






模型输入的问题
假设有一个模型的输入是一个人的身高、体重以及年龄,假设身高的范围(0.8米~2.2米),体重(60斤~300斤),年龄的范围(10虽~80岁),当我们针对这样的数据训练模型时会发现身高相对另外两个变量的变化较小,而体重的变化可能是最大的。此时可能面临的问题是模型会受到体重的影响更大,实际的训练曲线地形图可能如下
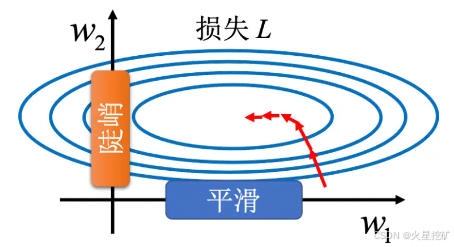
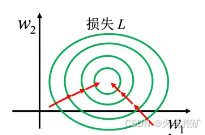
解决方法:特征归一化(Feature normalization)
在每一层输入一批数据前计算输入参数的均值、标准差,然后为每一个数据做归一化,使得输入变成一个不包含单位的标量。当输入的数据批次是训练数据的全体时,我们可以认为均值就是训练参数的数学期望。当然,实际的训练过程中会受到训练机器的资源限制(如算力、显存等限制),每次都会只能输入一个批次的数据,它可能是1/n的数据,此时也还可以使用相同的方法对输入数据进行特征归一化,即只计算批量数据的均值与标准差,此时可以称之为批量归一化(Batch Nomalization)。
神经网络模型往往包含多层网络,某层的输入被归一化后,输出将会成为下一层的输入。此时我们可以继续的将上一层输出完成归一化,这样的操作出现在每一层网络之上。如此的好处是模型训练的过程中,模型损失会更快的收敛。
批量归一化在模型运行中如何工作?
模型一旦使用批量归一化训练,所有的参数就会要求输入的参数都经过归一化,假设模型最小接受的批量是10笔数据,如果我们不做任何处理,则要求必须攒够10笔数据才能运行该模型。如此是不可接受的,实际上我们可以无需在运行模型时再次计算输入数据的均值和标准差,可以让模型在训练过程中记住训练时使用的均值和标准差。
由于训练过程中,我们会训练多次,为了让让模型的均值更接近真实的数据分布,往往需要一种策略动态的更新网络的均值与标准差。最直接的方法就是使用移动平均(moving average)动态的记录均值,当模型训练到最后,即把最后的均值记作模型在测试阶段使用的均值,标准差也可使用相同的方法。
![]()

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









