







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
项目介绍
在当今快节奏的生活中,早餐的选择变得至关重要。而肯德基(KFC)作为全球知名的快餐连锁品牌,其早餐系列丰富多样。想象一下,通过巧妙地爬取 KFC 早餐的相关信息,我们能够轻松地为自己搭配出一份营养均衡的早餐。
通过爬取到的丰富数据,通过多个因素可以分析出早餐主食的最多选择。
数据描述
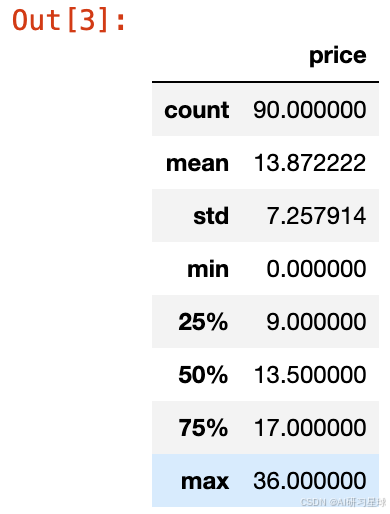
数据共90行,共4个字段。分别是:name、foods、price、img_url。
以下是表的部分数据:

分析数据
1、导入库
import pandas as pd
import jieba
import wordcloud
import imageio
from collections import Counter
from pyecharts import options as opts
from pyecharts.charts import Bar
导入数据,查看缺失值,异常值的处理
data = pd.read_csv('kfc.csv')
data.head()

data.describe()
data.info()
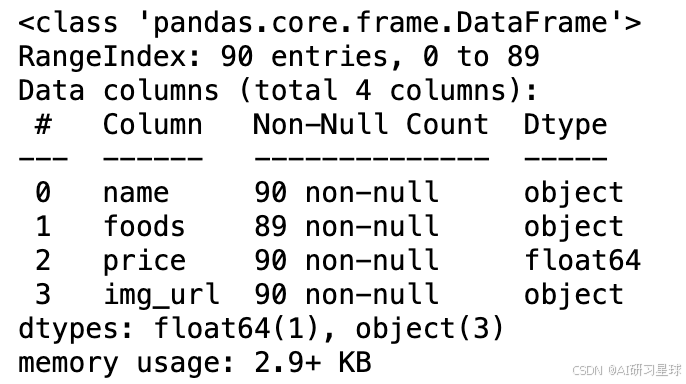
价格为 0.0 的使用平均数填充
# 价格为 0.0 的使用平均数填充
def f(p):
if p == 0.0:
p = 14
return p
else:
return p
data['price'] = data['price'].map(f)
删除缺失值的行
# 删除缺失值的行
data = data.dropna()
连接所有餐名,食物内容及通过jieba分词处理
# 连接所有餐名,食物内容
names = list(data['name'])
foods = list(data['foods'])
names.extend(foods)
names = ' '.join(names)
# 分词
ls = jieba.lcut(names)
txt = ' '.join(ls)

# 清洗掉与食物无关的词语
txt = txt.replace('产品','').replace('包装','').replace('包装实物','')\
.replace('br','').replace('随心换','').replace('实物','')\
.replace('主要','').replace('原料','').replace('指比菜','')\
.replace('单单','').replace('加价','').replace('换购','')\
.replace('总价','').replace('金额','').replace('为准','')\
.replace('早餐','').replace('饮品','')
2、主食营养分配
hamburger = {
'热量' : 250,
'脂肪' : 10,
'碳水化合物' : 20,
'蛋白质' : 10
}
rice_ball = {
'热量' : 200,
'脂肪' : 11,
'碳水化合物' : 21,
'蛋白质' : 6
}
porridge = {
'热量' : 50,
'脂肪' : 1.5,
'碳水化合物' : 8,
'蛋白质' : 2.5
}
chicken = {
'热量' : 255,
'脂肪' : 15,
'碳水化合物' : 10,
'蛋白质' : 21
}
x = ['汉堡','饭团','粥','鸡肉']
y1 = [250,200,50,255]
y2 = [10,11,1.5,15]
y3 = [20,21,8,10]
y4 = [10,6,2.5,21]
c = Bar()
c.add_xaxis(x)
c.add_yaxis("热量", y1, stack="stack1")
c.add_yaxis("脂肪", y2, stack="stack1")
c.add_yaxis("碳水化合物", y3, stack="stack1")
c.add_yaxis("蛋白质", y4, stack="stack1")
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title="主食营养分布"))
#c.render_notebook()
c.render_notebook()
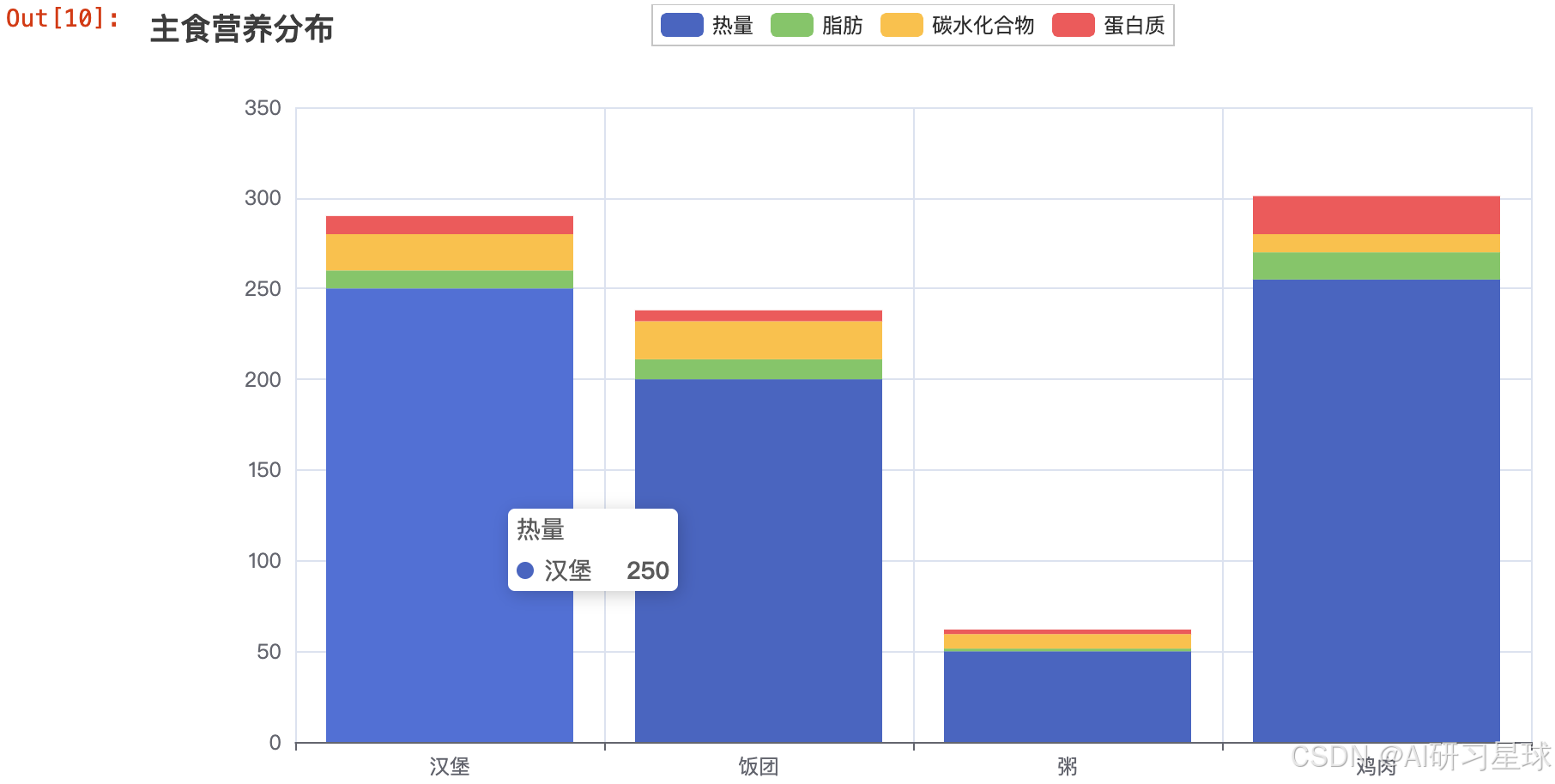
3、小吃营养分布
youtiao = {
'热量' : 388,
'脂肪' : 18,
'碳水化合物' : 51,
'蛋白质' : 7
}
chayedan = {
'热量' : 151,
'脂肪' : 6,
'碳水化合物' : 12,
'蛋白质' : 11
}
shubin = {
'热量' : 327,
'脂肪' : 22,
'碳水化合物' : 32,
'蛋白质' : 3
}
danta = {
'热量' : 255,
'脂肪' : 22,
'碳水化合物' : 38,
'蛋白质' : 7
}
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
list2 = [
{"value": 388, "percent": 388 / (388 + 18 + 51 + 7)},
{"value": 151, "percent": 151 / (151 + 6 + 12 + 11)},
{"value": 327, "percent": 327 / (327 + 22 + 32 + 3)},
{"value": 255, "percent": 255 / (22 + 38 + + 7 + 255)},
]
list3 = [
{"value": 18, "percent": 18 / (388 + 18 + 51 + 7)},
{"value": 6, "percent": 6 / (151 + 6 + 12 + 11)},
{"value": 22, "percent": 22 / (327 + 22 + 32 + 3)},
{"value": 22, "percent": 22 / (22 + 38 + 7 + 255)},
]
list4 = [
{"value": 51, "percent": 51 / (388 + 18 + 51 + 7)},
{"value": 12, "percent": 12 / (151 + 6 + 12 + 11)},
{"value": 32, "percent": 32 / (327 + 22 + 32 + 3)},
{"value": 38, "percent": 38 / (22 + 38 + 7 + 255)},
]
list5 = [
{"value": 7, "percent": 7 / (388 + 18 + 51 + 7)},
{"value": 11, "percent": 11 / (151 + 6 + 12 + 11)},
{"value": 3, "percent": 3 / (327 + 22 + 32 + 3)},
{"value": 7, "percent": 7 / (22 + 38 + 7 + 255)},
]
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
c.add_xaxis(['油条','茶叶蛋','薯饼','蛋挞'])
c.add_yaxis("热量", list2, stack="stack1", category_gap="50%")
c.add_yaxis("脂肪", list3, stack="stack1", category_gap="50%")
c.add_yaxis("碳水化合物", list4, stack="stack1", category_gap="50%")
c.add_yaxis("蛋白质", list5, stack="stack1", category_gap="50%")
c.set_series_opts(
label_opts=opts.LabelOpts(
position="right",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
c.render_notebook()
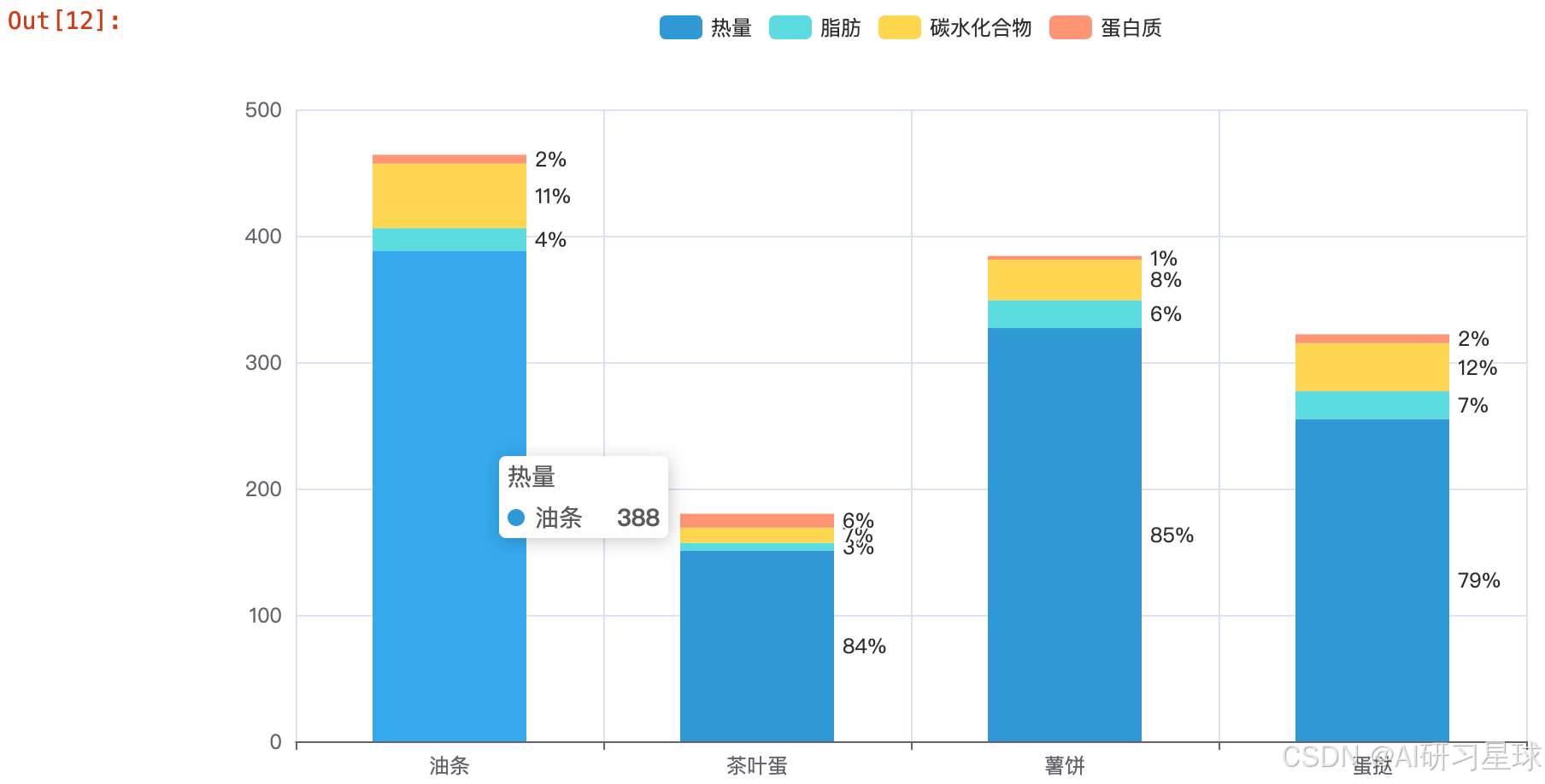
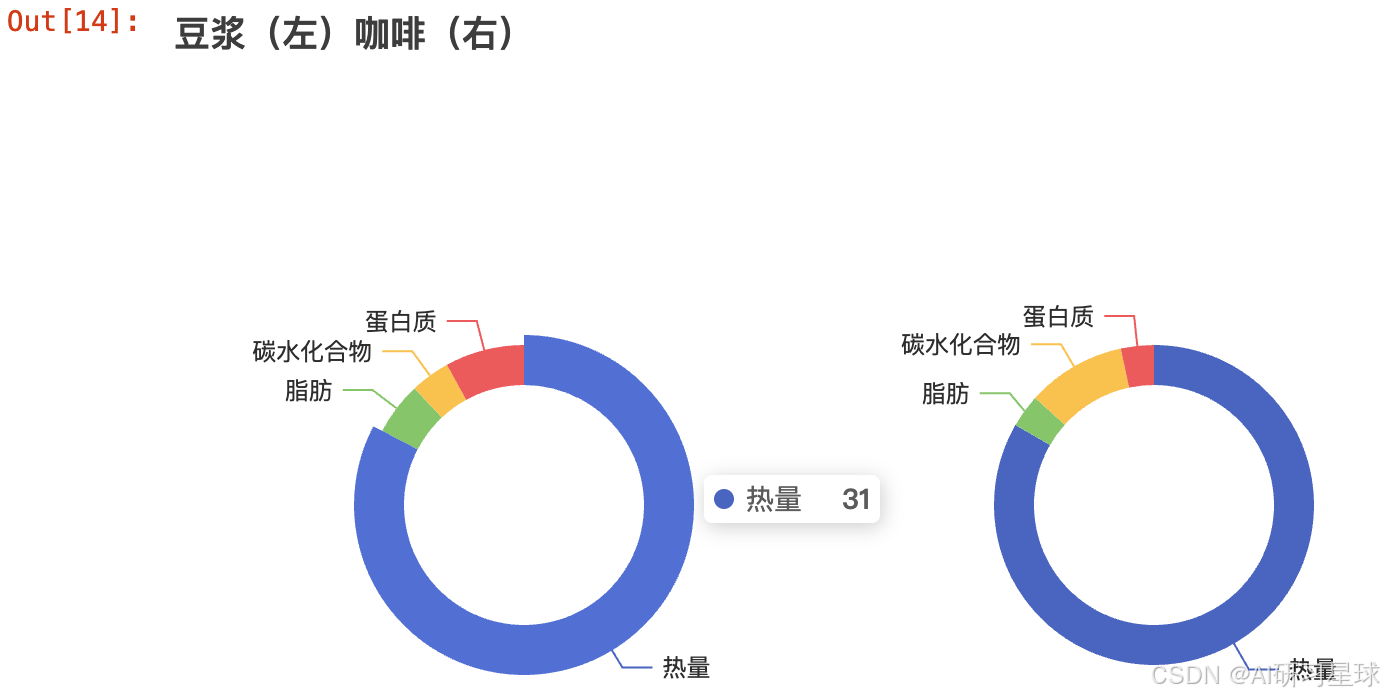
4、饮品
doujiang = {
'热量' : 31,
'脂肪' : 2,
'碳水化合物' : 1.5,
'蛋白质' : 3
}
coffe = {
'热量' : 100,
'脂肪' : 4,
'碳水化合物' : 12,
'蛋白质' : 4
}
from pyecharts import options as opts
from pyecharts.charts import Pie
c = Pie()
c.add(
"",
[list(z) for z in zip(["热量", "脂肪",'碳水化合物','蛋白质'],
[31,2,1.5, 3])],
center=["20%", "50%"],
radius=[60, 80],
)
c.add(
"",
[list(z) for z in zip(["热量", "脂肪",'碳水化合物','蛋白质'],
[100,4,12, 4])],
center=["55%", "50%"],
radius=[60, 80],
)
c.set_global_opts(
title_opts=opts.TitleOpts(title="豆浆(左)咖啡(右)"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="200%", pos_left="80%", orient="vertical"
),
)
c.render_notebook()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











