







说明:如需数据可以直接到文章最后关注获取。
1.数据背景
心脏病数据集最初由多个医疗研究机构收集,主要包括 Cleveland Clinic Foundation、Hungarian Institute of Cardiology, Budapest、VA Medical Center, Long Beach and the Cleveland Clinic Foundation 以及 University Hospital, Zurich, Switzerland。该数据集是心脏病学领域的一个重要资源,旨在帮助研究人员和临床医生更好地理解心脏病的风险因素,并开发更有效的预测模型。
Cleveland 数据集是最常被使用的版本,它包含了来自 Cleveland 诊所的 303 个病人的记录。随着时间的推移,这个数据集已经被广泛应用于机器学习和统计分析中,成为评估各种算法性能的标准之一。
心脏病数据集包含了一系列与病人健康状况相关的特征,总共 76 个属性,但通常只使用其中的 14 个最为常用且信息量丰富的特征。这些特征涵盖了病人的基本人口统计数据、生理指标、生活习惯以及医学检查结果等。每个特征都对理解心脏病的发生和发展具有潜在的重要性。
心脏病数据集主要用于以下几个方面:
疾病预测:构建机器学习模型来预测个体患心脏病的风险,帮助早期发现和干预。
特征选择:识别哪些特征对于预测心脏病最为关键,从而指导临床实践和进一步的研究。
医疗决策支持:为医生提供辅助工具,根据患者的特征评估心脏病的可能性,辅助制定治疗方案。
药物研发:理解不同因素如何影响心脏病的发展,有助于新药的研发和临床试验的设计。
心脏病是全球范围内导致死亡的主要原因之一,因此,对心脏病风险因素的理解和预测至关重要。心脏病数据集提供了宝贵的机会,使研究人员能够:
探索风险因素:深入分析哪些因素最有可能增加心脏病的风险,包括生活方式、遗传因素和环境因素。
提高诊断准确性:通过机器学习模型的不断优化,提升心脏病的诊断精度,减少误诊和漏诊。
个性化医疗:根据患者的具体情况定制个性化的预防和治疗策略,实现精准医疗。
心脏病数据集是一个极具价值的研究工具,它不仅帮助科学家们深入了解心脏病的发病机制,还为开发更准确的预测模型提供了坚实的基础。随着人工智能和大数据技术的不断发展,我们有理由相信,这个数据集将继续在心脏病学领域发挥重要作用,推动相关研究和技术的进步。
2.数据介绍
数据格式为csv格式。
| 编号 | 变量名称 | 描述 |
| 1 | age | 病人的年龄(以年为单位) |
| 2 | sex | 病人性别 (1 = 男, 0 = 女) |
| 3 | cp | 胸痛类型 (1: 典型心绞痛, 2: 非典型心绞痛, 3: 无心绞痛, 4: 无症状) |
| 4 | trestbps | 入院时的静息血压(毫米汞柱) |
| 5 | chol | 血清中的胆固醇含量(毫克/分升) |
| 6 | fbs | 空腹血糖水平 (> 120 mg/dl 为 1, 否则为 0) |
| 7 | restecg | 静息心电图结果 (0: 正常, 1: ST-T 波异常, 2: 可能或肯定的左室肥大) |
| 8 | thalach | 达到的最大心率 |
| 9 | exang | 运动诱发的心绞痛 (1 = 是, 0 = 否) |
| 10 | oldpeak | 相对于休息的旧峰 ST 抑制(连续值) |
| 11 | slope | 峰值运动 ST 段的斜率 (1: 上坡, 2: 平坦, 3: 下坡) |
| 12 | ca | 通过荧光透视显示的主要血管数目(0-3) |
| 13 | thal | 心肌灌注显像的结果 (3 = 正常, 6 = 固定缺陷, 7 = 可逆缺陷) |
| 14 | y | 0 = 没有疾病,1-4 = 不同程度的疾病 |
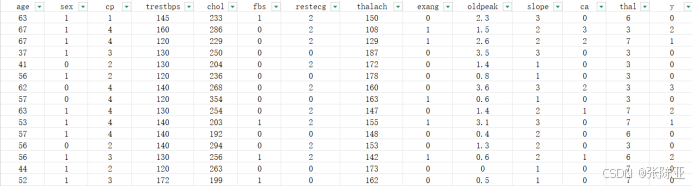
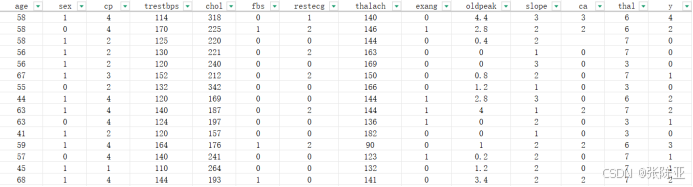
数据详情如下(部分展示):
3.数据获取
关注下方 回复1003,获取。


















 2857
2857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











