









整理不易,希望留个赞再走哦!!
学习路线

这个图描述的比较清晰,蓝框里是整个强化学习的一些概念基础了,橙色是一些学习方法,可以针对性的选择一些,废话不多说,接下来就按照这个路线图展开。
1. 马尔可夫链
马尔科夫链:用来描述智能体和环境互动的过程
- 智能体在环境中,观察到状态(S);
- 状态(S)被输入到智能体,智能体经过计算,选择动作(A);
- 动作(A)使智能体进入另外一个状态(S),并返回奖励®给智能体。
- 智能体根据返回,调整自己的策略。 重复以上步骤,一步一步创造马尔科夫链。
- 马尔可夫链包含三要素:state,action,reward
2. V值和Q值


接下来是V值和Q值,从某个状态,按照策略 ,走到最终状态很多很多次;最终获得奖励总和的平均值,就是V值。从某个状态选取动作A,走到最终状态很多很多次;最终获得奖励总和的平均值,就是Q值。这就是Q值,这两个值有什么区别呢?


一个状态的V值,就是这个状态下的所有动作的Q值,在策略下的期望。


Q就是子节点的V的期望!但要注意,需要把R计算在内。

V值和Q值之后我们再来了解一下蒙特卡罗(MC)和时序差分(TD)。MC和TD都是估算V值的一种方式,不同点是蒙地卡罗会让智能体从某个状态S出发,直到最终状态,然后回过头来给每个节点标记这次的价值G。
G代表了某次,智能体在这个节点的价值。
而时序差分是一步一回头。用下一步的估值,估算当前状态的估值。
于是得到S - A - G 的数据。这里的G就是对于状态S,选择了A的评分。也就是说, - 如果G值正数,那么表明选择A是正确的,我们希望神经网络输出A的概率增加。(鼓励) - 如果G是负数,那么证明这个选择不正确,我们希望神经网络输出A概率减少。(惩罚) - 而G值的大小,就相当于鼓励和惩罚的力度了。
3. Q-Learning和SARSA
接下来我们开始正式了解一些常用的强化学习。首先是Q-learning和SARSA,这两种方法的主要思路在于,用同一个策略下产生的动作A的Q值替代V(S_(t+1))。

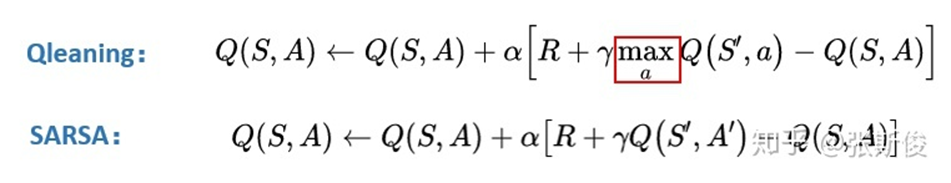
可以看到他们俩的更新公式长得很像,只差一个max,SARSA的想法是,用同一个策略下产生的动作A的Q值替代V(St+1)。Q-learning用所有动作的Q值的最大值替代V(St+1)。
4. 深度强化学习 DQN
开始进入深度强化学习的部分了。为什么深度强化学习这么强,是因为深度强化学习增加了一个很强的武器——深度神经网络。
深度神经网络就是一个函数。函数其实也很简单,就是描述两个东西的对应关系。F(x) = y , 描述的就是x和y之间的关系。
以前的函数,需要我们去精心设计的,要设计,就要描述其中的关系。但有些东西我们明明知道他们有关系,但又不好描述清楚。
例如,手写数字识别,一个正常人写的数字8,我们人类都能认出来。但我们却描述不出来,我们知道是两个圈是8,但有些人的圈明明不闭合,我们也认得出是8…

但深度神经网络这个工具就能自己学会这些关系。
我们先设一个Magic’(X),其中的X就是输入的图片;计算结果是各个数字的概率。这个判断一开始通常都是错的,但没关系,我们会慢慢纠正它。
纠正就需要有一个目标,没有目标就没有对错了。这里的目标是我们人类给他们标注的,告诉Magic’:这是数字8。
目标和现实的输出总是有一段距离的,这段距离我们称为损失(loss).
我们调整我们Magic’函数的参数,让损失最小化。也就是说,离目标越来越近。
这就是深度强化学习的主要思想。
Q-learning有一个问题:只能解决格子类型离散型状态问题,对连续型状态束手无策。
这是因为Q-learning在实做的时候用的是Q表格(Q-table)。表格这玩意儿注定就只能存离散的东西。但我们刚才说的神经网络,正好就能解决这个问题,因为神经网络是个函数,可以处理连续型的问题。两者一拍即合!DQN相当于Q-learning的Qtable换成深度神经网络,相当于用一根曲线穿过离散状态下所有的点。


Policy Gradient(PG)
这个时候我们发现,我们前面的方法都是通过Q值和V值来计算,也就是基于价值value。而PG用了一种全新的思路,用蒙特卡罗方法的G值来更新网络。也就是说,PG会让智能体一直走到最后,然后回溯计算G值。PG的思路比较新颖,但是缺点在于实际效果不太稳定,在某些环境下学习比较困难。所以我们希望用TD来代替MC,我们可不可以把PG和DQN结合起来呢?

如果你想详细学习这个模型,可以移步其他博客。当然也是我学习的过程中整理出来的,会有用别人图的情况,如果你觉得侵权可以随时跟我说我删帖。如果你想问原贴在哪也欢迎私信我哦!以下同理
PG原理:【强化学习】Policy Gradient原理
PG代码及注释:【强化学习】Policy Gradients代码注释版本
Actor-Critic
这个就是actor-critic思路的来源,AC准确来说是PG的TD版本。通过定义两个网络,actor网络和Critic网络。Critic网络负责估算Q值 Actor网络负责估算策略。AC方法相对PG来说具有更好的性能,同时也解决了连续动作空间的问题。

AC原理:【强化学习】Actor Critic原理
AC代码及注释:【强化学习】AC注释版本
A3C原理:【强化学习】A3C原理
A3C代码及注释:【强化学习】A3C代码注释版本
PPO
下一种PPO,这是目前使用最广泛的一种强化学习方法。PPO基于Actor-Critic框架,因此PPO也有两个网络,这是因为AC可以解决连续动作空间这一优点。PPO在AC的基础上主要做了两点改进,一个是延展的AC的TD(0),变成TD(N)的N步更新。第二点是在AC的基础上使用重要性采样,将在线策略变成了离线策略。

PPO代码及注释:【强化学习】PPO代码注释版本
DDPG
DDPG就是为了解决DQN连续控制型问题而产生的。
DQN的神经网络就相当于用线把Q-table的状态连起来。那到DDPG中,Critic网络就相当于我们用一张布,把整个Q-table的所有柱子都覆盖了。


DDPG的Actor接受输入一个状态,就相当于在这块布切沿着这个状态S切一个面。Actor的任务就是希望在这个面上找寻最高点,也就是最大的Q值。
所以和AC不同,DDPG预估的是Q而不是V。而DDPG的Actor采用的是梯度上升的方式找出最大值。而AC和PPO的Actor采用带权重更新的方法。
DDPG起源于DQN,是DQN解决连续控制问题的一个解决方法。
而DQN有一个众所周知的问题,就是Q值会被高估。这是因为我们用argmaxQ(s’)去代替V(s’),去评估Q(s)。当我们每一步都这样做的时候,很容易就会出现高估Q值的情况。
而这个问题也会出现在DDPG中。而要解决这个问题的思路,也在DQN的优化版本中。相信大家很快就明白,就是double DQN。
TD3
在TD3中,我们可以用了两套网络估算Q值,相对较小的那个作为我们更新的目标。这就是TD3的基本思路。


我们可以再次回到我们关于“布”的想象。
在DDPG中,计算target的时候,我们输入时s_和a_,获得q,也就是这块布上的一点A。通过估算target估算另外一点s,a,也就是布上的另外一点B的Q值。
在TD3中,计算target时候,输入s_到actor输出a后,给a加上噪音,让a在一定范围内随机。这又什么好处呢。
好处就是,当更新多次的时候,就相当于用A点附近的一小部分范围(准确来说是在s_这条线上的一定范围)的去估算B,这样可以让B点的估计更准确,更健壮。
















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









