







说明:如需数据可以直接到文章最后关注获取。
1.数据背景
Bank Marketing 数据集是机器学习和数据分析领域中广泛使用的另一个经典数据集。该数据集来源于葡萄牙的一家银行,记录了该银行通过电话营销活动推广定期存款产品的客户互动情况。数据集的目标是预测客户是否会订阅(购买)银行的定期存款产品。
数据集的应用场景-Bank Marketing 数据集广泛应用于以下几个领域:
1)分类模型评估:该数据集常用于评估分类算法的性能,尤其是二分类问题。常见的机器学习算法包括决策树、随机森林、支持向量机、逻辑回归、XGBoost 等。由于目标变量存在类别不平衡问题,研究人员通常会使用一些专门的评估指标(如 AUC-ROC、F1 分数、精确率、召回率等)来评估模型的性能。
2)不平衡数据处理:由于目标变量存在明显的类别不平衡问题,该数据集非常适合用于研究如何处理不平衡数据。常见的方法包括过采样(如 SMOTE)、欠采样、加权损失函数等。
3)特征工程:数据集中包含多种类型的特征(数值型、类别型、时间序列特征等),因此它是一个很好的练习特征工程的工具。研究人员可以尝试不同的特征选择、特征编码和特征组合方法,以提高模型的预测性能。
4)时间序列分析:数据集中包含了一些与时间相关的特征(如 day、month、pdays 等),因此也可以用于时间序列分析和建模。例如,研究人员可以探索不同时间段内客户的响应模式,或者分析季节性因素对营销效果的影响。
5)业务优化:该数据集可以帮助银行优化其电话营销策略。通过分析哪些客户更有可能订阅定期存款产品,银行可以更有针对性地选择潜在客户,从而提高营销活动的成功率和效率。
Bank Marketing 数据集是一个经典的机器学习数据集,广泛应用于分类算法的评估、不平衡数据处理、特征工程和时间序列分析等领域。该数据集提供了丰富的客户特征和营销活动信息,涵盖客户的个人特征、社会经济背景、银行账户信息以及与营销活动相关的交互信息。尽管数据集存在一些局限性,但它仍然是一个非常有价值的研究工具,尤其适合初学者和研究人员进行实践和探索。
2.数据介绍
数据格式为csv格式。
| 编号 | 变量名称 | 描述 |
| 1 | age | 客户的年龄 |
| 2 | job | 客户的职业 |
| 3 | marital | 客户的婚姻状况 |
| 4 | education | 客户的最高学历 |
| 5 | default | 客户是否有信用违约记录 |
| 6 | balance | 客户的银行账户余额(以欧元为单位) |
| 7 | housing | 客户是否有住房贷款 |
| 8 | loan | 客户是否有个人贷款 |
| 9 | contact | 营销人员与客户联系的方式 |
| 10 | day | 上次联系的日期(一个月中的某一天) |
| 11 | month | 上次联系的月份 |
| 12 | duration | 上次联系的持续时间(秒) |
| 13 | campaign | 当前营销活动中与客户的联系次数 |
| 14 | pdays | 自上次营销活动以来的天数(如果从未联系过,则为-1) |
| 15 | previous | 在当前营销活动之前与客户的联系次数 |
| 16 | poutcome | 上次营销活动的结果(如成功、失败、未知等) |
| 17 | y | 客户是否订阅了定期存款产品(yes 或 no) |
数据详情如下(部分展示):
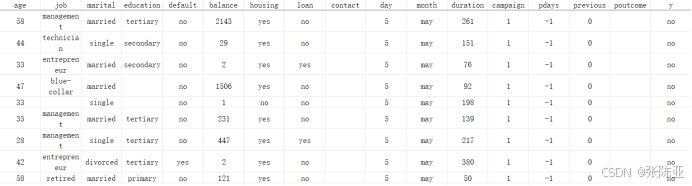
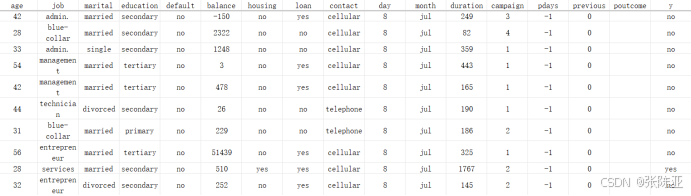
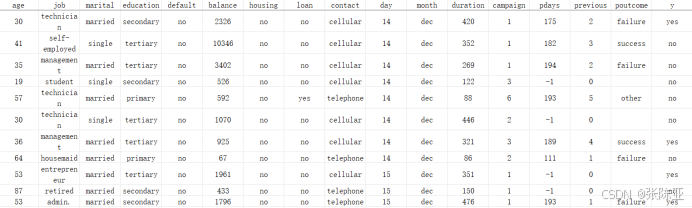
文本特征说明:
job:
admin.:行政人员(如办公室管理人员、文员等)
blue-collar:蓝领工人(如工厂工人、建筑工人、技术工人等)
entrepreneur:企业家(如企业主、自雇人士等)
housemaid:家庭佣工(如清洁工、保姆等)
management:管理层(如经理、主管等)
retired:退休人员
self-employed:自雇人士(如自由职业者、个体经营者等)
services:服务业人员(如酒店、餐饮、零售等行业员工)
student:学生
technician:技术人员(如工程师、程序员、维修人员等)
unemployed:失业人员
unknown:未知(数据缺失或无法确定)
marital:
married:已婚
divorced:离婚
single:未婚(包括从未结婚和丧偶)
education:
tertiary(高等教育):
描述:表示客户完成了大学本科或以上的教育,包括学士学位、硕士学位、博士学位等。
secondary(中等教育):
描述:表示客户完成了高中或职业培训课程,但未接受过高等教育。
primary(初等教育):
描述:表示客户仅完成了小学或初中教育,或者未完成九年义务教育。
3.数据获取
关注下方 回复1008,获取。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











