









Decoder 也是N层堆叠的结构。被分为3个 SubLayer,可以看出 Encoder 与 Decoder 三大主要的不同:
- Diff_1:Decoder SubLayer-1 使用的是 “masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露。
- Diff_2:SubLayer-2 是一个 encoder-decoder multi-head attention。
- Diff_3:LinearLayer 和 SoftmaxLayer 作用于 SubLayer-3 的输出后面,来预测对应的 word 的 probabilities 。
1 Diff_1 : “masked” Multi-Headed Attention
mask 的目标在于防止 decoder “seeing the future”,就像防止考生偷看考试答案一样。mask包含1和0:

用作者的话说, “We […] modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.”
2 Diff_2 : encoder-decoder multi-head attention
重点在于 x = self.sublayer1 self.src_attn 是 MultiHeadedAttention 的一个实例。query = x,key = m, value = m, mask = src_mask,这里x来自上一个 DecoderLayer,m来自 Encoder的输出。
到这里 Transformer 中三种不同的 Attention 都已经集齐了:
3 Diff_3 : Linear and Softmax to Produce Output Probabilities
最后的 linear layer 将 decoder 的输出扩展到与 vocabulary size 一样的维度上。经过 softmax 后,选择概率最高的一个 word 作为预测结果。
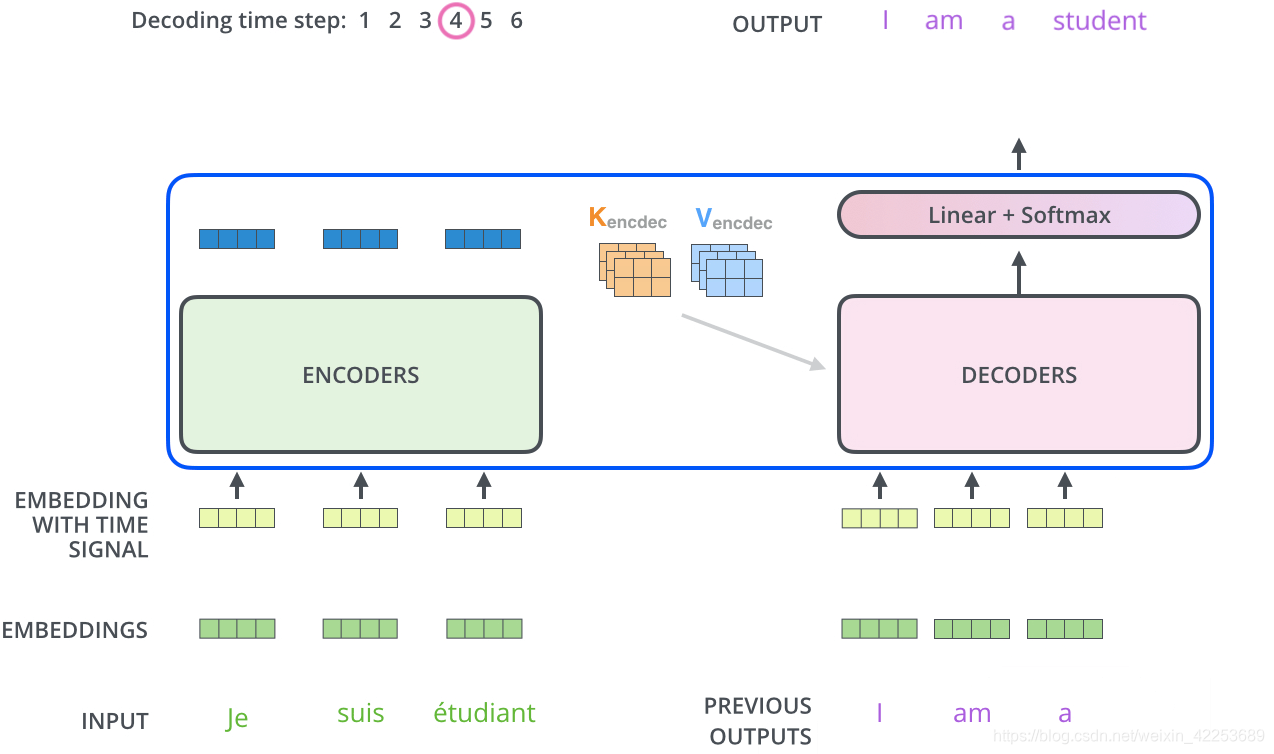
假设我们有一个已经训练好的网络,在做预测时,步骤如下:
- 给 decoder 输入 encoder 对整个句子 embedding 的结果 和一个特殊的开始符号 </s>。decoder 将产生预测,在我们的例子中应该是 ”I”。
- 给 decoder 输入 encoder 的 embedding 结果和 “</s>I”,在这一步 decoder 应该产生预测 “Love”。
- 给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love”,在这一步 decoder 应该产生预测 “China”。
- 给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love China”, decoder应该生成句子结尾的标记,decoder 应该输出 ”</eos>”。
- 然后 decoder 生成了 </eos>,翻译完成。
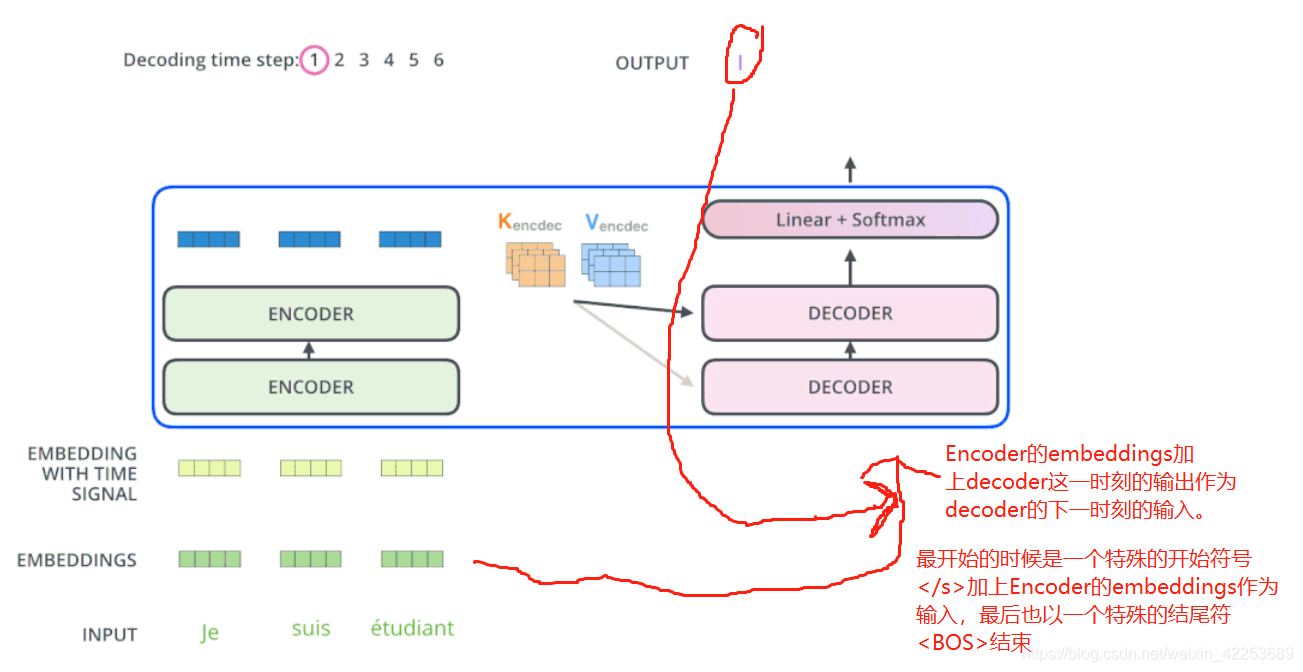
循环结果

动图:http://jalammar.github.io/images/t/transformer_decoding_2.gif
但是在训练过程中,decoder 没那么好时,预测产生的词很可能不是我们想要的。这个时候如果再把错误的数据再输给 decoder,就会越跑越偏:

这里在训练过程中要使用到 “teacher forcing”。利用我们知道他实际应该预测的 word 是什么,在这个时候喂给他一个正确的结果作为输入。
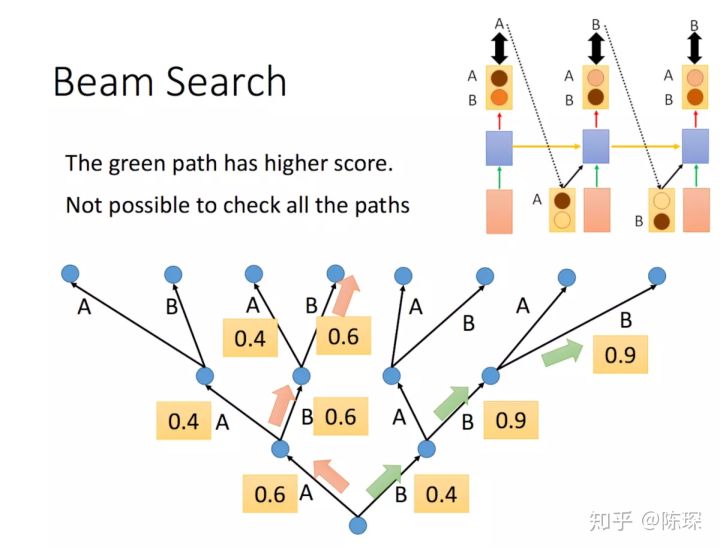
相对于选择最高的词 (greedy search),还有其他选择是比如 “beam search”,可以保留多个预测的 word。 Beam Search 方法不再是只得到一个输出放到下一步去训练了,我们可以设定一个值,拿多个值放到下一步去训练,这条路径的概率等于每一步输出的概率的乘积,具体可以参考李宏毅老师的课程:

或者 “Scheduled Sampling”:一开始我们只用真实的句子序列进行训练,而随着训练过程的进行,我们开始慢慢加入模型的输出作为训练的输入这一过程。

这部分对应 Annotated Transformer 中的实现为:
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)














 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}