






1.global()
返回全局符号表的字典
'''这是一个示例模块'''
def my_function():
"""这是一个示例函数"""
pass
module_docstring = globals()['__doc__']
print(module_docstring) # 输出:"这是一个示例模块"
function_docstring = my_function.__doc__
print(function_docstring) # 输出:"这是一个示例函数"
2.strftime()
指定日期时间输出格式
from datetime import datetime
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")#2023_08_15_17_18_55
3.yaml.safe_load()
将yaml文件中的数据解析为python数据格式(字典、列表、字符串)
import yaml
# 打开并读取 YAML 文件
with open('data.yaml', 'r') as f:
data = yaml.safe_load(f)
print(data)
# 输出解析后的数据
print(data['name']) # 输出:mrwang
print(data['age']) # 输出:19
print(data['city']) # 输出:nanjing
'''
data.yaml
name: mrwang
age: 19
city: nanjing
'''
4.setattr()
设置对象的属性值
class Person:
def __init__(self, name):
self.name = name
# 创建一个 Person 对象
person = Person("Alice")
# 设置属性值
setattr(person, "age", 30)
# 访问属性
print(person.name) # 输出:Alice
print(person.age) # 输出:30
5.torch.set_default_tensor_type(t)
可以设置整个模块或者整个项目使用的统一的tensor类型
torch.set_default_tensor_type(torch.DoubleTensor)
6.torch.numel(input)->int
返回tensor中元素的总个数
a=torch.rand(1,2,3,4)
print(torch.numel(a))#输出24
7.torch.set_printoptions(precision=None,threshold=None,edgeitems=None,linewidth=None,profile=None)]
precision设置保留小数点后几位,默认值为8
torch.set_printoptions(precision=2)
print(torch.tensor(1.2345))#输出1.23
threshold设置显式的显示的数组中数据元素的个数
torch.set_printoptions(threshold=100)
print(torch.rand(100))#将100个数据全部显示,不会因为太多而只显示部分
edgeitems设置多维张量显示时,每个维度显示的元素的个数,和threshold有点像,threshold只对一维的生效,edgeitems对多维的生效。edgeitems的默认值为3
linewidth设置数据间隔宽度,默认值为80
profile设置统一的打印格式,值有:default、short、full
short在数据元素过多时,简略显示,full完全显示,可以覆盖上面的选项
8.torch.from_array(ndarray)->Tensor
返回的张量和ndarray共享一片存储区域,修改一个会导致另一个的修改。返回的张量不能改变大小
a=np.array([[1,2,3],[4,5,6]])
b=torch.from_numpy(a)
print(b)#输出tensor([[1, 2, 3],
#[4, 5, 6]], dtype=torch.int32)
b[0][0]=11
print(a)#输出[[11 2 3]
#[ 4 5 6]]
9.torch.linespace(start,end,steps,out=None)->Tensor
返回一维张量,在start和end之间(包括start也包括end)的均匀间隔的steps个点,长度为steps。
print(torch.linspace(1,10,3))#输出tensor([ 1.0000, 5.5000, 10.0000])
print(torch.linspace(-10,10,10))#tensor([-10.0000, -7.7778, -5.5556, -3.3333, -1.1111, 1.1111, 3.3333,
#5.5556, 7.7778, 10.0000])
10.torch.logspace(start,end,steps,out=None)
生成10的start次方和10的end次方的steps个数据点
print(torch.logspace(-10,10,10))#输出tensor([1.0000e-10, 1.6681e-08, 2.7826e-06, 4.6416e-04, 7.7426e-02, 1.2915e+01,
#2.1544e+03, 3.5938e+05, 5.9948e+07, 1.0000e+10])
11.troch.ones(*size)
print(torch.ones(2,3))#输出tensor([[1., 1., 1.],
#[1., 1., 1.]])
12.torch.rand(*size)
生成(0,1)均匀分布的数据
print(torch.rand(5))
13.torch.randn(*size)
生成均值为0,方差为1的高斯分布数据
print(torch.randn((2,3)))
14.torch.randperm(n)->LongTensor
返回从0到n-1的随机整数序列,和arange(n)不同,它的顺序是随机的,arange的顺序是固定的顺序
print(torch.randperm(9))#tensor([5, 2, 7, 1, 6, 8, 0, 4, 3])
15.torch.arange(start,end,step=1,out=None)
返回一维张量,在[start,end)之间
torch.range(start,end,step=1,out=None)没什么区别,只不过数据包含end
print(torch.arange(1,89,9))#输出tensor([ 1, 10, 19, 28, 37, 46, 55, 64, 73, 82])
16.torch.zeros(*size)
print(torch.zeros(2,3))#输出tensor([[0., 0., 0.],
#[0., 0., 0.]])
2.索引 切片 连接 换位
17.torch.cat(inputs,dimension)->Tensor
在给定的维度对输入张量序列进行连接
input:任意相同类型的Tensor的序列
dimension(可选):沿着这个维度连接张量
a=torch.randn(2,3)
b=torch.cat((a,a,a),0)
print(b)
沿着哪个维度连接,哪个维度的长度就会增加
18.torch.chunk(tensor,chunks,dim=0)
chunks是分块的个数
print(torch.chunk(a,2,1))
19.torch.gather(input,dim,index,out=None)
灵活的选取index指定的位置的值进行聚合
注意:
1.index必须是一个张量,不能是普通数组
2.index的形状和input的形状可以不相同
3.index的值作为位置的索引
4.选取值的规则如下:
out[i][j][k] = tensor[index[i][j][k]][j][k] # dim=0
out[i][j][k] = tensor[i][index[i][j][k]][k] # dim=1
out[i][j][k] = tensor[i][j][index[i][j][k]] # dim=3
torch.set_printoptions(precision=2)
a=torch.rand(2,3)
aa=torch.gather(a,1,index=torch.LongTensor([[0,1,2],[2,1,1]]))
print("a=",a)
print("aa=",aa)
每个位置的输出结果是:
[0,0] [0,1] [0,2]
[1,2] [1,1] [1,1]

注:输出的形状和index一致
20.torch.index_select(input, dim, index)
torch.set_printoptions(precision=2)
# 选取第0行和第3行
a=torch.rand(4,6)
aa=torch.index_select(a,dim=0,index=torch.LongTensor([0,3]))
print('a=',a)
print('aa=',aa)
# 选取第1列和第5列
aaa=torch.index_select(a,dim=1,index=torch.LongTensor([1,5]))
print('aaa=',aaa)
# 选取a的第0行第3行、第1列和第5列,没有先后顺序
aaaa=torch.index_select(aa,dim=1,index=torch.LongTensor([1,5]))
print('aaaa=',aaaa)
21.torch.masked_select(input,mask)
a=torch.rand(2,3)
mask1=torch.BoolTensor([[1,0,1],[0,1,0]])
mask2=torch.ByteTensor([[True,False,True],[False,True,False]])
mask3=torch.BoolTensor([[True,False,True],[False,True,False]])
#[[True,False,True],[False,True,False]]
aa=torch.masked_select(a,mask3)
print('a=',a)
print('aa=',aa)

22.torch.nonzero(input)
返回非0元素的位置索引
如果输入是n维,那么输出的tensor形状是z*n的,z是输入中所有非0元素的总个数
a=torch.tensor([[[1,0,3],[0,0,9]],[[1,2,0],[0,9,0]]])
aa=torch.nonzero(a)
print('a=',a)
print('aa=',aa)

22.torch.split(tensor,split_size,dim)
split_size是切分成的单个块的大小,和chunk不同的是chunk指定的是分块的个数的数量,相同点是它们返回的都是元组,两个效果类似
a=torch.rand(2,3)
aa=torch.split(a,2,dim=1)
print('a=',a)
print('aa=',aa)

23.torch.squeeze(input,dim=None)
将形状中为1的维度去除,比如输入的形状是(A1BCD1E)那么输出的形状是(ABCDE)
就指定维度,也只对1的形状有效,如果指定的维度长度不为1,则无效,原样输出
a=torch.rand(2,3,1)
aa=torch.squeeze(a)
print('a=',a.size())
print('aa=',aa.size())
aaa=torch.squeeze(a,dim=1)
print('aaa=',aaa.size())

注意:
虽然squeeze前后squeeze后的维度不一致,但是数据量(数据元素的个数)是一致的,并且它们共享一片存储区域,当修改其中一个值时,另一个也会跟着修改。
24.torch.stack(sequence,dim=0)-堆叠函数
将序列中包含的张量按照指定维度连接,所有张量的形状应该相同,否则会报错。增加新维度,不是在原有基础上叠加
如两个(2,3)进行stack得到的不会是(4,3),而是(2,2,3)
a=torch.rand(2,3)
b=torch.rand(2,3)
ab=torch.stack((a,b),dim=0)
print('a=',a)
print('b=',b)
print('ab_size=',ab.size())
print('ab=',ab)

25.torch.transpose(input,dim0,dim1)-转置函数
1)交换维度
a=torch.rand(2,3,4)
print('a_size:',a.size())
aa=torch.transpose(a,2,1)
print('aa_size:',aa.size())

2.共享内存
26.torch.unbind(tensor,dim)-解除维度
(2,3,4)->(1,3,4)+(1,3,4)的元组dim=0时
(2,3,4)->(2,1,4)+(2,14)+(2,1,4)的元组dim=1时
a=torch.rand(2,3,4)
aa=torch.unbind(a,1)
print(aa)
print(aa[1].size())

返回的是元组
torch.unsqueeze(tensor,dim)
1)squeeze的反操作,在dim指定的位置增加一个长度为1的维度(abcd)->(a1bc*d)若dim=1
2)共享内存
a=torch.rand(2,3,4)
aa=torch.unsqueeze(a,2)
print(aa.size())
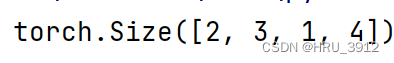
3.随机抽样
3.1 torch.manual_seed(seed)
设置生成随机数的种子
3.2 torch.initial_seed()
获得生成随机数的原始种子,如果在这之前用manual_seed(seed)设置过了,那么会获得设置的seed值。否则会获得随机值
3.3 torch.get_rng_state()
获得随机生成器的状态
print(torch.get_rng_state().size())

3.4 torch.set_rng_state(new_state)
new_state:torch.ByteTensor 长度为5056
3.5 torch.bernoulli(input)
1,输入概率
2.输出和输入形状相同的0或1值
a=torch.rand(3,4)#生成均匀分布的概率
print(torch.bernoulli(a))

3.6 torch.multinomial(input,num_samples,replacement=False)->LongTensor
a=torch.tensor([8.,5,6,7,2])
print(torch.multinomial(a,5,replacement=False))
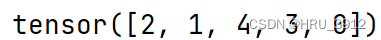
input表示每个位置索引的概率值,不要求和为1,要求非负;并且input要为浮点数,否则会报错
b=torch.tensor([[1.,2,3],[4,5,6]])
print(torch.multinomial(b,2))
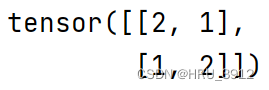
3.6 torch.normal(mean,std)-一组从均值和方差各不相同的正态分布采样的数据点的集合
mean和std都是张量
mean=torch.tensor(torch.arange(1.,11))
std=torch.tensor(torch.linspace(1.0,0,10))
print(torch.normal(mean,std))
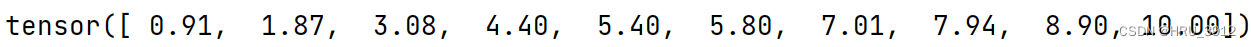
也可以将std设置为一个常数,共享方差
print(torch.normal(mean,1.))
4.序列化-保存pytorch中的对象到硬盘上
4.1保存和加载tensor
t=torch.tensor([1,2,3])
torch.save(t,'tensor.pt')

tt=torch.load('tensor.pt')
print(tt)
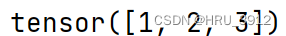
还可以将多个tensor封装到tuple、list、dict里面一起保存
t1=torch.tensor([1,2,3])
t2=torch.tensor([4,5,6])
t3=torch.tensor([7,8,9])
torch.save([t1,t2,t3],'tensor1.pt')
t11,t22,t33=torch.load('tensor1.pt')
print(t11,t22,t33)
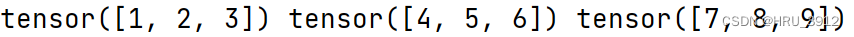
保存加载tensor可保留视图
不太明白
numbers = torch.arange(1, 10)
evens = numbers[1::2]
print(evens)
torch.save([numbers, evens], 'tensors.pt')
loaded_numbers, loaded_evens = torch.load('tensors.pt')
print(loaded_numbers)
print(loaded_evens)
loaded_evens *= 2
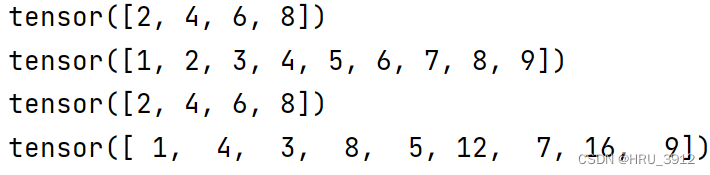
似乎是切片共享存储(Storage区)
large = torch.arange(1, 1000)
small = large[0:5]
torch.save(small, 'small.pt')
loaded_small = torch.load('small.pt')
print(loaded_small.storage().size())
large = torch.arange(1, 1000)
small = large[0:5]
torch.save(small.clone(), 'small.pt') # saves a clone of small
loaded_small = torch.load('small.pt')
print(loaded_small.storage().size())
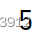
4.2 保存和加载torch.nn.Modules
模块的状态常常使用状态字典序列化,模块的状态字典包括所有参数和永久缓冲区
bn = torch.nn.BatchNorm1d(3, track_running_stats=True)
print(list(bn.named_parameters()))
print('------------------------')
print(list(bn.named_buffers()))
print('------------------------')
print(bn.state_dict())
结果:
[(‘weight’, Parameter containing:
tensor([1., 1., 1.], requires_grad=True)), (‘bias’, Parameter containing:
tensor([0., 0., 0.], requires_grad=True))]
[(‘running_mean’, tensor([0., 0., 0.])), (‘running_var’, tensor([1., 1., 1.])), (‘num_batches_tracked’, tensor(0))]
OrderedDict([(‘weight’, tensor([1., 1., 1.])), (‘bias’, tensor([0., 0., 0.])), (‘running_mean’, tensor([0., 0., 0.])), (‘running_var’, tensor([1., 1., 1.])), (‘num_batches_tracked’, tensor(0))])
Process finished with exit code 0
由于兼容性问题,通常不保存模块,而是保存状态字典,从字典恢复模块
bn = torch.nn.BatchNorm1d(3, track_running_stats=True)
print(list(bn.named_parameters()))
print('------------------------')
print(list(bn.named_buffers()))
print('------------------------')
print(bn.state_dict())
torch.save(bn.state_dict(), 'bn.pt')
bn_state_dict = torch.load('bn.pt')
new_bn = torch.nn.BatchNorm1d(3, track_running_stats=True)
new_bn.load_state_dict(bn_state_dict)
这里bn没有经过反向传播,所以将它的状态字典赋值给new_bn是没有意义的
另外,自定义的模块也有状态字典
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.l0 = torch.nn.Linear(4, 2)
self.l1 = torch.nn.Linear(2, 1)
def forward(self, input):
out0 = self.l0(input)
out0_relu = torch.nn.functional.relu(out0)
return self.l1(out0_relu)
m = MyModule()
print(m.state_dict())
torch.save(m.state_dict(), 'mymodule.pt')
m_state_dict = torch.load('mymodule.pt')
new_m = MyModule()
new_m.load_state_dict(m_state_dict)
torch.load()指定remap后的数据的位置
tt=torch.load('tensor.pt',map_location={'cpu':'cuda:0'})
print(tt)
5.并行化
5.1torch.get_num_threads()
获得用于并行CPU操作的openMP线程数
5.2torch.set_nunm_threads(num)
设置openMP的数目,越大CPU的占用越多
6.数学操作
torch.acos(input)-反余弦值
torch.add(input, value=1, other, out=None)-out=input+(other∗value)
torch.addcdiv(tensor, value=1, tensor1, tensor2, out=None) → Tensor
用tensor2逐元素除以tensor1乘上value再加上tensor,注意目前只支持tensor用浮点数格式
tensor2=torch.tensor([1.,2,3])
tensor1=torch.tensor([5.,6,7])
tensor=torch.tensor([8.,9,6])
re=torch.addcdiv(tensor,value=2,tensor1=tensor1,tensor2=tensor2)
print(re)
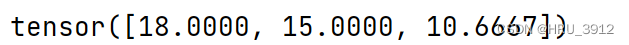
torch.addcmul和上面一样,只是相除改为相乘
torch.atan(input, out=None) → Tensor
torch.atan2(input1, input2, out=None) → Tensor
torch.ceil(input)-向上取整
a=torch.tensor([1.9,6.7,9.5])
print(a)
print(torch.ceil(a))
torch.clamp(input,min,max)
将输入 input 张量每个元素的夹紧到区间 [min,max],并返回结果到一个新张量。
a=torch.tensor([1.9,6.7,9.5])
print(a)
print(torch.clamp(a,5,9))

也可以只限制最小值或最大值
a=torch.tensor([1.9,6.7,9.5])
print(a)
print(torch.clamp(a,5))

torch.cosh-双曲余弦
torch.div(input, value, out=None)-input逐元素除以标量值
a=torch.tensor([1.9,6.7,9.5])
print(a)
print(torch.div(a,5))
 】
】
torch.div(input, other, out=None)-input和other都是张量,input除以other
torch.exp(input)-每个输入值的指数
a=torch.tensor([0,math.log(3)])
print(torch.exp(a))
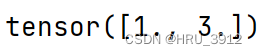
torch.floor(input)向下取整
a=torch.tensor([9.5,7.3,6.9])
print(torch.floor(a))
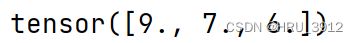
torch.log1p(input, out=None) → Tensor
yi=log(xi+1)对输较小的输入值,这个函数的输出值比torch.log更准确
torch.mul(input,value)
a=torch.tensor([1,2,3,4])
print(torch.mul(a,4))
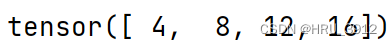
torch.mul(tensor1,tensor2)-两个张量逐元素相乘
a=torch.tensor([1,2,3,4])
b=torch.tensor(([2,3,4,5]))
print(torch.mul(a,b))

torch.neg(input)-取负
a=torch.tensor([1,2,3,4])
print(torch.neg(a))
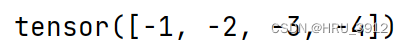
torch.pow(input,exponet)-指数函数,其中exponent可以是单一数,或者于input形状相同的张量,或者input为单一数,exponent为张量
a=torch.tensor([1,2,3,4])
print(torch.pow(a,4))
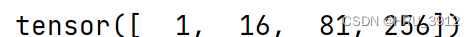
a=torch.tensor([1,2,3,4])
print(torch.pow(a,torch.tensor([5,4,3,2])))
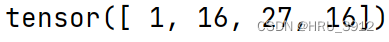
a=torch.tensor([1,2,3,4])
print(torch.pow(2,a))
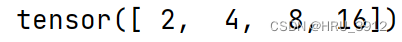
torch.reciprocal(input)-取倒数,输出浮点数
a=torch.tensor([1,2,4,5])
print(torch.reciprocal(a))
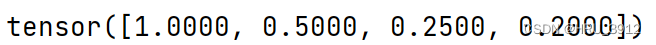
torch.remainder(input,other)-求余数
a=torch.tensor([1.1,2.2,4.4,5.6])
b=torch.tensor([2,2,4,5])
print(torch.remainder(a,b))
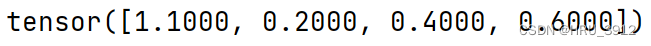
torch.round(input)-四舍五入
a=torch.tensor([1.1,2.2,4.4,5.6])
print(torch.round(a))

orch.rsqrt(input, out=None) → Tensor平方根倒数
a=torch.tensor([1.1,2.2,4.4,5.6])
print(torch.rsqrt(a))
print(1/torch.sqrt(torch.tensor([1.1])))
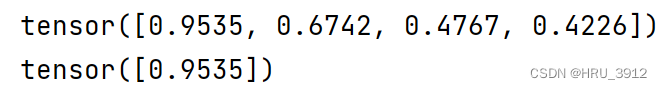
torch.sigmoid(input, out=None) → Tensor
torch.sign(input)
a=torch.tensor([1.1,2.2,-4.4,5.6])
print(torch.sign(a))-求符号
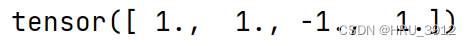
torch.trunc(input, out=None) → Tensor输出input的截断值,有符号的小数部分被舍弃
a=torch.tensor([1.1,2.2,-4.4,5.6])
print(torch.trunc(a))
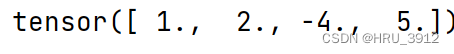
7.减少操作
7.1 torch.cumprod(input, dim, out=None) → Tensor按指定维度进行累乘
a=torch.tensor([1,2,-4,5])
print(torch.cumprod(a,dim=0))
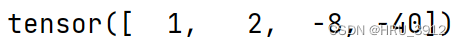
a=torch.rand([2,3])
print('a=',a)
print('dim=0:',torch.cumprod(a,dim=0))
print('dim=1:',torch.cumprod(a,dim=1))

torch.cumsum(input,dim)
a=torch.tensor([[1,2],[3,4]])
print('a=',a)
print('dim=0:',torch.cumsum(a,dim=0))
print('dim=1:',torch.cumsum(a,dim=1))

torch.dist(input,other,p)-返回(input-other)的p范数
a=torch.tensor([1.,2,3,4])
b=torch.tensor([5.,6,7,8])
print(torch.dist(b,a,2))
print(torch.dist(b,a,2).size())
print(type(torch.dist(b,a,2)))

torch.mean(input)->float-求张量的均值
a=torch.tensor([1.,2,3,4])
print(torch.mean(a))

torch.mean(input,dim)->Tensor
a=torch.rand(2,3)
print('a=',a)
print('dim=0:',torch.mean(a,dim=0))
print('dim=1:',torch.mean(a,dim=1))

torch.median(input,dim)
不指定dim默认为所有的数
a=torch.rand(2,3)
print('a=',a)
print('no_dim:',torch.median(a))
print('dim_0:',torch.median(a,dim=0))
print('dim_1:',torch.median(a,dim=1))

torch.mode(input,dim)
不指定dim默认为最后一个dim
a=torch.tensor([[1,2,2],[3,4,4]])
print('a=',a)
print('no_dim:',torch.mode(a))
print('dim_0:',torch.mode(a,dim=0))
print('dim_1:',torch.mode(a,dim=1))

torch.norm(input,p,dim)-范数
a=torch.tensor([[1.,2,2],[3,4,4]])
print('a=',a)
print('no_dim:',torch.norm(a,2))
print('dim_0:',torch.norm(a,2,dim=0))
print('dim_1:',torch.norm(a,2,dim=1))

torch.prod(input,dim)所有元素的乘积,但不是累乘
a=torch.tensor([[1.,2,2],[3,4,4]])
print('a=',a)
print('no_dim:',torch.prod(a))
print('dim=0:',torch.prod(a,dim=0))
print('dim=1:',torch.prod(a,dim=1))

torch.std(input,dim)标准差
a=torch.tensor([[1.,2,2],[3,4,4]])
print('a=',a)
print('no_dim:',torch.std(a))
print('dim=0:',torch.std(a,dim=0))
print('dim=1:',torch.std(a,dim=1))

torch.var(input,dim)方差
torch.sum(input,dim)和
8.比较操作
torch.eq(tensor1,tensor2)
输入的两个张量的形状必须相同,否则会报错
a=torch.tensor([1,2,3,4])
b=torch.tensor([1,2,4,4])
print(torch.eq(a,b))

torch.equal(tensor1,tensor2)
如果两个张量有相同的形状和值,那么返回真,否则返回假
a=torch.tensor([1,2,3,4])
b=torch.tensor([1,2,3,4])
print(torch.equal(a,b))
torch.ge(tensor1,tensor2)判断是否大于等于
a=torch.tensor([0,2,3,4])
b=torch.tensor([1,2,3,4])
print(torch.ge(a,b))

torch.gt(tensor1,tensor2)判断是否严格大于
a=torch.tensor([0,2,3,7])
b=torch.tensor([1,2,3,4])
print(torch.gt(a,b))
 ‘
‘
torch.kthvalue(input,k,dim)返回第k个最小值和所在位置的元组,不指定dim默认为最后一个dim
a=torch.tensor([0,8,3,7])
print(torch.kthvalue(a,2))

torch.le(tensor1,tensor2)-小于等于
torch.lt(tensor1,tensor2)-严格小
torch.max(tensor1,tensor2)-比较并返回二者之间的较大者
a=torch.tensor([0,8,3,7])
b=torch.tensor([5,2,1,8])
print(torch.max(a,b))
torch.ne(tensor1,tensor2)-不等于
a=torch.tensor([0,8,3,7])
b=torch.tensor([5,2,3,8])
print(torch.ne(a,b))
torch.sort(input,dim)-按照指定维度排序并输出
a=torch.tensor([0,8,3,7])
print(torch.sort(a,descending=True))

torch.topk(input,k,dim)返回k个最大值和其索引
a=torch.tensor([0,8,3,7])
print(torch.topk(a,2)

9.其他操作
torch.cross
torch.cross(input, other, dim=-1, out=None) → Tensor
返回沿着维度 dim 上,两个张量 input 和other 的向量积(叉积)。 input 和 other 必须有相同的形状,且指定的 dim 维上 size 必须为 3。
如果不指定 dim,则默认为第一个尺度为 3 的维。
a=torch.rand(3,3)
b=torch.rand(3,3)
re=torch.cross(a,b,dim=0)
print(re)

torch.diag(input,dim)
• diagonal = 0, 主对角线
• diagonal > 0, 主对角线之上
• diagonal < 0, 主对角线之下
a=torch.rand(3)
print(torch.diag(a))
print(torch.diag(a,diagonal=0))
print(torch.diag(a,diagonal=1)

torch.histc(input,bins,min,max)-直方图
a=torch.tensor([0.,0,8,6,6,5,4,3,9,1])
print(a)
print(torch.histc(a,bins=5,min=0,max=10))
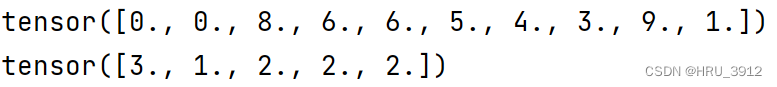 ’
’
torch.trace(input)
a=torch.arange(1,10).view(3,3)
print(a)
print(torch.trace(a))

















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









