







举例说明泰勒展开的用法,论文中经常用到这类优化方法
引入Factor Group-Sparse Regularization for Efficient
Low-Rank Matrix Recovery-NeurIPS中的supplement-公式(64)
A
t
=
argmin
A
∥
A
∥
2
,
1
+
μ
2
∥
X
t
−
A
B
t
−
1
−
E
t
−
1
+
μ
−
1
Y
t
−
1
∥
F
2
\boldsymbol{A}_t=\underset{\boldsymbol{A}}{\operatorname{argmin}}\|\boldsymbol{A}\|_{2,1}+\frac{\mu}{2}\left\|\boldsymbol{X}_t-\boldsymbol{A} \boldsymbol{B}_{t-1}-\boldsymbol{E}_{t-1}+\mu^{-1} \boldsymbol{Y}_{t-1}\right\|_F^2
At=Aargmin∥A∥2,1+2μ∥
∥Xt−ABt−1−Et−1+μ−1Yt−1∥
∥F2
要化为可求解形式 ∥ A ∥ 2 , 1 + ∥ A − K ∥ F 2 \|{A}\|_{2,1} + \|A-K\|_{F}^{2} ∥A∥2,1+∥A−K∥F2 的形式。
我们已知泰勒展开式为
f
(
x
)
=
f
(
x
0
)
+
f
(
1
)
(
x
0
)
(
x
−
x
0
)
+
f
(
2
)
(
x
0
)
(
x
−
x
0
)
2
2
!
+
.
.
.
+
f
(
n
)
(
x
0
)
(
x
−
x
0
)
n
n
!
f(x)=f(x_{0})+f^{(1)}(x_{0})(x-x_{0})+\frac{f^{(2)}(x_{0})(x-x_{0})^{2}}{2!}+...+\frac{f^{(n)}(x_{0})(x-x_{0})^{n}}{n!}
f(x)=f(x0)+f(1)(x0)(x−x0)+2!f(2)(x0)(x−x0)2+...+n!f(n)(x0)(x−x0)n
此时,将
μ
2
∥
X
t
−
A
B
t
−
1
−
E
t
−
1
+
μ
−
1
Y
t
−
1
∥
F
2
\frac{\mu}{2}\left\|\boldsymbol{X}_t-\boldsymbol{A} \boldsymbol{B}_{t-1}-\boldsymbol{E}_{t-1}+\mu^{-1} \boldsymbol{Y}_{t-1}\right\|_F^2
2μ∥
∥Xt−ABt−1−Et−1+μ−1Yt−1∥
∥F2当作
f
(
A
)
f(A)
f(A),就有
f
(
x
)
=
f
(
x
0
)
+
f
(
1
)
(
x
0
)
(
x
−
x
0
)
+
f
(
2
)
(
x
0
)
(
x
−
x
0
)
2
2
!
+
.
.
.
+
f
(
n
)
(
x
0
)
(
x
−
x
0
)
n
n
!
f(x)=f(x_{0})+f^{(1)}(x_{0})(x-x_{0})+\frac{f^{(2)}(x_{0})(x-x_{0})^{2}}{2!}+...+\frac{f^{(n)}(x_{0})(x-x_{0})^{n}}{n!}
f(x)=f(x0)+f(1)(x0)(x−x0)+2!f(2)(x0)(x−x0)2+...+n!f(n)(x0)(x−x0)n
此时,将
μ
2
∥
X
t
−
A
B
t
−
1
−
E
t
−
1
+
μ
−
1
Y
t
−
1
∥
F
2
\frac{\mu}{2}\left\|\boldsymbol{X}_t-\boldsymbol{A} \boldsymbol{B}_{t-1}-\boldsymbol{E}_{t-1}+\mu^{-1} \boldsymbol{Y}_{t-1}\right\|_F^2
2μ∥
∥Xt−ABt−1−Et−1+μ−1Yt−1∥
∥F2看作
f
(
A
)
f(A)
f(A),有
f
(
A
)
=
f
(
A
t
−
1
)
+
<
Q
,
A
−
A
t
−
1
>
+
L
t
2
∥
A
−
A
t
−
1
∥
F
2
f(A)=f(A_{t-1})+<Q,A-A_{t-1}>+\frac{L_t}{2}\|A-A_{t-1}\|_F^2
f(A)=f(At−1)+<Q,A−At−1>+2Lt∥A−At−1∥F2
(最多是F范数,就停到了二阶导)
其中,Q是
f
(
A
)
f(A)
f(A)的一阶导,
L
t
L_t
Lt满足>=Hessian矩阵(二阶导,西瓜书253页)
有
Q
=
μ
(
X
−
t
−
A
t
−
1
B
t
−
1
−
E
t
−
1
+
μ
−
1
Y
t
−
1
)
(
−
B
t
−
1
T
)
,
Q=\mu(X-t-A_{t-1}B_{t-1}-E_{t-1}+\mu^{-1}Y_{t-1})(-B_{t-1}^T),
Q=μ(X−t−At−1Bt−1−Et−1+μ−1Yt−1)(−Bt−1T),
L
t
≥
μ
∥
B
t
−
1
∥
F
2
.
L_t \geq \mu\|B_{t-1}\|_F^2.
Lt≥μ∥Bt−1∥F2.
综上,有
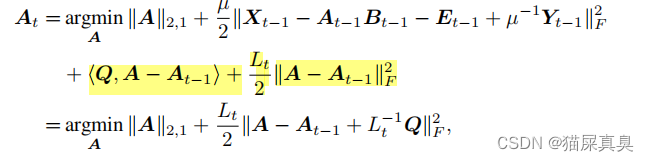















 7115
7115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









