







一、PG回顾
1、对于离散动作,策略搜索使用神经网络来参数化随机策略中的动作概率,网络的输入是智能体的当前状态,网络输出为当前所有动作的概率,该网络是一种分类网络。网络训练使用数据为一个episode数据(s,a,r). 参考https://blog.csdn.net/weixin_40493501/article/details/110384894
2、对于连续性动作来说,一般使用随机高斯策略,网络的输入是智能体当前状态,网络的输出的高斯策略的均值和标准差,网络是一个拟合网络。
无论是连续动作还是离散动作,在使用PG时,必须先弄清下面公式【主要推导上一个文章已给出】,离散动作和连续动作最大的不同就在于。
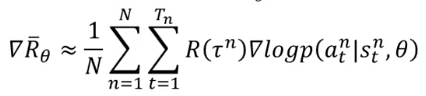
在离散动作的网络设计中,输入是状态,输出可以看做是每个动作的概率,与动作标签进行对比,尽量使动作概率的输出接近标签。
在连续动作中,将看成是动作的分布,例如高斯分布
二、连续动作PG算法网络

输入层为状态,连续动作空间的输出层不再是动作,二是动作描述的一种分布参数,利用输出的参数可以得到动作的分布,可以根据分布来选择动作。
【需要补充具体的计算过程】
三、代码实现
import tensorflow as tf
import numpy as np
import gym
import matplotlib.pyplot as plt
RENDER = False
'''
连续动作
使用的是高斯策略,用神经网络参数化高斯分布的均值和方差
状态空间为 2
动作空间为 1 其取值范围在[-2,2]之间
注意其误差的构建
'''
#利用当前策略进行采样,产生数据
class Sample():
def __init__(self,env, policy_net):
s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4022
4022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









