







0. 获取数据集
关注公众号:『AI学习星球』
回复:基于水色图像的水质评价 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我

1. 项目背景及目标
水产养殖业是国民经济的一个重要组成部分,水域内污染物的检测与评价非常重要。在水质的检测方面,数字图像处理技术是基于计算机视觉,以专家经验为基础,来对池塘水色进行优劣分级,以实现对池塘水色的准确快速判别。本文使用拍摄的池塘水样图片数据,结合图像切割和特征提取技术,使用决策树算法对水质进行预测,以辅助生产人员对水质状况进行判断。
- 定义数据挖掘目标:
- 对水样图片进行切割,提取水样图片中的特征。
- 基于提取的特征数据,构建水质评价模型。
- 对构建的模型进行评价,评价模型对水色的识别效率。
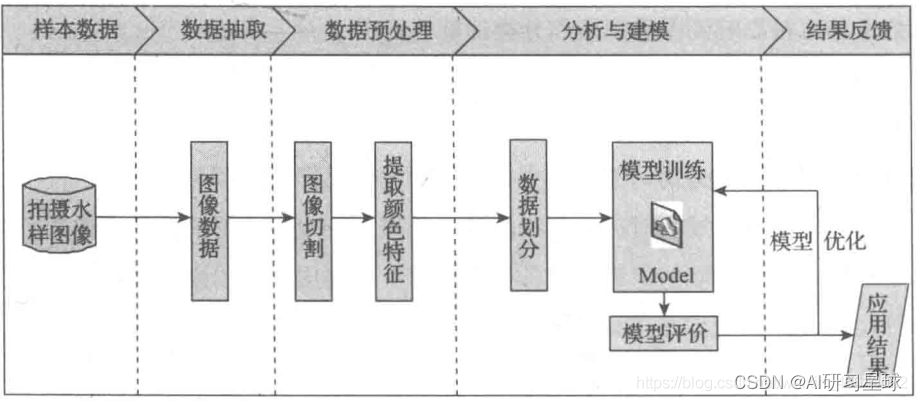
2. 分析步骤:
- 从采集到的原始水样图像中进行选择性抽取形成建模数据。
- 数据预处理:包括图像切割和颜色矩阵特征提取。
- 利用训练集构建分类模型。
- 利用训练集进行模型评价。
3. 数据预处理
3.1图像切割
一般情况下,采集到的水样图片包含盛水容器,且容器颜色与水体颜色差异较大,同时水体位于图片中央,所以为了提取水色特征,就需要提取水样图片中央部分具有代表意义的图像,具体实施方式是提取水样图像中央101×101像素的图像。设原始图像的大小是M×N,则截取宽从第M/2 -50个像素点到第M/2+50个像素点,高从第N/2 -50个像素点到第N/2+50个像素点的子图像
3.2特征提取
图像特征主要包括颜色特征、纹理特征、形状特征、空间关系特征等。与几何特征相比,颜色特征更为稳健,对于物体的大小和方向均不敏感,表现出较强的鲁棒性。本案例中,由于水色图像是均匀的,故主要关注颜色特征即可。颜色特征是一种全局特征,它描述了图像或图像区域所对应的景物的表面性质。一般颜色特征是基于像素点的特征,所有属于图像或图像区域的像素都有各自的贡献。在利用图像的颜色信息进行图像处理、识别、分类的研究实现方法上已有大量的研究成果,主要采用颜色处理常用的直方图法和颜色矩方法等。
颜色直方图是最基本的颜色特征表示方法,它反映的是图像中颜色的组成分布即出现了哪些颜色以及各种颜色出现的概率。其优点在于它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。其缺点在于它无法描述图像中颜色的局部分布及每种色彩所处的空间位置,即无法描述图像中的某一具体的对象或物体。
基于颜色矩提取图像特征数学基础在于图像中任何的颜色分布均可以用它的矩来表示。根据概率论的理论,随机变量的概率分布可以由其各阶矩唯一地表示和描述,一副图像的色彩分布也可认为是一种概率分布,那么图像可以由其各阶矩来描述。颜色矩包含各个颜色通道的一阶距、二阶矩和三阶矩,对于一副RGB颜色空间的图像,具有R、G和B3个颜色通道,则有9个分量。
颜色直方图产生的特征维数一般大于颜色矩的特征维数,为了避免变量过多影响后续分类效果,选择基于颜色矩提取图像特征的方式,建立水样图像与反映该图像特征的数据信息之间的关系。
3.2.1各阶颜色矩的计算公式
-
一阶颜色矩采用一阶原点矩,反映了图像的整体明暗程度

-
二阶颜色矩采用的是二阶中心距的平方根,反映了图像颜色的分布范围

-
三阶颜色矩采用的是三阶中心距的立方根,反映了图像颜色分布的对称性

3.3 python实现
import numpy as np
import os, re
from PIL import Image
def get_ImgNames(path):
"""
获取图片名称
:param path: 路径
:return: 名称列表
"""
# os.listdir用于返回该路径下所包含的文件或文件夹的名字列表
filenames = os.listdir(path=path)
imgnames = []
for i in filenames:
# 在返回的文件名字中寻找正则表达式所匹配的所有字符串,如果不存在,返回空列表
if re.findall('^\d_\d+\.jpg$', i) != []:
imgnames.append(i)
return imgnames
def Var(data=None):
"""
获取三阶颜色矩
:param p: 数据
:return: 返回三阶颜色矩
"""
x = np.mean((data - data.mean()) ** 3)
return np.sign(x) * np.abs(x) ** 1 / 3
def imageCutting_FeatureExtraction(path, imgnames=None):
"""
图像切割与基于颜色矩进行特征提取
:param path: 路径
:param imgnames: 所有图片的名称
:return: 返回特征提取后的9个分量,以及对应标签
"""
# 获取图片的数目
n = len(imgnames)
data = np.zeros((n, 9)) # 用来存放特征提取后的分量
label = np.zeros((n)) # 用来存放样本标签
# 对每一张图片进行图像分割,并计算9个分量
for i in range(n):
# 打开图像文件
img = Image.open(path + imgnames[i])
# 获取图片的尺寸
M, N = img.size
# 图像切割提取图样中间部分,img.crop返回图像的矩阵区域,参数为 (left, upper, right, lower)的元祖
img = img.crop((M / 2 - 50, N / 2 - 50, M / 2 + 50, N / 2 + 50))
# 将图像分割成3个通道,
r, g, b = img.split()
# 转化为数组数据并归一化,获得对应的像素矩阵
rd = np.array(r, dtype=np.float32) / 255
gd = np.array(g, dtype=np.float32) / 255
bd = np.array(b, dtype=np.float32) / 255
# 计算一阶颜色矩
data[i, 0] = rd.mean()
data[i, 1] = gd.mean()
data[i, 2] = bd.mean()
# 计算二阶颜色矩
data[i, 3] = rd.std()
data[i, 4] = gd.std()
data[i, 5] = bd.std()
# 计算三阶颜色矩
data[i, 6] = Var(rd)
data[i, 7] = Var(gd)
data[i, 8] = Var(bd)
# 获取样本标签-每个图片名的第一个数字代表类别
label[i] = imgnames[i][0]
return data, label
if __name__ == '__main__':
# 获取所有图片的名称
imgNames = get_ImgNames(path='data/images')
# 图像切割与特征提取
data, label = imageCutting_FeatureExtraction(path='data/images/', imgnames=imgNames)
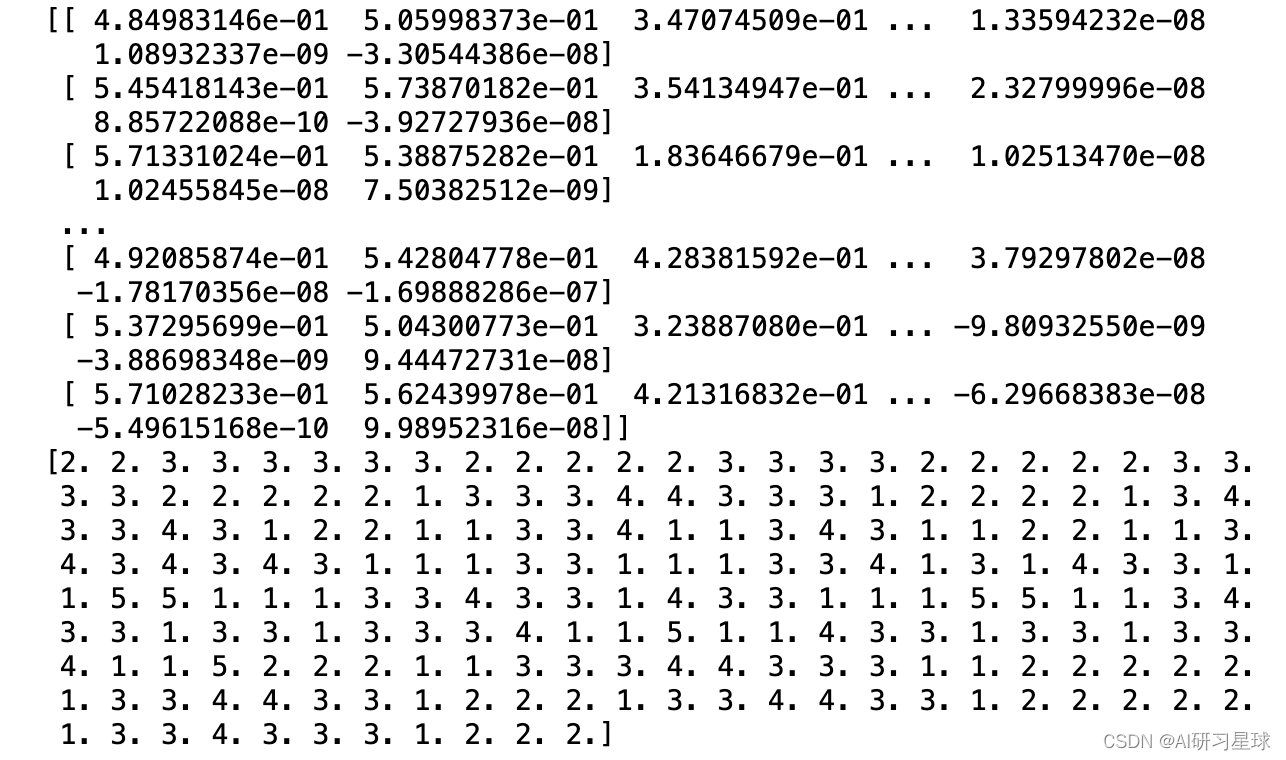
print(data)
print(label)
4. 模型构建
使用决策树模型来构建水质评价分类模型
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, accuracy_score
# 划分数据集
# shuffle=True尽可能每一类别都取到或者采用分层抽样
data_tr, data_te, label_tr, label_te = train_test_split(data, label, test_size=0.2, shuffle=True)
model = DecisionTreeClassifier(random_state=1234)
model.fit(data_tr, label_tr)
# 预测
pred_te = model.predict(data_te)
# 混淆矩阵
cm = confusion_matrix(label_te, pred_te)
print('混淆矩阵为\n', cm)
# 准确率
acc = accuracy_score(label_te, pred_te)
print('准确率为\n', acc)

分层抽样
StratifiedKFold分层的K折交叉和验证,是将训练集划分为训练集与验证集,保证它们中的比例。根据分层抽样思想自定义函数,保证训练集与测试集的类别比例与原数据集中的相等。完整代码如下
import math
import numpy as np
import os, re
from PIL import Image
import pandas as pd
def get_ImgNames(path):
"""
获取图片名称
:param path: 路径
:return: 名称列表
"""
# os.listdir用于返回该路径下所包含的文件或文件夹的名字列表
filenames = os.listdir(path=path)
imgnames = []
for i in filenames:
# 在返回的文件名字中寻找正则表达式所匹配的所有字符串,如果不存在,返回空列表
if re.findall('^\d_\d+\.jpg$', i) != []:
imgnames.append(i)
return imgnames
def Var(data=None):
"""
获取三阶颜色矩
:param p: 数据
:return: 返回三阶颜色矩
"""
x = np.mean((data - data.mean()) ** 3)
return np.sign(x) * np.abs(x) ** 1 / 3
def imageCutting_FeatureExtraction(path, imgnames=None):
"""
图像切割与基于颜色矩进行特征提取
:param path: 路径
:param imgnames: 所有图片的名称
:return: 返回特征提取后的9个分量,以及对应标签
"""
# 获取图片的数目
n = len(imgnames)
data = np.zeros((n, 9)) # 用来存放特征提取后的分量
label = np.zeros((n)) # 用来存放样本标签
# 对每一张图片进行图像分割,并计算9个分量
for i in range(n):
# 打开图像文件
img = Image.open(path + imgnames[i])
# 获取图片的尺寸
M, N = img.size
# 提取图样中间部分,img.crop返回图像的矩阵区域,参数为 (left, upper, right, lower)的元祖
img = img.crop((M / 2 - 50, N / 2 - 50, M / 2 + 50, N / 2 + 50))
# 将图像分割成3个通道,
r, g, b = img.split()
# 转化为数组数据并归一化,获得对应的像素矩阵
rd = np.array(r, dtype=np.float32) / 255
gd = np.array(g, dtype=np.float32) / 255
bd = np.array(b, dtype=np.float32) / 255
# 计算一阶颜色矩
data[i, 0] = rd.mean()
data[i, 1] = gd.mean()
data[i, 2] = bd.mean()
# 计算二阶颜色矩
data[i, 3] = rd.std()
data[i, 4] = gd.std()
data[i, 5] = bd.std()
# 计算三阶颜色矩
data[i, 6] = Var(rd)
data[i, 7] = Var(gd)
data[i, 8] = Var(bd)
# 获取样本标签
label[i] = imgnames[i][0]
return data, label
def split_train_test(data, test_size=0.2):
"""
保证训练集与测试集的类别比例与原数据集中的相等
:param data: 特征向量
:param label: 标签
:param test_size: 测试集比例
:return: 训练集与测试集
"""
label = set(data.iloc[:, -1])
data_tr = pd.DataFrame()
data_te = pd.DataFrame()
for i in label:
data_i = data[data.iloc[:, -1] == i]
# 标签是i的数据集长度
length = len(data_i)
# 切割的数据长度
split_length = math.floor(length * test_size)
tr = data_i.iloc[:split_length, :]
te = data_i.iloc[split_length:, :]
data_tr = data_tr.append(tr)
data_te = data_te.append(te)
return data_tr.iloc[:, :-1], data_te.iloc[:, :-1], data_tr.iloc[:, -1], data_te.iloc[:, -1]
if __name__ == '__main__':
# 获取所有图片的名称
imgNames = get_ImgNames(path='data/images')
# 图像切割与特征提取
data, label = imageCutting_FeatureExtraction(path='data/images/', imgnames=imgNames)
print(data)
print(label)
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, accuracy_score
data = pd.DataFrame(np.hstack((data, label.reshape(-1, 1))))
# 划分数据集
data_tr, data_te, label_tr, label_te = split_train_test(data, test_size=0.2)
model = DecisionTreeClassifier(random_state=1234)
model.fit(data_tr, label_tr)
# 预测
pred_te = model.predict(data_te)
# 混淆矩阵
cm = confusion_matrix(label_te, pred_te)
print('混淆矩阵为\n', cm)
# 准确率
acc = accuracy_score(label_te, pred_te)
print('准确率为\n', acc)
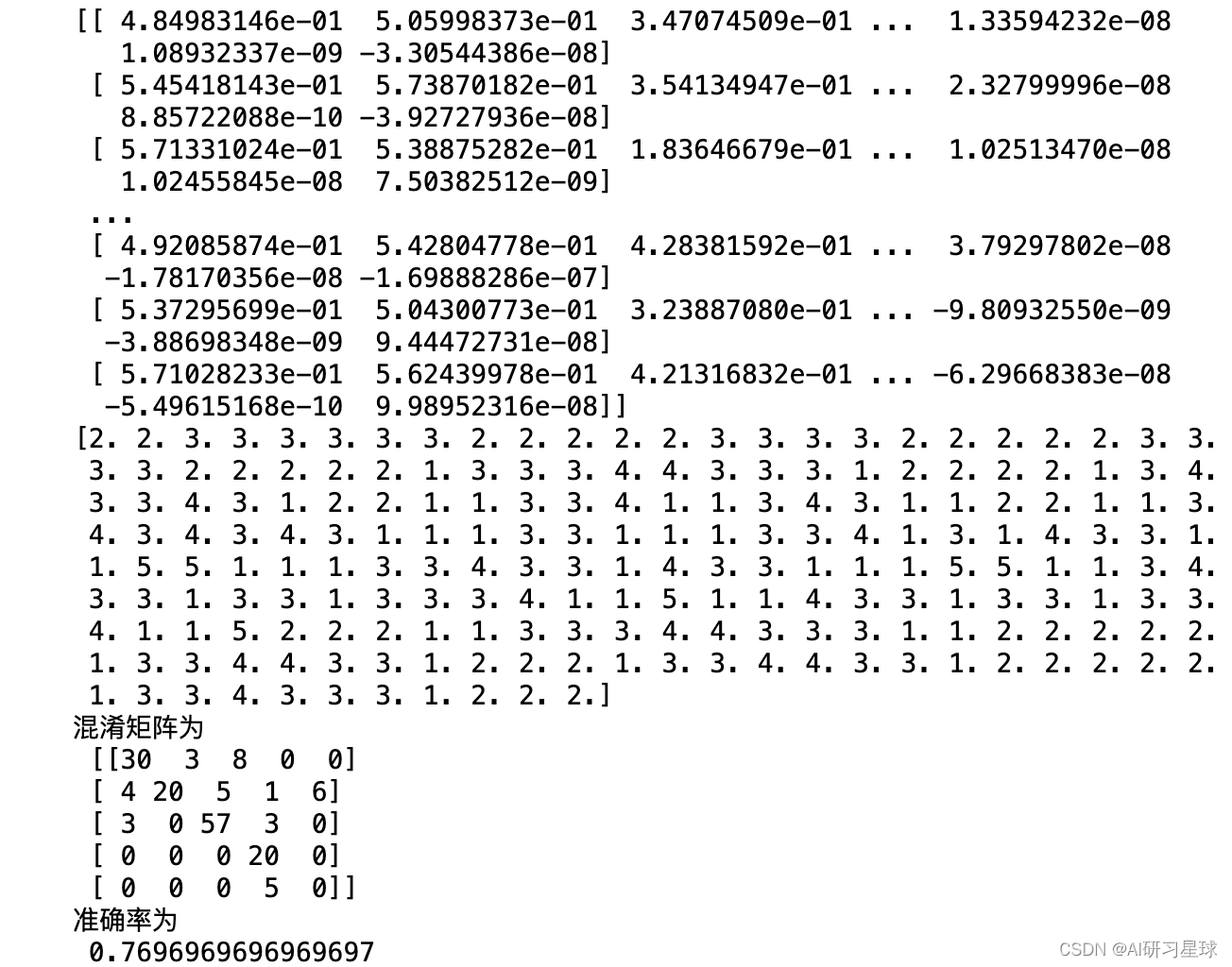
效果反而不如之前只是打乱的效果好
关注公众号:『AI学习星球』
回复:基于水色图像的水质评价 即可获取数据下载。
论文辅导或算法学习可以通过公众号滴滴我















 8936
8936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









