







本文紧接《一幅图真正理解LSTM、BiLSTM》,需要RNN,LSTM,BiLSTM的基础。
本文目的:
attention最早用于图像领域,但在NLP领域中发扬光大(主要是2018 年的 BERT 和 GPT ),最近又回归CV领域大放异彩。
现在CV领域越来越多的应用到了transformer(主要是attention),并且分类和检测任务的SOTA模型渐渐被其占领,这似乎是一种趋势,当下有必要对它们的来龙去脉、原理、关键技术做一次初步的系统性剖析。
提示:
- Encoder-Decoder的提出——2014年(Bengio 团队):Cho et al., Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- Seq2Seq的提出——2014年(谷歌):Sutskever et al., Sequence to Sequence Learning with Neural Networks
- attention在Encoder-Decoder中的应用——2014年(Bengio 团队):Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate
目录
2.4 Encoder-Decoder 和 Seq2Seq的区别
1 什么是Encoder-Decoder
Encoder–Decoder是一种解决问题的框架,许多算法中都有该种框架。它并不特值某种具体的算法,而是一类算法的统称,只要是符合上面的框架的算法,都可以统称为 Encoder-Decoder 模型。

- Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
- Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
几点说明:
- 不论输入和输出的长度是什么,中间的“向量c”长度都是固定的,存在丢失信息的可能性。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM等)
- Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
在CV领域中,也经常用到Encoder-Decoder,举2个非常简单且完备的例子:
应用例子1:压缩存储图像
压缩表示非常适合以比存储原始数据更高效的方式保存和共享任何类型的数据。比如,我们可以建立一个卷积自编码器来压缩存储MNIST数据集,编码器部分将由卷积和池化层组成,解码器将由学习“上采样”压缩表示的转置卷积层组成,流程如下:

一个完整的Encoder-Decoder网络的具体实现细节如下:

问题:这东西是怎么压缩存储数据的?
回答:当这个网络训练好后,网络里面所有参数都固定了,那么,我们只要把MNIST数据集中每一张图像经过此网络时,把上图中间那个7x7的池化层的输出特征图保存即可,即,那个位置的特征图就相当于“4”这张28x28图像的压缩信息。后续我们要“复原”图像时,只要把这些特征图通过Decoder层就能得到“4”(当然图像清晰图没有原图好)。这个例子中,原始图像的大小是28x28x1 = 784个浮点数。而特征图是7x7x4(通道)=196个浮点数,所以Encoder后的数据是原始图像大小的25%左右。
应用例子2:图像去噪
原理和功能1类似,只是改下损失函数就能实现图像去噪功能,流程如下:

当网络训练好后,去噪效果如下:

具体代码实现:
- 优达学城《DeepLearning》2-4:自编码器
- https://blog.csdn.net/weixin_42118657/article/details/118026184
2 什么是Seq2Seq
2.1 Seq2Seq 诞生背景
在 Seq2Seq 框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。图像分类领域中输入和输出通常都可以表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
然而许多重要的问题,例如机器翻译、语音识别、自动对话等,表示成序列后,其长度事先并不知道。因此如何突破先前深度神经网络的局限,使其可以适应这些场景,成为了2013年以来的研究热点,Seq2Seq框架应运而生。
2.2 Seq2Seq概念
Seq2Seq( Sequence-to-sequence),就如字面意思,输入一个序列,输出另一个序列,泛指一些Sequence到Sequence的映射问题,并不是一种具体算法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
Seq2Seq特指网络的输入和输出都是“变长序列”。主流的Seq2Seq都是基于Encoder-Decoder来实现的,当然也有另辟蹊径想开宗立派的。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:

如上图:输入了 4 个汉字,输出了 2 个英文单词,输入和输出的长度不同。
2.3 Seq2Seq 的构成及其生效原理
最简单的Seq2Seq用两个RNN即可实现,一个RNN作为encoder,另一个RNN作为decoder。
RNN是可以学习概率分布,然后进行预测,比如我们输入t时刻的数据后,预测t+1时刻的数据,比较常见的是字符预测例子或者时间序列预测。为了得到概率分布,一般会在RNN的输出层使用softmax激活函数,就可以得到每个分类的概率。

2.4 Encoder-Decoder 和 Seq2Seq的区别
- Seq2seq是应用层面的概念,即序列到序列,强调应用场景。
- Encoder-decoder是网络架构层面的概念,特指同时具有encoder模块和decode模块的结构。
- encoder-decoder模型是一种应用于seq2seq问题的模型。
- 目前,Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型的范畴。
总之,它们是两个不同维度的概念。Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
这有点像深度学习目标检测问题,目标检测需要有一个特征提取器,目前特征提取器通常使用CNN,如ResNet 18网络,但并不是说,所有特征提取器一定要用CNN,也并不是说CNN只能用在目标检测领域,它们两者是不同维度的概念。就比如第一章中提到的“图像压缩”和“图像去噪”例子,它们利用了Encoder-Decoder方式,但并不属于Seq2Seq问题。
由于在Seq2Seq提出不久,应该是短短几个月后,常规的attention机制就被应用到Seq2Seq中,所以Seq2Seq的应用放在attention章节中介绍。
3 什么是Attention
先明白一句话:attention本质上是一种实现“注意力”作用的数学建模方法,实现这种功能可以有很多种不同的结构和计算形式,它可以嵌入到Seq2Seq中。还有,就是2017年Google的transformer中用的是Self-Attention和Multi-Head Attention,与2014年初次在Seq2Seq中用的attention不是同一种结构。这其实有点像CNN中特征提取器,刚开始火爆时是归因alexnet网络,后来又出现VGG特征提取器、ResNet特征提取器等,它们结构不一样,但要实现的效果一样。
在我们了解注意力是如何使用之前,请允许我与你分享使用seq2seq模型进行翻译任务背后的直觉。
直觉:seq2seq
翻译员从头到尾阅读德语文本。一旦完成,他开始逐字逐句地翻译成英语。如果这个句子非常长,他很可能已经忘记了他在前面读到的内容。
这是一个简单的seq2seq模型。我要进行的注意力层的逐步计算是一个seq2seq+attention模型。这里有一个关于这个模型的快速直觉。
直觉: seq2seq + attention
翻译员在从头到尾阅读德语文本的同时写下关键词,然后开始翻译成英语。在翻译每一个德语单词时,他会利用他写下的关键词。
3.1 attention概述
- 诞生时间:attention机制并不是一个新概念,在很久之前(90年代)就有学者提出,最早应用在图像领域。
- 意义:在机器翻译领域,attention机制的成功应用,取得了巨大成功,几乎是神经网络方法超越传统方法的分水岭。
- 作用:
- Attention机制可以让神经网络更多的关注到输入中相关的信息,并减少对无关信息的注意。就像当我们看一副图,我们往往会对其中感兴趣的那部分更加注意,Attention机制也以类似的方式帮助神经网络更好的利用输入的信息。
- 有助于提升模型的可解释性。
3.2 attention诞生背景
2014年, Seq2Seq模型正式提出, 并以其优异的表现席卷了机器翻译领域,但是Seq2Seq模型还是有一些问题:
- 信息有很多损失:Encoder 和 Decoder 之间只通过一个固定长度的语义向量 C 来唯一联系。也就是说,Encoder 把输入的整个序列的信息都压缩进一个固定长度的向量中,存在两个弊端:一是语义向量 C 可能无法完全表示整个序列的信息;二是先输入的信息容易被后输入的信息覆盖掉,输入的序列越长,该现象就越严重。
- 没有侧重点:我们知道的是每一句话都有其侧重点,那翻译当然也应该注意其侧重点,不应该是每一个词在一个句子中都具有同等地位。
3.3 attention的结构和全过程
我们先看普通的Seq2Seq在做翻译任务时的样貌:(注意:翻译解码部分只是一种示意)

我们再看Seq2Seq + attention(全局attention类型,且没有学习参数)是什么样的:

仔细看上图的左上角attention模块内部细节,其之所以能有“注意力”这一功能,本质上是由于里面有个softmax,各时序的score通过softmax输出的权重不一样,加权求和后,就有种“注意力”功能了。
由于attention只是一种数学建模机制,它的结构和算子灵活多变,所以上图我只绘制了一种不带学习参数的全局attention原理图,绘图参考的是:《动画图解Attention机制,让你一看就明白》。
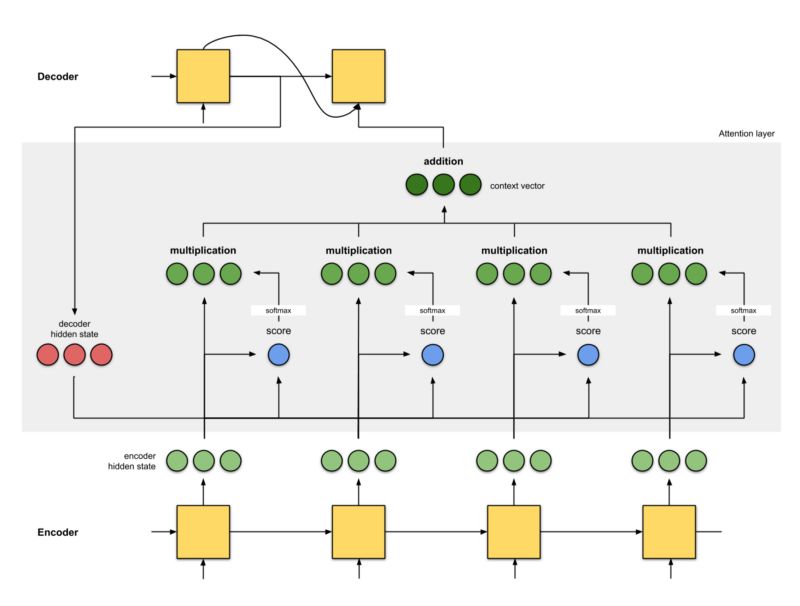
要在attention层中加学习参数其实很容易理解,就像LSTM中一样,可以在一些地方巧妙的加几个全连接层和激励函数。
attention真正火爆,应该是2017年Google论文《Attention Is All You Need》,里面提出了Transformer结构,以及Self-Attention和Multi-Head Attention的概念。
下一篇文章,我将详细梳理Self-Attention、Multi-Head Attention和Transformer!
更详尽和有深度的参考资料:
-
(attention机制绘图参考)动画图解Attention机制,让你一看就明白https://mp.weixin.qq.com/s?__biz=Mzg5ODAzMTkyMg==&mid=2247485860&idx=1&sn=e926a739784090b3779711164217b968
-
(详细讲解了机器翻译的全过程!)全面解析RNN,LSTM,Seq2Seq,Attention注意力机制https://zhuanlan.zhihu.com/p/135970560
-
(综合性较好的)Seq2Seq 编码器-解码器模型与注意力机制https://zhuanlan.zhihu.com/p/136597401















 2586
2586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









