





2023年是高阶自动驾驶方案从Demo走向量产的一年,在这一年里学术界着重讨论了3D Lidar Detection更快(Edge端更友好的模型),更高(更高的数据有效率),更强(带来提点的模型结构)。
随着各大公司从量产走向大规模量产,如何在量产的过程中提高数据的有效率,增加不同项目之间数据的可复用性也成为了比较火热的研究课题。在这篇文章中,总结了4篇来自于上海人工智能实验室的文章,都是关于Lidar based 3D Detection 任务和数据效率相关的文章。
DetZero: Rethinking Offboard 3D Object Detection with Long-term Sequential Point Clouds.
简介:这篇工作来自上海人工智能实验室,作者发现现有的离线检测模块基本遵循了多阶段的模块化流水线设计,在目标轨迹的完整性和利用长间上下文表示中遇到了局限性。文章提出了一种新的离线3D目标检测新范式,专注生成目标轨迹的完整性,并且加强长序列点云中跨对象的上下文信息交互。并且,这样的离线自动标注结果是可以替代人工标注的。
主要方法:
DetZero框架整体,输入为多帧检测器以 N 帧点云,接下来的离线跟踪器生成准确且完整的对象轨迹。对于每个对象轨迹,Pipeline对其特定于对象的pointcloud序列和跟踪的边界框序列。因此,Detzero通过三个同时步骤对对象轨迹进行细化:细化几何大小,平滑运动轨迹,更新置信度分数。之后,它们被合并并通过从世界坐标到帧坐标的变换作为最终的“自动标签”。
Complete Object Tracks Generation:
Object Detection:生成完整轨迹的第一阶段任然是进行高质量的多帧目标检测,作者使用centerpoint作为基线并作出了三点优化。1)在基线的基础上作者使用使用五帧点云的组合作为输入提高预测性能。2)设计了一个点密度感知模块,以利用原始点特征和体素特征进行精确的细化。3)为了提高适应复杂环境的能力,使用了点云数据的测试时增强 (TTA)和多模型集成(不同分辨率、网络结构和容量),以增强检测性能。
Offline Tracking:
多目标跟踪器采用了两阶段的数据关联策略,以减轻误匹配的可能性。具体而言,检测到的边界框根据其置信度分数被划分为两个不同的组。现有的对象轨迹最初仅与高分组进行数据关联,随后,成功关联的边界框用于更新现有轨迹。未更新的轨迹进一步与低分组关联,未关联的边界框被弃用。此外,对象的生命周期允许一直持续到序列终止,之后未更新的任何冗余边界框都将被移除。这个操作有助于重新连接被截断的对象轨迹并有效防止ID切换。作者发现后处理对于生成高质量的轨迹也至关重要,论文中按照逆时间顺序重新执行Tracking,以生成另一组轨迹,这些轨迹然后通过位置感知相似性匹配分数进行关联。最后,论文中额外采用 策略融合配对的轨迹,进一步改善缺失的边界框并稳定运动状态,这被称为正向和逆向顺序跟踪融合。此外,我们对过短的轨迹不运行下游模块。这些短轨迹的边界框,以及未被更新的冗余边界框,将直接合并到最终的自动标签中。
Object Data Preparation: 论文中给定一个对象轨迹,我们首先沿着三个维度略微放大被跟踪边界框的感兴趣区域(RoI),放大比例由参数 α 决定,用于补偿丰富的上下文信息。然后,取出位于这些放大边界框范围内的点。这部分取出的数据会作为后续阶段的输入使用。
Attribute-based Refining Module:
先前的以对象为中心的自动标注方法通常采用基于状态的策略来优化上游模块生成的proposal。这种方法不仅导致错误分类的传播,还导致了对象之间的潜在相似性被忽视。然而,作者观察到对于刚性对象而言,无论其运动状态如何,对象的几何形状在连续时间段内变化不大。此外,对象的运动状态通常呈现出规律的模式,并与相邻时刻具有强烈的一致性。基于这些观察,论文提出了一种新颖的方法,将传统的边界框回归任务分解为三个独立的模块,分别预测对象的几何属性、位置和置信度属性。
Geometry Refining Model:这部分模型由三个模块组成
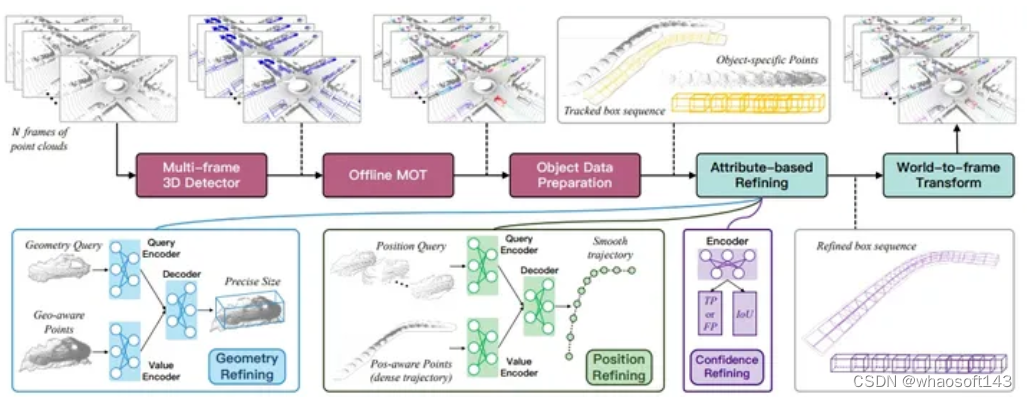
- Geometry-aware Points Generation:通过获取对象的多个视点,采用局部坐标变换操作,将对象点对齐到本地框坐标。然后,汇合来自不同帧的点,并随机采样形成一组点用于后续处理。
- Proposal-to-Point Encoding:强调了有效利用几何信息的重要性,通过对每个点进行proposal到点的编码,计算点与对象边界框表面之间的投影距离,将这些新生成的点特征作为更好的proposal信息表示。
- Attention-based Geometry Interaction across Views.:提出了一种初始化几何查询特征的方法,利用特定于对象的点。通过多头自注意力层和交叉关注机制,编码了丰富的上下文关系和特征依赖性,用于推理几何信息,最终通过前馈网络解码获得预测的对象大小。
Position Refining Model:
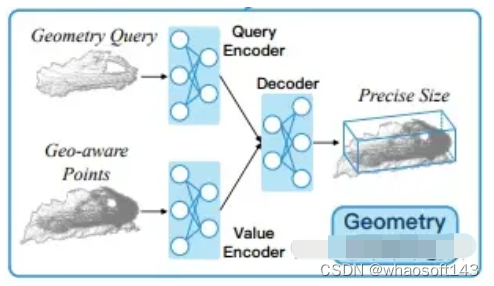
- Position-aware Points Generation:对于每个对象,通过从其跟踪的边界框序列中随机选择一个边界框的位置,创建一个新的局部坐标系。然后,将其他边界框以及相应的对象特定点转换到这个坐标系中。最后,从这些点中随机选择固定数量的点,形成位置感知的点特征。
- Attention-based Local-to-Global Position Interaction.:对于每个对象轨迹,使用结构化查询编码器生成位置查询,并提取整个对象轨迹的点特征。这些特征被用作后续计算的qkv。通过自注意力模块捕捉点与其他点之间的相对距离,并通过交叉注意力模块建模局部到全局的位置上下文关系。最终,预测了地面实际中心与相应初始中心在局部坐标系下的偏移,以及基于箱的朝向角度。
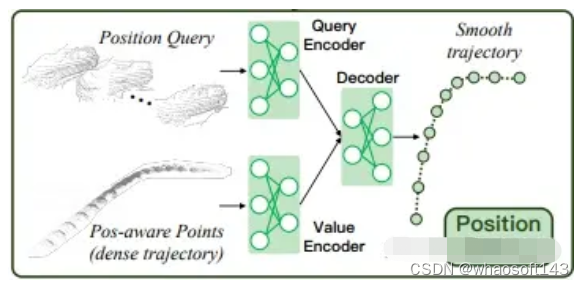
Confidence Refining Model: 为了解决生成的对象轨迹中存在与真实正样本相差较远的边界框的问题,引入了CRM模型,该模型由两个分支组成,分别用于优化置信度分数。
- classification branch:类似于传统的第二阶段目标检测器,该分支用于确定正样本(TPs)或假正样本(FPs),通过更新分数。将与地面真实框的IoU比率低于阈值 τl 的跟踪框分配为负标签,而IoU比率高于阈值 τh 的跟踪框则被视为正样本。其他框对分类目标不产生贡献。
- IoU regression branch:该分支用于预测对象在经过细化后应该具有的IoU。回归目标设置为地面真实框与由先前的几何细化模型(GRM)和位置细化模型(PRM)预测的细化框之间的IoU。
在训练期间,使用类似于GRM的编码器处理对象特定的点,提取的特征融合并输入到这两个分支中。通过随机采样预先划分的正样本和负样本的对象轨迹进行训练,以实现更好的收敛性。最终分数是两个分支分数的几何平均值。CRM的引入旨在提高检测模块生成的对象轨迹的质量,特别是在处理离真实正样本较远的边界框时。
实验结果:
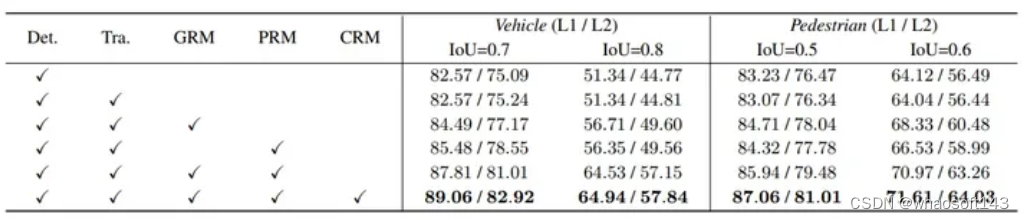
DetZero框架中每个组件在Waymo Open Dataset验证集上的效果。度量标准包括车辆和行人的L1和L2难度的3D平均精度(APH),分别使用标准IoU阈值(0.7和0.5)以及较高IoU阈值(0.8和0.6)。
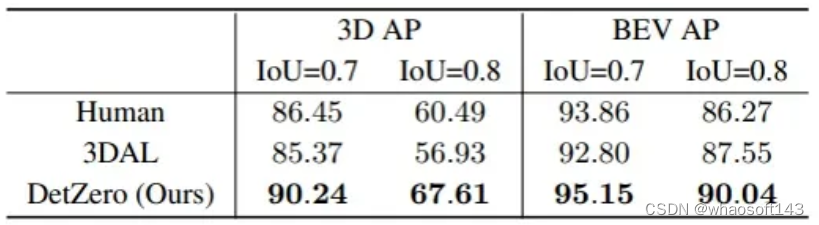
比较人工标签和自动标签。结果是在来自Waymo Open Dataset验证集的5个序列上,对于车辆(L1难度),在0.7和0.8的IoU阈值下的3D和BEV的平均精度(AP)。
2. [2303.06880] Uni3D: A Unified Baseline for Multi-dataset 3D Object Detection (arxiv.org)
简介:同样来自于PJLab的工作,3D的目标检测性能往往会根据特定Lidar的扫描形式,数据集偏差等原因造成跨数据集模型性能严重下降。受到这一观察的启发,作者提出了一个名为Uni3D的方法,它利用简单的数据级别校正操作和一个设计良好的语义级别耦合和重耦合模块,分别缓解了不可避免的数据级别和分类级别差异。
问题定义:论文中首先定义了多数据集推理问题为一个Multi-Domain Fusion (MDF)问题。目的是从多个带标签的域中训练一个统一的模型,以获取更具有普适性的表示。作者发现MDF在3D目标检测中的局限性主要表现在尝试将多个数据集合并为一个更大的数据集时,性能显著下降。直接将不同源数据集合并为一个整体数据集并不能提高检测器在跨数据集上的准确性。具体而言,直接在数据集级别进行整合不能有效提升3D场景级别数据集上检测器的准确性,反而可能由于不同数据集之间存在显著差异而导致特征学习的干扰。例如,对比了单数据集和直接合并的基准模型,对于3D场景级别数据集,直接进行数据集级别整合并不能提升检测器在跨数据集上的检测准确性。相反,由于不同数据集之间存在显著差异,检测器可能会受到特征学习干扰,从而导致性能下降。
在大量实验中,作者发现了导致性能下降的两个主要原因:
- 数据级别差异:
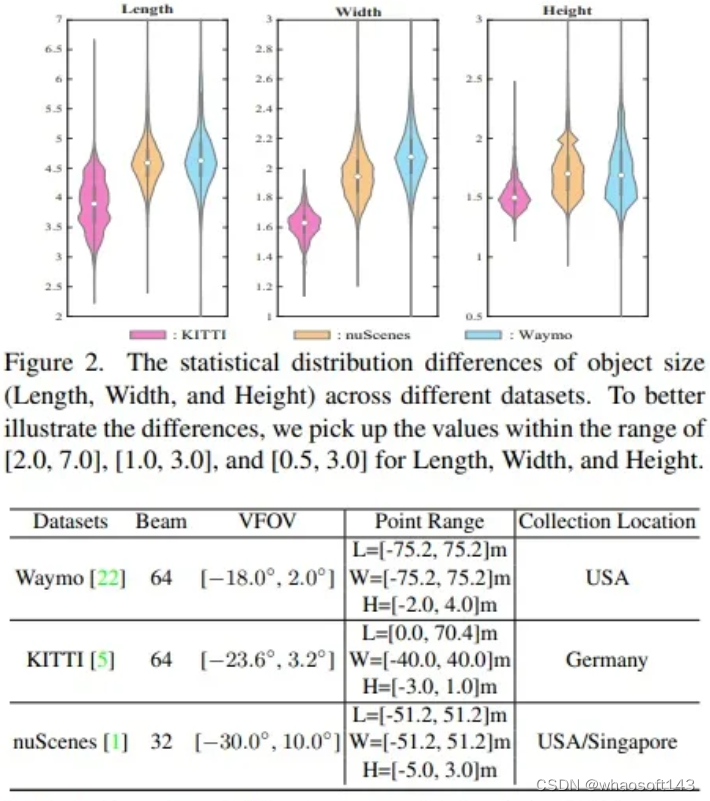
- 与由像素组成且具有一致值范围[0, 255]的2D自然图像不同,3D点云通常使用具有不同点云范围的不同传感器类型进行采集,导致数据集之间存在分布差异。
- 由于不同数据集具有不一致的点云范围,导致相同物体的感受野大小差异显著,因此点云范围的对齐被确定为实现多数据集3D目标检测的必要预处理步骤。
- 不同数据集的点云呈现出更多样化的数据分布,特别是由于这些数据集在不同城市和国家收集而导致实例大小差异较大。
- 分类级别差异:
- 不同自动驾驶制造商使用不一致的类别定义和注释粒度。
- 例如,Waymo将道路上的所有车辆(包括汽车和卡车)注释为一个统一的类别,即“Vehicle”;而nuScenes使用不同的层次结构和不同的粒度为不同的车辆(如“Car”、“Truck”和“Van”)进行注释。
- MDF任务需要考虑如何在不一致的分类标签空间下训练3D检测器,并有效地重用可以在不同数据集之间共享的领域无关知识。
主要方法:
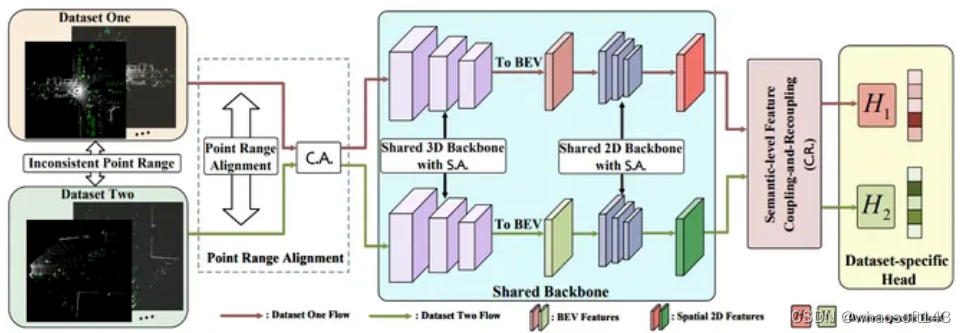
作者希望通过一系列方法,能够消减上述的Domain Gap,主要涵盖两个模块:
数据级别校正操作通过引入统计级别对齐(Statistic-level Alignment,S.A.)来解决多个数据集之间的数据级别差异。该操作涉及以下步骤:
- 统计信息获取:对于每个网络层,从每个数据集中获取数据集特定的通道均值 和方差
- 样本正则化:使用数据集特定的均值和方差对每个数据集的样本进行正则化,以确保输入数据在每个层次上都符合零均值和单变量。
- 转换步骤:类似于批标准化,应用转换步骤以还原表示能力。
通过这些步骤,数据级别校正操作可使模型更好地适应不同数据集之间的数据分布差异,特别是对于不同LiDAR类型和数据采集标准引起的问题。
Semantic-level Feature Coupling-and-Recoupling Module: 语义级别的特征耦合与重耦合模块(C.R.)通过两个关键操作实现多个数据集之间的特征共享:
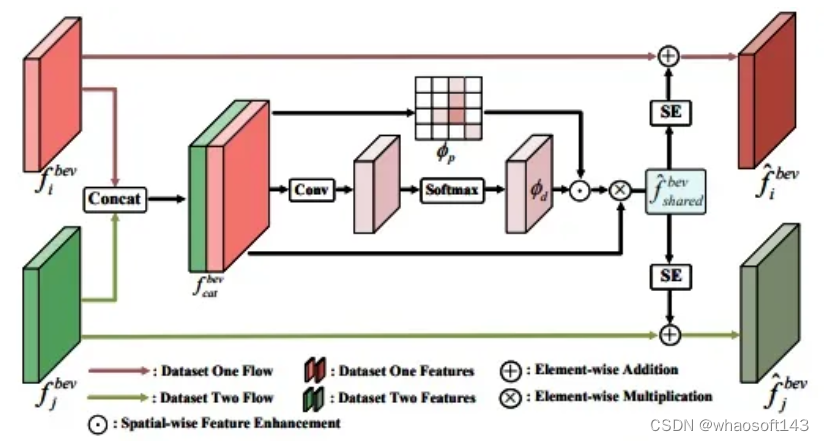
- 特征耦合:通过BEV(鸟瞰图)特征的通道维度将不同数据集的特征耦合在一起。使用前景感知和数据集级别的注意力掩码,学习数据集无关的表示。
- 特征重耦合:将共享的特征与先前与数据集相关的特征进行融合。通过通道-wise的重新缩放操作,将共享特征与数据集相关的特征相结合,以进一步提高模型在不同数据集上的泛化性能。
在训练阶段,为了保持模型的一致性,使用BEV特征复制方法。这两个操作共同确保了模型能够从多个数据集中学习到通用且可重复使用的特征表示。
Dataset-specific Detection Heads:为了解决不同数据集之间的分类级别差异,提出了特定于数据集的检测头。该方法假定已知3D数据源的先验知识,并为每个数据集使用不同的检测头及相应的检测损失函数。在训练阶段,通过整体的损失函数将不同数据集的损失叠加在一起,以共同训练模型。而在推理阶段,使用数据级校正操作以解决数据分布差异,并使用相应数据集的检测头生成最终的预测结果。这一设计使得模型能够有效地应对数据集间的分类标签不一致问题,提高了在不同数据集上的检测性能。
实验结果与总结:
这里列出最主要的实验结果:在Waymo和nuScenes数据集上联合训练的结果。作者在IoU阈值分别为0.7、0.5和0.5的情况下测试了Vehicle(Waymo上的车辆)、Pedestrain和Cyclist的结果,并利用了在Waymo上的LEVEL 1指标的AP和APH,以及在nuScenes上的40个召回位置上的APBEV和AP3D。最佳检测结果以粗体标记。由于页面限制,多个数据集的平均准确性在附录中报告。
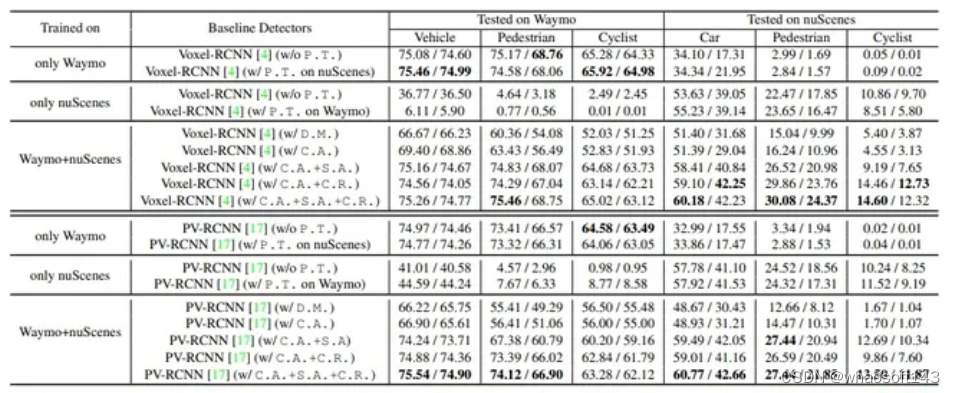
总结,Uni3D提供了一种解决昂贵数据采集成本的选择,允许在新场景的少量数据和先前完整数据集之间进行训练。实验证明,在nuScenes数据集上,Uni3D的检测准确度优于仅使用nuScenes数据的方法。其次,Uni3D显著提高了基线检测器的零样本学习能力,通过从多个数据集学习可泛化特征,使得零样本推断准确度得到显著提升。这种改善的原因可能在于Uni3D通过联合训练不同数据集,学习了数据集间的潜在变化,从而更好地识别未预见的领域。此外,Uni3D生成的预训练参数还可以增强现有领域自适应(UDA)模型的适应性。这一系列特性使Uni3D在实际应用中具有更大的灵活性和泛化性。
3. [2303.05886] Bi3D: Bi-domain Active Learning for Cross-domain 3D Object Detection (arxiv.org)
简介:同样来自于PJLab的工作,在Lidar base的3D检测任务上,基于无监督领域自适应的3D模型与使用完全注释的目标域进行训练的监督模型之间的性能差距仍然较大。为此,作者提出了一种双域主动学习方法,即Bi3D,以解决跨域3D目标检测任务。Bi3D首先开发了一种基于域感知的源采样策略,该策略从源域中识别类似目标域的样本,以避免模型受到不相关的源数据的干扰。
主要方法:
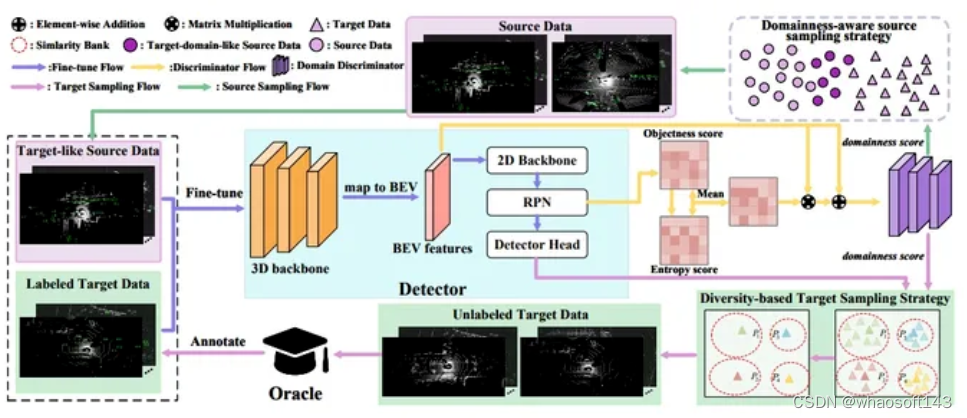
Bi3D 采用 PV-RCNN 作为基线,由基于域感知的源采样策略和基于多样性的目标采样策略组成。首先,通过学习的域感知分数选择类似于目标域的源数据,然后在选择的源域数据上对检测器进行微调。接下来,使用相似性库选择多样性和代表性的目标数据,然后由 Oracle 进行注释。最后,检测器在选择的源和目标数据上进行微调。
Foreground Region-aware Discriminator:为了度量源和目标样本的领域性,文章提出了一种前景区域感知鉴别器,并基于该鉴别器设计了一个双领域采样策略,以将预训练的3D检测器从源域调整到新的目标域。前景区域感知鉴别器通过生成场景级表示来解决点云数据的稀疏性问题,并通过结合目标性分数和不确定性分数来增强前景区域特征。该方法通过在源域选择类似目标域的数据,并在目标域选择多样性和代表性数据,以联合训练的方式帮助3D检测器更好地适应目标域。领域鉴别器使用了场景级的前景区域感知特征,并通过损失函数进行域性分类,从而引导模型学习源域和目标域之间的领域差异。
Domainness-aware Source Sampling Strategy:为了表示解决在目标域表示学习中源样本干扰的问题。策略的核心思想是通过领域鉴别器计算源数据的场景级别领域得分,然后根据得分选择类似目标域的源数据。通过对选定的源数据进行微调,该方法旨在增强模型对目标域的适应性,从而提高在目标域上的性能。这有助于检测器提取更准确的实例级特征,为选择更具信息量的目标数据奠定基础。
Diversity-based Target Sampling Strategy:为了提高3D检测器对目标域的适应性。首先,在领域感知的源采样策略的基础上,对源域数据进行微调,然后从目标域选择代表性的数据。由于相邻场景帧通常相似,传统主动学习方法可能选择具有较小类间差异的样本,因此引入了多样性策略。该策略利用置信度分数重新加权ROI实例级特征,以获得更准确的实例描述,并通过维护相似性库,基于两两相似性对未标记的目标数据进行聚类。最后,从每个更新的库中选择具有最高领域得分的未标记帧,形成用于手动注释的数据集。通过这种方式,提高了3D检测器对目标域的适应性,并能够选择更具多样性和代表性的目标数据。
实验结果与总结:
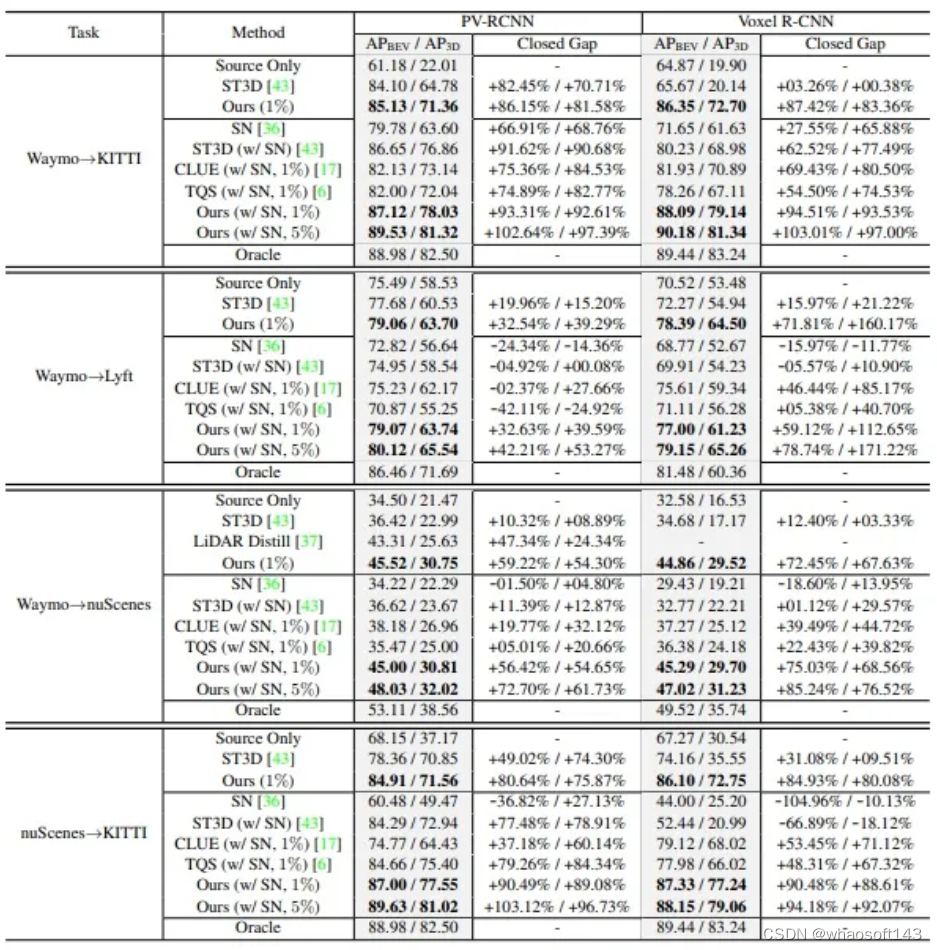
表格标注了了在1%和5%标注预算下,不同适应情景的结果。采用IoU(重叠联合)为0.7时,对汽车类别进行40个位置的召回率,并报告APBEV和AP3D。Source Only表示预训练的检测器直接在目标域上进行评估,Oracle表示使用完全注释的目标域获得的检测结果。Closed Gap表示各种方法在Source Only和Oracle结果之间的性能差距。最佳适应结果用粗体标出。
4. [2306.00612] AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset (arxiv.org)
简介:2022年图像的大规模预训练模型很好的改变了2D图像领域,但是在点云任务上感知模型能够从大规模点云数据集中学习,以获取统一的表示,从而在不同任务或基准测试上取得良好的结果任然是需要探索的。本文中来自PJLab的科学家首次致力于构建一个具有多样数据分布的大规模预训练点云数据集,同时从这样一个多样的预训练数据集中学习可泛化的表示。
主要方法:
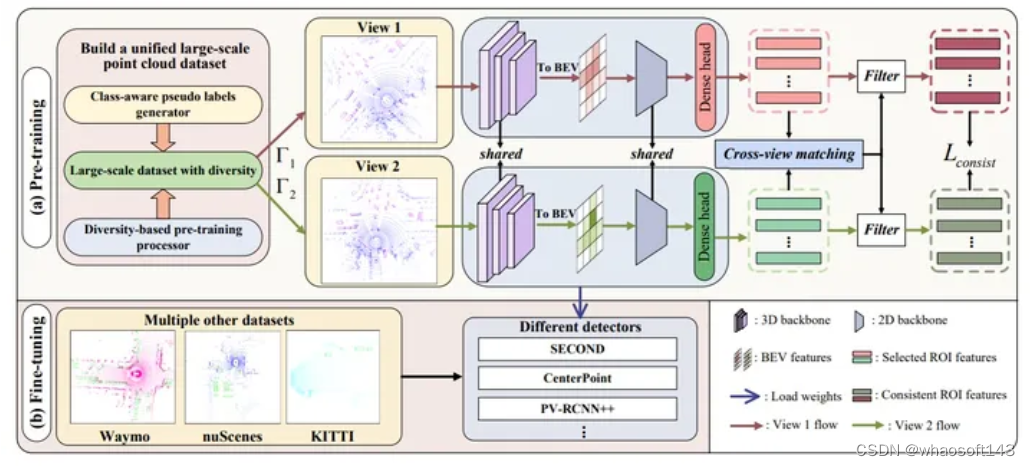
AD-PT主要包括大规模点云数据集准备过程和统一的面向自动驾驶的表示学习过程。为了启动预训练,首先开发了一个类别感知的伪标签生成器,用于生成DU的伪标签。然后,为了获得更多样化的样本,我们提出了一个基于多样性的预训练处理器。最后,为了在这些伪标记的数据上进行预训练,学习其用于自动驾驶目的的可泛化表示,设计了一种基于未知感知的实例学习结合一致性损失。
Large-scale Point Cloud Dataset Preparation
Class-aware Pseudo Labels Generator:
Class-aware Pseudo Labeling: 使用ONCE benchmark评估伪标签准确性,选择PV-RCNN++和CenterPoint等基准模型执行逐类的伪标签过程。类别感知的伪标签生成有助于优化目标类别的检测性能。
Semi-supervised Data Labeling:使用半监督学习方法(MeanTeacher)充分利用未标记的数据,提高伪标签的准确性。这进一步增强了逐类检测的能力,提高了性能。
Pseudo Labeling Threshold:为了避免标注大量的假阳性实例,设置了相对较高的伪标签置信度阈值。这有助于过滤掉预测分数较低的难样本,保持标注的准确性。
Diversity-based Pre-training Processor
数据的多样性对于预训练至关重要,因为高度多样化的数据可以极大提升模型的泛化能力。这个结论在3D预训练中也同样成立。然而,现有的数据集大多由同一LiDAR传感器在有限的地理区域内收集,这损害了数据的多样性。因此,我们尝试从LiDAR光束和物体大小两个方面增加多样性,并提出了一种点对光束的重采样和物体重新缩放的策略。
Data with More Beam-Diversity: Point-to-Beam Playback Re-sampling.:通过使用距离图像作为中间变量,对LiDAR点云进行上采样和下采样,以获取具有不同光束多样性的数据。通过将点云的坐标转换为倾角和方位角,并在距离图像上进行插值或采样,实现了LiDAR光束的重新采样。最终,通过将距离图像重新转换为点云,可以生成具有不同点密度的场景,从而提高了场景级别的多样性。
Data with More RoI-Diversity: Object Re-scaling: 在不同位置收集的不同3D数据集中存在的问题)例如物体大小具有不一致的分布,这个现象在上文中的Uni3D提出过)。由于单一数据集无法涵盖各种物体大小的分布,导致模型无法学习到统一的表示。为了克服这个问题,作者提出了一种对象重新缩放机制,该机制能够随机重新缩放每个对象的长度、宽度和高度。具体而言,通过将点转换到局部坐标,然后通过提供的缩放因子将点的坐标和边界框的大小相乘,最后将带有边界框的缩放点转换为自车坐标。这种重新缩放的方法使得生成的数据集包含了更多样化分布的对象大小,从而进一步增强了实例级点的多样性。
Learning Unified Representations under Large-scale Point Cloud Dataset
与2D或视觉-语言预训练数据集不同,伪数据集仅包含有限的类别标签(车辆、行人和骑行者)。同时,在为了获取准确的伪标注时,作者设定了较高的置信度阈值,这可能会忽略一些难以处理的实例。由于这些被忽略的实例可能在下游数据集中被视为感兴趣的类别,例如nuScenes数据集中的Barrier,因此它们在预训练过程中会被抑制。为了缓解这个问题,作者提出了将预训练视为一种开放集学习问题的新观点。与传统的旨在检测未知实例的开放集检测不同,作者的目标是在预训练阶段尽可能激活多个前景区域。为此,他们引入了一个双分支未知感知实例学习头,以防止将潜在的前景实例错误地视为背景部分。此外,使用一致性损失来确保计算的前景区域在两个分支之间具有一致性。
Overall Model Structure:设计的预训练模型包括一个体素特征提取器、一个具有稀疏卷积的3D骨干、一个2D骨干以及提出的头部。具体而言,给定点云论文首先通过不同的数据增强方法将点转换成不同的视图。然后,体素特征由3D Backbone提取并映射到BEV空间。之后,由2D Backbone生成的dense feature以被获取,最终,这些特征被输入到提出的head上。
Unknown-aware Instance Learning Head:受到以前的开放集检测工作的启发,作者考虑在具有相对高目标性分数的背景区域建议中的未知实例,这些实例在预训练阶段被忽略,但在下游任务中可能很重要。为了解决直接将这些未知实例视为前景实例会导致激活大量背景区域的问题,作者引入了一个双分支头作为committee,以确定哪些区域可以有效地表示为前景实例。具体操作包括选择具有最高分数的一组特征,并通过计算边界框中心之间的距离,确定这些特征的对应关系。一旦获得了来自不同输入视图的特征对应关系,这些未知实例将被更新为可以输入到其原始类别头的前景实例。这个设计旨在提高预训练模型对背景中可能重要的未知实例的识别能力。
Consistency Loss:在获得不同分支对应的激活特征后,使用一致性损失来确保这些对应特征的一致性。
主要实验结果:

在Waymo验证集上的实验结果表明,提出的方法在与先前的半监督预训练(SS-PT)方法的比较中表现出色。三个检测器在使用AD-PT初始化时都取得了最佳结果,甚至在使用较小的预训练数据集(例如在ONCE小数据集上的约100k帧)时,也超过了以前的SS-PT方法。与在Waymo 100%未标记训练集上进行预训练的SS-PT方法相比,这种改进尤其显著。此外,为了验证在少量样本上微调的有效性,作者进行了在Waymo训练集的3%(约5K帧)上的微调实验,结果显示借助预训练的先验知识,即使在数据量较小的情况下,微调也能取得比从头开始训练更好的性能。
至此,2023年主流几个Lidar 检测的大组的一些方案就都收集和总结完毕了,一共大概总结了25篇左右的文章,从最模型结构开始,到模型加速,再到数据有效性以及帧融合。算是交作业了!















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









