







PointNet: Deep Learning on Point Sets for 3D Classifification and Segmentation
PointNet网络由斯坦福大学(Stanford University)的祁芮中台(Charles Qi)博士等人在论文PointNet: Deep Learning on Point Sets for 3D Classifification and Segmentation中提出,论文首先提出了一种新型的处理点云数据的深度学习模型-PointNet,并验证了它能够用于点云数据的多种认知任务,如分类、语义分割和目标识别。本文是根据上述论文整理的学习笔记。
原文连接:https://arxiv.org/abs/1612.00593
abstract:Point cloud is an important type of geometric data structure. Due to its irregular format, most researchers transform such data to regular 3D voxel grids or collections of images. This, however, renders data unnecessarily voluminous and causes issues. In this paper, we design a novel type of neural network that directly consumes point clouds and well respects the permutation invariance of points in the input. Our network, named PointNet, provides a unified architecture for applications ranging from object classification, part segmentation, to scene semantic parsing. Though simple, PointNet is highly efficient and effective. Empirically, it shows strong performance on par or even better than state of the art. Theoretically, we provide analysis towards understanding of what the network has learnt and why the network is robust with respect to input perturbation and corruption.
1. What is PointCloud?
1.1 3D Representation

-
点云(PointCloud):由N个D维的点组成

-
网格(Mesh):由三角面片或正方形面片组成。

-
体素、栅格(Volumetric):由三维栅格将物体用0和1表征。


-
多角度的RGB图像或者RGB-D(深度图像)

1.2 Why we use PointCloid?
- 点云更接近于设备的原始表征(即雷达扫描物体直接产生点云)。
- 点云的表达方式更加简单,一个物体仅用一个N×D的矩阵表示,最简单的点云数据你只需要一个记事本,存储一些x,y,z坐标。
- 随着各种点云获取设备的迭代升级,我们获取点云数据相比以前变得更为容易。
- 真香!
1.3 Application
-
导航

-
地形测绘

-
道路建模
-
森林覆盖率调查
-
文物保护

1.4 Task
-
object classification:物体分类
-
parts segmentation:部件分割

-
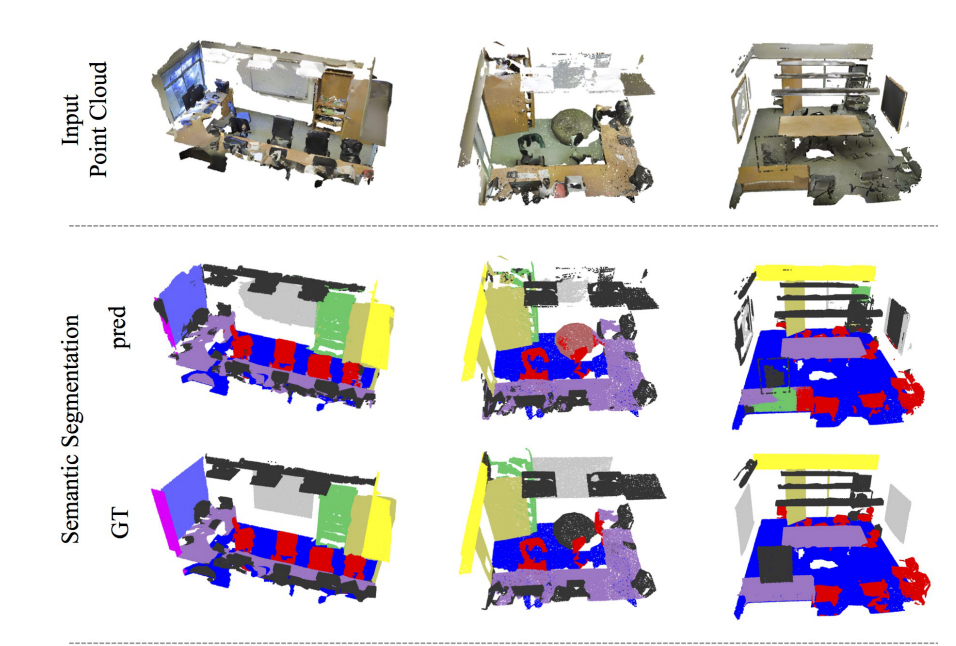
semantic segmentation:场景语义分割
-
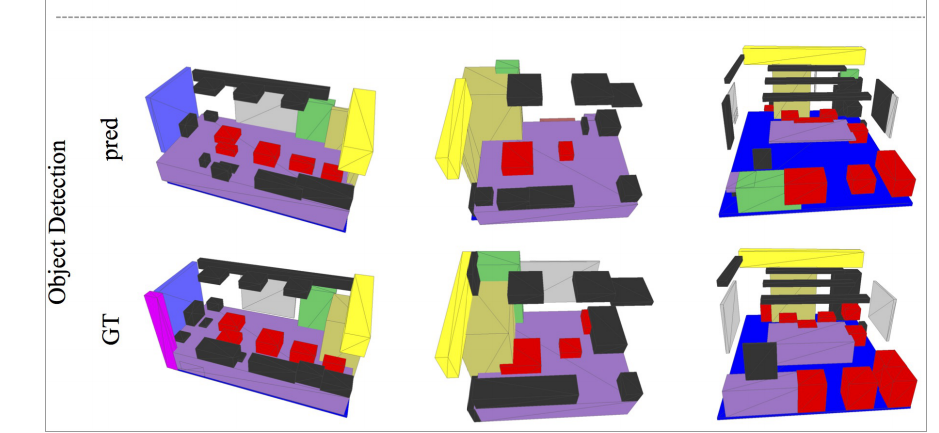
object detection:目标检测
1.5 Previous relevant work
在PointNet出现以前,点云上的深度学习模型大致分为三类:
- 基于3DCNN的体素模型:先将点云映射到体素空间上,在通过3DCNN进行分类或者分割。但是缺点是计算量受限制,目前最好的设备也大致只能处理32 × 32 × 32 的体素;另外由于体素网格的立方体性质,点云表面很多特征都没有办法被表述出来,因此模型效果差。
- 将点云映射到2D空间中利用CNN分类
- 利用传统的人工点云特征分类
- normal 法向量
- intensity 激光雷达的采样的时候一种特性强度信息的获取是激光扫描仪接受装置采集到的回波强度,此强度信息与目标 的表面材质、粗糙度、入射角方向,以及仪器的发射能量,激光波长有关
2. PointNet
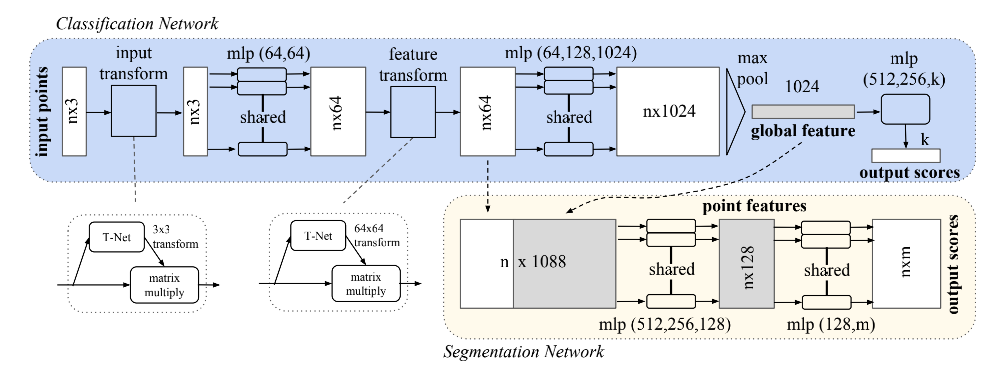
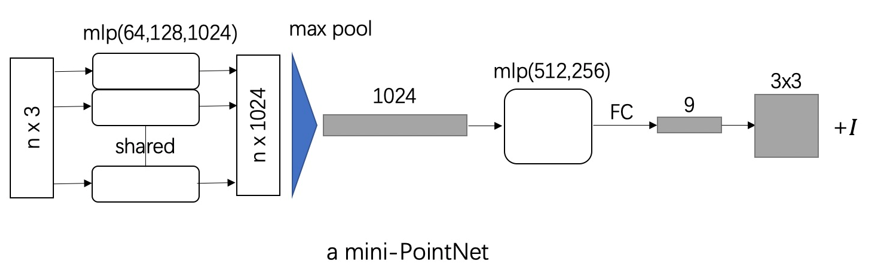
根据网络表示,对于每一个N × 3 的点云输入,网络先通过一个T-Net将其在空间上对齐(旋转到正面),再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的1 × 1024 的向量就是N个点云的全局特征。
如果做的是分类的问题,直接将这个全局特征再进过MLP去输出每一类的概率即可;但如果是分割问题,由于需要输出的是逐点的类别,因此其将全局特征拼接在了点云64维的逐点特征上,最后通过MLP,输出逐点的分类概率。
由于分割可以看成是每一个点分类,所以两个任务都是用的交叉熵作为Loss。
2.1 Feature
点云数据有三个重要的特性,在设计处理点云数据的网络时是绝对不能忽略的。
- Unordered(无序性,又称置换不变性)。即点云数据所表示的对象不并受数据排列的顺序影响,同一个物体得到的点云数据,我们将它打乱以后它仍可以表示原来那个物体。
- Interaction among points(点间联系)。即每一个点不是孤立存在,它们之间存在一定的联系。
- Invariance under transformations(旋转不变性)。即给予一个点云一个旋转,所有的x , y , z坐标都变了,但是代表的还是同一个物体。
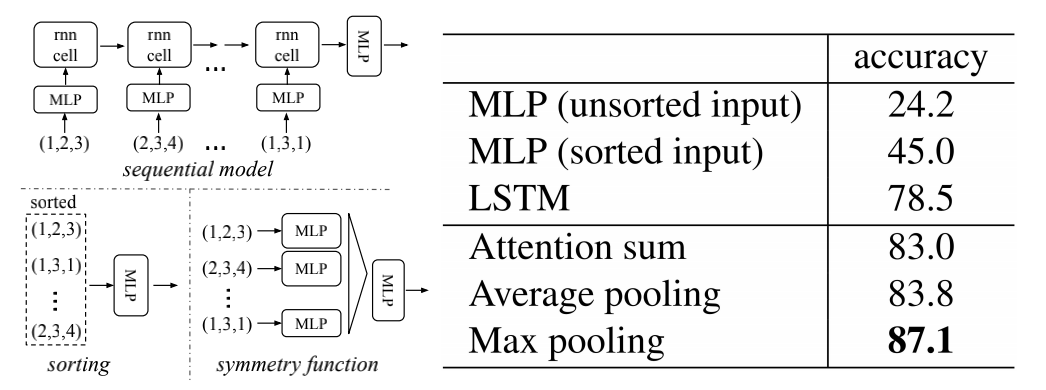
2.2 Symmetry Function for Unordered Input

可选方案:
-
直接将点云中的点以某种顺序输入(比如按照坐标轴大小排序)
很难找到一个稳定的排序方式
-
作为序列去训练一个RNN,即使这个序列是随机排布的,RNN也有能力学习到排布不变性。
RNN很难处理好成千上万长度的输入元素
-
使用一个简单的对称函数去聚集每个点的信息
f ( x 1 . x 2 , x 3 , . . . , x n ) ≡ f ( x π 1 , x π 2 , x π 3 , . . . . x π n ) , x i ∈ R f(x_1.x_2,x_3,...,x_n)\equiv f(x_{\pi1},x_{\pi2},x_{\pi3},....x_{\pi n}),x_i\in\mathbb{R} f(x1.x2,x3,...,xn)≡f(xπ1,xπ2,xπ3,....xπn),xi∈Rf ( { x 1 . x 2 , x 3 , . . . , x n } ) ≈ g ( h ( x 1 ) , h ( x 2 ) , h ( x 3 ) , . . . , h ( x n ) ) , x i ∈ R w h e r e f : 2 R N → R , h : R N → R K a n d g : R K × R K × ⋅ ⋅ ⋅ × R K × R K ⏟ N → R i s a s y m m e t r i c f u n c t i o n f(\{x_1.x_2,x_3,...,x_n\})\approx g(h(x_1),h(x_2),h(x_3),...,h(x_n)),x_i\in\mathbb{R}\\ \\ where\quad f:2^{\mathbb{R}^N}\to\mathbb R,\quad h:\mathbb{R}^N\to\mathbb{R}^K\quad and\quad \\g:\underbrace {\mathbb{R}^K \times \mathbb{R}^K \times \cdot\cdot\cdot \times\mathbb{R}^K \times \mathbb{R}^K}_N\to\mathbb R\quad is\quad a\quad symmetric\quad function f({x1.x2,x3,...,xn})≈g(h(x1),h(x2),h(x3),...,h(xn)),xi∈Rwheref:2RN→R,h:RN→RKandg:N RK×RK×⋅⋅⋅×RK×RK→Risasymmetricfunction
左边 f f f是目标函数,右边 g g g是我们期望设计的对称函数。由上公式可以看出,基本思路就是对各个元素(即点云中的各个点)使用 h h h分别处理,再送入对称函数 g g g中处理,以实现排列不变性。
在实现中 h h h就是MLP, g g g 就是max pooling

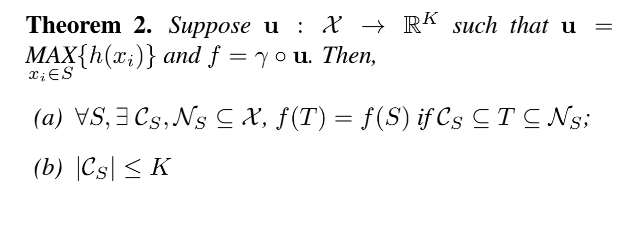
定理2(a)说明对于任何输入数据集S,都存在一个最小集Cs和一个最大集Ns,使得对Cs和Ns之间的任何集合T,其网络输出都和S一样。这也就是说,模型对输入数据在有噪声(引入额外的数据点,趋于Ns)和有数据损坏(缺少数据点,趋于Cs)的情况都是鲁棒的。定理2(b)说明了最小集Cs的数据多少由maxpooling操作输出数据的维度K给出上界。换个角度来讲,PointNet能够总结出表示某类物体形状的关键点,基于这些关键点PointNet能够判别物体的类别。这样的能力决定了PointNet对噪声和数据缺失的鲁棒性。如图所示,作者通过实验列出了PointNet学习到的以下几个物体的关键点。
2.3 Joint Alignment Network
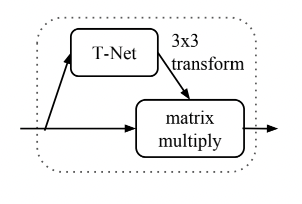
引入了一个T-Net网络去学习点云的旋转,将物体校准。由图可以看出,只需要对一个N × D 的点云矩阵乘以一个D × D的旋转矩阵即可。特别注意的是在特征空间的校准中,由于特征空间中的变换矩阵比空间变换矩阵的维数要高得多,这大大增加了优化的难度 。因此在 softmax training loss(实际使用的是loss是分类中常用的交叉熵)中加入了一个正则项,希望其尽可能接近于一个正交矩阵。
L
r
e
g
=
∣
∣
I
−
A
A
T
∣
∣
F
2
L_{reg}=||I-AA^T||^2_F
Lreg=∣∣I−AAT∣∣F2
其中A为一个小网络预测的特征对齐矩阵。需要一个正交变换不会丢失输入中的信息。添加正则化优化后,模型更加稳定,取得更好的性能。
2.4 Local and Global Information Aggregation
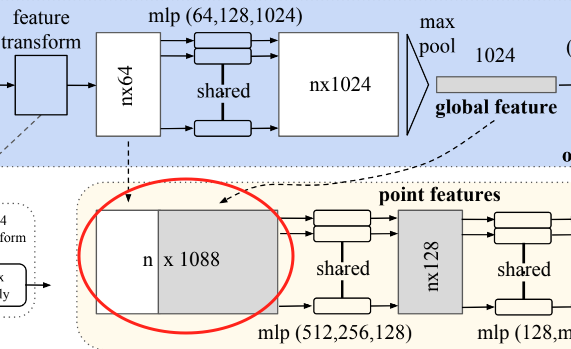
采用拼接的办法,将局部和全局特征融合。
对于分割任务,设计point-wise feature
因此分割网络和分类网络设计局部略有不同,分割网络添加了每个点的local和global特征的拼接过程,以此得到同时对局部信息和全局信息感知的point-wise特征,提升表征效果。
2.5 Experiment
DataSet & Task
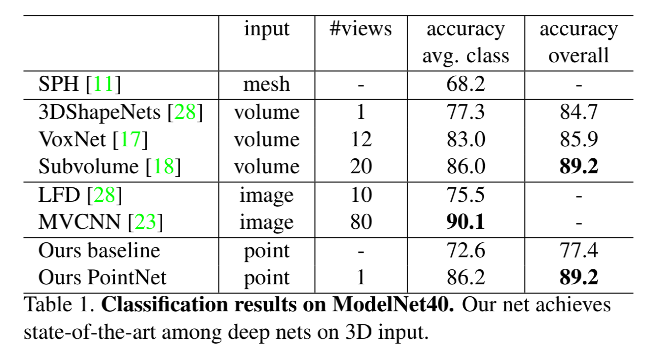
分类:ModelNet40
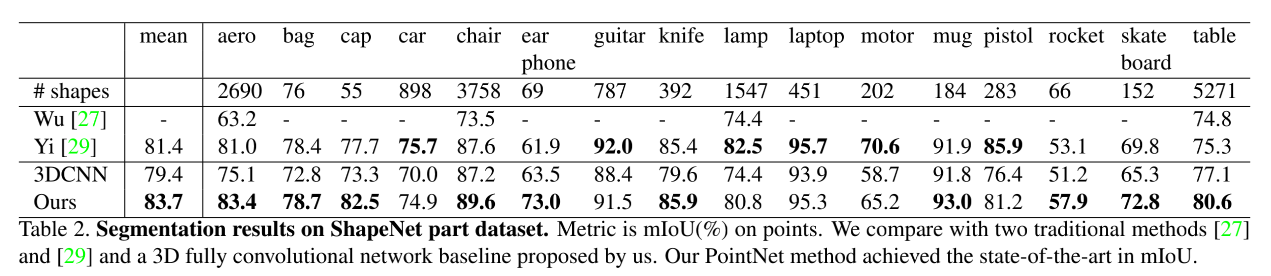
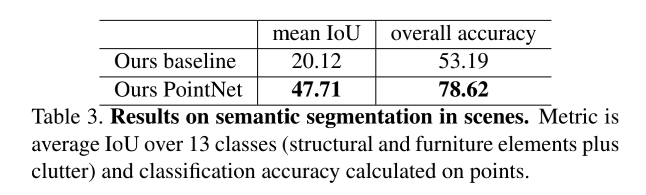
分割:ShapeNet Part dataset 、Stanford 3D semantic parsing dataset
Result
classification(分类):
parts segmentation(部件分割):
semantic segmentation(场景语义分割 ):
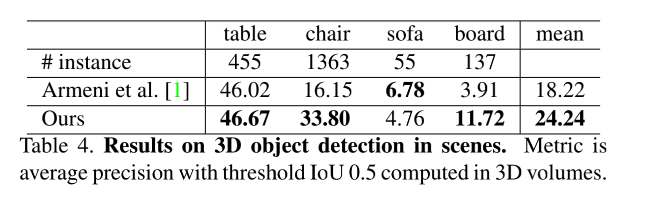
object detection(目标检测):
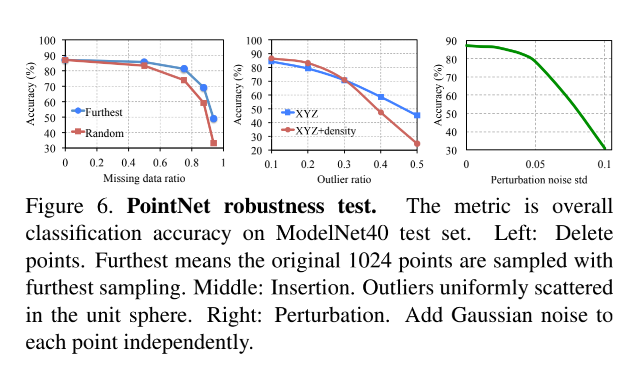
Robustness
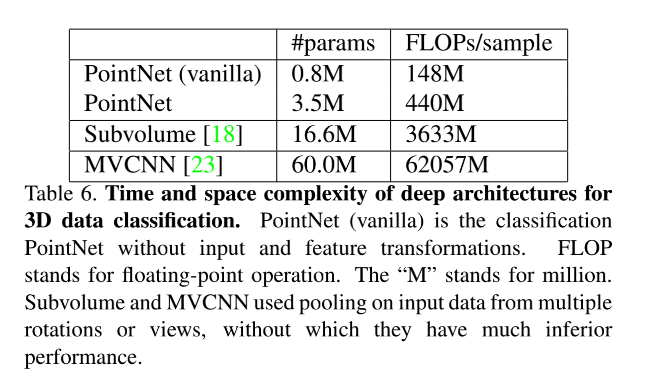
在PointNet出现以前,点云处理这一块一直没有一统江湖的最佳基本结构。不像图像有CNN,NPL有Transformer。PointNet开了个头,对过去的点云处理方法来说算是一个降维打击,从此以后深度学习方法也可以直接处理点云。
PointNet网络结构看似简单,实则想设计出这样一个网络并不容易。Vanilla
以点云为代表的3D领域必然是未来一个热门领域,事实上点云在国外的研究热度也在最近几年逐渐升温。不过国内的研究学者还很少,也没有有关中文社区,想在国内找资料学习点云有关方向较为困难,国外资料相对于国内较多,然而对于多数外语水平一般的初学者来说,这无疑会增加学习周期和学习成本。

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









