







2021-01-10 18:21:55

作者 | JayLou娄杰
这次解读的论文来自陈丹琦团队,一作曾是清华特奖得主@高天宇;借鉴GPT-3的核心思想,探索小样本微调方法。
2020年引领NLP社区的GPT-3[1]在众多语言理解任务中展现了惊人能力。GPT-3 仅仅通过一个自然语言提示(prompt)和少量的任务示例就可以作出正确的预测,值得注意的是:这一过程不需要更新预训练模型的参数权重。
虽然GPT-3表现惊艳,但有一点很明显:拥有1750亿参数(如此重量)在真实世界也是很难应用!更何况,据说GPT-4会有上万亿参数?
哎,GPT-3落地还是比较困难啊~
不过,就在2020年最后一天12月31日,陈丹琦团队发表了最新力作《Making Pre-trained Language Models Better Few-shot Learners》。

本文研究了一个更符合实际场景的小样本学习问题:1)可以在普通硬件资源上访问中等大小的语言模型(如RoBERTa);2)可以通过少量样本进行微调。
其实,自BERT等预训练语言模型诞生以来,本身就降低了对大规模标注数据量的需求;此外,获得少量的标注样本(比如每个类别16个样本),对我们也是很容易的。
因此,我们可以试想一下:如果能基于小样本对语言模型微调就能获得不俗表现,是不是极具现实意义呢?(boss再也不用担心标注成本啦~)
这不,丹琦女神团队借鉴GPT-3思想(引入提示和样本示例),提出了一种基于语言模型的小样本微调方法(LM-BFF),该方法在低资源设置下,比普通的标准微调方法最高提升30%、平均提升11%!提升如此明显,LM-BFF也有两种“贴切”解释:
-
better few-shot fine-tuning of language models(正经一些)
-
languagemodels’bestfriendsforever (俏皮一些)
本篇专栏文章,JayJay就以QA形式和大家分享丹琦团队是如何构建小样本微调框架的。
论文地址:https://arxiv.org/pdf/2012.15723.pdf
Github开源:https:// github.com/princeton-nlp/LM-BFF
Q1: 小样本微调框架是怎样的?
LM-BFF就是一套针对小样本进行微调的简单技术,主要包括两部分:
-
基于提示(prompt)进行微调,关键是如何自动化生成提示模板;
-
将样本示例以上下文的形式添加到每个输入中,关键是如何对示例进行采样;

LM-BFF的基本方式如上图所示,红框部分就是提示模板,蓝框部分就是额外的样本示例。
Q2:为什么要通过「提示模板」构建MLM任务呢?
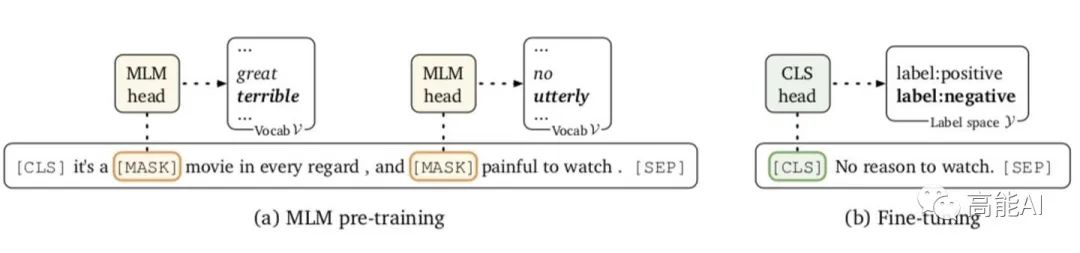
在普通的标准微调方法中(如上图b所示),新参数的数量(独立于原始预训练模型外的参数)可能会很大,例如基于RoBERTa-large的二分类任务会新引入2048个参数,会使从小样本(如32个标注数据) 中学习变得困难。
为解决这一问题,LM-BFF借鉴masked language model (MLM) 方式(如上图a所示),将下游任务直接转化为MLM任务,即:通过语言模型对「提示模板」进行“自动补全”。这也是论文所称的「基于提示的微调方法」。
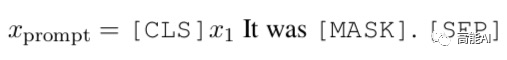
具体地:首先构建如上图的提示模板,[MASK]包含在提示模板中;然后对[MASK]预测,预测输出是标签词(label words),与具体标签建立映射关系:例如,标签positive对应单词great,标签negative对应单词terrible。
值得注意的是:上述方法重新使用了预先训练的参数权重,并且没有引入任何新参数来进行微调。同时还减少了微调和预训练之间的差距,这可以更有效地用于小样本场景。
Q3:为何「提示」选择如此重要、又很困难?
由上述分析,我们可以得知「提示」由两部分构成:
-
模板T:例如It was [MASK] 。
-
标签词映射M(y):即[MASK]位置预测输出的词汇集合,与真实标签y构成映射关系。例如,标签positive对应单词great,标签negative对应单词terrible。
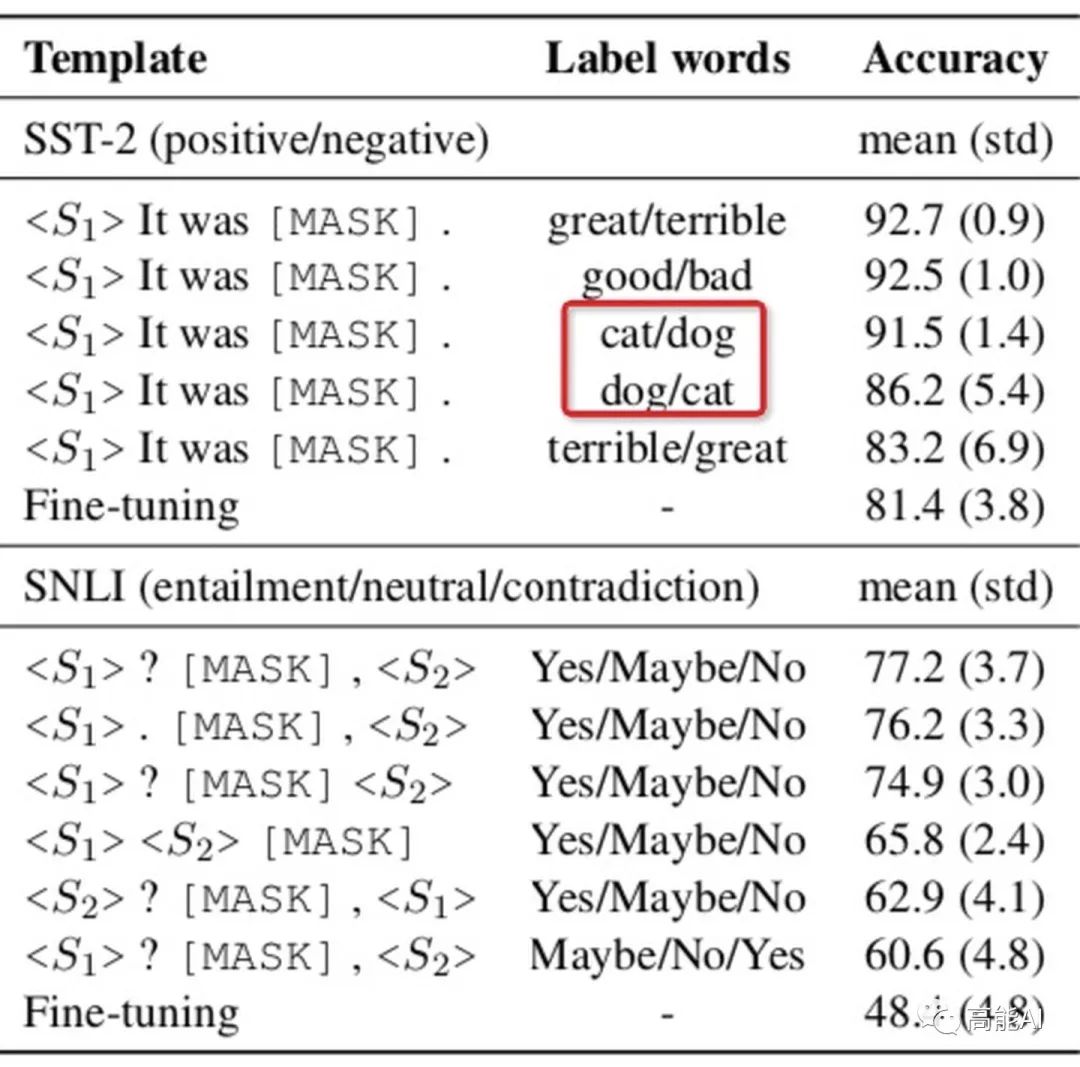
在基于提示的微调方法中,不同的模板和标签词选择其实对最终结果影响很大,如上图所示:
-
使用相同「标签词」,即使对「模板」进行较小改动(如删除标点)也会呈现不同结果;
-
使用相同「模板」,不同的「标签词」效果不一样,例如cat/dog和dog/cat就不同了,而互换great和terrible指标则会大幅下降。
上述「模板」是根据人工直觉设计的,可以更好的完成相关类似任务。但是,找到一个合适的、正确的「提示」,既需要专业知识、又需要对语言模型内部的运作方式有着充分的理解。
其实,针对不同任务,就人工手动设计提示「模板」或者「标签词」,是一件费力不讨好的事情,因为人工模板也不一定奏效~ 因此,我们应该试图去自动化构建提示:自动构建一种与任务无关的廉价方法。
BUT!「提示」的搜索空间很大,尤其是「模板」。这很容易理解,毕竟模板千千万,选择哪个很费劲~此外,当只有少量标注数据进行模板搜索时,很容易导致过度拟合。
综上所述:「提示」选择虽然很重要,但自动化构建却很难。论文针对这一点提出了有效方法。
Q4:如何自动化构建「提示」?
自动化构建「提示」分为「标签词」和「模板」的构建。自动化构建的目的是削减人工设计「提示」的工作,并找到超越手动构建的「最佳提示」。
1、自动化选择「标签词」
自动化构建「标签词」,即固定模板、选择最佳的标签词映射关系M,使得在验证集的分类准确率最高。
由于「标签词」搜索空间随着类别数目呈指数增加,LM-BFF采用一种简单的搜索策略:
第一步:通过未经微调的预训练模型,对于训练集中的每一个类别,选择top-k的单词使得条件概率最大:
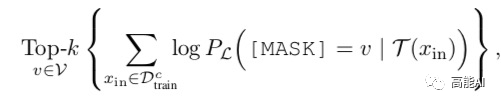
第二步:综合每个类别下的候选标签词,然后找出使得训练集正确率最大的top-n个分配方式;
第三步:通过对dev集微调,从n个分配方式中选择最佳的一个标签词,构建标签映射关系M。
2、自动化选择「模板」
自动化构建「模板」,即固定标签词构建模板。LM-BFF使用Google提出的T5模型[2]进行解码,从而生成模板。
T5基于多种无监督目标进行预训练,其中最有效的一个无监督目标就是:利用<X>或<Y>替换一个或多个连续span,然后生成对应输出。例如:在“Thank you <X>me to your party <Y>week ”,T5会在<X>生成“for inviting ”、在<Y>生成“last ”。
很显然,T5这种方式很适合生成模板,不需要指定模板的token数目。具体,依然利用<X>或<Y>作为mask tokens,1种可能的输入方式为:
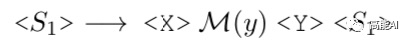
然后我们就可以基于T5去填充占位符<X>和<Y>,生成提示模板T。生成的模板应该是训练集中的输出概率最大化。具体的模板生成过程如下图所示:
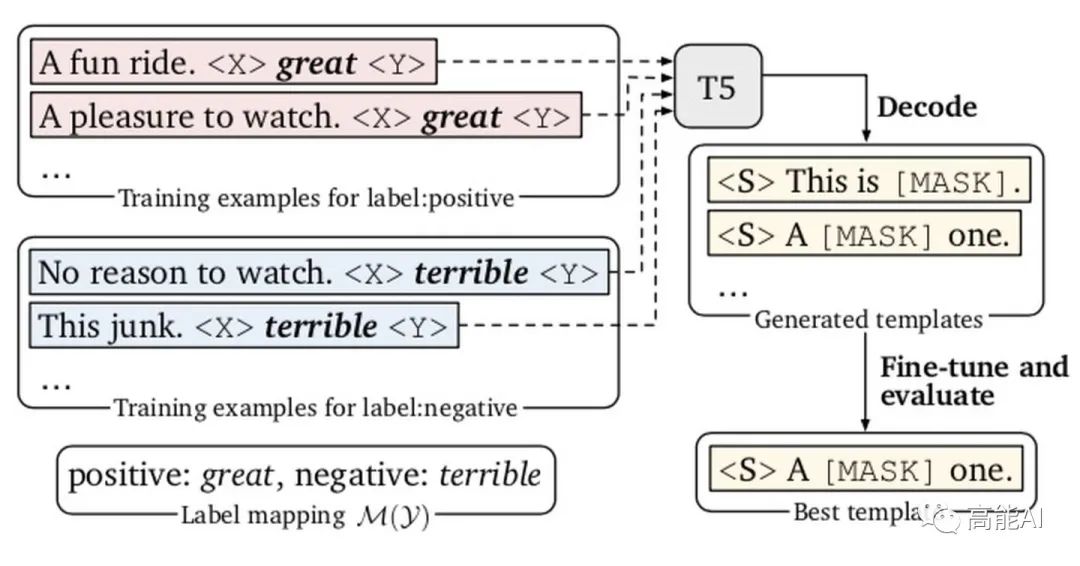
论文采用柱搜索来解码生成多个候选模板,然后对每一个候选模板利用dev集微调、选择其中一个最佳模板。
尽管在每个模板上微调模型似乎很昂贵,由于训练集较小,这与手动生成提示模板并进行调整相比:这种方式在实践中是快速的、完全自动化的。
Q5:如何基于「样本示例」进行微调?
在GPT-3中,是从训练集中随机抽取32个示例,以上下文的形式添加到每个输入中的;这种方式的缺陷在于:
-
样本示例的数量会受到模型最大输入长度的限制;
-
不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
LM-BFF采用2种简单的方式进行了改进:
-
对于每个输入,从每个类别中随机采样一个样本示例,最终将所有类别下的采样示例进行拼接输入;
-
对于每个输入,在每个类别中,通过与Sentence-BERT进行相似度计算、并从排序得分的top50%中随机选择一个样本示例。
Q6:实验结果:LM-BFF性能如何?
为验证LM-BFF的有效性,论文在8个单句、7个句子pair任务上进行了小样本验证(每个类别下,采取15个标注样本),实验采用RoBERTa-large模型。
首先介绍进行对比的各个方法:
-
Majority:使用训练集中频率最高的类别最为result;
-
Prompt-based zero-shot:零样本设置,使用手动设计的模板、并不引入额外的样本示例;
-
“GPT-3” in-context learning:零样本设置,使用手动设计的模板,与GPT-3相同,从训练集中随机抽取示例,以上下文的形式添加到每个输入中。
-
Fine-tuning:小样本设置,标准微调方式,引入新的参数。
-
Fine-tuning(full):使用全量的标注数据进行标准微调;
-
Prompt-based FT(man):本文微调方法,使用人工手动设计的提示模板;
-
Prompt-based FT(auto):本文微调方法,自动构建提示模板;
-
+demonstrations:代表引入额外样本示例到上下文中;
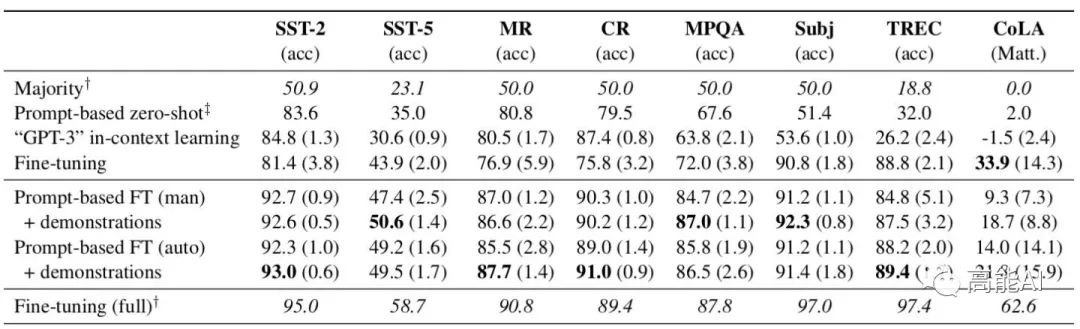
如上图所示,我们可以发现:
-
基于提示模板的微调方法,明显超越普通的标准微调方法;自动构建的模板能够匹敌、或者超过手动模板。
-
利用额外的样本示例,指标可在绝大数任务上保持增益;LM-BFF方法相较于标准微调,最高可提升30%,平均提升11%。
-
虽然在小样本条件下,LM-BFF可大幅领先标准微调,但其相较于使用全量数据的标准微调仍然落后。
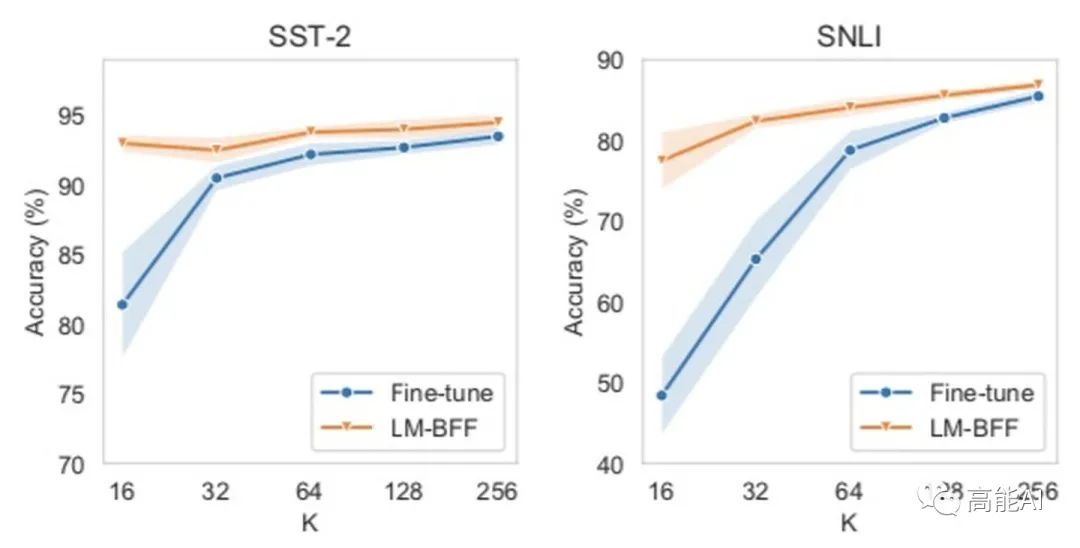
此外,论文也将LM-BFF和标准微调在不同K(每个类别下的标注样本数量)下进行了比较,如上图所示。可以发现:不同K下,LM-BFF都领先标准微调。可见LM-BFF方法在小样本条件下的有效性。
总结
本文提出了一种简单而又有效的小样本微调方法——LM-BFF,这是一种任务无关的方式,在小样本设置下,LM-BFF超越「标准微调」平均11%(最高30%)。主要包括2部分:
-
采用提示自动构建方式来进行「基于模板的微调方法」。
-
动态选择样本示例,作为输入的上下文。
但LM-BFF也有以下缺陷:
-
LM-BFF仍落后基于全量标注数据的标准微调方法(PS:废话,数据目前还是越多好~)
-
LM-BFF自动构建提示的方法虽然有效,但扩展搜索空间在现实应用中仍是一个巨大挑战;
-
LM-BFF仅支持几种特定的任务:1)能自然转化为「空白填空」问题,如结构化预测的NER任务可能就不适合;2)句子输入不要太长;3)不要包含过多的类别;其中2)和3)可以在长距离语言模型中进行改善。
参考文献
[1] Language models are few-shot learners
[2] Exploring the limits of transfer learning with a unified text-to-text trans- former.















 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









