







本地部署 Langchain-ChatGLM
前言
最近在学习Langchain这个框架,在Github上看到这个项目,简单记录一下:
项目主页:
https://github.com/chatchat-space/Langchain-Chatchat?tab=readme-ov-file
简介&原理
ChatGLM就不用再介绍了,前面已经本地化部署了。Langchain的一个简单说明:

应用场景
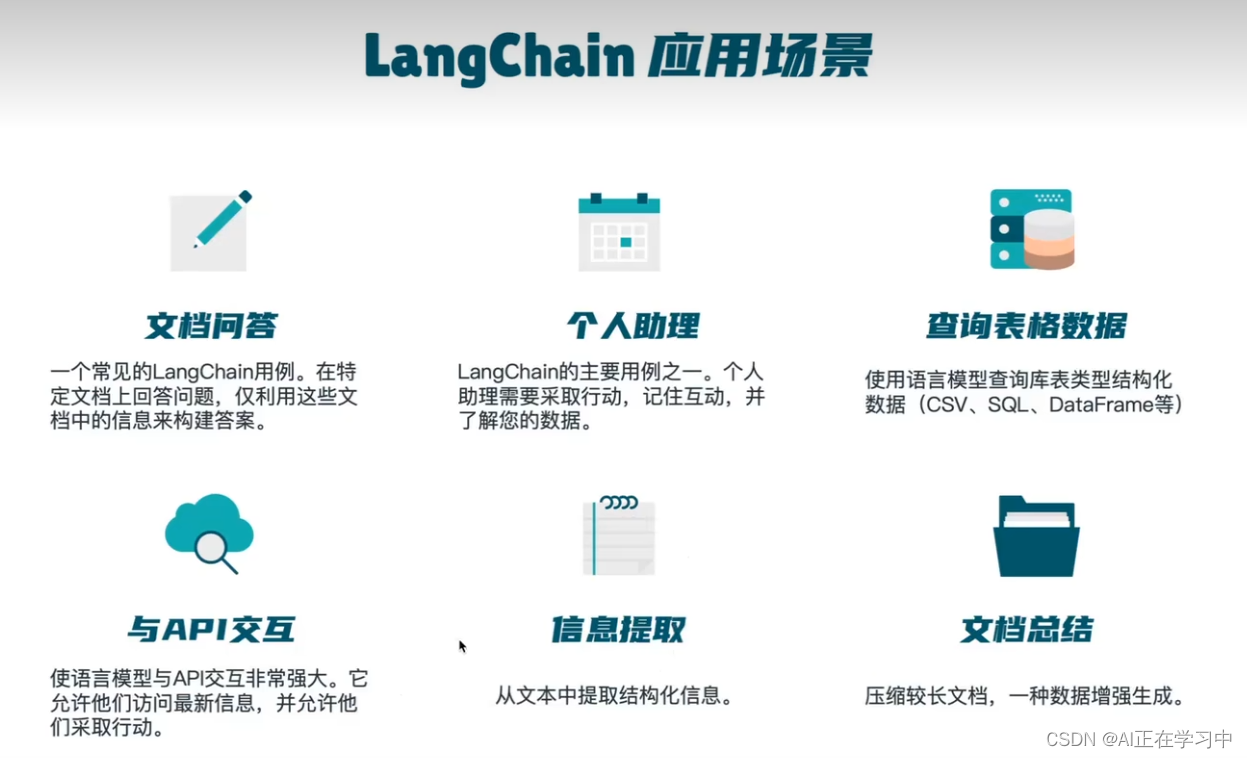
该项目的一个实现思路:

这里我是观看了官方的一个介绍视频,来解释该项目的原理的,其实很简单,就是将本地的多个文档,读入数据集,再进行文本切割,并做一些其他的处理,存入到向量数据库。在进行问答时候,用用户的检索词也去生成向量,再将这个向量与之前存储的知识库向量进行匹配,取出前K最相关的知识片段作为输入给大大模型的prompt的一部分。生成回答,返回给用户。项目中原理介绍如下:

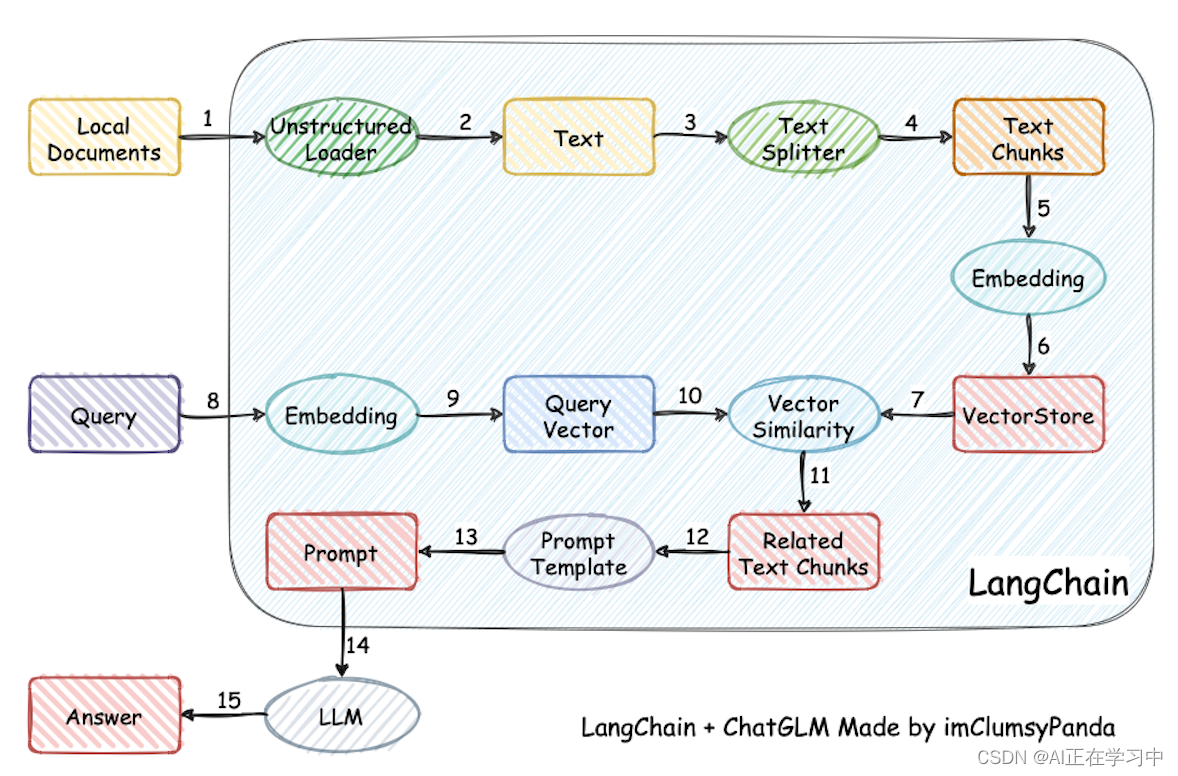
开始部署
我们先用conda建立一个虚拟环境:
conda create --name langchain_chatglm python=3.11
切换到虚拟环境:
conda activate langchain_chatglm

用git bash拉取项目
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
拉取完成就能看到项目了:
进入目录:
cd Langchain-Chatchat

安装依赖:
pip install -r requirements.txt
pip install -r requirements_api.txt
pip install -r requirements_webui.txt
ok 没有任何报错!
接下来我们开始配置
用pycharm打开项目:
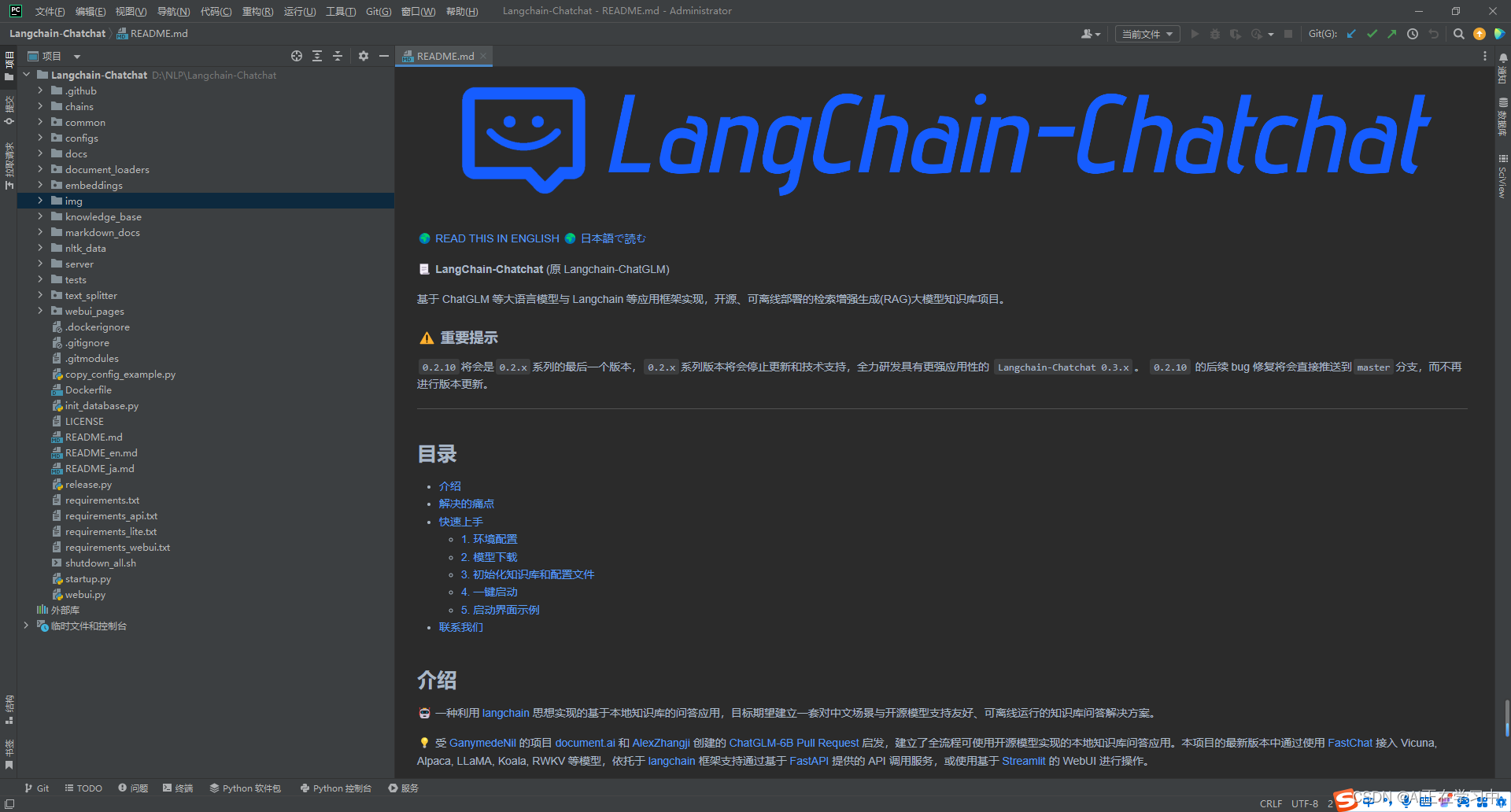
选择我们建立的虚拟环境中的python解释器
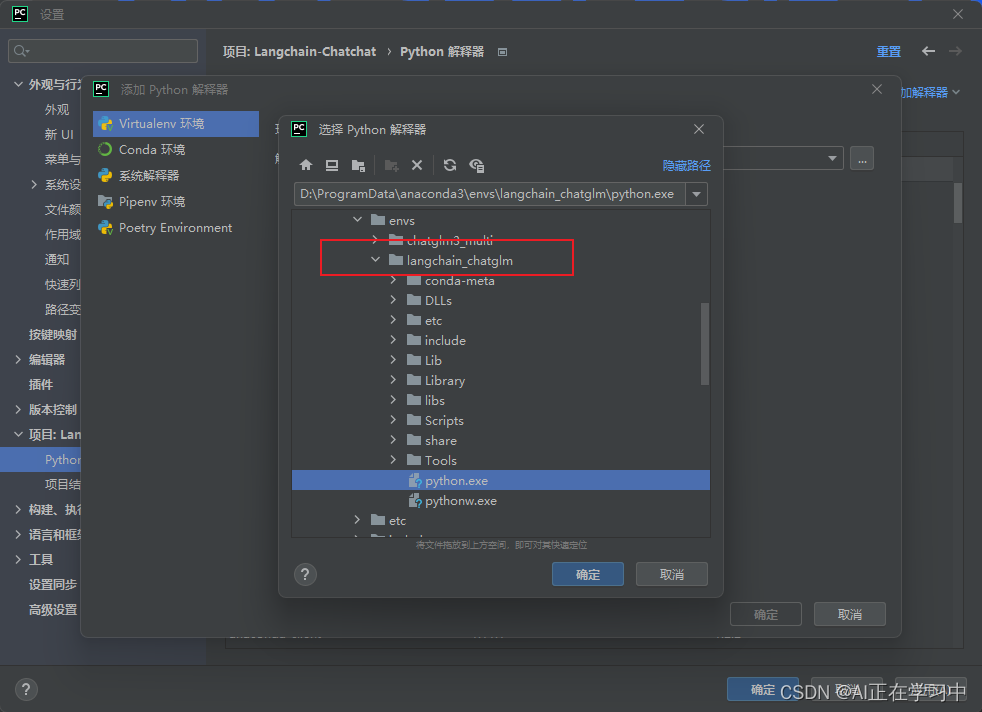
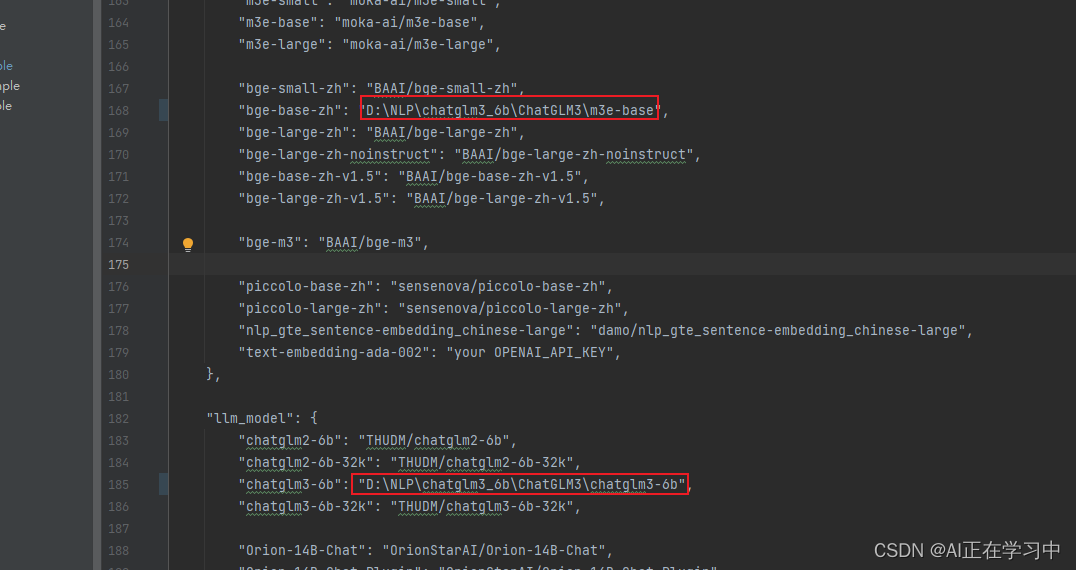
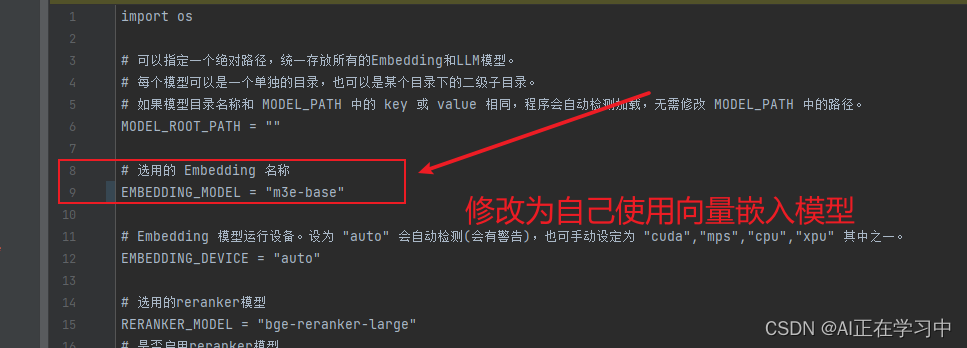
配置文件中修改路径:
按官方文档,启动模型:
运行命令:
python copy_config_example.py
python init_database.py --recreate-vs

可以看到模型正在加载中。
证明路径没有问题,开始加载模型了…

执行完毕!
运行启动模型命令:
python startup.py -a

模型正在启动;
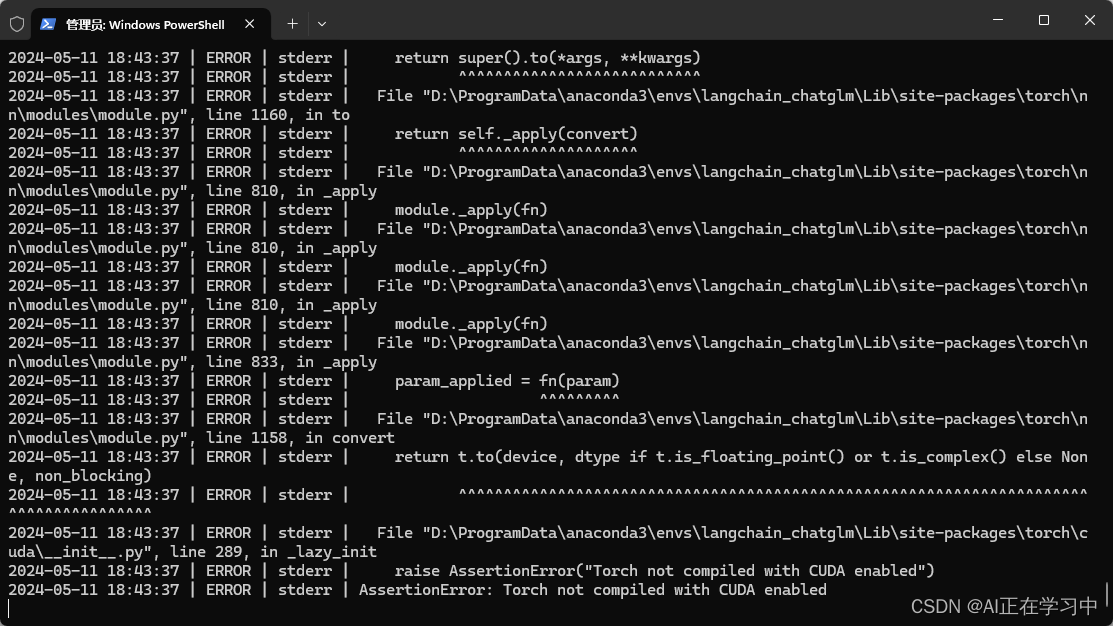
报错问题:没有安装GPU版本的torch
但是后边报错了,看这些日志信息,好像是没有安装cuda的加速服务。
因此我们安装GPU版本的torch。按照之前的方法:
在网址:https://pytorch.org/get-started/previous-versions/
找到安装命令:
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=12.1 -c pytorch -c nvidia
下载中:
再次启动,依次执行:
python copy_config_example.py
python init_database.py --recreate-vs
python startup.py -a
启动过程中看看GPU的状态:
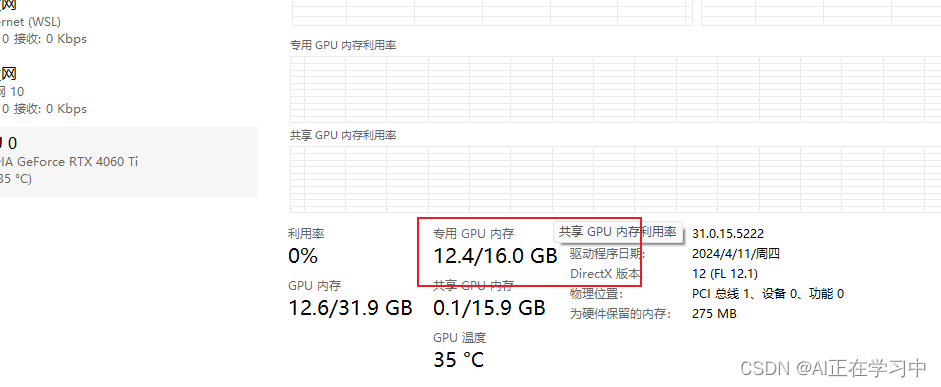
证明模型已经在运行了!
启动成功后,成功弹出项目地址:
ok,
测试,简单的尝试一下
对话
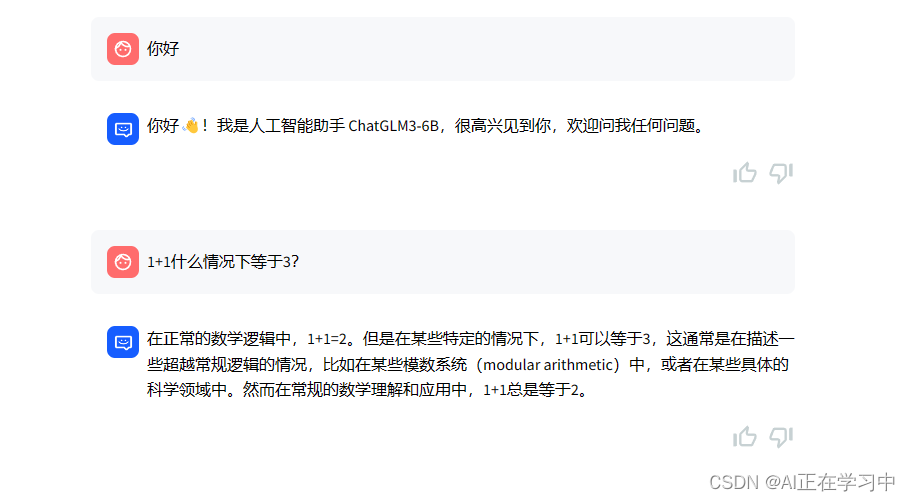
没有问题
知识库管理
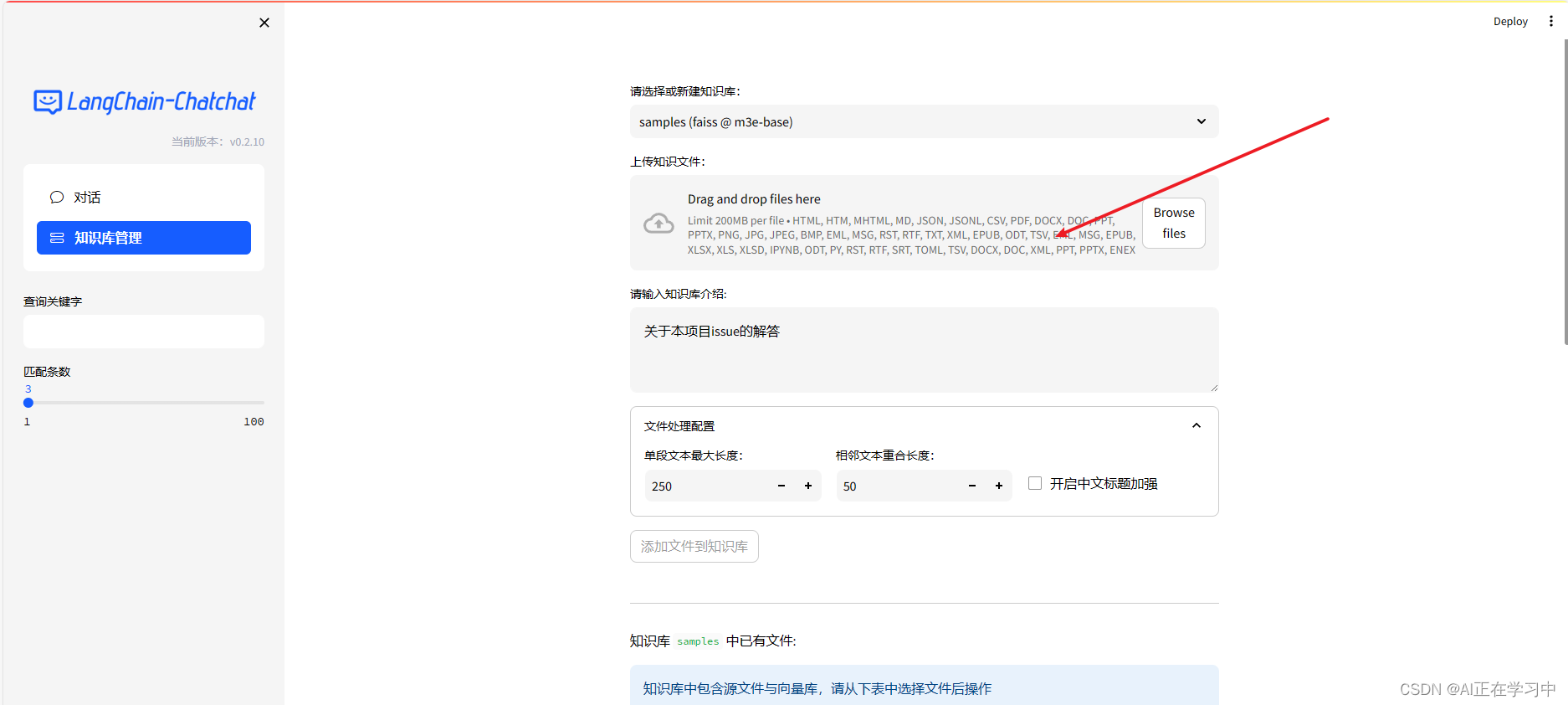
重建向量库:
保存更改
比较知识库添加前后的问题答案
添加知识库之前的回答:
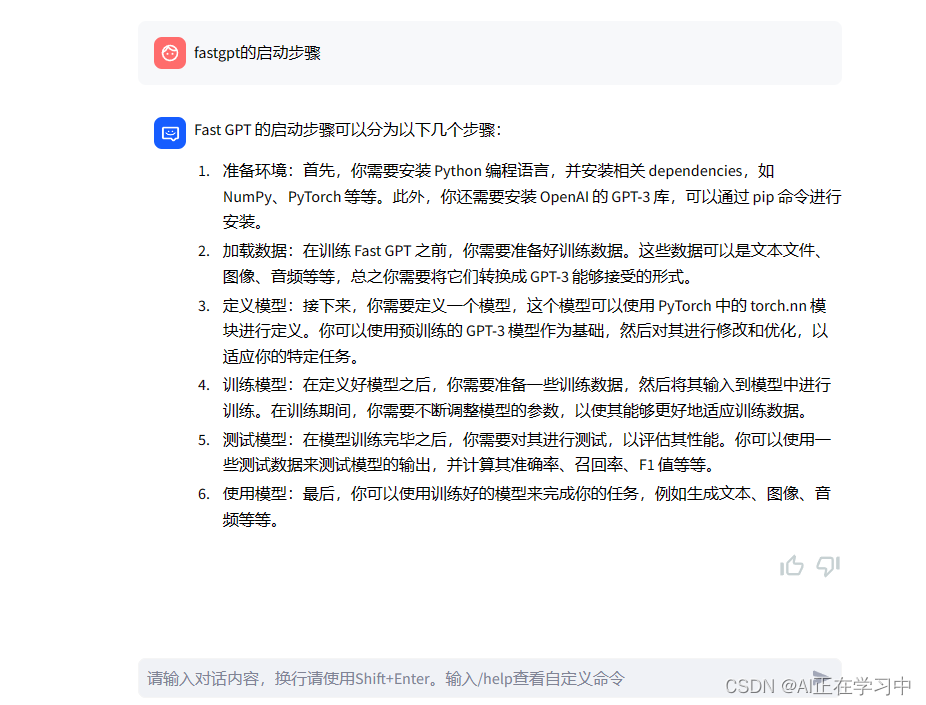
添加知识库之后的回答:

总结
根据以上的测试,感觉没有很大的差别,仔细想想该项目的实现原理,仅仅是增强了prompt的背景知识,整个回答还是语言模型生成的,就不难理解了,该项目不会从根本上改变大模型的回答,仅仅是会向期望的回答上靠拢了一点点,如果需要更加精确和具有专业知识的模型,还是需要进行大模型微调。















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









