







 本文介绍了《Universal adversarial perturbations》中的通用扰动构造方法,该方法针对深度学习模型,能对同一分布的样本产生使模型误分类的扰动。算法核心思想在于寻找最小扰动,使图像远离决策边界,实验表明其具有良好的泛化和黑盒攻击能力。后续研究中,对该方法进行了改进,如GDUAP、AAA、NAG等,但直接应用于图像检索仍具挑战。
本文介绍了《Universal adversarial perturbations》中的通用扰动构造方法,该方法针对深度学习模型,能对同一分布的样本产生使模型误分类的扰动。算法核心思想在于寻找最小扰动,使图像远离决策边界,实验表明其具有良好的泛化和黑盒攻击能力。后续研究中,对该方法进行了改进,如GDUAP、AAA、NAG等,但直接应用于图像检索仍具挑战。
本文关于介绍关于通用扰动的《Universal adversarial perturbations》。
1. 《Universal adversarial perturbations》
本文介绍了一种通用(Universal)扰动的构造方法,攻击方只需要对所有同一分布的样本添加该通用算法下的扰动,就能实现对抗样本构造。即不用像之前的方法那样,要针对每一个样本进行梯度计算以求得扰动。
1.1 算法核心思想
μ表示一组图片, ![]() 表示分类器,作者用下式形容算法的构造要求,即:寻找一个扰动v,使得在添加扰动后,μ内大多数图片都能被分类器误分类。(这里可以看出本次的UAP算法是一种不指定误分类目标的对抗样本构造方法)
表示分类器,作者用下式形容算法的构造要求,即:寻找一个扰动v,使得在添加扰动后,μ内大多数图片都能被分类器误分类。(这里可以看出本次的UAP算法是一种不指定误分类目标的对抗样本构造方法)
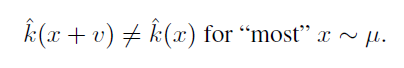
对于扰动v,作者用下式来对它进行限制:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









