







传统机器学习——特征工程之数值处理
前言
书接上文,前面两篇介绍了关于空值的处理,这篇开始用不同手段细化处理过程,本篇将会介绍数值型数据的二值化、区间量化(分箱)、对数变换、指数变换、特征缩放\归一化、交互特征、特征选择。
(注:为了只操作在一个数据集上,有些原理在其上的应用可能比较生硬)
声明:关于编程语法相关问题不会展开论述,本文只针对方法路线。
二值化
二值化的应用场景/作用:这里还是用前面两篇所用到的数据集来说明问题(House Price from kaggle),其中有一列为“Fireplaces”,即火炉的个数,为了说明二值化,可以这样理解,火炉有即可,有几个不重要或者说数量相距较大时对分布有影响,所以如果火炉的个数大于0,就可以将其用“1”来表示,如果等于0,则用“0”来表示,代码如下:

区间量化(分箱)
以数据集中的“2ndFlrSF”为例,它表示屋子得第二层的面积,使用直方图查看数据的分布情况:


由上图可以看出,大多数的面积为0 ,而且不同个体的面积横跨了三个数量级。“在线性模型中,同一系数应该对所有可能的计数值起作用,对无监督学习,k-均值聚类使用欧式距离作为相似度函数啦衡量数据点之间的相似度,数据中过大的值对相似度的影响会远超其他元素,从而破坏相似度测量”。
针对上述问题,可对数据进行区间量化,必须确定每个分箱的宽度,按照分箱的宽度,可以细化为固定宽度分箱和自适应分箱。
1.固定宽度分箱
每个分箱会包含一个具体范围的数值,这些数值可以:
- 人工定制
- 自动分段
- 线性的
- 指数的
这里制作符合问题描述的数据集:
 生成数据如下:
生成数据如下:
[27 18 93 51 12 20 58 17 6 62 86 16 45 41 94 39 8 90 20 71]
以10为宽度,每个数除以10再下下取整后,每个分箱的取值范围都是0~9(线性)

线性分箱结果:[2 6 1 3 1 6 2 7 3 3 1 5 7 0 6 2 6 1 6 8]
当然,更多的情况是一组数据中会同时存在若干数量级的数,此时若用线性分箱,恐怕不能满足要求,所以针对这种情况需要用指数分箱:

观察如上数据,横跨了4个数量级,使用对数函数映射到指数分箱中:
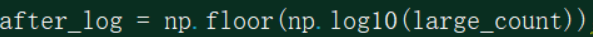 指数分箱结果:[2. 3. 4. 1. 0. 2. 2. 3. 3. 4. 4. 1. 1. 3. 2. 2. 4.]
指数分箱结果:[2. 3. 4. 1. 0. 2. 2. 3. 3. 4. 4. 1. 1. 3. 2. 2. 4.]
2.自适应分箱/分位数分箱
固定宽度分箱的优点显而易见,计算简单,但是如果数据分布不均匀,会产生空箱子(有待考证),自适应分箱可以解决这个问题。
先说“分位数分箱”中的分位数:分位数是可以将数据划分为相等的若干份数的值,比如中位数可以将数据分为两半,前一半数据比中位数小,后一半数据比中位数大;四位数将数据四等分,十位数将数据十等分……
下面演示十分位数:
使用pd.Dataframe.quantile来求出n位数(语法知识请自行百度),这里指定十位数。
 结果:即这9个数将数据等分十份。
结果:即这9个数将数据等分十份。
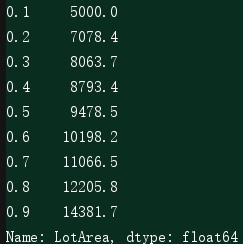
将十位分数与原数据一起绘制到直方图上,可以看到数据是向较小的计数值偏斜的:

对数变换
上面简要地通过取计数值的对数将数据映射到指数宽度分箱,这里针对再次实现
作用:对数函数可以对大数值的范围进行压缩,对小数值的范围进行扩展。

将取对数前后的直方图作对比,可以看出取对数后,数据分布更符合正态分布。

指数变换
指数变换只是对数变换的一个特例。
特征缩放/归一化
min - max缩放
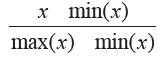
特征标准化/方差缩放
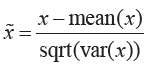
归一化
喜欢的库函数又来了:
from sklearn.preprocessing import StandardScaler
a = StandardScaler().fit_transform(b)
交互特征
简单来说就是某几个数据相互组合可以得到一个交互特征(个人理解)
如下:
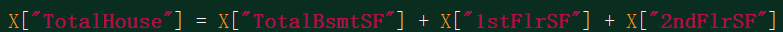
这四个属性为样本中不同的四列,但是总面积等于基础面积+一楼面积+二楼面积。
特征选择
不同的特征对应不同的重要性,为了选择那些重要特征或者说降低维数,可以使用PCA、LDA、Lasso,这里使用lasso(算法原理:https://blog.csdn.net/xiaozhu_1024/article/details/80585151)将每个样本的数据可视化:
代码如下:
 从图中能够看出每个属性的对分类的重要性,可以去除重要性为0和负值的属性
从图中能够看出每个属性的对分类的重要性,可以去除重要性为0和负值的属性
















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









