tag='train/acc',step=step,value=acc)
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'Mymodel')#保存模型
#模型校验
with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyDNN')
model = MyDNN()
model.load_dict(model_dict) #加载模型参数
model.eval() #训练模式
for batch_id,data in enumerate(test_reader()):#测试集
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
#读取预测图像,进行预测
def load_image(path):
img = Image.open(path)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
print(img.shape)
return img
#构建预测动态图过程
with fluid.dygraph.guard():
infer_path = 'data/dataset/Dataset/1/IMG_4696.JPG'
model=MyDNN()#模型实例化
model_dict,_=fluid.load_dygraph('MyDNN')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
infer_img = load_image(infer_path)
infer_img=np.array(infer_img).astype('float32')
infer_img=infer_img[np.newaxis,:, : ,:]
infer_img = fluid.dygraph.to_variable(infer_img)
result=model(infer_img)
display(Image.open('data/dataset/Dataset/1/IMG_4696.JPG'))
print(np.argmax(result.numpy()))
总结:
- 对于一个深度学习任务,可以通过搭建最简单的DNN模型来进行测试,然后再从这个基础上尝试更好的网络。
- 优化器的选择真的很重要,笔者在开始选择了Adam优化器导致一直无法收敛,后来选择SGD优化器才得以让训练正常进行。通过查阅资料才发现Adam会有导致不收敛的情况发生,这个必须得亲自尝试之后才能了解。
- 通过visualdl对模型训练的可视化,有助于训练过程中的调参已及网络的对比,帮助我们选择更适合的网络。
- 学习率对网络的收敛速度影响很大,我们可以在训练初期使用大的学习率加快收敛,训练后期使用小的学习率进行微调。
- 通过visualdl对模型训练过程中特征图的变化情况,可以看出,卷积层越接近输入层,特征图与原图越接近,卷积层离得输入层越远,特征图与原图差距越大。其次,离输入层越近的手势越少,越远的越多,我认为这个和每一层的输入输出通道数相关,前一层接受的输入经过卷积池化等操作会作为多个通道的输出,而不使用drop的情况下,每个卷积核都将学到上一层卷积的所有通道的输出,随着这样不断地叠加,后面学到的特征将越来越丰富。
- 在使用np.reshape()改变维度时,会导致图现中出现多个图,在这里需要使用transpose()函数进行通道交换
VisualDL的Github地址:https://github.com/PaddlePaddle/VisualDL
VIsualDL的Gitee地址:https://gitee.com/PaddlePaddle/VisualDL















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









