







朱松纯UCLA实验室最牛的PHD应该是朱毅鑫了,UCLA实验室demos中有43个挂了他的名字。
而他主页中说道,如想跟随他做研究,发邮件前最好看如下3篇论文:
- 《A Stochastic Grammar of Images》
- 《A TALE OF THREE PROBABILISTIC FAMILIES: DISCRIMINATIVE, DESCRIPTIVE AND GENERATIVE MODELS》
- 《“暗”,不止于“深”——迈向认知智能与类人常识的范式转换》
第1篇是朱松纯2016年的专著104页,既往生涯研究的综述性著作。
第2篇是偏数学理论性质。
第3篇是朱松纯团队进来研究成果的综述性介绍。(之前已读)
本篇文章以撰写读后感形式对《A Stochastic Grammar of Images》中每一个小结做个自己的理解。
读前目标:
-
想干什么事?
-
能解决什么问题?
-
目前成了什么事?
-
为什么想到可以这样设计?
-
如何实现的?
-
能达到什么效果?
-
与深度学习的异同?
答:
4:人类语言(由词汇+语法构成)可以精确描绘和解释、分解一幅图像。作者也希望用这种方式让计算机通过分解来理解图像。
摘要
这篇探索性的论文寻求一种随机和上下文敏感的图像语法。
语法要实现以下四个目标,从而成为大量宾语类别的表征、学习和识别的统一框架。
(i)语法既表示终端节点和非终端节点对场景、对象、部件、原语和像素的分层分解,又通过节点之间的水平连接表示空间关系和功能关系的上下文。它将每个对象类别表示为语法生成的所有可能有效配置的集合。
(ii)语法体现在一个简单的与或图形表示,其中每个或节点指向可选的子配置,和节点分解成许多组件。该表示支持贝叶斯框架下的自顶向下/自底向上的图像解析递归过程,方便了复杂度的扩大。给定一个输入图像,图像解析任务动态构造一个最可能的解析图作为输出解释,在Or节点上做出选择之后,该解析图是与或图的子图。
(iii)在此和或图表示上定义概率模型,以说明物体和部件的自然发生频率及其关系。这个模型从一个相对较小的训练集每类别,然后采样合成大量的配置覆盖小说在测试对象实例集。这种泛化功能主要是缺少有识别力的机器学习方法,可以很大程度上提高识别性能实验。
(iv)为了填补符号和原始信号之间众所周知的语义鸿沟,该语法包括一系列可视化词典,并通过图形组成将其组织起来。在底层,字典是一组图像原语,每个图像原语都有许多锚点,这些锚点带有开放的键,可以与其他原语链接。这些原语可以组合成越来越大的部件和对象的图形结构。在推断局部原语时的歧义应该通过使用较大结构的自顶向下计算来解决。最后这些原语形成一个原始草图表示,该表示将生成输入图像,每个像素都有解释。
该建议文法整合了文献中三个突出的表示法:合成的随机文法,上下文的马尔科夫(或图形)模型,和基元的稀疏编码(小波)。它还结合了视觉文献中基于结构和基于外观的方法。最后,本文通过三个案例来说明所提出的语法。
1 介绍
1.1 图像语法的冬眠和苏醒
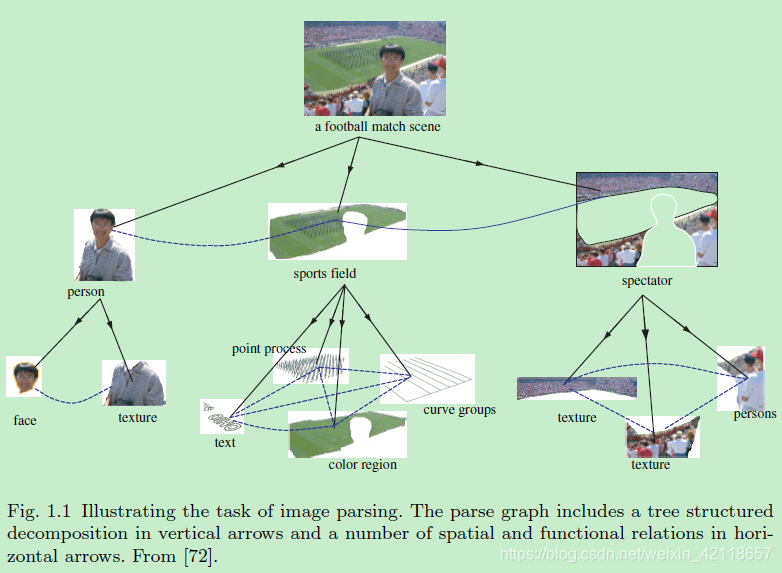
图1.1说明了图像解析的任务。解析图包括一个树结构的分解在垂直箭头和一些空间和函数关系在水平箭头。
总结:
介绍图像语法的诞生、当初陷入停滞的原因(内存等),以及复苏原因:
- (i)一个一致的数学和统计框架来整合各种图像模型,如马尔可夫(图形)模型[90]、稀疏编码[56]、随机上下文自由文法[10]。
- (ii)图像原语连接符号与像素的更逼真的外观模型。
- (iii)更强大的算法,包括判别分类和生成方法,如数据驱动的Markov China Monte Carlo (DDMCMC)[73]。
- (iv)大量的真实训练和测试图像[87]。
1.2目标
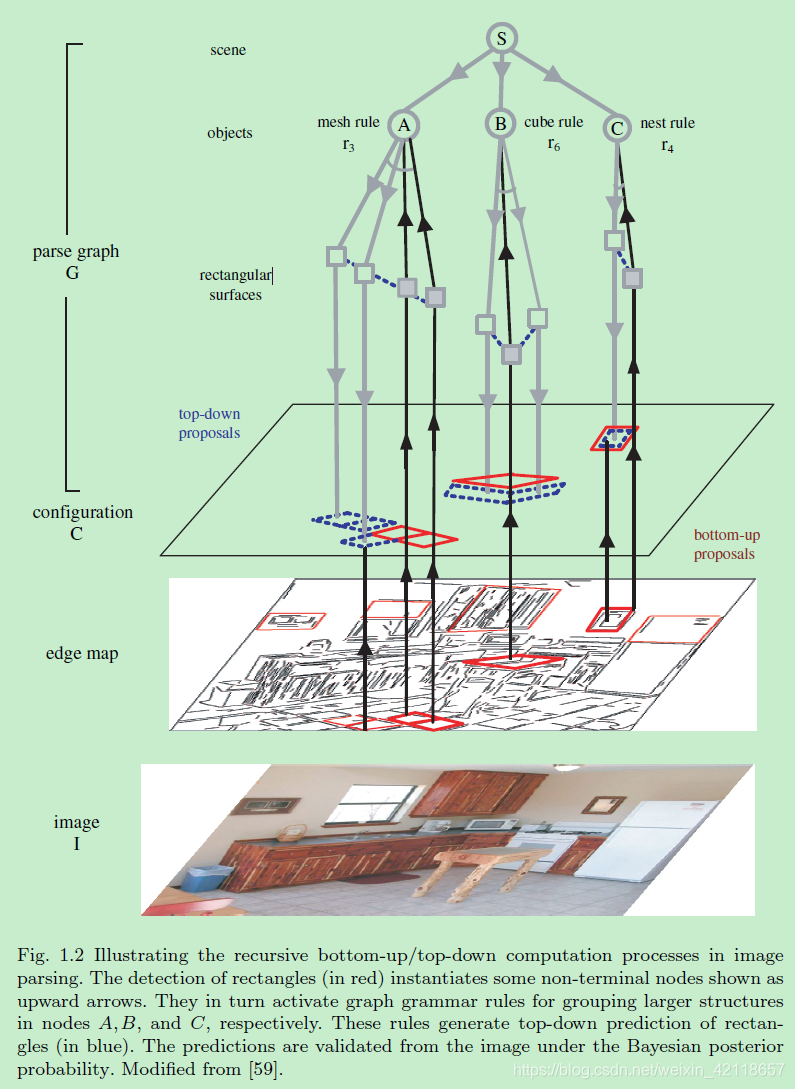
图1.2说明了图像解析中自底向上/自顶向下的递归计算过程。矩形(红色)的检测实例化了一些非终端节点,如向上的箭头所示。它们依次激活图形语法规则,分别用于分组节点A、节点B和节点C中的较大结构。这些规则生成自顶向下的矩形预测(蓝色部分)。在贝叶斯后验概率下,从图像上验证了预测结果。
图1.2显示了在一个时间步骤中正在构建的解析图。这个简单的语法是我们在后面部分使用一个原语的案例研究之一:投影到图像平面上的矩形表面。语法规则代表各种组织,如网格、线性、嵌套、立方结构中的矩形的对齐。在厨房场景中,四个矩形(红色)通过自下而上的过程被接受,它们分别激活了由非终端节点A、B、C所代表的生产规则。然后在自上而下的搜索中预测一些候选人(蓝色部分)。向上的实线箭头表示自底向上的绑定,而向下的箭头表示自顶向下的预测。从后面的图9.5的ROC曲线可以看出,自顶向下的预测大大提高了矩形的识别率,因为部分矩形由于遮挡和严重的图像退化,只能通过自顶向下的处理产生幻觉。
图像语法要实现以下4个目标:
目标1:视觉知识表示和对象分类的共同框架。
目标2:可伸缩的、自顶向下/自底向上递归计算。
目标3:小样本学习和推广。
目标4:映射视觉词汇以填补语义空白。
1.3 图像语法概述
介绍图像语法的基本概念,主要是分两部分:
- 表示和数据结构。
- 图像标注数据集的语法学习,以及学习和计算问题。
1.3.1 表示和数据结构
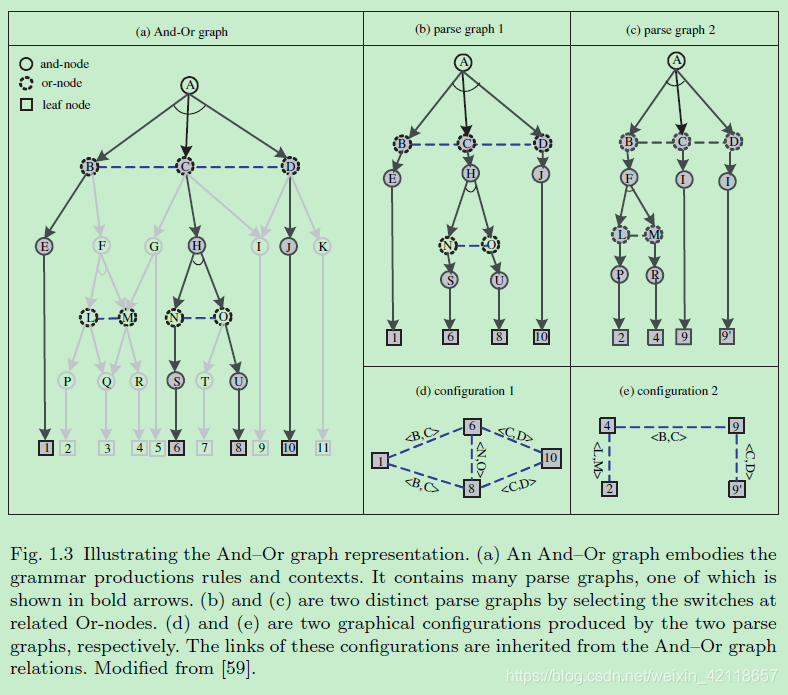
图1.3说明与或图表示。(a)和或图体现语法生成规则和上下文。它包含许多解析图,其中一个以粗体箭头显示。(b)和(c)通过选择相关or节点上的开关是两个不同的解析图。(d)和(e)分别是由两个解析图生成的两个图形配置。这些配置的链接继承自和或图关系。
上图解释:
- 一个与或图
- 图1.3(a)显示了一个和或图的简单示例。与或图包括三种类型的节点:and节点(实心圆)、or节点(虚线圆)和leaf终端节点(正方形)。
- And-node表示将实体分解为各个部分。它对应于语法规则,例如:A→ BCD, H → NO。and -node的子节点之间的水平链接表示关系和约束。
- or-node充当“开关”表示可选子结构,表示不同层次的分类标签,如场景类别、对象类别、部件等。它与生产规则相对应,如:B → E | F, C → G | H | I.
- 由于这种递归定义,可以将许多对象或场景类别的与或图合并为更大的图。理论上,所有场景和对象类别都可以用一个巨大的与或图形来表示,自然语言就是这样。与或图中的节点可能有共同的部件,例如,汽车和卡车都有橡胶车轮作为部件,时钟和墙上画像都有一个框子。
- 一个解析图
- 如图1.1所示,是对特定图像的层次化生成解读。解析图是从解析树扩展而来的,通常在自然或编程语言中使用,通过在节点之间添加一些关系(显示为边链接)。通过选择相关Or节点上的开关或分类标签,可以从And或图派生解析图。图1.3(b)和1.3(c)是来自图1.3(a)中的与或图的解析图的两个实例。两个节点共享的部分可能有不同的实例,例如,节点I同时是节点C和节点d的子节点,因此我们有两个节点9的实例。
- 配置
- 配置是通过连接图像平面中原语的开放键而形成的平面属性图。图1.3(d)和图1.3(e)分别是由图1.3(b)和图1.3(c)中的解析图生成的两种配置。直观地说,当解析图折叠时,它会生成一个平面配置。配置从其祖先节点继承关系,可以看作具有可重构邻域的马尔可夫网络(或可变形模板[19])。我们引入混合随机场模型[20]来表示构型。混合随机场扩展了传统的马尔可夫随机场模型,允许地址变量,并处理由遮挡引起的非局部连接。在这个生成模型中,一个配置对应于一个原始草图[31]。
- 视觉词典
- 由于可缩放特性,终端节点可以出现在And-or图的所有级别上。每个终端节点都从某个集合获取实例,该集合称为字典,包含各种复杂的图像补丁。集合中的元素可以通过变量索引,如其类型、几何变换、变形、外观变化等。每个补片都用锚点和开放的键来与其他补片连接。
- 语法的语言是由语法生成的所有可能的有效配置的集合。在随机语法中,每种构型都与一个概率有关。由于And或图是有向递归的,任何节点A下面的子图都可以被认为是节点A表示的概念的子语法。因此节点A的子语言是根在A的And或图生成的所有有效配置的集合。例如,如果A是一个对象类别,比如car,那么该子语言定义了car的所有有效配置。在现有的情况下,终端节点的子语言只包含原子配置,因此称为字典。
1.3.2 数据集来源和训练概述
概述随机图像语法的学习和计算问题。
一个最重要的问题是:如何构建这个语法?数据集在哪里?为学习和训练收集数据集可能比学习任务本身更具挑战性。
数据集从哪来?
2005年在中国成立了一个数据集建设团队,每个图像被制作为一个解析图。共50万幅图像,280个类别。
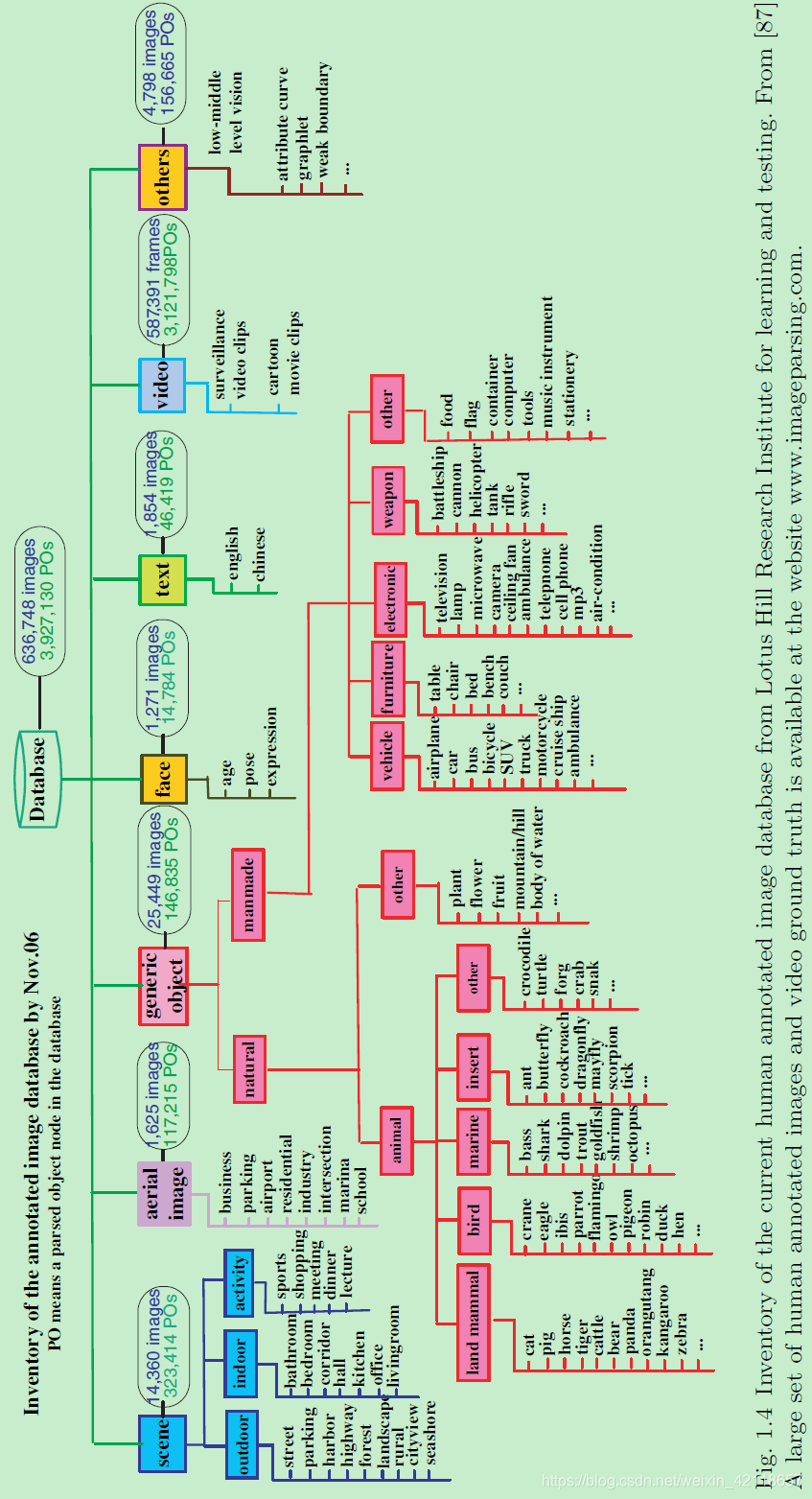
两张图的标注和解析方式示例:
如何学习(训练)的?
有了这个注释数据集,我们可以为对象和场景类别构造和或图,并学习概率模型与或图。这些学习步骤由极大极小熵学习方案[90]和最大似然估计指导。全文分为三个部分:
- 学习或节点上的概率,以便生成的配置解释自然共现频率。这在随机上下文自由文法[10]中是典型的。
- 学习和追求水平连接和关系上的马尔可夫模型,以解释空间关系,以及和或图中节点之间外观的一致性。这类似于马尔可夫随机场的学习[90],除了我们处理的是动态图形配置,而不是固定的邻域。
- 学习和或图结构和字典。终端节点通过聚类学习,非终端节点通过绑定学习。本文对这一问题进行了简要的讨论,因为目前的文献在这方面还没有取得显著的进展。
论文的其余部分按照以下方式组织:
第2章:讨论了随机语法的产生背景、形成过程、图像语法相对于语言语法的新问题以及图像语法的研究进展。
第3-6章:依次介绍语法和与或图:视觉语法、关系和配置、解析图,最后是与或图。
第7章:讨论了学习算法和结果。
第8章:讨论了自顶向下/自底向上的推理算法。
第9章:研究了三个案例。
第10章:提出了一些有待解决的问题作为本文的结论。
2 背景
语法的起源:现实世界的信号的某些部分经常一起出现,而不是偶然发生。这些共同发生的元素可以组合在一起,形成信号的高阶部分,这个过程可以重复,以形成越来越大的部分。由于这些部件的概率较高,因此它们会在其他类似信号中再次出现,因此它们形成了可重用部件的词汇表。
将语法建模成概率表示:
一个基本的统计度量,它表明某物是否是一个好的部分,它是一个量,以比特表示信号s的两部分s|A和s|B的结合强度:
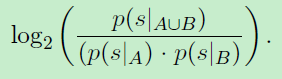
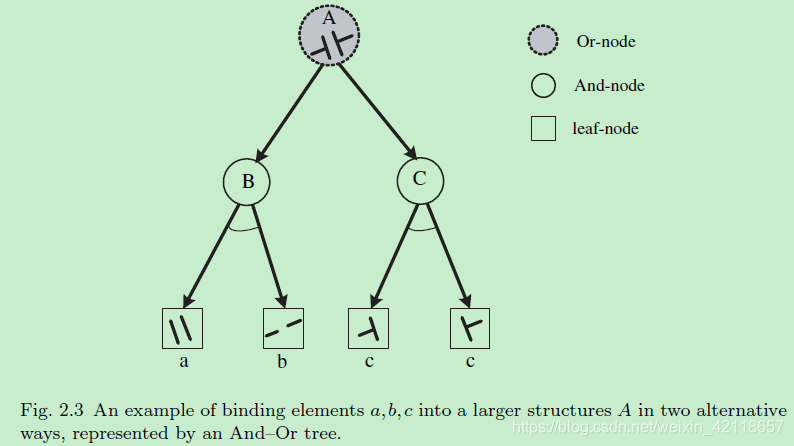
将元素a、b、c以两种可选方式绑定成更大的结构a的示例,用And-Or树表示。(上图中,a,b可以合成A,c,c也可以合成A)
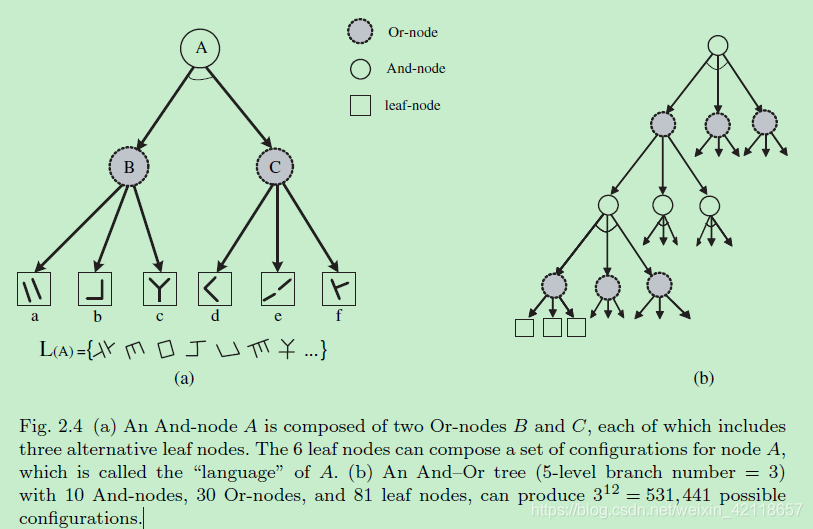
(a)和节点A由两个或节点B和C组成,每个或节点包括三个可选叶节点。节点A的6个叶节点可以组成一组配置,称为A语言。
(b)一个和或树(5级分支数为3)有10个和节点、30个或节点、81个叶节点,可以产生312 = 531,441种可能的配置。(作者举这个例子是说如果仅用“树”结构,无法穷尽。。。)
ym:有点像深度学习神经元中dropout,物体的特征图有很多,关闭几个不影响物理分类。

零件共享和与或图中的菱形结构。看一个例子:
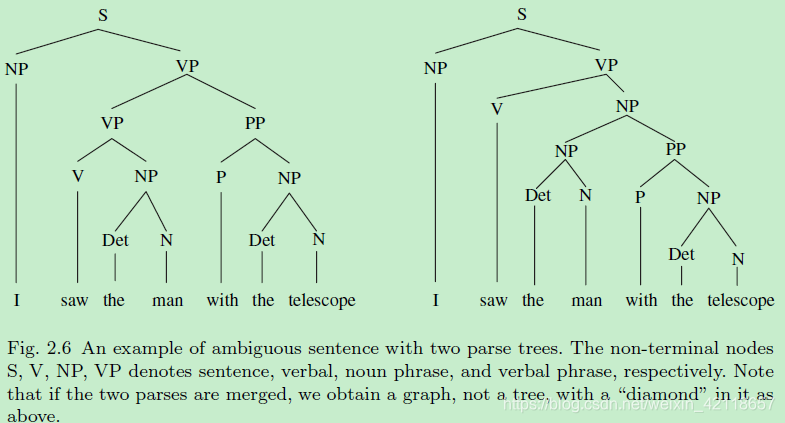
一个带有两个解析树的歧义句的例子。非终端节点S、V、NP、VP分别表示句子、动词、名词短语和动词短语。注意,如果这两个解析被合并,我们得到一个图,而不是树,其中有一个菱形如上所示。
如何表示图像?

图2.10显示了从[85]开始的三个层次的人脸。左边一列显示三种分辨率的人脸图像,中间一列显示三种增加细节的配置(图形),右边一列分别显示每种分辨率下使用的字典(终端)。在低分辨率下,一张脸是由一个整体的小块表示(例如,通过主成分分析),在中分辨率下,它是由许多部分表示,在高分辨率下,脸是由一个使用较小图像原语的草图表示。图2.10中间所示的示意图随着分辨率的增加而扩展。我们可以通过向每个非终端节点添加一些终止规则来解释这一点,例如,每个非终端节点可能会在低分辨率情况下退出生产。
该领域历史上的一些表示方法:
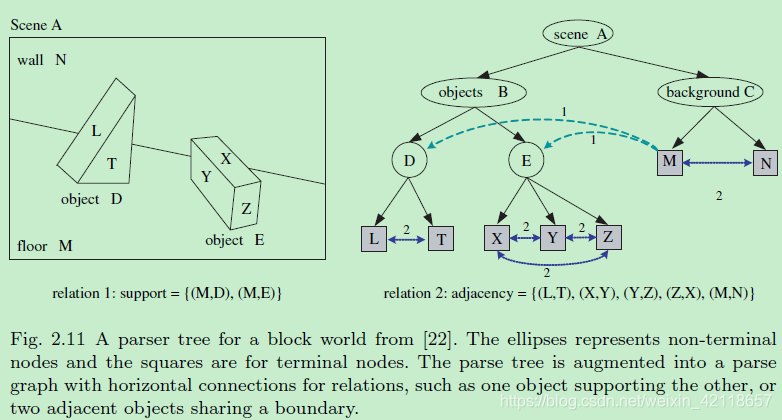
图2.11来自[22]的一个块世界的解析器树。椭圆表示非终端节点,正方形表示终端节点。解析树被扩充成带有关系的水平连接的解析图,例如一个对象支持另一个对象,或者两个相邻的对象共享一个边界。
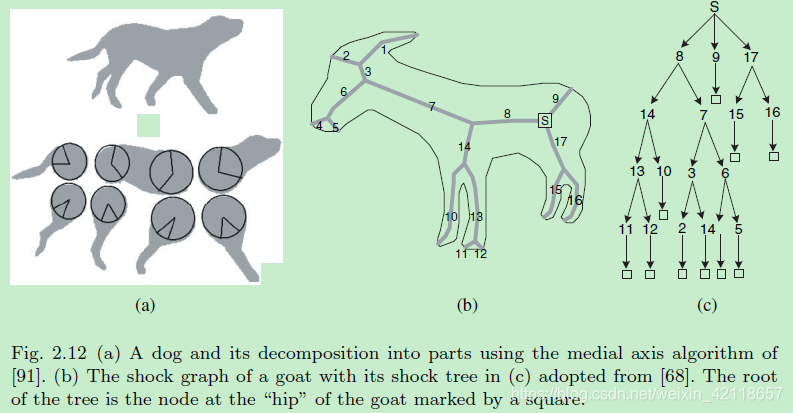
图2.12 (a) a dog及其利用[91]的中轴算法分解。(b)采用[68]中(c)的山羊冲击图。树的根是山羊臀部的节点,用一个正方形标记。
3 视觉字典
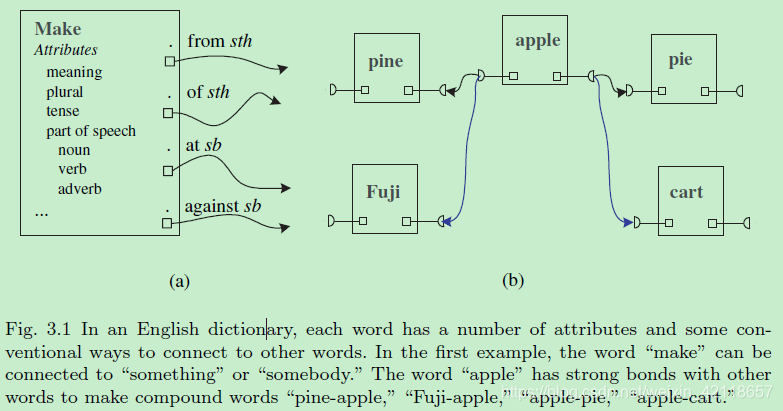
图3.1在英语词典中,每个单词都有一些属性和一些与其他单词联系的常规方式。在第一个例子中,单词make可以和某事或某人联系起来。苹果这个词与其他单词有很强的联系,可以组成合成词pie -apple, Fuji-apple(富士山苹果), apple pie, apple cart。
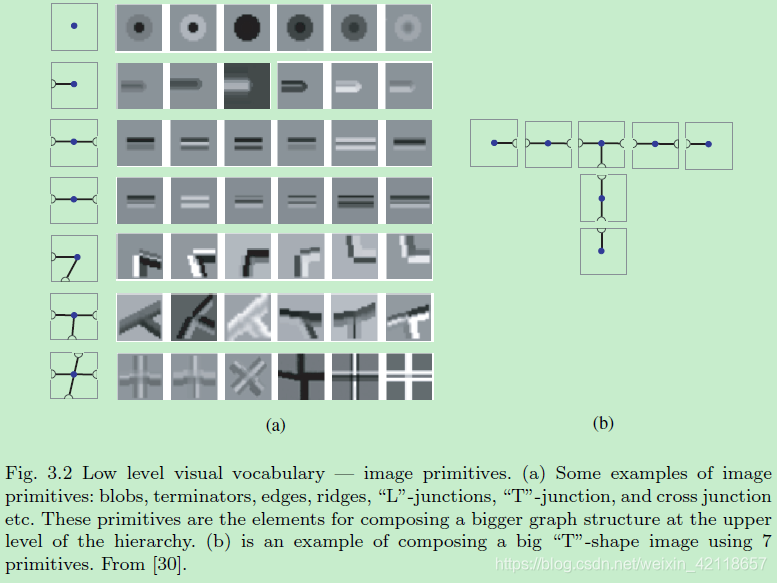
图3.2低层次视觉词汇图像原语。(a)图像基元的一些例子:斑点、终端、边缘、脊线、L连接、T连接和交叉连接等。这些原语是用于在层次结构的上层组成更大的图形结构的元素。(b)是一个使用7个原语组成一个大T形图像的例子。从[30]。
一个例子:
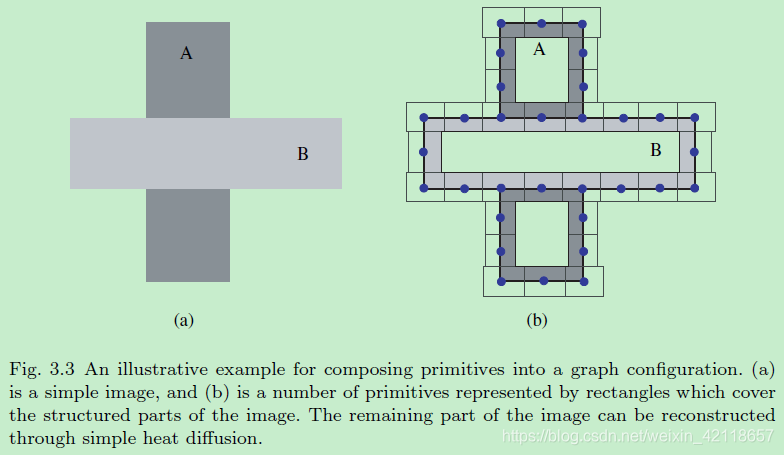
图3.3用于将原语组合成图形配置的说明性示例。(a)是一幅简单的图像,(b)是一些由矩形表示的基元,这些矩形覆盖了图像的结构化部分。图像的其余部分可以通过简单的热扩散重建。
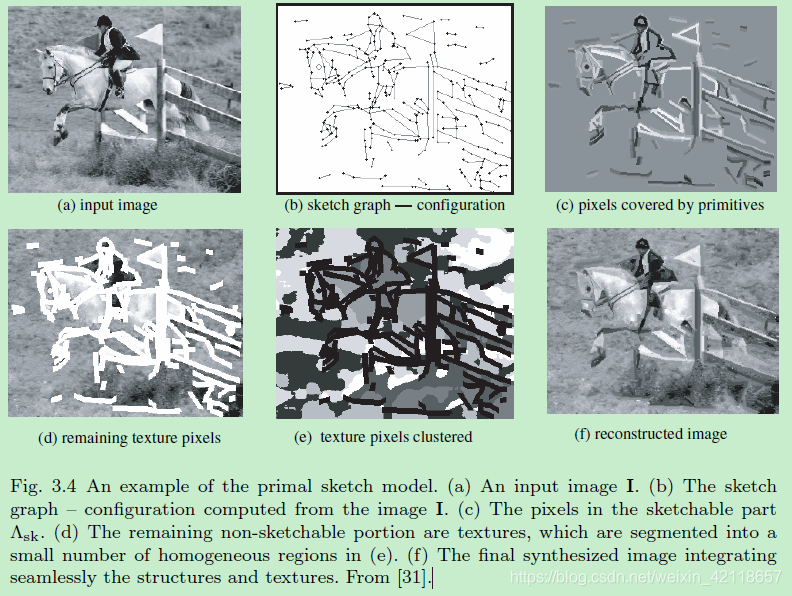
图3.4原始草图模型示例。(一)一个输入图像。(b)的素描图配置计算图像。(c)的像素sketchableΛsk一部分。(d)其余的非素描部分是纹理,在(e)中被分割成少量的同质区域。(f)最终合成的图像无缝集成的结构和纹理。从[31]。
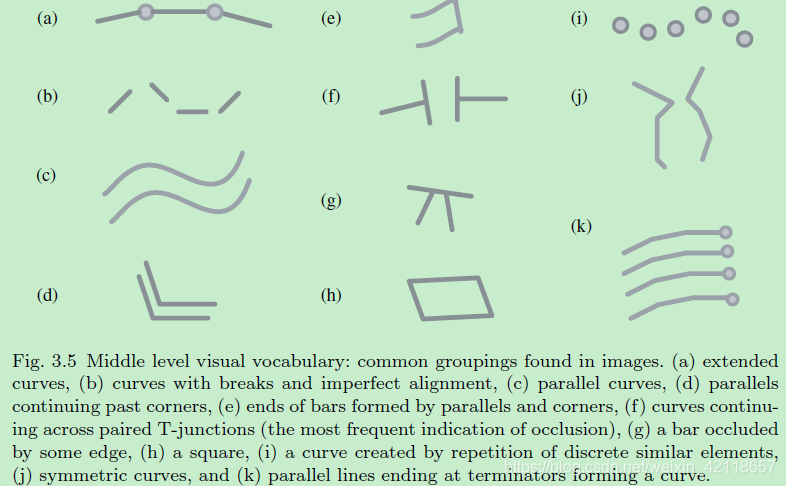
图3.5中层视觉词汇:图像中常见的分组。(a)扩展曲线,曲线(b)与休息和不完美对齐,(c)平行曲线,(d)继续过去的角落进行比较,(e)的酒吧由相似之处和角落,(f)曲线继续在配对丁字路口(最常见的闭塞的迹象),(g)酒吧阻挡一些边缘,(h)广场,(i)曲线由离散的重复类似的元素,(j)对称的曲线,(k)平行线结束在终端形成一条曲线。
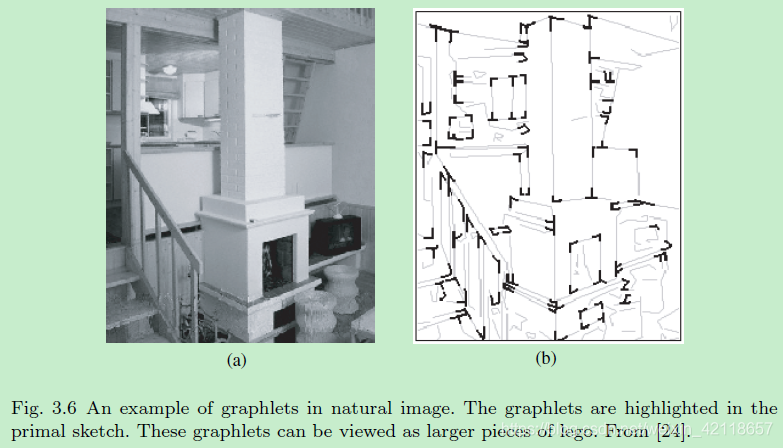
图3.6自然图像中的图形示例。图形在原始草图中突出显示。这些图形可以看作是更大的乐高块。从[24]。
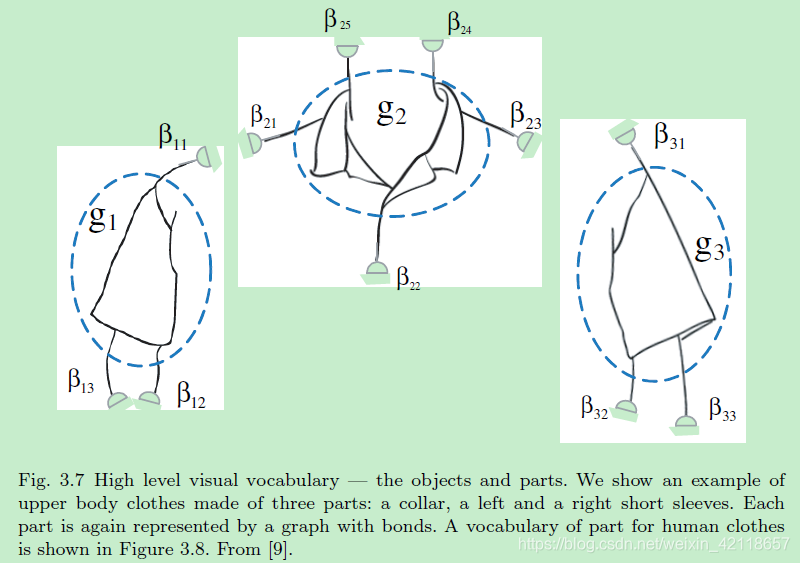
图3.7物体和部件的高级视觉词汇。我们展示了一个由三个部分组成的上身衣服的例子:领子,左边和右边的短袖。每一部分都用带键的图表示。人体服装的部件词汇表如图3.8所示。从[9]。
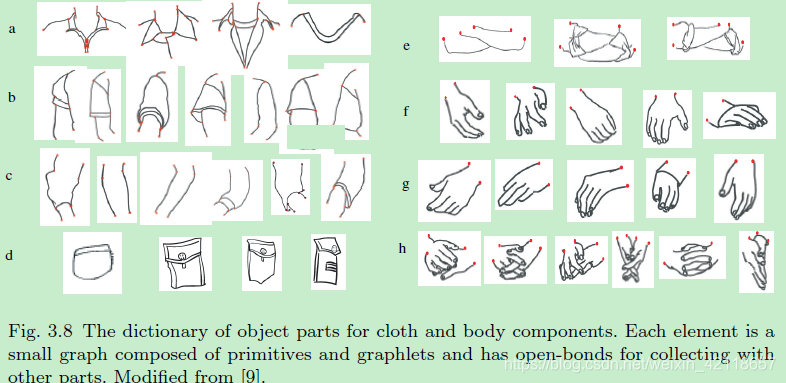
图3.8用于布料和身体部件的对象部件字典。每个元素都是一个由原语和图形组成的小图形,并具有与其他部分收集的开放键。修改[9]。
4 关系和配置
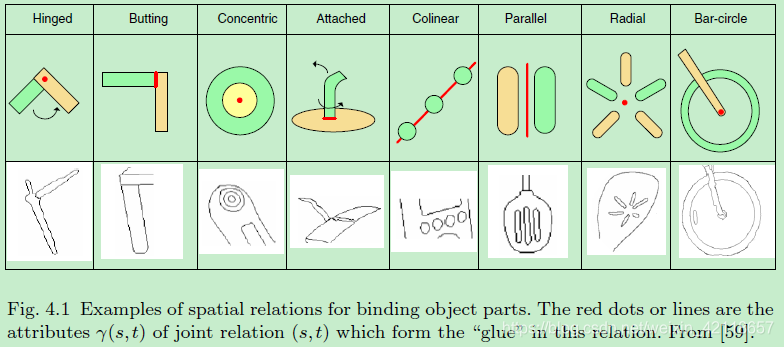
图4.1对象部件绑定空间关系示例。红点或线是连接关系(s, t)的属性(s, t),它在这个关系中形成了粘合剂。从[59]。
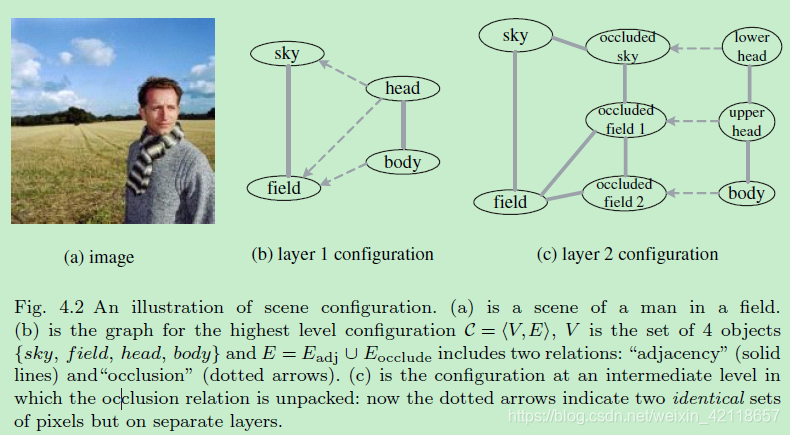
图4.2场景配置示意图。(a)是一个人在田野里的情景。(c)是一个中间层次的配置,在这个层次中遮挡关系被解开:现在虚线箭头表示两个相同的像素集,但在单独的层上。
5 解析对象和场景的图
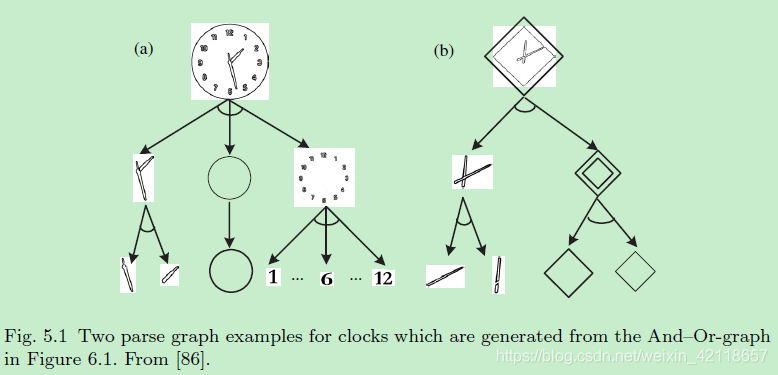
图5.1由图6.1中的And-Or-graph生成的时钟的两个解析图示例。从[86]。
6 用与或图表示知识
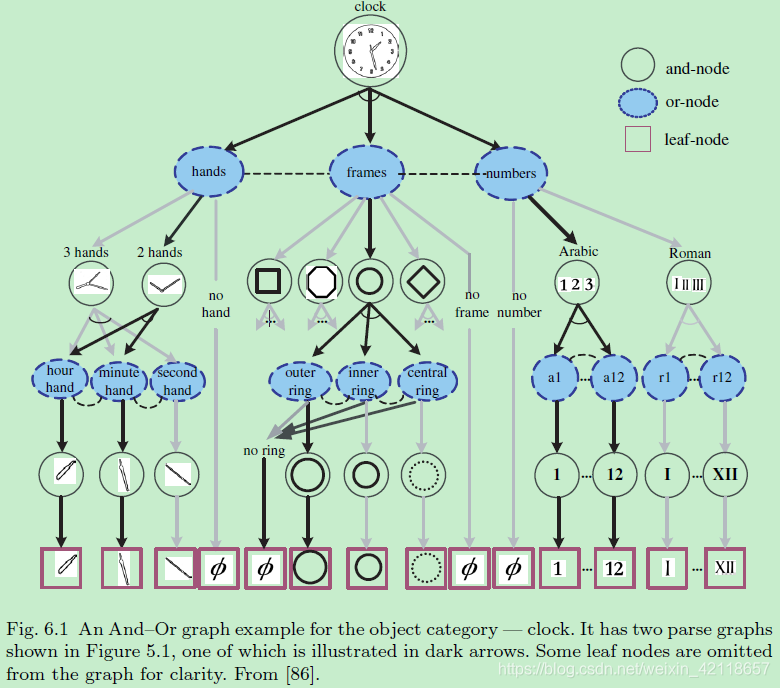
图6.1对象类别时钟的和或图示例。它有两个解析图,如图5.1所示,其中一个用黑色箭头表示。为了清晰起见,图中省略了一些叶节点。从[86]。
7 用与或图学习和估计
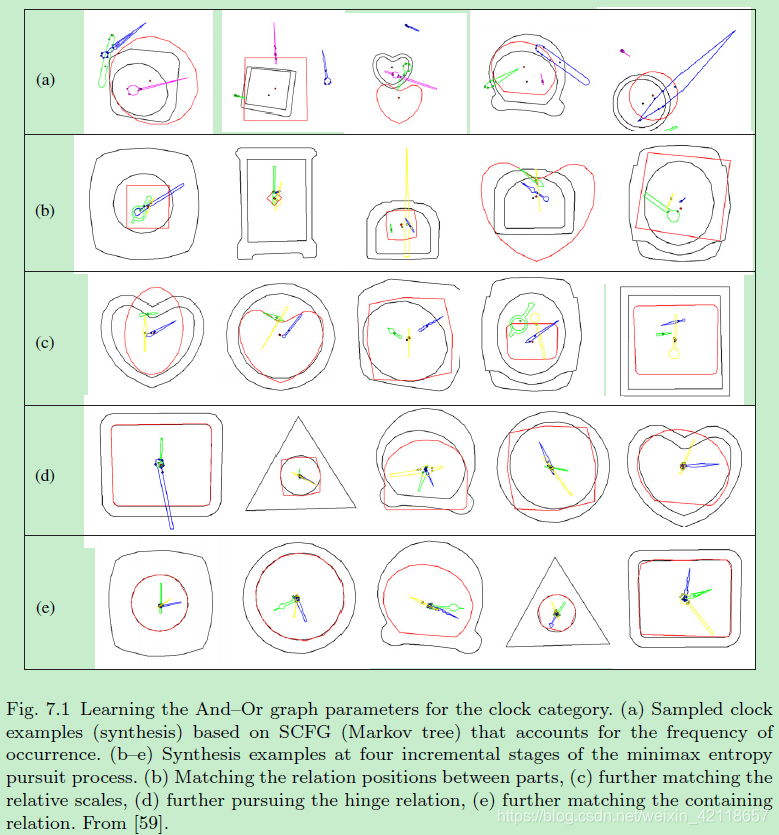
图7.1学习时钟类别的和或图形参数。(a)基于SCFG(马尔可夫树)的采样时钟示例(合成),说明发生频率。(b-e)极小极大熵追求过程的四个增量阶段的综合实例。(b)匹配零件之间的关系位置,(c)进一步匹配相对尺度,(d)进一步追求铰链关系,(e)进一步匹配包含关系。从[59]
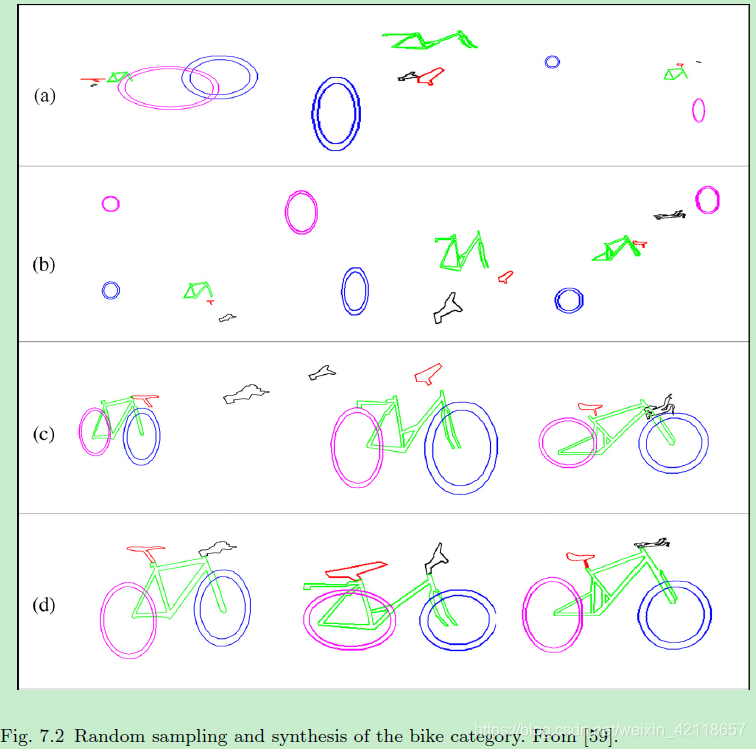
图7.2自行车类随机抽样合成图从[59]。

法7.1。学习Θ随机梯度
学习算法总结
总之,学习算法从一个SCFG(马尔可夫树)和一些观察到的用于训练Dobs的解析图开始。它首先通过计算or节点的发生频率来学习SCFG模型。然后通过采样这个SCFG,合成一组实例Dsyn。Dsyn中采样的实例具有合适的组件,但由于SCFG中没有指定组件之间的空间关系,这些组件之间的空间关系往往是错误的。
然后,该算法选择一个在集合Dobs和Dsyn之间的某些度量上统计量(直方图)差异最大的关系。然后学习模型在选择的关系上重现观察到的统计信息。采样一组新的合成实例。这个迭代过程继续下去,直到观察到的集和合成集之间没有更明显的差异为止。
8 自顶向下/自底向上的图像解析递归算法
本章简要回顾了作者和合作者使用语法进行图像解析的推理算法和三个案例研究。第一种是人造世界场景的通用语法。构成对象包括建筑(室内或室外)和家具。第二种是对人体服装和上半身[9]的语法限制较多。第三种情况[86]应用语法识别五种对象类别时钟,自行车,计算机(屏幕和键盘),杯/碗,茶壶。在这两种情况下,推理都在贝叶斯框架下进行。给定输入图像I作为终端配置,我们计算一个后验概率最大的解析图pg.

图8.1和或图上递推推理算法的数据结构。参见文本的解释。

算法8.1。图像解析采用自顶向下/自底向上推理
9 图像语法的三个案例研究
案例研究一:对人造世界的视角进行解析
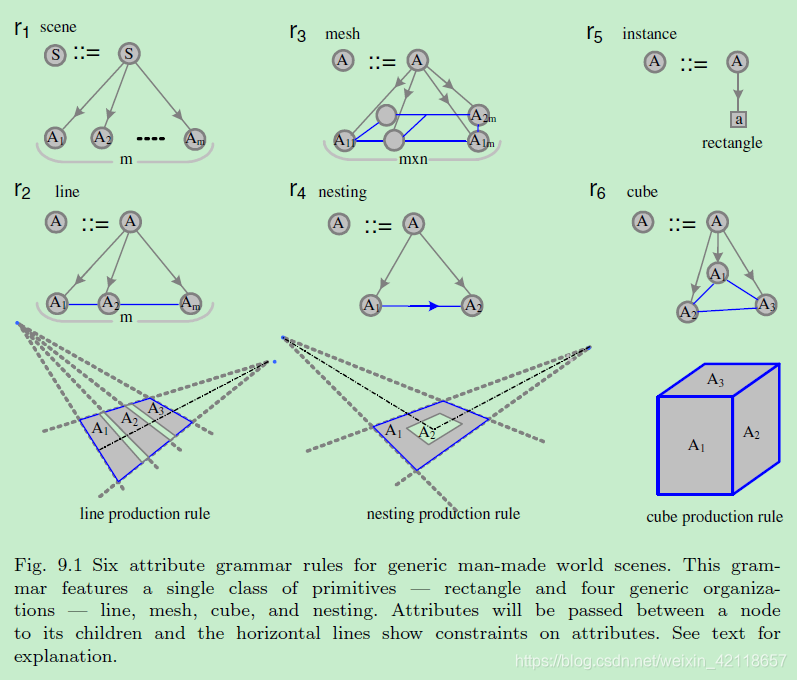
图9.1人工世界场景的六种属性语法规则。该语法提供了单一类的基本类型rectangle和四种通用组织line、mesh、cube和嵌套。属性将在节点之间传递给其子节点,水平线显示属性的约束。见文字说明。
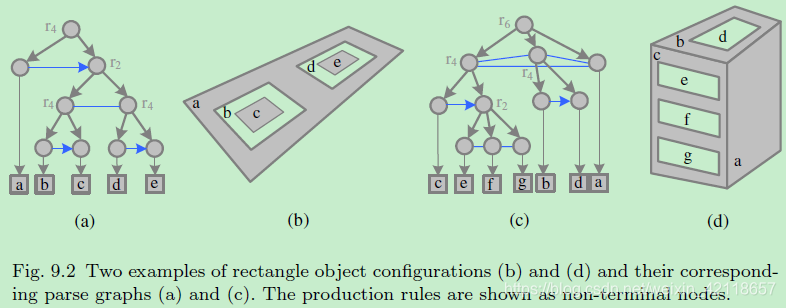
图9.2两个矩形对象配置示例(b)和(d)及其对应的解析图(a)和(c)。生成规则显示为非终端节点。
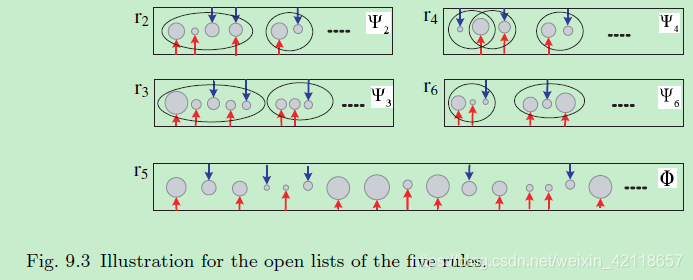
图9.3五个规则的开放列表示意图。
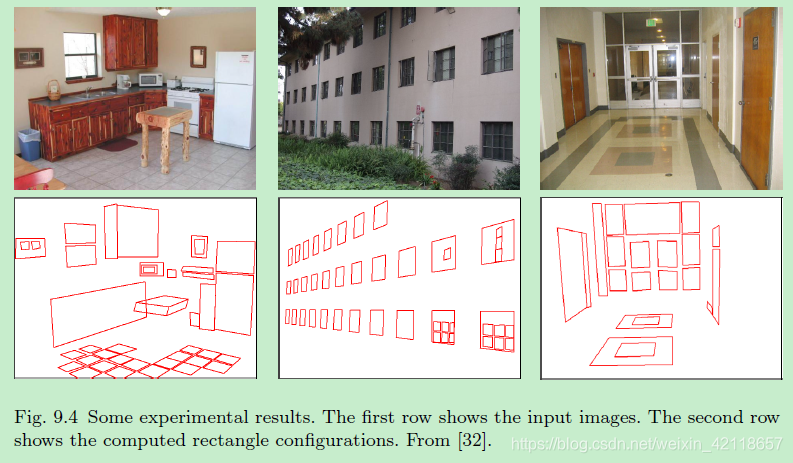
图9.4部分实验结果。第一行显示输入图像。第二行显示计算后的矩形配置。从[32]。
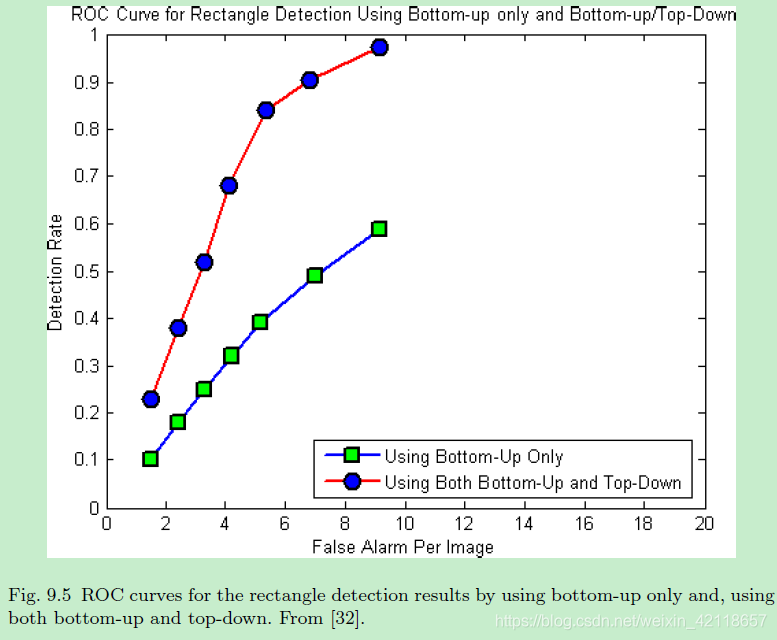
图9.5仅自底向上和同时自底向上和自顶向下检测矩形的ROC曲线。从[32]。
案例研究二:人体布料建模与推理
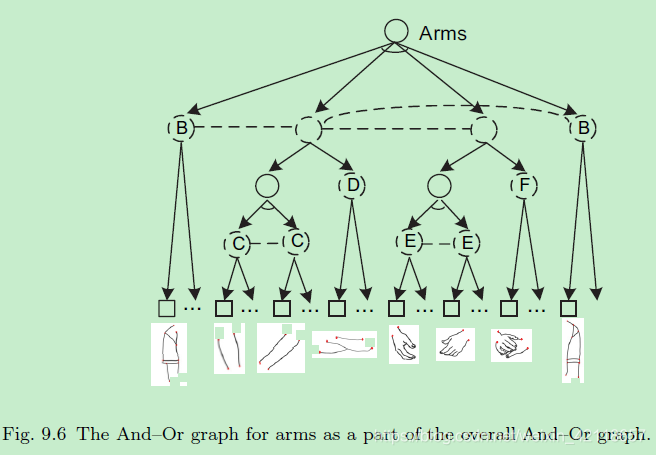
图9.6作为整体和或图的一部分的arm的和或图。
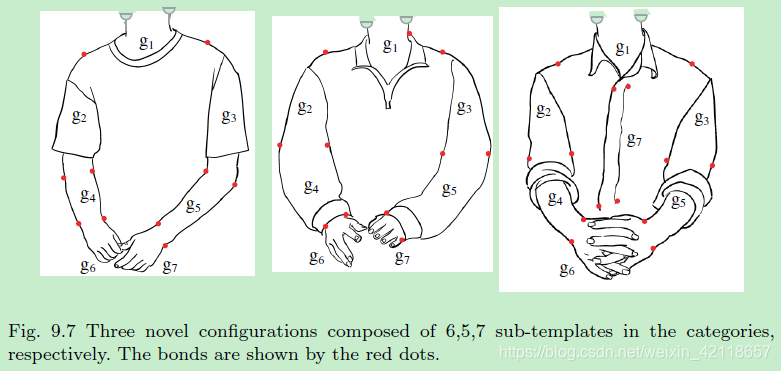
图9.7三种新的配置分别由类别中的6,5,7个子模板组成。这些化学键用红点表示。

图9.8用衣服从图像推断上半身的实验。从[9]。
案例研究三:对象类别的识别
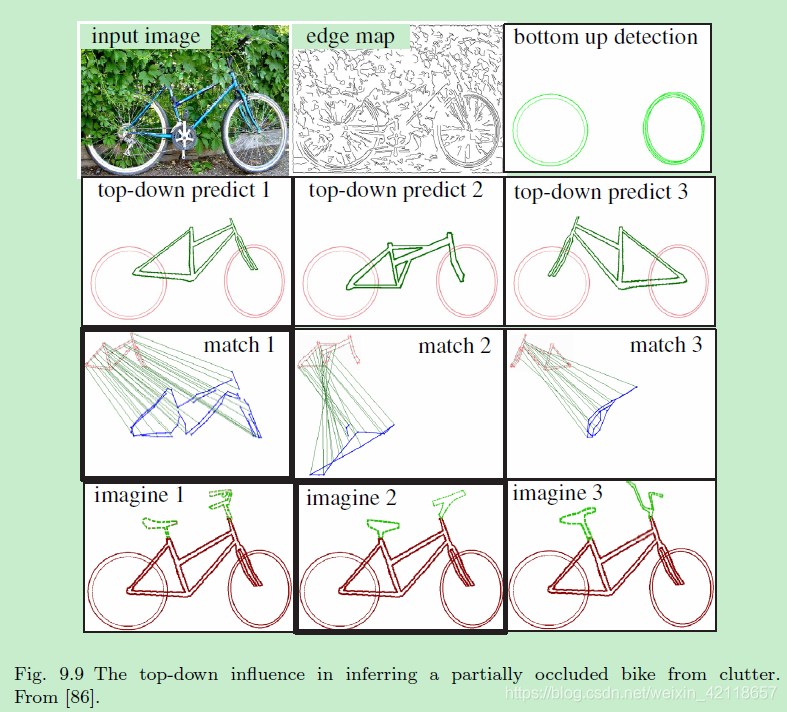
图9.9从杂波中推断部分遮挡自行车时自上而下的影响。从[86]。

图10.1五类目标的识别实验。从[86]。
10 总结和讨论
这篇探索性的论文关注在一个一致的建模、学习和计算框架中表示大规模的可视化知识。具体来说,在一个健壮的视觉系统可行之前,必须解决两个巨大的问题:(i)大量的(数百)物体和场景类别;(二)类内结构变异较大。为了解决这两个问题,我们提出了一种嵌入和或图中的随机图语法,它可以从一个大型注释数据集中学习。
首先,为了表示类别内的变化,语法可以从一个相对小得多的词汇表创建大量的配置。And或图类似于可重新配置的母模板,并动态地组装新的配置,以解释以前未见过的新实例。
其次,为了扩展到数百个类别,将递归地设计And或图。因此,无需太多开销,就可以将所有类别集成到一个大的And或图中。学习和推理算法也是递归设计的。这允许大规模并行计算。
有两个有待进一步研究的问题:
- 学习和发现和或图。正如在最近的一系列著作中提出的那样[17,52,59,81,86],其目标是绘制视觉词汇图,包括所有抽象层次和所有视觉方面的词典。这个任务可以制定理论下常见的学习原则,是把字典Δ到最大似然学习过程。各种信息标准,如结合强度,互信息极大极小熵,将自然地从这个学习过程中产生。然而,最终的视觉词汇是不可能完全自动地从统计原理学习,因为词汇的确定必须考虑到视觉的目的。这就提出了莲花山研究所正在实施的半自动方法。人类用户在现实生活体验、心理和视觉任务的指导下,定义了大部分结构,而将参数的估计和适应性留给计算机。在更复杂的阶段,计算机应该能够在字典中查找并追踪新元素的添加。到目前为止,莲花山研究所已经为超过200种物体和场景类别构建了And Or图形,其中包括航空图像[87]。
- 自顶向下和自底向上过程的调度和排序。当我们有一个由数千个节点分层组织的大的和或图时,我们可以想象计算过程就像一个拥有数千条装配线的多层工厂。直观地说,每条装配线都对应于和或图中某个节点的开链表和闭链表。由于所有这些装配线只共享一个CPU(甚至多个CPU),因此优化调度以最大限度地提高工厂的总吞吐量是至关重要的。传统上,视觉算法总是从自下而上的过程开始,向装配线提供原材料(提出加权假设),例如,DDMCMC[73,92]和前馈神经网络[61]。由于具有多分辨率特性,And或图中的每个节点都可以立即终止,因此原材料可以直接发送到工厂所有楼层的装配线上,而不是逐个楼层上升。这一策略得到了人类视觉实验的支持[18,70],实验表明人类可以像检测低水平文本和原语一样快速地检测场景和物体类别。
关于自上而下和自下而上过程的作用存在着长期的争论[76]。我们认为,只能从数字上而不是口头上回答这一辩论。也就是说,我们需要从数字上计算每个操作符在真实世界图像集合上的信息增益,无论是自顶向下还是自底向上。


















 2904
2904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









