







《波》简介和采样
“我们将某一物理量的扰动或振动在空间逐点传递时形成的运动称为波”百科定义。
声音也是一种波,在数字领域,通过对模拟信号(声音)的采样,得到数字信号(此数字信号也称之为离散信号)。这个过程,称为:采样。在采样过程中,有2个指标,分别是《采样频率》和《采样位深》。
一、采样频率
采样频率——在一定时间内将连续的模拟信号采样多少次。一般我们说48k采样率,即为1S内采样48000个点,每2个采样点之间时间为1/48000S,即为1/48Ms,也就是1Ms内有48个点。
根据采样定理,数字信号所承载波形的最高频率是采样频率的1/2,即在采样频率(采样率)为48k时,数字信号所能呈现的最高频率为24k。采样频率越高,所承载的信号频率越高。
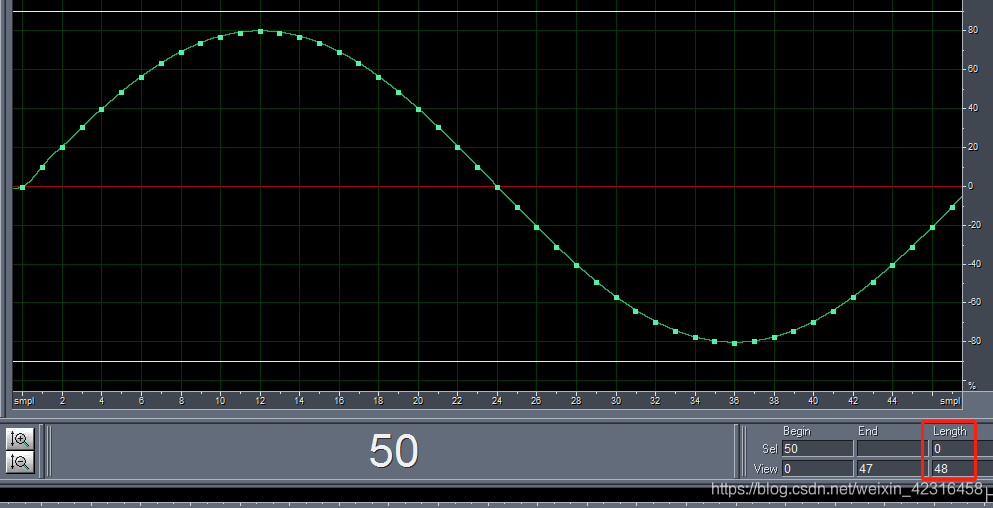
下图为48k采样率下,1000Hz正弦波信号,1个正弦波周期(即1Ms1个周期),1Ms为48个采样点波形图。可以把连续的波形理解为模拟信号,每个点代表数字信号的采样点。
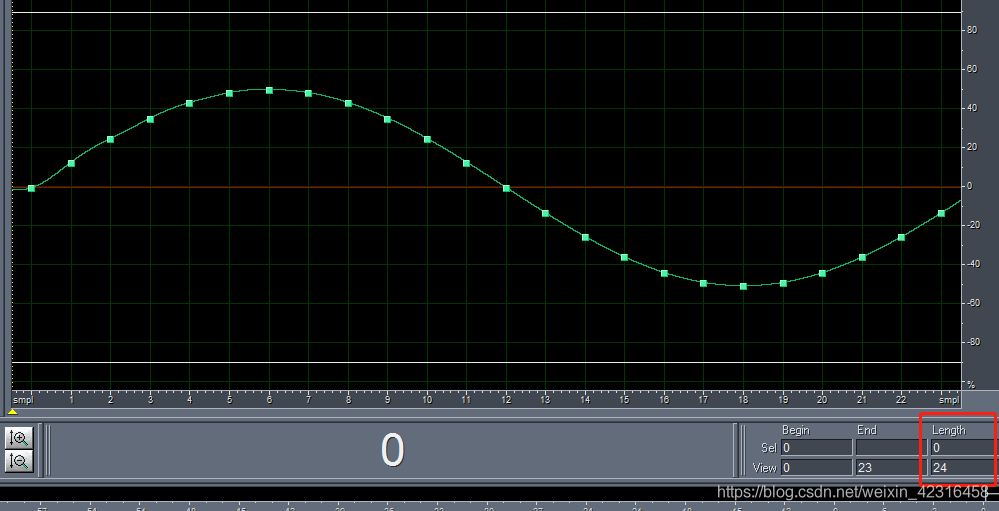
下图为24k采样率下,1000Hz正弦波信号,1个正弦波周期(即1Ms1个周期),1Ms为24个采样点波形图。可以把连续的波形理解为模拟信号,每个点代表数字信号的采样点。
二、采样位深
采样位深——在每次采样时,每个点的数据存储为多少bit。音频在数字信号中,振幅范围为[-1,1],也可以把采样位深理解为将振幅[-1,1]划分为多少级。举个极端、简单的例子,情况①:采样精度为1时,那么采样到数据为-1,0,1。仅三级。情况②:采样精度为0.1时,那么采样到数据为-1,-0.9,-0.8……-0.1,0,0.1……0.8,0.9,1。有21级。所以采样位深越高,所承载的信号的精度越高。
一般我们常看到音频采样位深为16Bit、24Bit。意思是2进制数16位、24位。16位2进制数所能表达的数据范围为-32767-32767。24位2进制数所能表达的数据范围为-8388607~8388607。
理解以上2个概念后,我通过MATLAB来绘图解释这2现象。
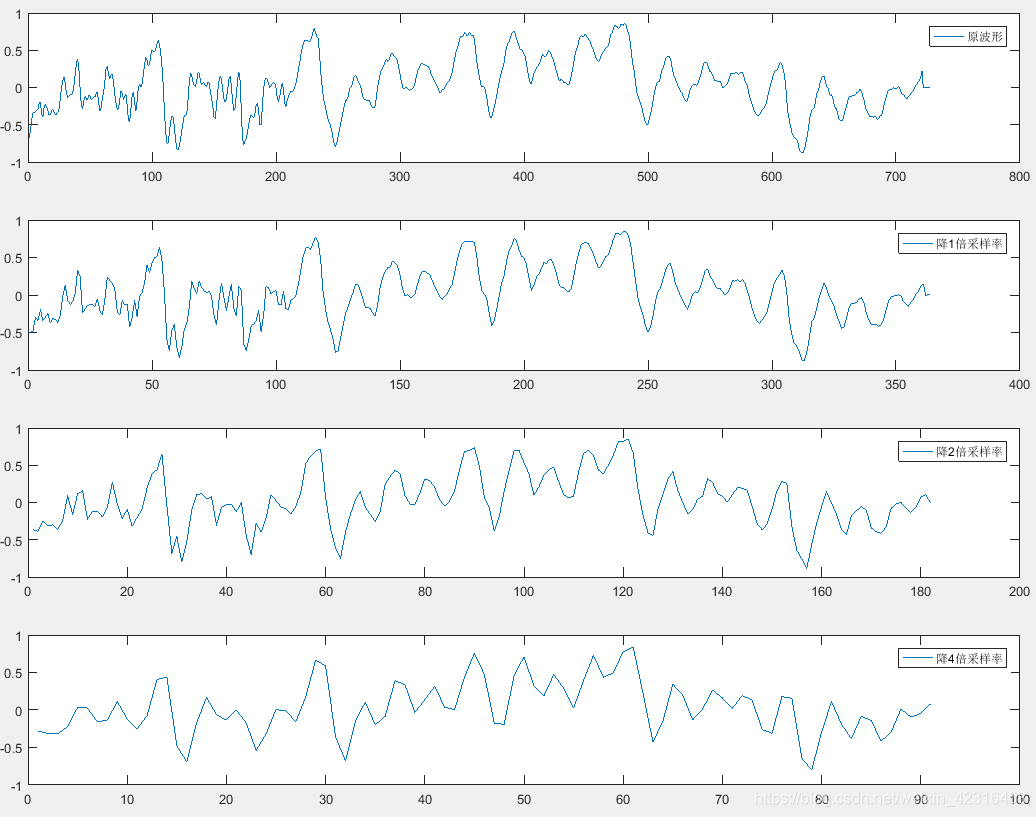
1、验证采样率:将原信号进行降低采样率后,在下图左边部分能明显看出来信号的快速抖动没有了(即高频没有了,因为由于采样率下降,数字信号所能承载的最高频率下降了)。
2、验证采样位深:将原信号进行降低位深后(此处是通过保留小数点位数达到降低划分多少级的目的),在下图能明显看出来信号的连续变化没有了,出来了许多折线(信号线越平滑,表示原信号的相邻点的连续性越强)。

放个大图来看看数据位深(数据精度)造成的问题。

三、关于音质改善的认识
以上仅从数字信号领域浅谈《波》的2个指标。在现实场景中,我们一般所遇到的均是数字音频(即存储在计算机中的音频),而在实际的应用场景中是将数字的音频信号通过“数模转换”后,再通过放大电路和播放设备(喇叭、耳机等)播放出来。

我们常见的HIFI、高音质等名词,一般均指数字音源的参数(采样率和位深)。
关于采样率:初中物理课本中讲人耳能听到的频率为20Hz——20000Hz,而且一般人大概17000~18000Hz以上都听不到,而且年龄越大,能听到的最大频率越小。
而在数字信号中,采样率越高,所能承载的信号频率越高,最高频率为采样率的一半。即采样48k时,能承载的24k,也就是24000Hz。(在我看来,这个采样率已经足够高了,因为即使采样率再高,放出来的音频频率人耳也已经听不到了,所以再高也无意义了)
关于位深:我们一般能看到16Bit/24Bit等指标,这个指标可以说是越高越好,但也要跟后边的DAC、放大电路、播放设备相匹配。(经过我的测试,大多数都听不出16Bit,24Bit的区别,所以我觉得24Bit以上,也都已经无意义了)
综上,如果要改善听感,必须找到这4个环节中的瓶颈,哪个弱改善哪个。不能一味的直追求音源的高品质,而忽略了后面的环节带来的问题。
以下附上Matlab程序
建立一个"check_FS_Bit"文件夹和"OrigWav.wav"文件,即可直接运行以下程序。我使用的是Matlab 2016a版本。
%% 读取源数据
[inSoc, fs] = audioread('check_FS_Bit\OrigWav.wav');
inSoc = inSoc(:,1); %只取单声道做处理
%% 把读取到的wav长度凑成8的整数倍取整
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
if (mod(length(inSoc),8) ~= 0)
inSoc = [inSoc;0];
end
end
end
end
end
end
end
%% 重采样操作
outSoc1 = resample(inSoc,floor(fs/2),fs);
outSoc2 = resample(inSoc,floor(fs/4),fs);
outSoc3 = resample(inSoc,floor(fs/8),fs);
%% 将生成的wav输出
audiowrite('check_FS_Bit\OutWav1.wav',outSoc1, floor(fs/2));
audiowrite('check_FS_Bit\OutWav2.wav',outSoc2, floor(fs/4));
audiowrite('check_FS_Bit\OutWav3.wav',outSoc3, floor(fs/8));
%% 作图
figure(1);
subplot(4,1,1);plot(inSoc); legend('原波形');
subplot(4,1,2);plot(outSoc1); legend('降1倍采样率');
subplot(4,1,3);plot(outSoc2); legend('降2倍采样率');
subplot(4,1,4);plot(outSoc3); legend('降4倍采样率');
%% 降低精度操作
outBitSoc1 = round(inSoc,3);
outBitSoc2 = round(inSoc,2);
outBitSoc3 = round(inSoc,1);
%% 作图
figure(2);
subplot(4,1,1);plot(inSoc); legend('原波形');
subplot(4,1,2);plot(outBitSoc1); legend('保留3位小数');
subplot(4,1,3);plot(outBitSoc2); legend('保留2位小数');
subplot(4,1,4);plot(outBitSoc3); legend('保留1位小数');
%% 作图
figure(3);
clf;
plot(inSoc,'*'); hold on;
plot(outBitSoc1,'b'); hold on;
plot(outBitSoc2,'c'); hold on;
plot(outBitSoc3,'r'); legend('原信号','保留3位小数','保留2位小数','保留1位小数');
axis([9,19,-0.45,-0.15]);















 5180
5180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









