








1. 论文简要
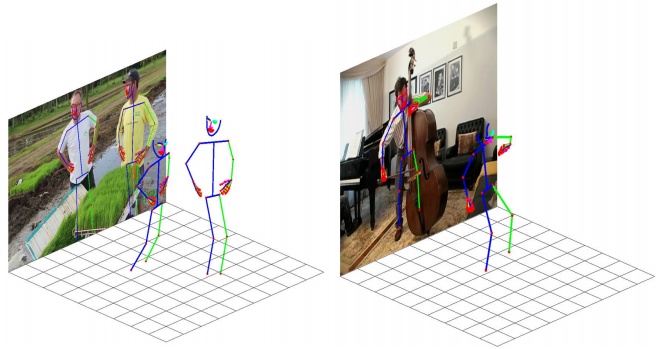
本论文提出一种检测和估计全身三维人体姿态的方法(身体,手,人脸),该方法的挑战主要在于带标签的3D全身姿态。大多数之前的工作将标注好的数据单独应用于身体,人手,或者人脸当中。在这项工作中,本文提出利用这些数据集来训练各个部分的独立专家模型,即身体、手和脸的模型,并将他们的知识提取到一个单一的深度网络中,用于全身的2D-3D位姿检测。在实际应用中,针对一幅有部分标注或没有标注的训练图像,各部分专家模型分别对其二维和三维关键点子集进行检测,并将估计结果结合起来得到全身伪真实标注姿态。蒸馏损失引导整个身体的预测结果尽量模仿专家模型的输出。
测试代码和模型地址:https://europe.naverlabs.com/research/computer-vision/dope
2. 背景介绍
在现实世界的图像和视频的理解在人类有许多潜在的应用,从阿凡达动画增强虚拟现实到机器人技术。人体全身三维位姿估计的任务主要是逐个部分进行的,之前的工作对人体位姿估计,人手姿态或人脸标定进行了研究。这些方法在各自的具体任务上都有突出的表现,如何有效地将它们结合起来是一个有待解决的问题。
全身三维人体姿态的标注方案在处理三维姿态时是不可能的,当目标人物的重要部分被遮挡或在图像边界之外时,就会导致全局估计失败的情况。其他一些工作利用由身体
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









