







Double Graph Based Reasoning for Document-level Relation Extraction
Shuang Zeng1,2∗, Runxin Xu1∗, Baobao Chang1,2†and Lei Li3
1Key Laboratory of Computational Linguistics, Peking University, MOE, China
2School of Software and Microelectronics, Peking University, China
3ByteDance AI Lab, China
{zengs,chbb}@pku.edu.cn runxinxu@gmail.com lileilab@bytedance.com
精简总结
本文提出了一种图聚合和参考网络(GAIN)用于篇章级的关系抽取。在公共数据集DocRED上进行了实验,结果表明比当前最好的模型有了F1(2.85)的提高。
https://github.com/DreamInvoker/GAIN
1 介绍
1.1 面临挑战
在文档级有效的关系抽取中有几个主要的挑战:
- 关系中涉及的主体和客体实体可能出现不同的句子中
- 同一实体可能在不同句子中被提及,为了更好地表示,必须聚合跨句子上下文
- 许多关系识别需逻辑推理技术
1.2 先前工作
- 没有考虑推理
- 仅使用基于图或分层的神经网络以隐式方式进行推理
2 任务制定

3 GAIN框架
3.1 模型构成
- Encoding module
- Mention module
- Entity module
- Classfication module

3.2 Encoding module
将文档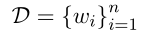 转换为向量序列
转换为向量序列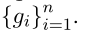
在姚等人(2019)的基础上,对于D中的每个词,我们首先将它的词嵌入与实体类型嵌入和共指嵌入连接起来:
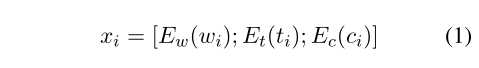
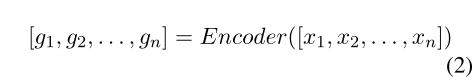
编码器可以用LSTM或其他模型替换。
3.3 Mention-level Graph Aggregation Module
为了对文档级信息以及提及和实体之间的交互进行建模,构建了一个异构提及级图(hMG)。
hMG有两种不同类型的节点:mention node 和 document node。 mention node代表每一个提及的实体,hMG还有一个document node来对文档进行整体建模。
hMG还有三种类型的边Edge:
- Intra-Entity Edge:同一提及实体相连
- Inter-Entity Edge:同一句子中的不同实体相连
- Document Edge:所有提及实体均与之相连
然后用一个Graph Convolution Network对所有来自邻居的特征进行聚合。
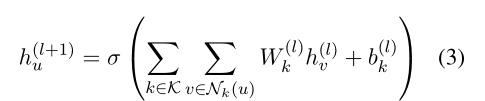
σ 是激活函数(e.g., ReLU).
3.4 Entity-level Graph Inference Module
一个实体可以通过融合来自其提及的信息来表示,这些信息通常分布在多个句子中。此外,潜在的推理线索由实体之间的不同路径来建模。然后,它们可以与注意机制相结合,这样我们就可以考虑潜在的逻辑推理链来预测关系。(详细推理过程见原文)
3.5 Classification Module
对于每个实体对(eh,et),我们连接以下表示:
(1)在实体级图中导出的头和尾实体表示,通过比较操作(Mou等人,2016)来加强特征,即两个实体的表示之间相减的绝对值,| eh-et |,以及元素方向的乘法,eh*et;
(2)文档节点在提及级图mdoc中的表示,因为它可以帮助聚合跨语句信息并提供文档感知表示;
(3)综合推理路径信息ph,t。
4 实验
4.1 数据集
我们在DocRED (Yao等人,2019)上评估了我们的模型,DocRED是一个基于维基百科和维基百科构建的用于文档级RE的大规模人类注释数据集。DocRED共有96种关系类型、132,275个实体和56,354个关系事实。DocRED中的文档平均包含8句左右,超过40.7%的关系事实只能从多句中提取。此外,61.1%的关系实例需要各种推理技能,例如逻辑推理(姚等人,2019)。我们遵循数据集的标准分割,3053个文档用于培训,1000个用于开发,1000个用于测试。关于DocRED更详细的统计,建议读者参考原论文(姚等,2019)。
4.2 实验设置
在我们的GAIN实现中,我们使用了两层GCN,并将辍学率设置为0.6,学习率设置为0.001。我们使用AdamW (Loshchilov和Hutter,2019)作为权重衰减为0.0001的优化器来训练GAIN,并在PyTorch (Paszke等人,2017)和(Wang等人,2019b)下实现GAIN。我们为GAIN实现了三种设置。GAIN-GLow使用GloV e (100d)和BiLSTM (256d)作为单词嵌入和编码器。GAINBERTbaseand和GAIN-Bertlarge分别使用BERTbase和BERTlargeas编码器,学习速率设置为1e 5。
4.3 对比实验

4.4 分析

5 结论
在文档级关系抽取中,抽取句间关系和进行关系推理是具有挑战性的。为了更好地处理文档级关系抽取,本文引入了图聚合与推理网络,该网络以不同粒度的双图为特征。增益利用一个异构的提及级别图来建模文档中不同提及之间的交互,并捕获文档感知特性。它还使用一个实体级图和一个建议的路径推理机制来更明确地推断关系。在大规模人工标注数据集DocRED上的实验结果表明,GAIN优于以前的方法,尤其是在内容和推理关系场景中。消融研究也证实了我们模型中不同模块的有效性。















 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









