







感受:
- 大多数人学业和工作事情很多,基本都是业余参加的比赛。
- 数据集少的竞赛,运气占很大成分,各种模型几乎都影响不大了,哪怕是YOLO3结构稍微修改输出层也能进前6名。
- CPU赛道方法创新性、技术复杂性、PPT质量、答辩水平明显比GPU低了几个档次。
- 第3名很励志,家具店店主,全凭业余爱好,闯进第3名。虽然口才很差,但是算法概念和框架熟练度感觉比很多摸鱼的算法工程师都熟练,赞。
总结:
当前阶段竞赛,运气占大头,需要花费很长时间去测试各种模型的效果,以及排列组合效果,并不是COCO集的SOTA模型就一定适合特定的比赛使用。所以,这是任何人的机会。
第1名 北交大 - 3人(太优秀,各种模型的测试数据,还做了软件演示)
北交大2人+中科院1人
赛题分析及理解

核心思路-算法框架设计
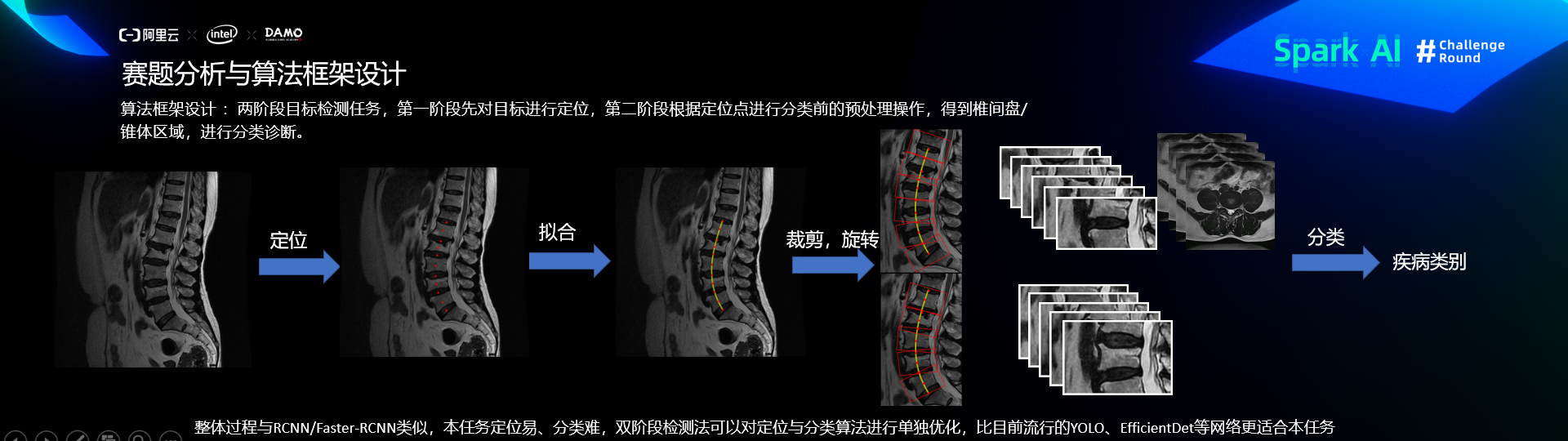
第一阶段:定位
预处理
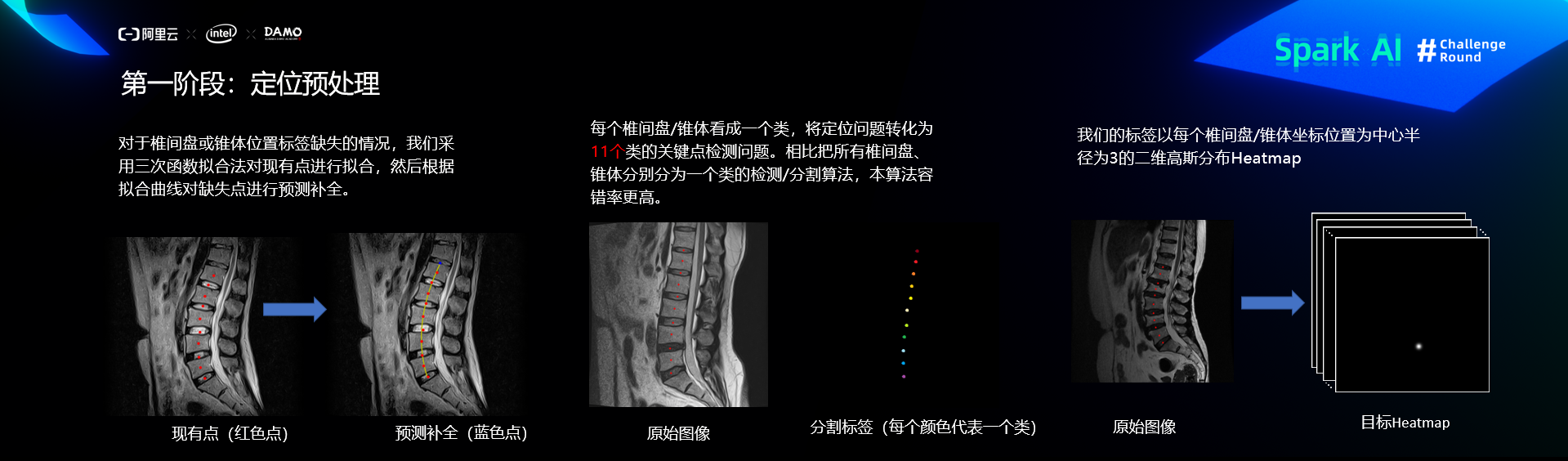
定位网络
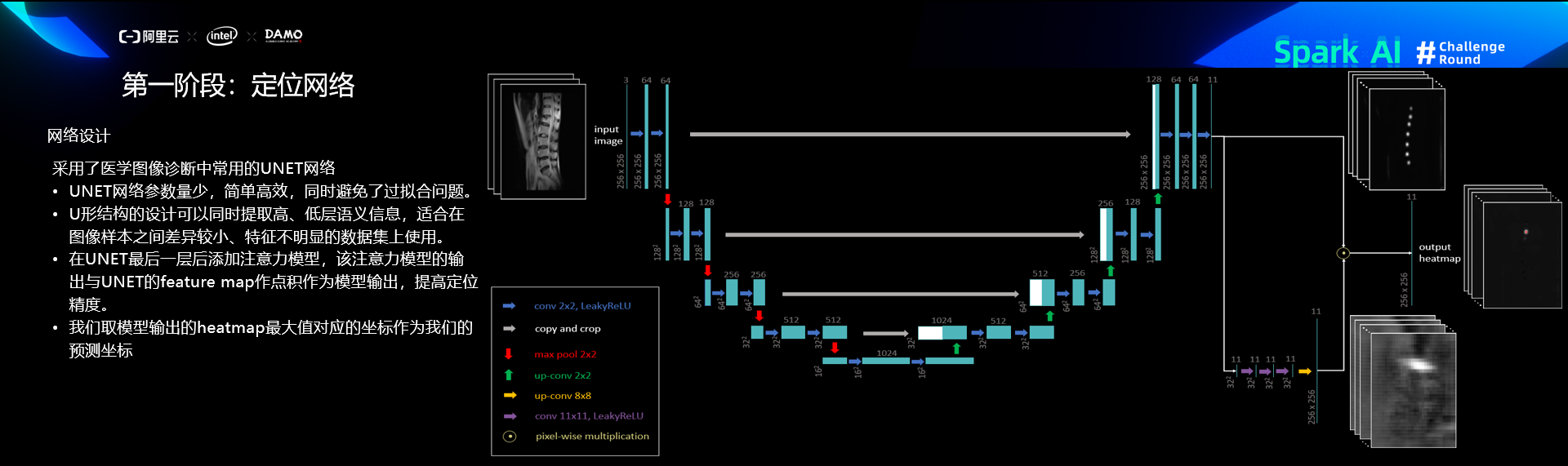

定位训练过程

第二阶段:分类
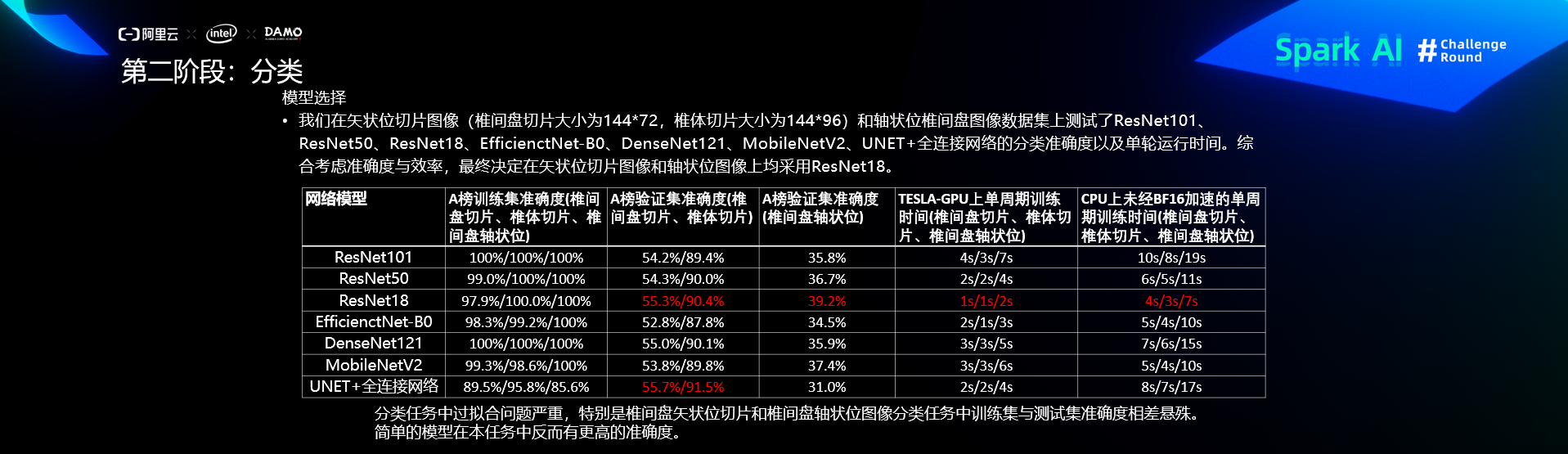
预处理
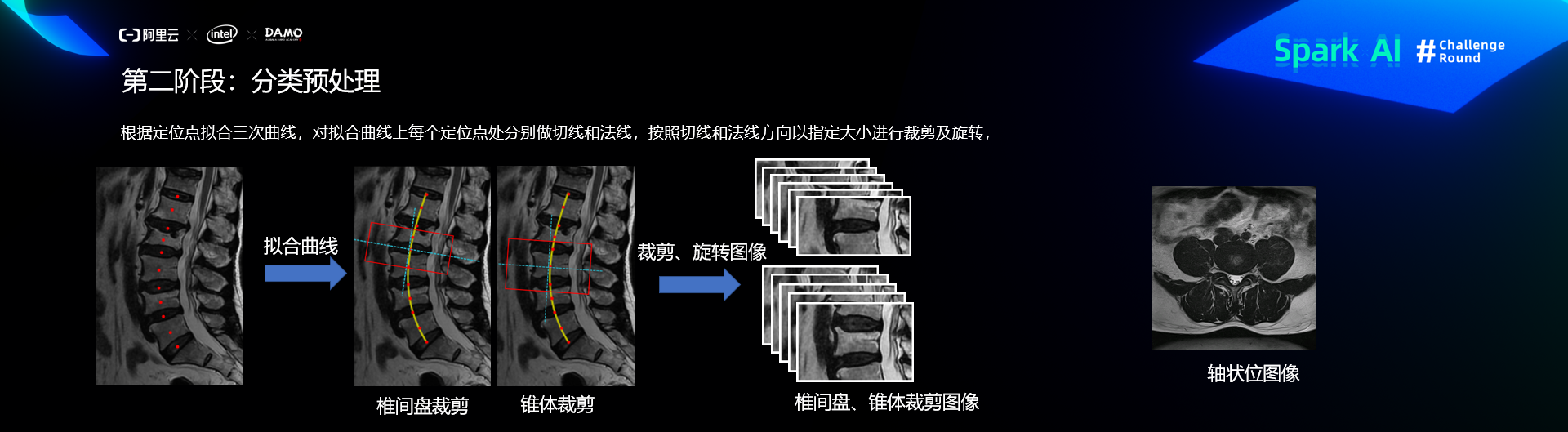
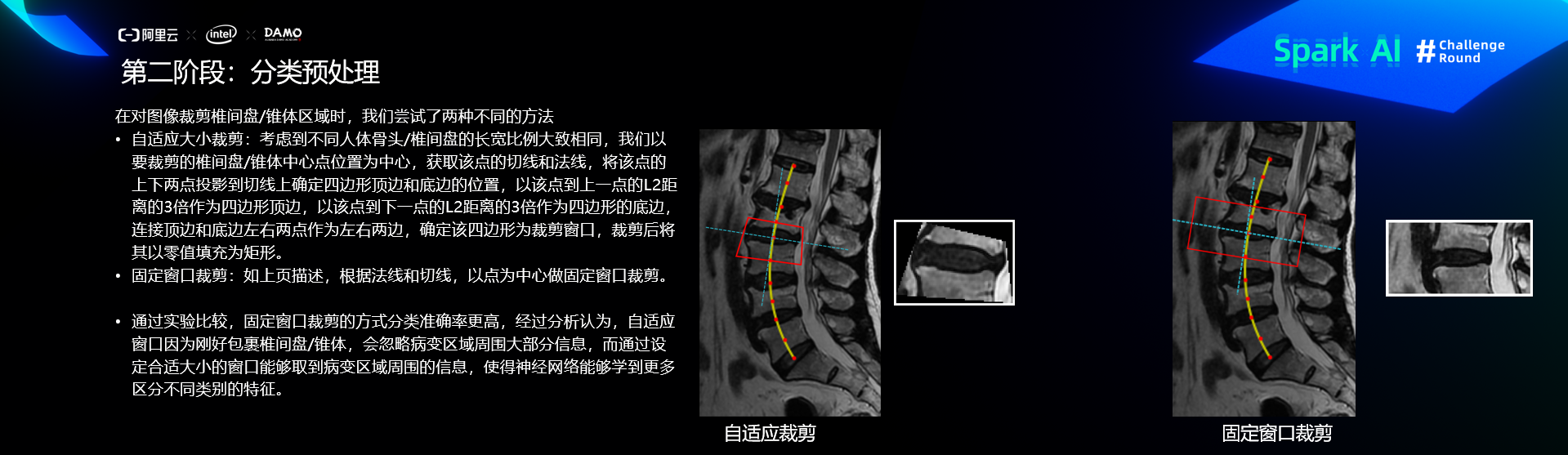
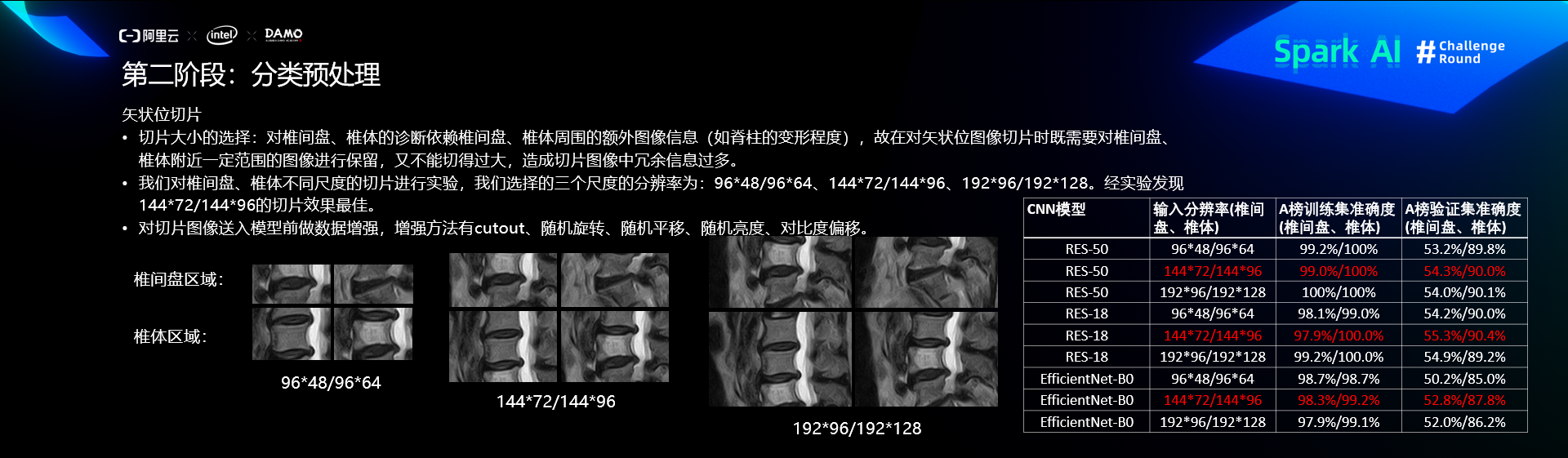
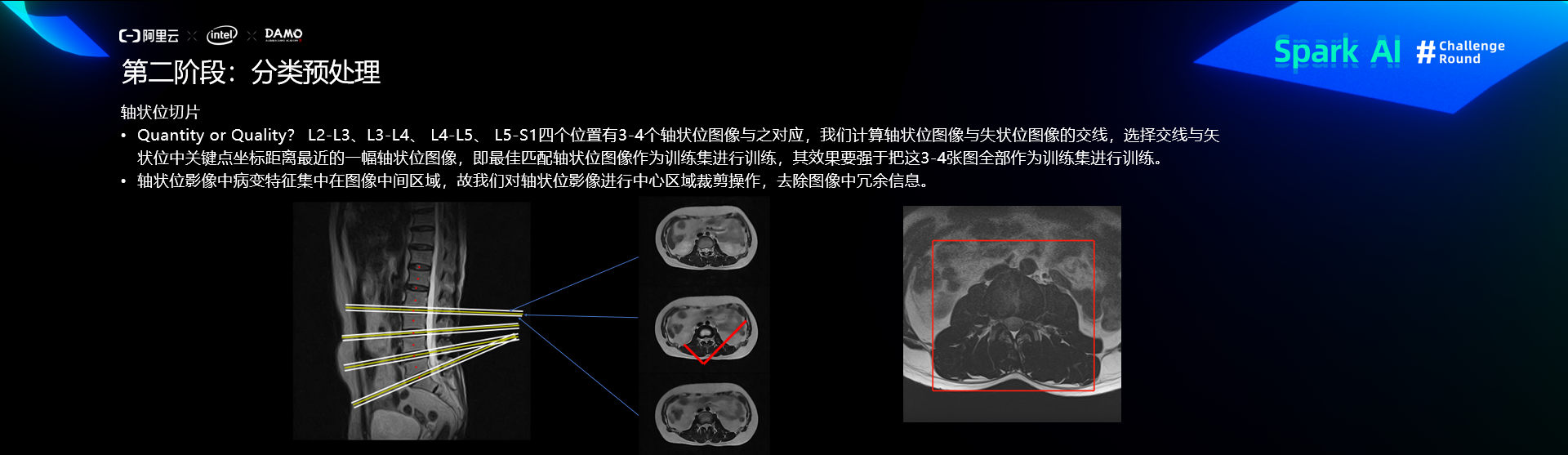
分类算法


关键代码
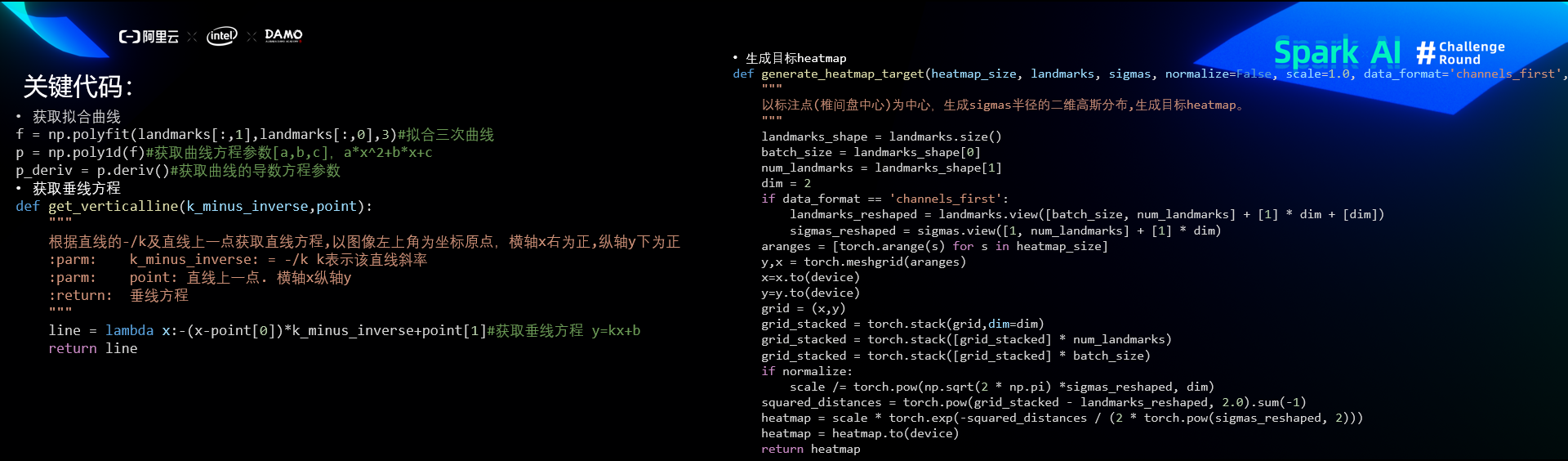
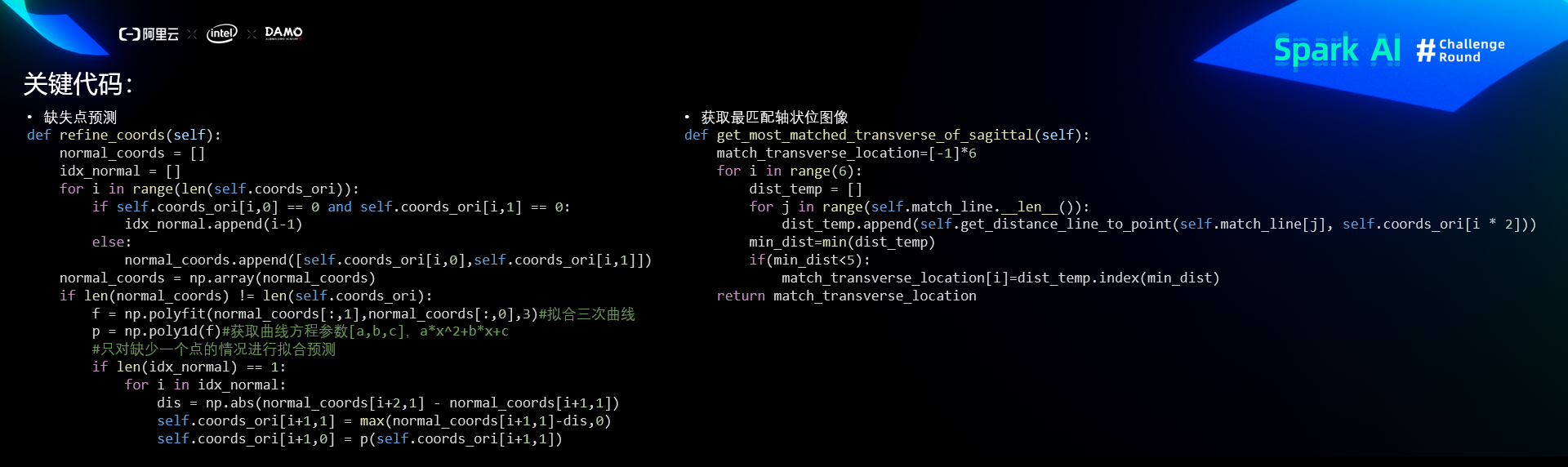
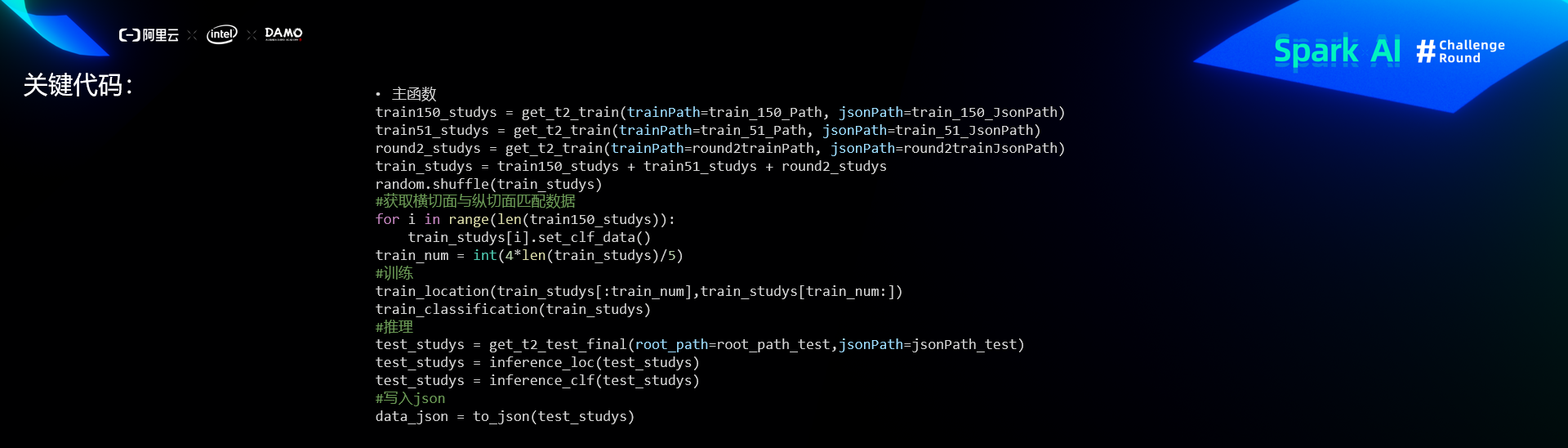
比赛经验和总结

第2名 “U-Net” - 大连理工 - 3人(有PPT下载)
大连理工2人(也是下班时间完成的)+柏林工业1博士
CPU赛道需要使用intel cpu进行模型的训练,为了减少踩坑,我们决定基于baseline进行二次开发,在原有的腰椎定位模型的基础上添加分类分支,端到端的完成模型训练。
模型设计
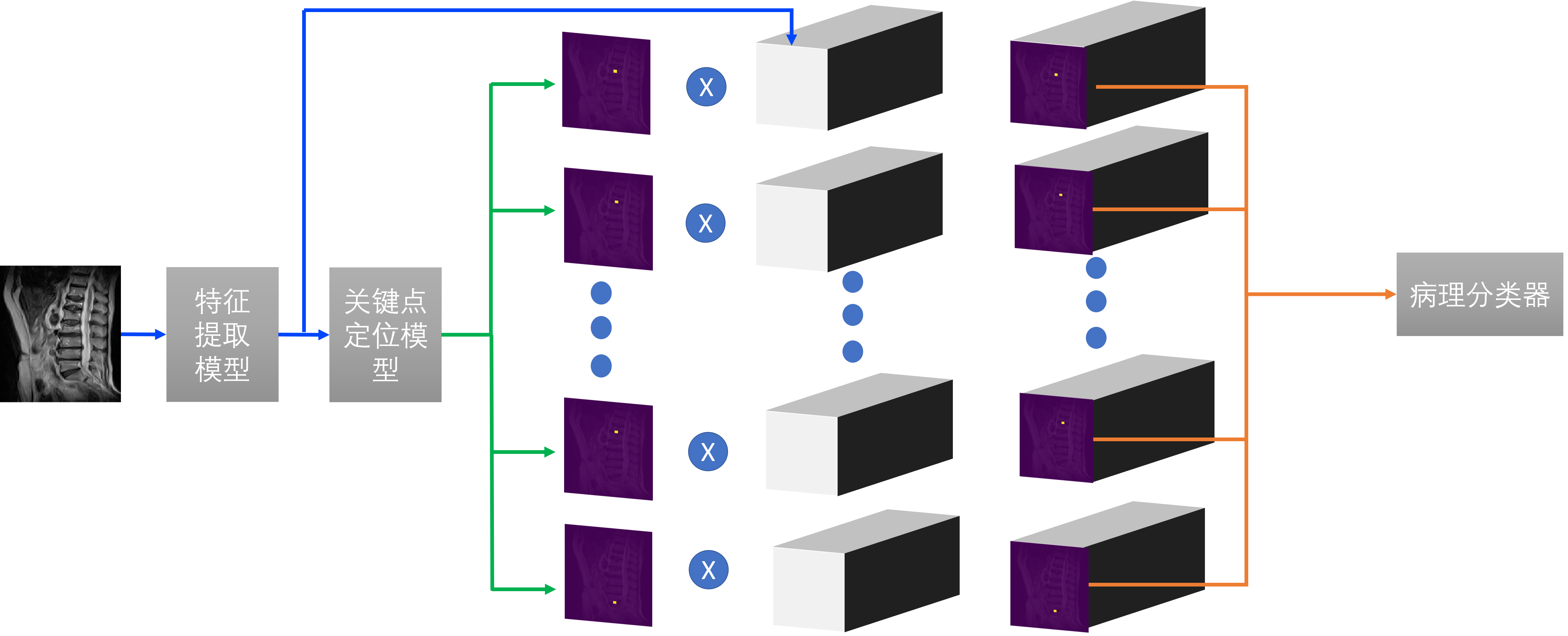
腰椎定位模型使用了FPN(特征金字塔)网络结构,C1-C5为骨干网络,负责提取图像的语义特征,P5-P2将骨干网络的语义特征进行逐级放大,最终得到一个相比原图4倍下采样的关键点的热力图。同时在每个特征放大阶段,使用跳级连接将不同层级的特征进行融合,让特征包含轮廓、边缘信息。
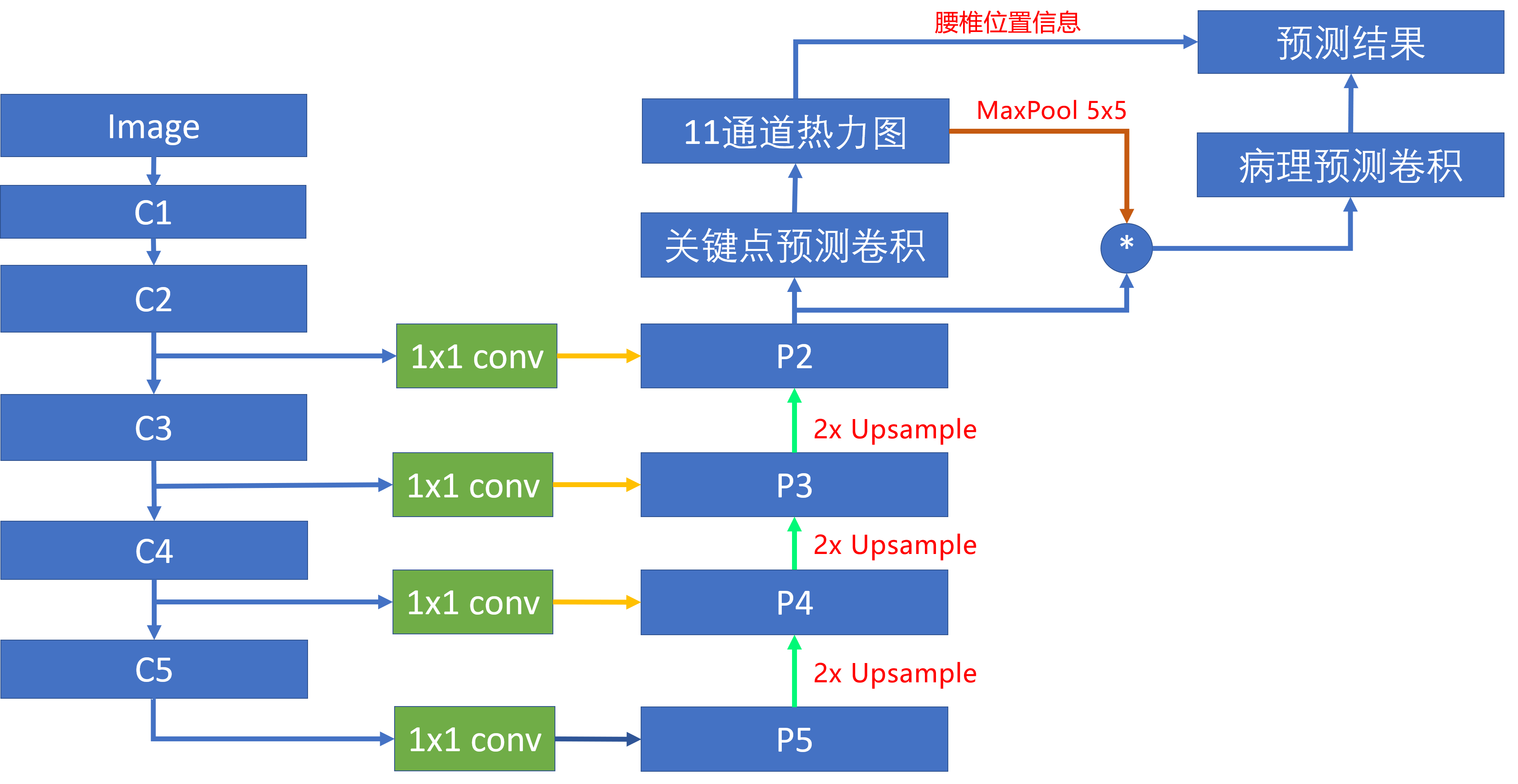
在得到腰椎关键点热力图之后,我们对每个关键点的热力图进行一个5x5的maxpool,扩大热力图关键点区域的面积。然后将每个热力图和前端模块的特征相乘,得到11个不同位置的融合后的特征图。将这些融合后的特征送入分类器中就可以得到腰椎对应的病理类别,整个过程示意图如图。
模型训练
训练配置
- 学习率:3e-4
- 优化器:Adam
- 训练轮次: 60
- 学习率调整方案:逐级衰减 (10, 30, 50, 55)
调优策略
数据增强主要使用了随机裁剪、随机旋转以及随机模糊。线下验证时,数据增强的效果并不明显,为了增强模型泛化性能仍然使用了数据增强。在实验中发现,更深的骨干网络精度更高,同时模型的腰椎定位能力相对精准,制约精度的主要因素是类别识别不准确。
不足
在比赛的最后我们发现很多锥体内疝出经常和别的病变同时出现,我们只选择其中一种类别进行识别,这样导致很多锥体疝出的漏检。可以考虑使用多分类的手段处理,一个锥体多个病变的情况。
第3名 “下午两点半” - 无 - 1人
广西南宁一个小县城小家具店店主,27岁,毕业于广西大学行健文理学院。
本次比赛我使用的是类似于EfficientDet 的物体检测方法(虽说类似,但其实差别也很大),首先数据经过统一resize到(512,512,3)之后经过backbone(efficientnet b7)输出三层的feats[(64,64,80)(32,32,224)(16,16,640)],由于512x512的图片经过efficientnet输出的特征图最小只有16x16,所以各使用8层的resnet继续采样得到8x8和4x4大下的特征图,之后经过ResFPN(一个参照resnet设计的残差FPN)进行特征融合,然后取最大的特征图即64x64来用于最后输出头的输入,输出头的第一个操作就是继续采样得到32x32大小的特征图 ,即最后的物体检测操作其实是在32x32大小的特张图上进行,loc用于判断背景或者物体(iou<0.3为背景,0.3<iou<maxiou不输出loss,iou==maxiou即为物体),reg用于坐标的回归(iou<0.6不输出loss,iou>0.6正常输出loss),cls用于判断物体的症状(iou<0.6不输出loss,iou>0.6正常输出loss)。
模型结构图
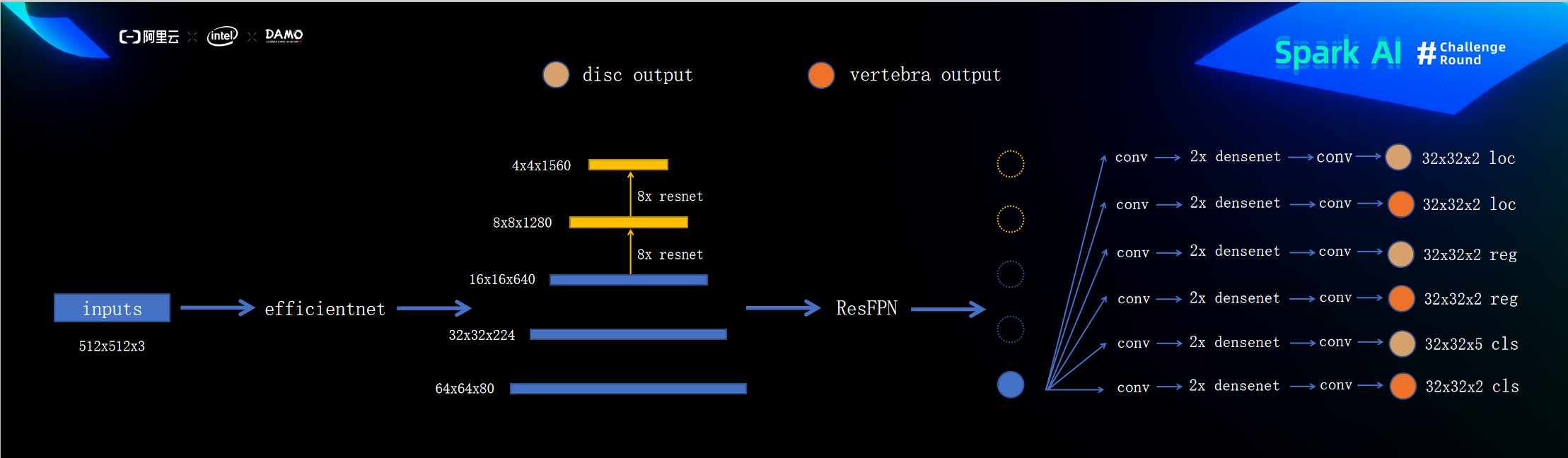
ResFPN结构
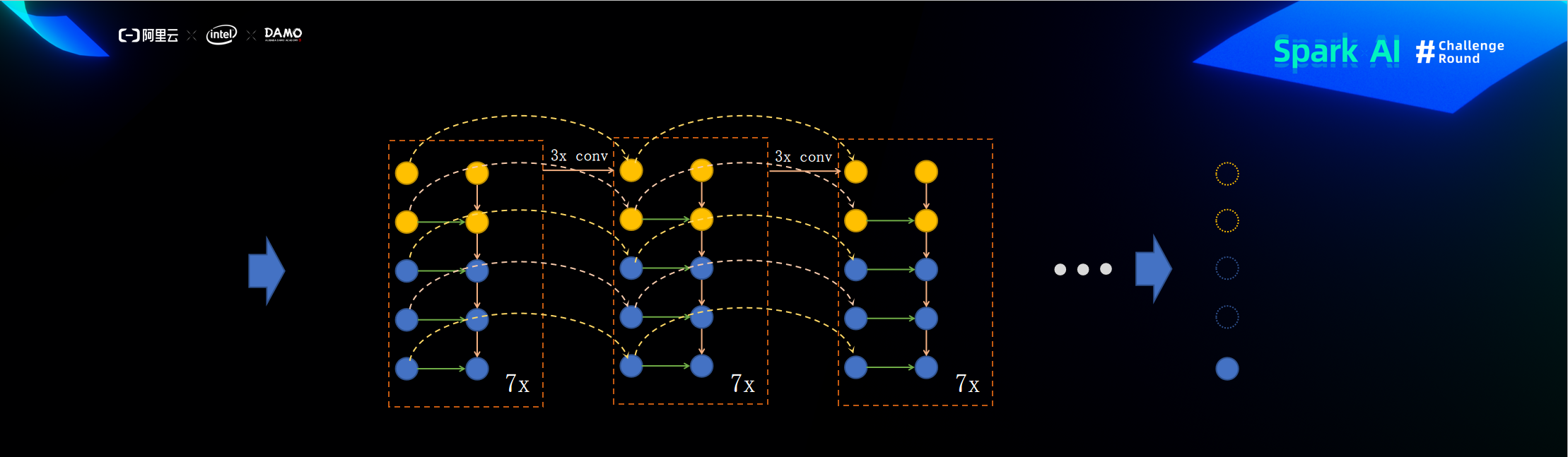
ResFPN关键代码
输出头部分的第一个conv 为继续下采样到32x32,第二个conv为调整最后的输出,比如将loc的输出filter调整为2,中间置一个dense net为防止过拟合(dense net之间的每个连接分别加一层0.5的dropout)
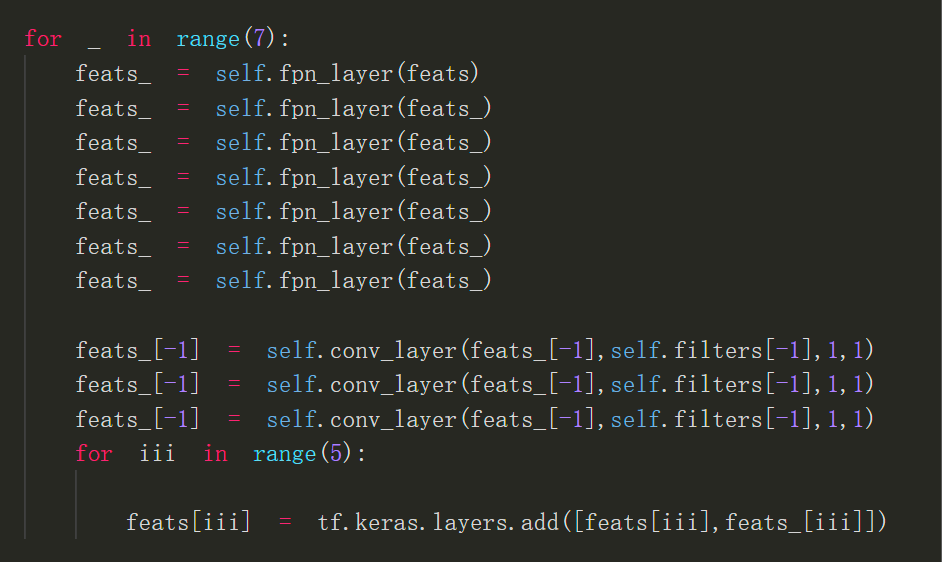
以上便是我此次参加比赛所使用的模型,提交分数为0.633,但此模型其实还可以做些改进,比如将backbone出来的feats继续下采样的resnet换成efficientnet block,ResFPN也可以继续改进到ResFPN2.0,ResFPN里的每层fpn_layer其实就是一次自顶向下融合,ResFPN2.0与第一代ResFPN的区别就是ResFPN2.0每一次自顶向下融合之后最顶上的特征图就进行一次卷积之后再进行下一次融合。
以下是ResFPN2.0关键代码:

此次比赛我使用的loc loss 是focall_loss 、reg loss 是tf.keras.losses.Huber、cls loss 是tf.keras.losses.CategoricalCrossentropy ,优化器采用的是 tf.keras.optimizers.Nadam。
此次比赛能用的训练数据比较少,所以我使用了一个分类模型挑选出json文件里未标注的其它T2帧来扩充训练数据,数据增强部分采用了随机左右平移、随机亮度增减、随机对比度增减。
第4名 “AI探索者” - 无 - 1人(社会人)
中国人民大学
1.有幸提供了初赛tensorflow baseline,复赛时为了更好的分类椎间盘,附加了ResNet101作为识别。也许可以直接改造mask r-cnn的损失函数。
2.为了更好的分类,ResNet101用的focal_loss作为损失函数。
3.复赛没来得及提交v5识别结果,也许成绩会更好些。
4.比赛攻略ppt详见附件。
第5名 “Tangguo” - 成都小象科技 - 1人
华南理工,社会人
1 赛题背景分析及理解
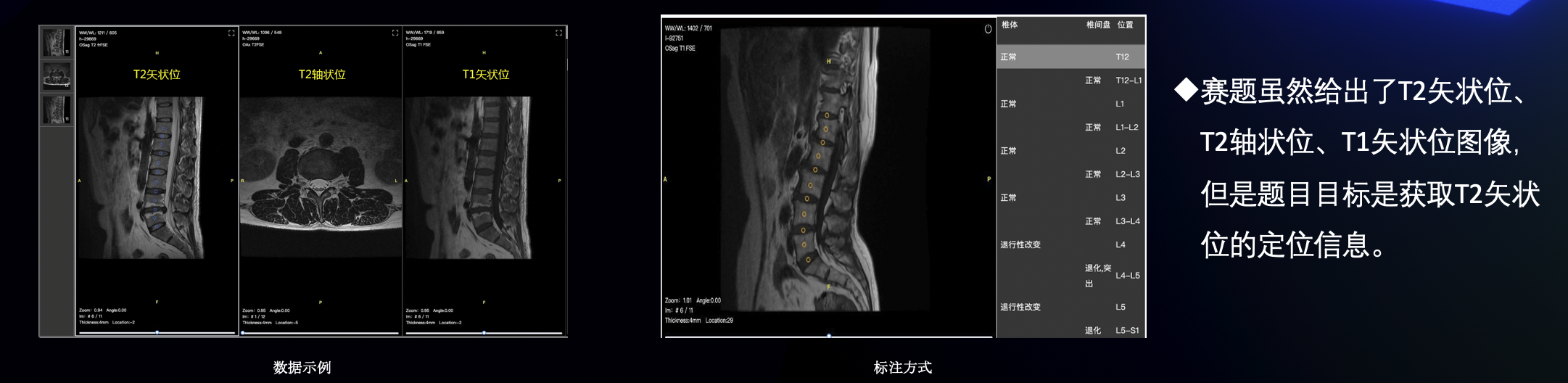
本次赛题是对核磁共振影像进行分析,检测定位腰椎的关键点并对疾病进行判断。可以分为三个任务:
- 从一次检查获取到的很多图像中,找出合适标记的图像
- 在合适标记的图像上定位腰椎的11个关键点
- 对每一个关键点的疾病进行分类
2 核心思路
2.1 找出合适标记的图像
这个任务主要是找到T2序列,后期举办方已经给出了T2序列的ID,这个任务就简化成简单的排序取中间的规则了。
2.2 关键点定位
采用yolov3的模型。考虑特征图上每点需要只有一个特征点落在其中,所以只保留最精细一层特征图的输出。只要定位位置,所以去掉高宽的输出。
特征点落在靠近边线和角点的位置时,xy的真值靠近0或1,处于sigmoid函数饱和区,难于训练。所以添加4组定位中心,一共5组定位中心使得任意一点距离最近的定位中心不超过0.3。距离定位中心距离小于0.3的置信度真值给1,否则按距离递减,用以拉开有把握和没把握的定位框输出的置信度。
最终特征图上每点输出维度为:5组定位中心*(1置信度+2位置+11关键点)
2.3 疾病分类
疾病分类的包含较多主观因素,存在较大噪声,训练不太稳定,选择轻模型多折训练以期提高稳定性。最终采用的MobileNet v3,三折训练。并做标签平滑,根据标签距离都给与非0真值,如标注标签是v2,离v1、v3都比较近,都给v1、v3的真值0.08,离v4比较远,给v4的真值0.008,剩下0.85就是标注标签v2的真值。
2.4 数据增强
- 随机的旋转、缩放、偏移
- 临近帧融合:在标注帧附近的矢状位帧上进行定位或者分类,应该没有太大的差别。所以可以将标注帧附近的帧与标注帧对齐后单独或随机插值产生新的图像进入训练。
2.5 关键代码
2.5.1 定位训练时附加4个定位中心真值的计算
- 找到定位中心的放置方式,使所以点中最大的到最近定位中心的距离最小。没有找到最优的放置方式,用程序遍历找到一个总小于0.3的放置方式。
- 特征图真值设置。标注点位置减去定位中心偏移量之后其他照旧即可
2.5.2 根据距离做标签平滑
v1-v4的标签用0-3的整数表示,设标注的标签真值为L,
第i个分类到标注标签的距离: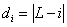
各分类的真值设置为: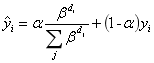
2.5.3 标注帧临近的矢状位帧融合增强
标注帧上标注点位置换算到3D世界坐标系后,投影到临近帧上,作为临近帧上标注点的位置。从标注点中找到形成最大三角形的三个顶点,用这三个顶点在标注帧上的位置和在临近帧上的位置计算仿射变换矩阵,通过这个仿射变换矩阵将临近帧与标注帧对齐。
对齐之后,临近帧与标准帧随机比例的插值融合得到增广的训练图像进入训练。
2.6 比赛经验总结和感想
本次比赛收获很多,业务上了解了深度学习在医学图像分析上的应用,算法上对于数据处理、空间变换、模型训练等各方面上都有更深的体会,框架上学习到Analytics Zoo这种统一的平台,设备上体验到了INTER CPU强大的BF16加速。
也有一些遗憾,最大的就是由于前期代码编写得过于丑陋,导致将Analytics Zoo和INTER CPU的BF16加速接入到我比赛代码的过程困难重重,最终未能应用上。但这也为今后的实践带来很多宝贵的失败经验。
第6名 “随便跑跑” - 浙大 - 4人
备注:该团队中2人获得了2020年3月“天池-酒瓶瑕疵检测”第1名。
建模思路
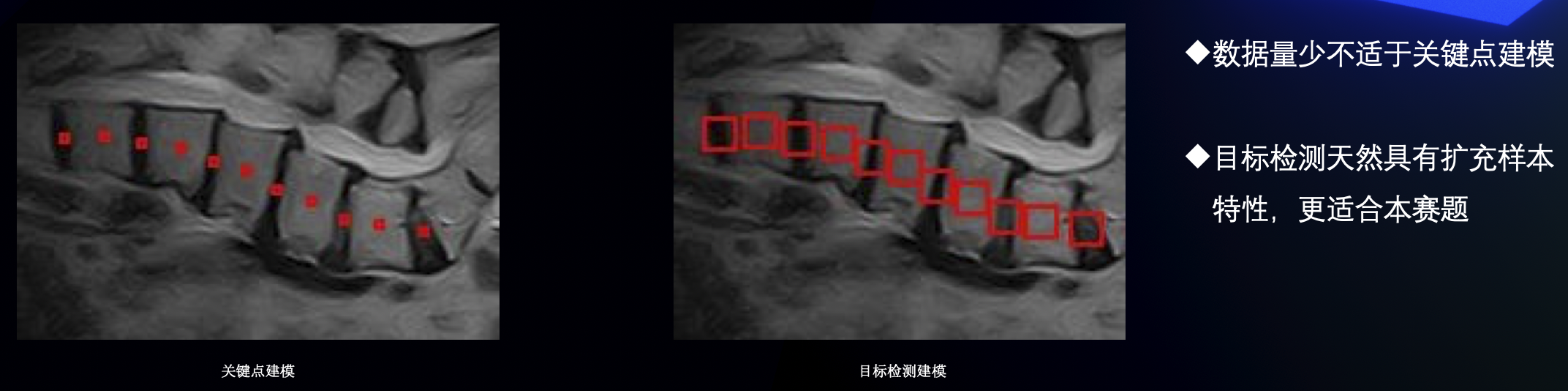
我们队伍把本次比赛当成检测任务来做
算法部分
- 数据方面,我们把每个椎类点外扩做成gt框,最后用一个最小外界矩阵框住所有框。
- 数据增强方面,我们采用了griderase
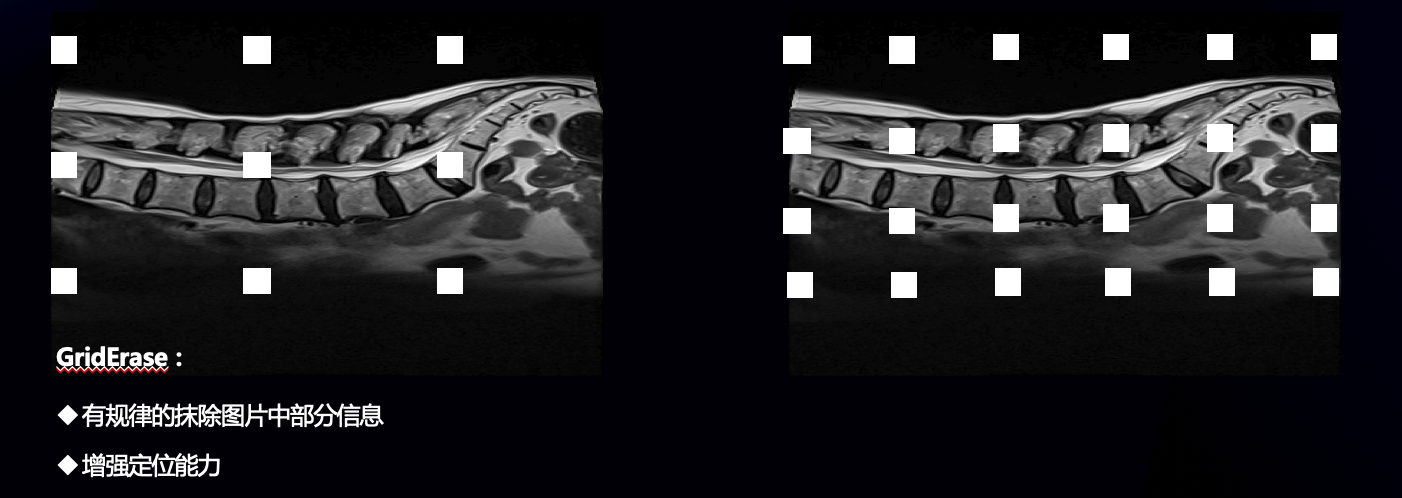
- 模型方面,采用经典的faster r-cnn ,纯pytorch版本,backbone为r50,从而适应cpu训练,具体细节上采用了fpn、多尺度训练和预测、以及bbox voting
- 不work的方面
- r101 以及res2net 101 均不work
- 融合不work
总结
- 工作党太懒,尝试较少,应该更努力
- 测试集太小了,感觉像摸奖,波动极其大,或许有个b榜更好些



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









