







TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
摘要
本文提出了时间图网络(TGNs),这是一种通用的,有效的框架,可用于对以时间事件序列表示的动态图进行深度学习。
贡献
- 提出了时间图网络(TGN)的通用归纳框架,该框架在以事件序列表示的连续时间动态图上运行,并表明许多以前的方法都是TGN的特定实例。
- 新颖的训练策略,允许模型从数据的顺序中学习,同时保持高效的并行处理。
- 作者对框架的不同组成部分进行了详细的ablation study,并分析了速度和准确性之间的权衡。
- 作者展示了在归纳和归纳设置下多个任务和数据集的最新性能,同时比以前的方法要快得多。
背景
静态图表示学习
静态图 G = ⟨ V , E ⟩ G=\langle V,E\rangle G=⟨V,E⟩包含节点 V = { 1 , . . . , n } V=\{1,...,n\} V={1,...,n}以及边 E ⊆ V × V E\subseteq V \times V E⊆V×V,节点和边都包含特征表示为 v i v_i vi和 e i j e_{ij} eij。
对于GNN来说为了得到embedding
z
i
z_i
zi可以使用以下方法来表达:
z
i
=
∑
j
∈
N
i
h
(
m
i
j
,
v
i
)
z_i = \sum_{j \in \mathcal{N_i}}h(m_{ij},v_i)
zi=j∈Ni∑h(mij,vi)
m
i
j
=
msg
(
v
i
,
v
j
,
e
i
j
)
m_{ij}=\text{msg}(v_i,v_j,e_{ij})
mij=msg(vi,vj,eij)可以解释为从
i
i
i的邻居
j
j
j传递的消息,
N
=
j
:
(
i
,
j
)
∈
E
\mathcal{N}={j:(i,j)\in E}
N=j:(i,j)∈E表示节点
i
i
i的邻居节点,msg和h是可学习的函数。
动态图表示学习
动态图的模型分为两大类:
- 离散时间动态图(DTDG)
- 连续时间动态图(CTDG)
我们主要研究连续时间动态图(CTDG),我们定义一系列的时间戳事件 G = { x ( t 1 ) , x ( t 2 ) , . . . } G=\{x(t_1),x(t_2),...\} G={x(t1),x(t2),...},每个事件 x ( t i ) x(t_i) x(ti)可以表示为两种类型:
- 节点事件:表示为 v i ( t ) v_i(t) vi(t),表示在 t t t时刻,节点 i i i发生了一个事件 v v v( v v v为事件的向量)。
- 边事件:表示为 e i j ( t ) e_{ij}(t) eij(t) ,表示节点 i i i与节点 j j j之间发生的事件(边的删除将在后续讨论)。
模型
该模型主要学习
t
t
t时刻下,图中节点的embedding信息,即
Z
(
t
)
=
(
z
1
(
t
)
,
.
.
.
,
z
n
(
t
)
(
t
)
)
Z(t)=(z_1(t),...,z_{n(t)}(t))
Z(t)=(z1(t),...,zn(t)(t))。
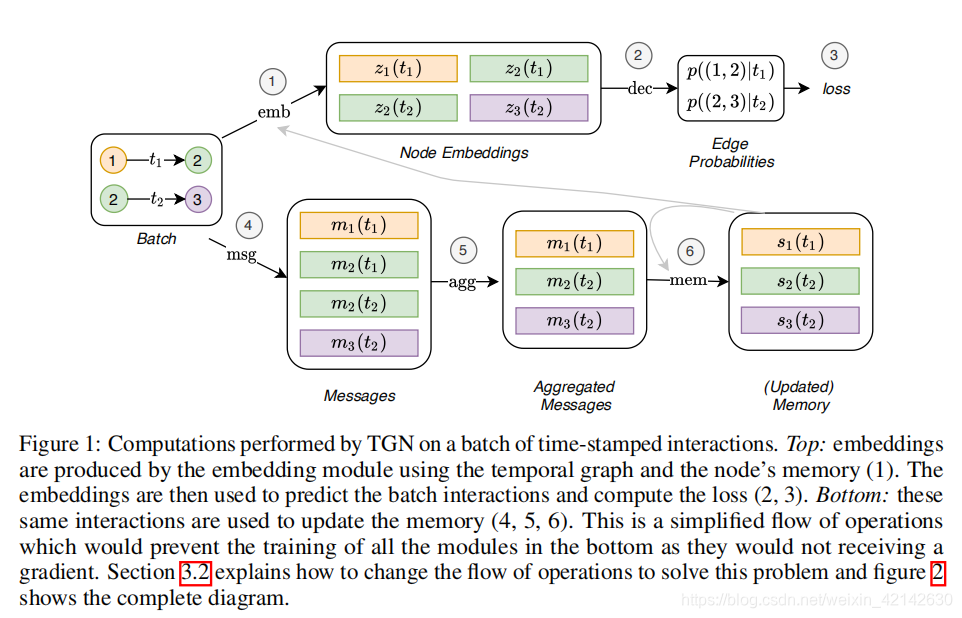
核心模块
Memory
在时间 t t t处,模型的Memory(状态)由模型迄今所见的每个节点的向量 s i ( t ) s_i(t) si(t)组成,代表一个节点的历史信息。1) memory将在一个事件发生后进行更新。2)如果出现一个新的节点,则其内存初始化为0向量。
Message Function
对于每一个包含节点
i
i
i和
j
j
j的事件
e
i
j
(
t
)
e_{ij}(t)
eij(t)而言,则会对应两条消息:
m
i
(
t
)
=
msg
s
(
s
i
(
t
−
)
,
s
j
(
t
−
)
,
Δ
t
,
e
i
j
(
t
)
)
,
m
j
(
t
)
=
msg
d
(
s
j
(
t
−
)
,
s
i
(
t
−
)
,
Δ
t
,
e
i
j
(
t
)
)
m_i(t)=\text{msg}_s(s_i(t^-),s_j(t^-),\Delta t,e_{ij}(t)),\ m_j(t)=\text{msg}_d(s_j(t^-),s_i(t^-),\Delta t,e_{ij}(t))
mi(t)=msgs(si(t−),sj(t−),Δt,eij(t)), mj(t)=msgd(sj(t−),si(t−),Δt,eij(t))如果仅仅是包含节点
i
i
i的事件而言,则会对应一条消息:
m
i
(
t
)
=
msg
n
(
s
i
(
t
−
)
,
t
,
v
i
(
t
)
)
m_i(t)=\text{msg}_n(s_i(t^-),t,v_i(t))
mi(t)=msgn(si(t−),t,vi(t))其中
s
i
(
t
−
)
s_i(t^-)
si(t−)表示节点
i
i
i在
t
t
t之前的memory,
msg
s
\text{msg}_s
msgs,
msg
d
\text{msg}_d
msgd以及
msg
n
\text{msg}_n
msgn都是可学习的参数。
贴别的,删除边事件定义为
(
i
,
j
,
t
′
,
t
)
(i,j,t',t)
(i,j,t′,t)表示节点
i
i
i和节点
j
j
j在
t
′
t'
t′产生边,在
t
t
t删除边。
m
i
(
t
)
=
msg
s
′
(
s
i
(
t
−
)
,
s
j
(
t
−
)
,
Δ
t
,
e
i
j
(
t
)
)
,
m
j
(
t
)
=
msg
d
′
(
s
j
(
t
−
)
,
s
i
(
t
−
)
,
Δ
t
,
e
i
j
(
t
)
)
m_i(t)=\text{msg}_{s'}(s_i(t^-),s_j(t^-),\Delta t,e_{ij}(t)),\ m_j(t)=\text{msg}_{d'}(s_j(t^-),s_i(t^-),\Delta t,e_{ij}(t))
mi(t)=msgs′(si(t−),sj(t−),Δt,eij(t)), mj(t)=msgd′(sj(t−),si(t−),Δt,eij(t))
Message Aggregator
由于效率的原因,作者将多个事件聚合在一起。
m
ˉ
i
(
t
)
=
a
g
g
(
m
i
(
t
1
)
,
.
.
.
,
m
i
(
t
b
)
)
\bar{m}_i(t)=agg(m_i(t_1),...,m_i(t_b))
mˉi(t)=agg(mi(t1),...,mi(tb)) 其中
a
g
g
agg
agg为聚合函数。虽然可以使用可学习的方法进行学习(如RNN或是attention机制),但是作者选择不可学习的方法,例如most recent message(仅保留给定节点的最新消息)和mean message(给定节点的所有消息的平均值)。
Message Updater
主要根据节点的memory和event message进行自我更新
s
i
(
t
)
=
m
e
m
(
m
ˉ
i
(
t
)
,
s
i
(
t
−
)
)
s_i(t)=mem(\bar{m}_i(t),s_i(t^-))
si(t)=mem(mˉi(t),si(t−))对于涉及两个节点
i
i
i和
j
j
j的交互事件,事件发生后将更新两个节点的memory。对于节点事件,仅更新相关节点的内存。在此,
m
e
m
mem
mem是可学习的内存更新功能例如GRU或是LSTM。
Embedding
Embedding模块用于在时间
t
t
t生成节点i的时间嵌入
z
i
(
t
)
z_i(t)
zi(t)。 嵌入模块的主要目的是避免所谓的memory陈旧的问题(即只在事件发生时进行更新memory,那么长时间没有事件的节点memory则会变得不适用)。
通用的Embedding模块如下所示:
z
i
(
t
)
=
e
m
b
(
i
,
t
)
=
∑
j
∈
n
i
k
(
[
0
,
t
]
)
h
(
s
i
(
t
)
,
s
j
(
t
)
,
e
i
j
,
v
i
(
t
)
,
v
j
(
t
)
)
z_i(t)=emb(i,t)=\sum_{j \in \mathcal{n}^k_i([0,t])}h(s_i(t),s_j(t),e_{ij},v_i(t),v_j(t))
zi(t)=emb(i,t)=j∈nik([0,t])∑h(si(t),sj(t),eij,vi(t),vj(t)),其中
h
h
h是可学习参数,包含了如下形式:
- Identity(id): e m b ( i , t ) = s i ( t ) emb(i,t)=s_i(t) emb(i,t)=si(t),直接使用内存作为节点的embedding。
- Time projection(time): e m b ( i , t ) = ( 1 + Δ t w ) ∘ s i ( t ) emb(i,t)=(1+\Delta tw)\circ s_i(t) emb(i,t)=(1+Δtw)∘si(t),其中 w w w为可学习参数, Δ \Delta Δ代表自从上一次交互所发生的时间, ∘ \circ ∘代表元素相乘。
- Temporal Graph Attention(attn):一系列
L
L
L图注意力层通过汇总来自其
L
L
L跳时间邻域的信息来计算节点i的嵌入。
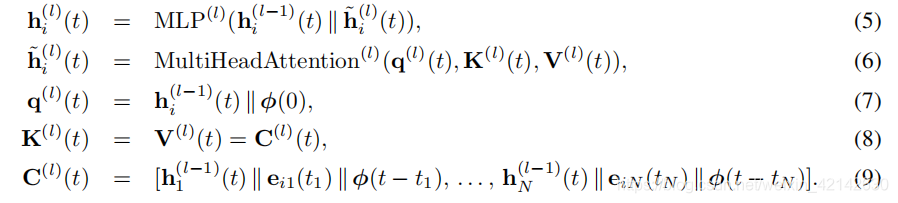
输入到第 l l l层的是 i i i的表征 h i ( l − 1 ) ( t ) h^{(l-1)}_i(t) hi(l−1)(t),当前时间戳 t t t, i i i的时间表征 { h 1 ( l − 1 ) ( t ) , . . . , h N l − 1 ( t ) } \{h_1^{(l-1)}(t),...,h_N^{l-1}(t)\} {h1(l−1)(t),...,hNl−1(t)} - Temporal Graph Sum(sum),本文主要使用以下方式:
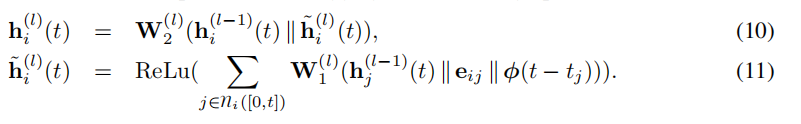
其中, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是时间的embedding信息,而 z i ( t ) = e m b ( i , t ) = h i ( L ) ( t ) z_i(t)=emb(i,t)=h_i^{(L)}(t) zi(t)=emb(i,t)=hi(L)(t)
训练
TGN可以针对各种任务训练TGN,例如边缘预测(自我监督)或节点分类(半监督)
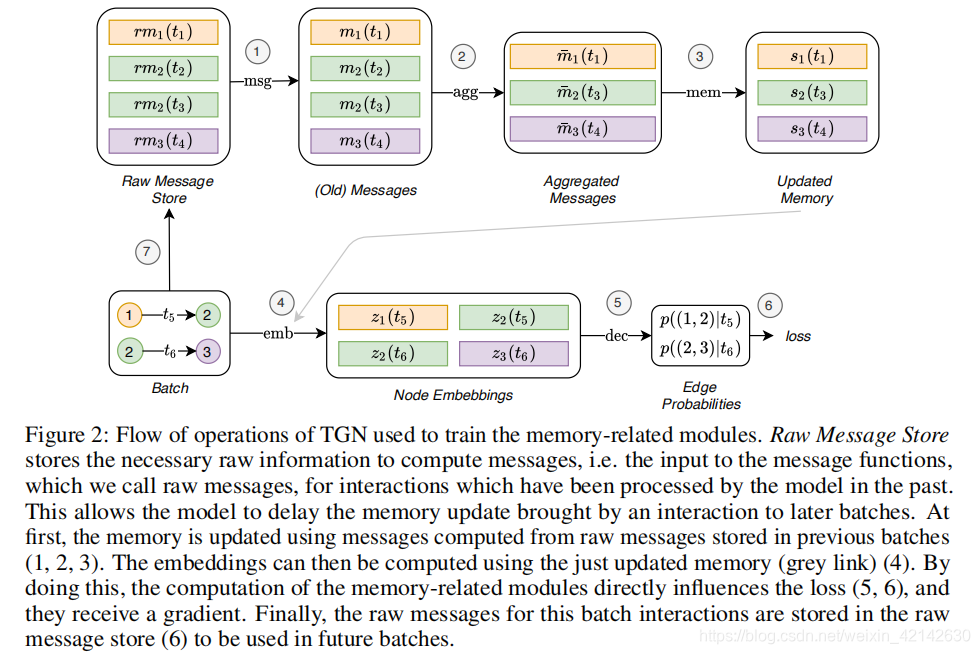
出现的另一个问题则是,在并行化TGN训练时,保持交互之间的时间依赖性是重要的。
实验
模型表现
链路预测
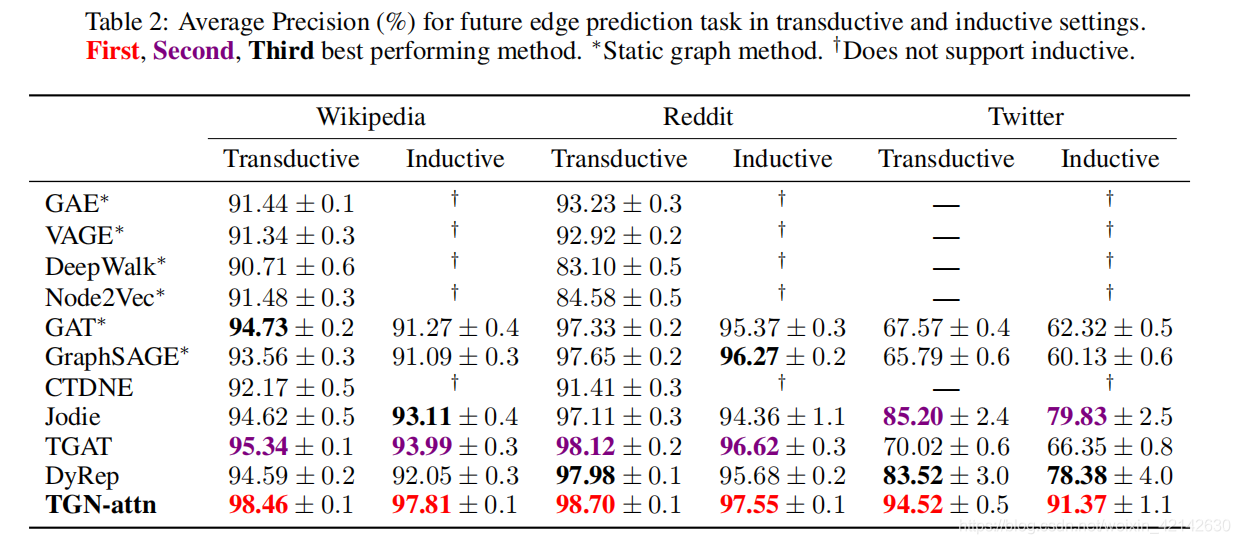
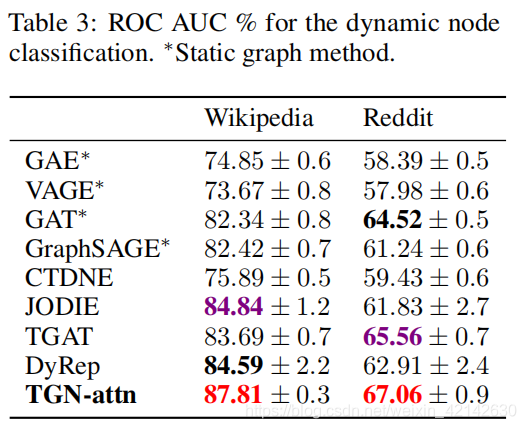
节点分类
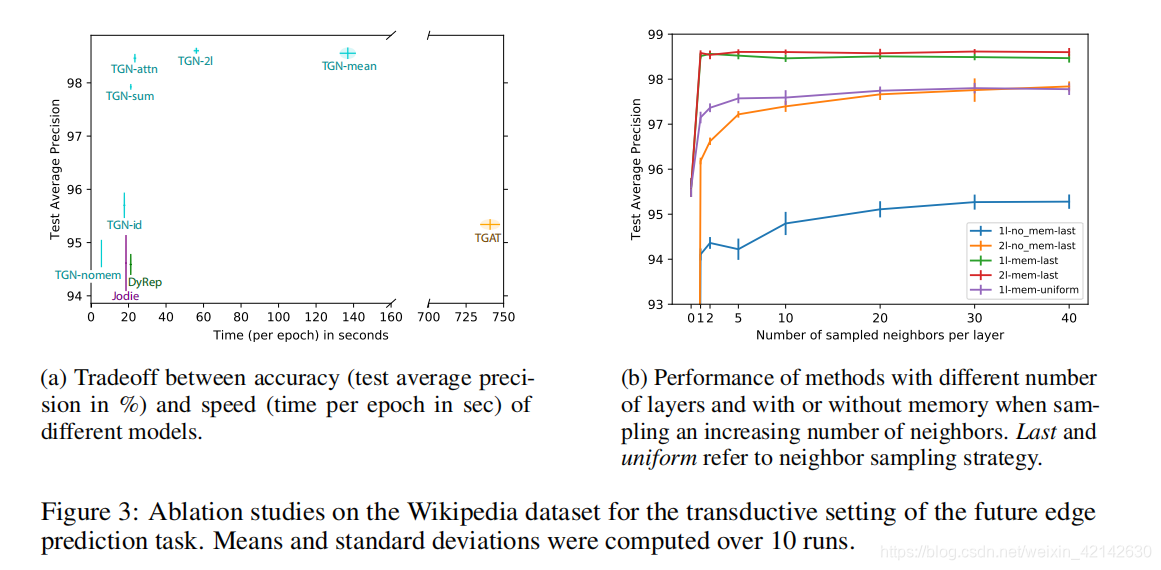
Ablation Study

















 7875
7875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









