







1.Transformer总体框架
先来一张名图镇楼,哈哈哈。
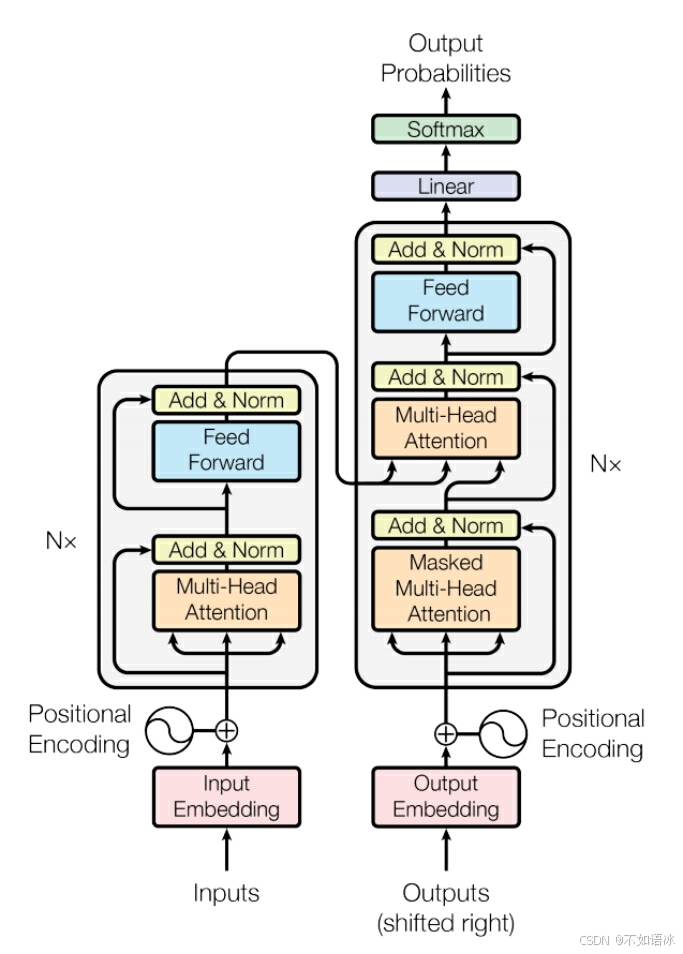
Transformer模型是深度学习模型的里程碑之作,但它并不是凭空产生的,相反,经过前面章节的学习,在学习transformer模型时,我们可以意识到其是站在巨人的肩膀上的,融合了很多之前创新的想法,比如残差网络,比如全连接层,比如词向量,比如注意力机制,比如seq2seq框架,取得了惊艳的效果。下面我们将一步一步抽丝剥茧,仔仔细细地完成transformer模型的学习。
开始的开始,我们说深度学习就是用来拟合函数,是一个参数经由网络训练学习得到的拟合函数,是一个黑盒,如下图,经过这个黑盒函数后,将一种语言转变成另一种语言,完成了不同语言的翻译。这个工作可以用RNN系列模型来实现。

然后我们又学习了seq2seq框架,知道了它是Encoder-Decoder架构的一种形式,而Transformer模型也是Encoder-Decoder架构,主要结构包括两部分,编码层和解码层,也就是中间的黑盒函数可以进一步细化如下图。
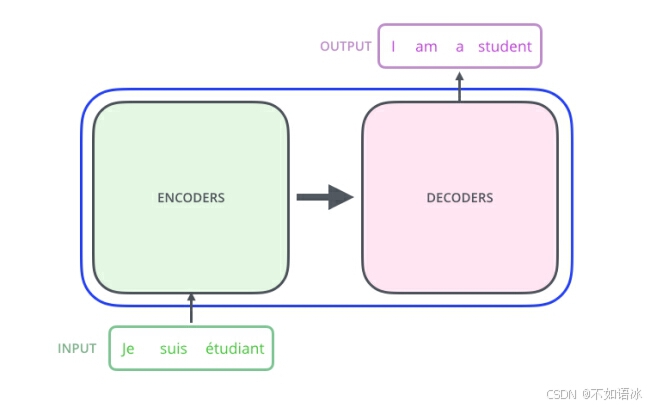
而编码层和解码层内部又有多个编码器和解码器堆叠而成,Transformer模型里:
编码层:6个编码器的堆叠(“6”可以调整),每个编码器结构相同,包括两部分, 自注意力层(self-attention)和前向传播层(feed forward),但编码器之间不共享权重,这也导致参数量巨大。
解码层:6个解码器的堆叠。

那具体每个编码器和解码器的内部结构是什么样的呢?学习神经网络模型的核心就是抓住数据流,即数据的形状和维度,一般来说,输入都是矩阵/向量,这时就要重点关注经过每个模块后数据的形状和维度变化。下面我们就一点点地介绍学习。
2 Encoder
首先考虑一下输入数据的特征维度,对于序列数据,前面已经介绍了如何将序列数据转化为词向量,而transformer模型的输入除了词向量之外,还有单词在句子中的“位置编码”。接下来详细介绍一下各个输入。
2.1 网络输入——词嵌入与位置编码(positional encoding)
2.1.1 独热编码One-Hot Encoding
一种最简单的词向量方式是独热编码one-hot representation(虽然目前已基本不会再使用,但是获得词向量的基础)。首先定义一个含有n个词语的词汇表(想象成不同的字典),然后每个单词定义一个向量1*n(该向量长度即为词汇表的长度),单词在词汇表的位置a对应的向量位置为1,其余位置的全为0。
举个简单的例子,假如词汇表中有5个词,第3个词表示“你好”这个词,那么该词对应的 one-hot 编码即为 00100(第3个位置为1,其余为0)。
One-hot Representation 形式很简洁,使用起来也很简单,只需要给每个单词分配一个编号,然后在对应的向量位置记为1就好了。但也存在2个很大的问题:
(1)维度灾难:词汇表一般都非常大,假如词汇表有 10k 个词,那么一个词向量的长度就需要达到 10k,而其中却仅有一个位置是1,其余全是0,内存占用过高且表达效率很低。
(2)无法体现出词与词之间的关系:比如 “爱” 和 “喜欢” 这两个词,它们的意思是相近的,但基于 one-hot 编码后的结果取决于它们在词汇表中的位置,不能很好地刻画词与词之间的相似性。因为任何两个one-hot向量之间的内积都是0,很难区分他们之间的差别。
2.1.2 词向量嵌入Word Embedding
One-Hot 的形式看上去很简洁,也挺美,但劣势在于它很稀疏,而且还可能很长。更重要的是,这种方式无法体现出词与词之间的关系。因此,我们需要另一种词的表示方法,能够体现词与词之间的关系,这种方法即 词嵌入Word Embedding。
那么应该如何设计这种方法呢?最方便的途径是设计一个可学习的权重矩阵 W(这个矩阵是致密的),将独热编码与这个矩阵进行点乘,在学习过程中,单词对应的权重矩阵不断优化成我们想要的词向量,其优点如下:
2.1.2.1降维
假设词汇表共有5个词语, “爱” 和 “喜欢” 这两个词经过 one-hot 后分别表示为 10000 (1*5)和 00001,权重矩阵设计如下(5*3):
[ w00, w01, w02
w10, w11, w12
w20, w21, w22
w30, w31, w32
w40, w41, w42 ]
那么两个词点乘后的结果分别是 [w00, w01, w02] 和 [w40, w41, w42],在网络学习过程中(这两个词后面通常都是接主语,如“你”,“他”等,或者在翻译场景,它们被翻译的目标意思也相近,它们要学习的目标一致或相近),权重矩阵的参数会不断进行更新,从而使得 [w00, w01, w02] 和 [w40, w41, w42] 的值越来越接近。
其实,可以将这种方式看作是一个查询表 lookup table:对于每个 单词word,进行词嵌入 word embedding 就相当于一个查询lookup操作,在表中查出一个对应结果。
需要注意的是,要获取的词向量是这里要学习的参数矩阵,另一方面,对于以上这个例子,我们还把向量的维度从5维压缩到了3维 [w00, w01, w02] 和 [w40, w41, w42]。因此,词嵌入word embedding 还可以起到降维的效果。
A∗B=C
在上述公式中,经过训练,原来的独热编码10个元素的A矩阵2*5,变成参数矩阵B中对应行的2*3,直观上大小缩小了近一半。
更进一步地,假设一个100Wx10W的原始矩阵,训练得到10Wx20的参数矩阵,降低10w/20=5000倍。
总结:在某种程度上,嵌入Embedding层实现了降维的作用,核心就是把词向量的长度从词汇表的长度降到了人为设置的一个常数。
再延伸一下,Embedding本质是用一个低维稠密的向量表示一个对象,这里的对象可以是一个词(Word2vec),也可以是一个物品(Item2vec),亦或是网络关系中的节点(Graph Embedding)。
在 Pytorch 框架下,可以使用 torch.nn.Embedding来实现 word embedding:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.ebd = nn.Embedding(voca_size, d_model)
self.d_model = d_model
def forward(self, x):
return self.ebd t(x) * math.sqrt(self.d_model)
其中,voca_size 代表词汇表中的单词量,one-hot 编码后词向量的长度就是这个值;d_model代表权重矩阵的列数,通常为512,就是要将词向量的维度从 voca_size 编码到 d_model。
2.1.2.2词与词之间关系
前面讲到one-hot编码词向量不能表示词与词之间的关系,为什么呢?一般来说,数学中使用两个向量之间的距离或者余弦来表示相似性。而one-hot编码因为每个词只在词汇表位置处为1,每个词向量的内积都是0,那么任意两个向量的“距离”或者说“相似性”都为0.
以下图为例,可以看到love和like的词向量余弦相似度是比较近的。
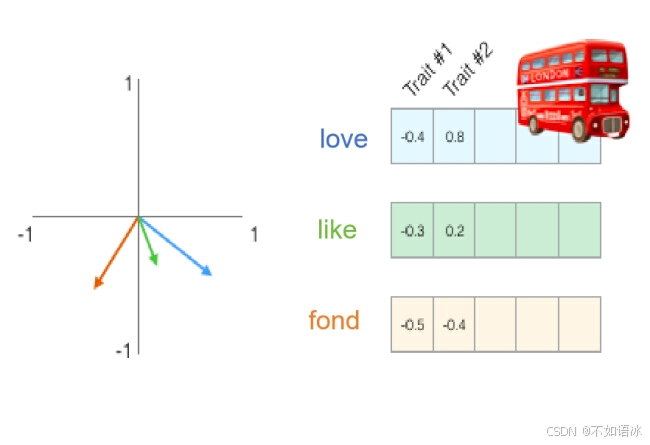
简单总结一下,词向量克服了one-hot表示的缺点,有以下2个有点:
(1) 可以表征词与词之间的相似关系:利用词之间的余弦来表征“距离”或“相似度”,这对很多自然语言处理的任务非常有帮助。
(2) 维度更低,包含信息更多: 相比one-hot的向量长度为词汇表长度,分布式词向量维度为人为设置的常数,维度更低;而且相比one-hot仅含有词在词汇表的位置这一信息,词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
2.1.3位置编码(positional encoding)
那么是不是词嵌入就完成的单词的向量化呢?还差了一步。因为这只是编码了一个个独立的单词,但是单词在句子中的位置信息还不知道。而字词的位置和顺序是所有语言的基本组成部分。它们定义了语法从而定义了句子的实际语义。比如“小红喜欢小白”和“小白喜欢小红”两句,因为词语的位置不同,则表达的意思是不同的。
因此知道每个单词在输入句子中的位置和顺序,便可以进一步掌握单词之间的内在关系。一种让模型感知顺序的方法是对每个词加一小块它在句子中的位置信息,我们把这"一小块信息"叫做位置编码。
循环神经网络(RNNs)自带了对字词顺序的考虑,它们通过顺序地逐字解析一条句子,这样就把字词的顺序集成到了RNNs的主干当中。但是Transformer架构抛弃了循环机制,选择一次性读取一个句子中的所有单词。它避免了RNNs循环的方法,使得训练时间大大加速。并且理论上,它可以捕获句子中更长距离的依赖(使用多头自注意力机制)。但也是因为transformer所有的输入都是一起的,不会像RNN输入一个处理一个,所以其需要位置编码。
那么该如何增加位置编码呢?
脑子冒出来的第一种想法是对每个时间戳赋一个[0,1]的值,其中0代表第一个字,1代表最后一个时间戳。你能想到这样会导致什么样的问题吗?其中一个它会产生的问题是,指定了这样的范围,你不知道里面总共表示了多少个词。换句话说,不同句子之间,时间戳的增量没有一致的意义。
另一个想法是线性地赋予每个时间戳一个数字。就是说,第一个字给它个"1",第二个字给它个"2",以此类推。这个方法的问题是不仅这个值可能会变得很大,而且我们的模型可能会遇到比训练里更长的句子。再更进一步说,我们的模型可能会从来没看过某个特定长度的样本,从而损伤了模型的泛化能力。
理想地说,位置编码要满足以下这些标准:
- 唯一性:它应该对每个时间戳(句子当中字词的位置)输出一个唯一的编码
- 一致性:不同长度的句子当中,任意两个时间戳的距离应该要一致。(前提这两个时间戳相对距离一样)
- 有界性:我们的模型应该在不付出任何努力的条件下泛化到更长的句子。它的编码值应该要有限(有界)。
- 确定性:它必须是确定性的。
那么具体该怎么做?我们通常容易想到两种方式:
- 通过网络来学习;
- 预定义一个函数,通过函数计算出位置信息;
Transformer 的作者对以上两种方式都做了探究,发现最终效果相当,于是采用了第2种方式,从而减少模型参数量,同时还能适应即使在训练集中没有出现过的句子长度。
论文中的计算方法如下
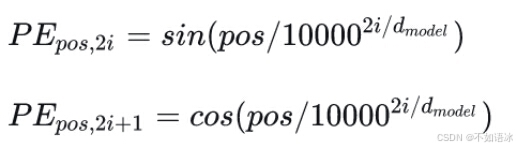
其中,pos是指当前词在句子中的位置(比如一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









