






还是这说好这不是物联网的那个协议啊~~
第4部主要讲实现,及一些实用技巧
LoRA是Low-Rank Adaptation或Low-Rank Adaptors的缩写,它提供了一种用于对预先存在的语言模型进行微调的高效且轻量级的方法。
LoRA的主要优点之一是它的效率。通过使用更少的参数,lora显著降低了计算复杂度和内存使用。这使我们能够在消费级gpu上训练大型模型,并将我们的lora(以兆字节计)分发给其他人。
lora可以提高泛化性能。通过限制模型的复杂性,它们有助于防止过拟合,特别是在训练数据有限的情况下。这就产生了更有弹性的模型,这些模型在处理新的、看不见的数据时表现出色,或者至少保留了它们最初训练任务中的知识。
LoRA可以无缝集成到现有的神经网络架构中。这种集成允许以最小的额外训练成本对预训练模型进行微调和适应,使它们非常适合迁移学习应用。
本文将首先深入研究LoRA,然后以RoBERTa模型例从头开发一个LoRA,然后使用GLUE和SQuAD基准测试对实现进行基准测试,并讨论一些技巧和改进。
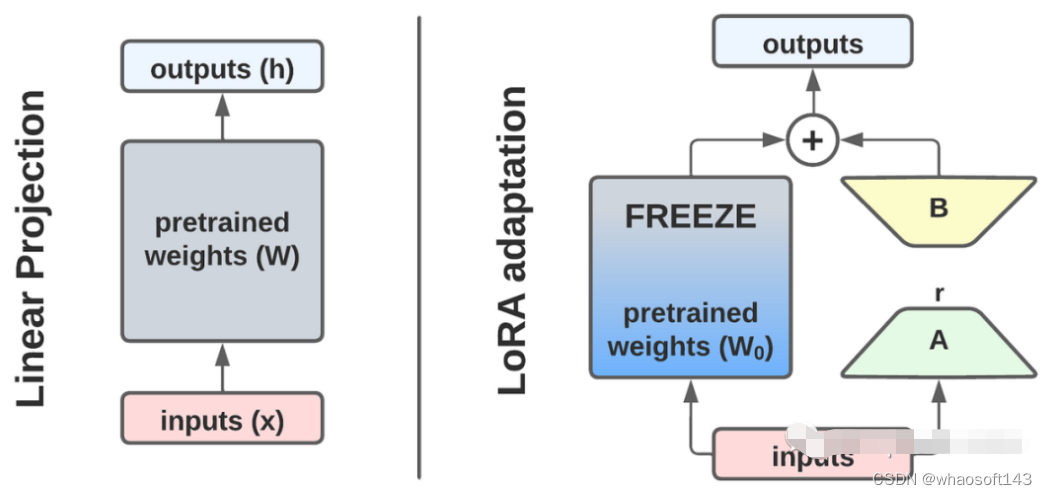
LoRA是如何工作的
LoRA的基本思想是将预训练的矩阵(即原始模型的参数)冻结(即处于固定状态),只在原始矩阵上添加一个小的delta,其参数比原始矩阵少。
例如矩阵W,它可以是全链接层的参数,也可以是transformer注意力机制的矩阵之一:
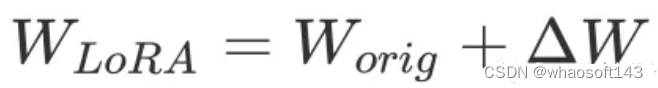
如果w-orig的维度是n×m,我们只是初始化一个新的具有相同维度的矩阵来微调则会把参数翻倍。
所以我们通过从低维矩阵B和A进行矩阵乘法来构建ΔW,使其比原始矩阵“维度”更少。

其中,我们首先定义秩r,并且小于基本矩阵的维数r≪n, r≪m。那么矩阵B是n×r矩阵A是r×m。将它们相乘得到一个与W具有相同维数的矩阵,但是参数更少。
我们希望在训练开始的时候像原始模型一样,所以B通常初始化为全零,而A初始化为随机(通常为正态分布)值。
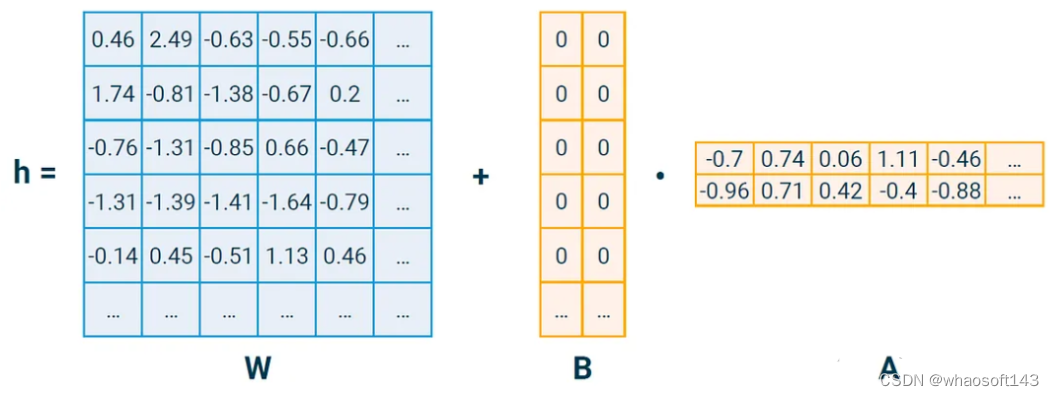
假设我们的基本维数是1024,我们选择了一个LoRA秩r为4,那么:
W有1024 * 1024≈100万个参数;A和B各有r * 1024 = 4 * 1024≈4k参数,共8k
也就是说只需要训练0.8%的参数就可以用LoRA更新我们的矩阵。在LoRA论文中,他们用alpha参数衡量delta矩阵:

如果你只是将α设置为r并微调学习率,可已得到与论文近似的结果。我们在下面的实现中忽略这个细节,但它是许多其他LoRA库(例如hugs Face的PEFT)中的一个常见特性。
手写LoRA
我们在这里的实现将在PyTorch中完成,虽然我们希望严格遵循原始的LoRA论文,但是我们稍微简化了代码,这样它应该更容易阅读,同时仍然显示了基本元素。
我们这里使用RoBERTa模型。使用Huggingface的实现RobertaSelfAttention作为基类创建新类LoraRobertaSelfAttention,这里将初始化LoRA矩阵。所有B矩阵初始化为零,所有A矩阵初始化为正态分布中的随机数。
要使用这些方法,我们必须重写RobertaSelfAttention的原始转发函数。虽然这有点硬编码(后面有改进的讨论),但它非常简单。首先,我们从modeling_roberta.py复制原始的转发代码。然后将每次对query的调用替换为lora_query,并将每次对value的调用替换为lora_value。然后函数看起来像这样:
这样我们就在注意力层添加了lora部分。剩下任务就是替换掉原来RoBERTa模型中的注意力模块。
这里我们需要遍历RoBERTa模型的每个命名组件,检查它是否属于RobertaSelfAttention类,如果是,则将其替换为LoraRobertaSelfAttention,同时保留原始权重矩阵。
self.replace_multihead_attention:用我们之前写的LoraRobertaSelfAttention替换了所有神经网络的注意力层
self.freeze_parameters_except_lora_and_bias:这将冻结训练的所有主要参数,这样梯度和优化器步骤仅应用于LoRA参数以及我们希望可训练的其他例如归一化层等参数。
然后就是递归地遍历所有模型部分,冻结所有不想再训练的参数:
以上就是我们最简单的一个LORA的实现,下面我们看看效果
用GLUE和SQuAD进行基准测试
我们使用GLUE(通用语言理解评估)和SQuAD(斯坦福问答数据集)基准进行评估。
GLUE基准是一套由8个不同的NLP任务组成的测试,它包括情感分析、文本蕴涵和句子相似性等挑战,为模型的语言适应性和熟练程度提供了一个强有力的衡量标准。
SQuAD专注于评估问答模型。它包括从维基百科的段落中提取答案,模型在其中识别相关的文本跨度。SQuAD v2是一个更高级的版本,引入了无法回答的问题,增加了复杂性,并反映了现实生活中的情况,在这种情况下,模型必须识别文本缺乏答案。
对于下面的基准测试,没有调优任何超参数,没有进行多个runes(特别是较小的GLUE数据集容易出现随机噪声),没有进行任何早停,也没有从之前的GLUE任务开始微调(通常这样做是为了减少小数据集噪声的可变性并防止过拟合)。
从刚初始化的rank为8的LoRA注入到RoBERTa-base模型开始,每个任务的训练精确地进行了6次训练。在前2个epoch中,学习率线性放大到最大值,然后在剩余的4个epoch中线性衰减到零。所有任务的最大学习率为5e-4。所有任务的批处理大小为16
基于roberta的模型有1.246亿个参数。有了LoRA我们只有42万个参数需要训练。这意味着我们实际上只使用0.34%的原始参数进行训练。LoRA为这些特定任务引入的参数数量非常少,实际磁盘大小仅为1.7 MB。
训练后重新加载LoRA参数,在每个任务的验证集上测试性能。结果如下:
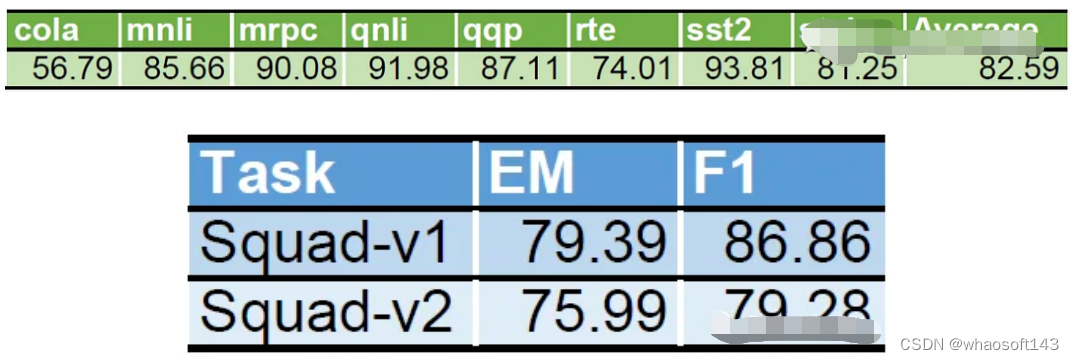
它清楚地证明了我们的LoRA实现是有效的,并且注入的低秩矩阵正在学习。
改进思路
我们上面很多的代码都是硬编码,有人可能会想:“除了重新编码自关注类并执行复杂的替换之外,还有更有效、更通用(即可转移到其他网络体系结构)的方法吗?”
其实我们可以简单地实现nn.Linear的包装器,也就是说我们想用它替换哪些层,通过检查它们的名字直接进行替换就可以了。
只将LoRA注入所有线性层也成为一种相当普遍的做法。因为保持偏差和归一化已经很小了,所以你不需要再去精简它们。
另外,上面的代码实际上是(接近)huggingface PEFT库实现LoRA的方式。虽然我们的实现是可用的,但是还是强烈建议您使用PEFT,因为我们不是为了学习原理,而不是新造一个轮子。所以下面我们还是要介绍一下如何使用PEFT
PEFT使用指南
我们以量化的方式加载模型。由于bitsandbytes与transformers 库(于2023年5月推出)的集成,这是一件轻而易举的事情。
我们这里使用4位的量化加载,速度会慢一些,我们也可以可以通过检查模型的模块和参数数据类型来验证4位加载:
现在用PEFT注入LoRA参数。PEFT库通过模块的名称定位要替换的模块;因此要看一下模型model.named_parameters()。这是非量子化roberta基模型的样子。
然后我们可以指定要为那些层进行LoRA微调。。所有未注入LoRA参数的层将自动冻结。如果我们想以原始形式训练层,可以通过将列表传递给Lora-Config的modules_to_save参数来指定它们。在我们的例子中,
下面的示例注入rank为2的LoRA。我们用上面的8来指定alpha参数,因为这是我们第一次尝试的秩,应该可以让我们使用上面例子中的学习率。
为LoRA注入指定更多模块可能会增加VRAM需求。如果遇到VRAM限制,请考虑减少目标模块的数量或降低LoRA等级。
对于训练,特别是QLoRA,选择与量化矩阵兼容的优化器。将标准优化器替换为bitsandbytes变体,如下所示:
这样就可以像以前一样训练这个模型了,训练完成后,保存和重新加载模型的过程很简单。使用模型。Save_pretrained保存模型,指定所需的文件名。PEFT库将在此位置自动创建一个目录,在其中存储模型权重和配置文件。该文件包括基本模型和LoRA配置参数等基本细节。
用peft.AutoPeftModel.from_pretrained,将目录路径作为参数可以重新加载模型。要记住的关键一点是,LoRA配置目前没有保留初始化automodelforsequencecclassification的类的数量。当使用from_pretrained时,需要手动输入这个作为附加参数。
重新加载的模型将包含应用了LoRA的原始基本模型。如果您决定将LoRA永久地集成到基本模型矩阵中,只需执行model.merge_and_unload()。
总结
我们从简单的(尽管是硬编码的)LoRA实现,深入了解了LoRA、它们的实际实现和基准测试。并且介绍了另一种更有效的实现策略,并深入研究了用于LoRA集成的PEFT等现有库的优点。
完整的代码可以在这里找到:
https://github.com/Montinger/Transformer-Workbench/tree/main/LoRA-from-scratch















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









