







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
一、项目背景
京东消费行为分析数据报告是基于京东平台所积累的大量消费数据,对消费者在京东平台上的消费行为进行系统研究、统计和分析后形成的报告。
二、数据说明
该数据共两个文件,分别是:df_shoft.csv、JD_labels.csv
df_shoft.csv:用户实际产生购买的订单数据(约包含订单号、客户id、消费物品的类别(大类、小类)与牌子、购物日期等)
| 列名 | 字段说明 |
|---|---|
| Unnamed | 未知 |
| customer_id | 用户的id,针对同一用户,id是一样的 |
| product_id | 商品的id,针对同一商品,id是一样的 |
| type | 某些种类的划分 |
| brand | 品牌名,如:小米、苹果、华为、格力等 |
| category | 细分种类,如:衣服大品类中 —— 外套,电子产品大品类中 —— 手机等 |
| shop_category | 大品类,如:衣服、电子产品、母婴产品等 |
| date | 订单时间 |
JD_labels.csv:通过日常操作收集到的用户偏好数据(约包含用户id,用户偏好的细分类别,浏览的购物平台的时间,活跃度等)
| 列名 | 字段说明 |
|---|---|
| Unnamed | 未知 |
| customer_id | 用户的id,针对同一用户,id是一样的 |
| time_browse | 用户浏览购物平台的时间点,如:上午,下午,晚上 |
| time_Order | 用户下单的时间点:如:上午,下午,晚上 |
| cate_most_browse | 当前用户查看最多的细分品类,如:衣服大品类中 —— 外套,电子产品大品类中 —— 手机等 |
| cate_most_Follow | 当前用户收藏最多的细分品类,如:衣服大品类中 —— 外套,电子产品大品类中 —— 手机等 |
| cate_most_SavedCart | 当前用户添加到购物车最多的细分品类,如:衣服大品类中 —— 外套,电子产品大品类中 —— 手机等 |
| cate_most_Order | 当前用户购买次数最多的细分品类,如:衣服大品类中 —— 外套,电子产品大品类中 —— 手机等 |
| month_buy | 当前用户月购买商品的次数 |
| month_Cart | 当前用户月添加商品到购物车的次数 |
| month_active | 当前用户月活次数 —— 可能是一月内登录上线次数/发言/进行某些操作的次数 |
| week_buy | 当前用户周购买商品的次数 |
| week_Cart | 当前用户周添加商品到购物车的次数 |
| week_active | 当前用户周活次数 —— 可能是一周内登录上线次数/发言/进行某些操作的次数 |
| last_browse | 当前用户最近一次浏览的时间间隔 |
| last_SavedCart | 当前用户最近一次添加商品到购物车的时间间隔 |
| last_Order | 当前用户最近一次下单的时间间隔 |
| interval_buy | 当前用户最近两次购买的间隔天数 |
| browse_not_buy | 当前用户浏览了商场后是否没有购买商品 |
| cart_not_buy | 当前用户添加在购物车的商品是否没有被购买 |
| buy_again | 当前用户是否重复购买了此细分品类 |
三、数据分析
1、数据导入
因为数据集已被选定,所以本次先从导入数据开始,去观察数据包含什么内容,我们可以通过这些数据获取什么样的内容。
# 数据工具导入
import pandas as pd
import numpy as np
from datetime import datetime,timedelta
# 可视化工具导入
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import *
from pyecharts.faker import Faker
# 数据导入
df_short = pd.read_csv('df_short.csv')
JD_labels = pd.read_csv('JD_labels.csv')
import warnings
warnings.filterwarnings('ignore')
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体 宋体
mpl.rcParams["axes.unicode_minus"] = False #字体更改后,会导致坐标轴中的部分字符无法正常显示,此时需要设置正常显示负号
a、订单数据的数据处理
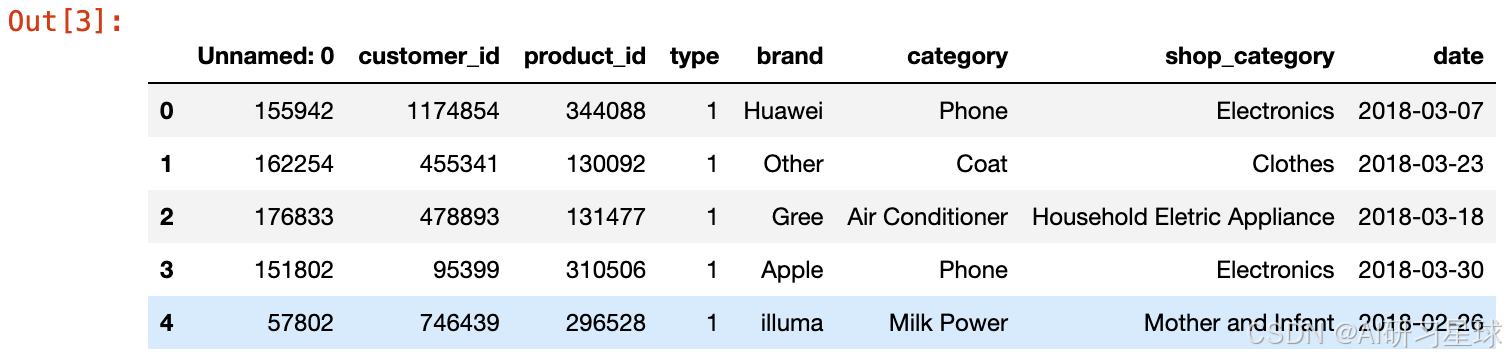
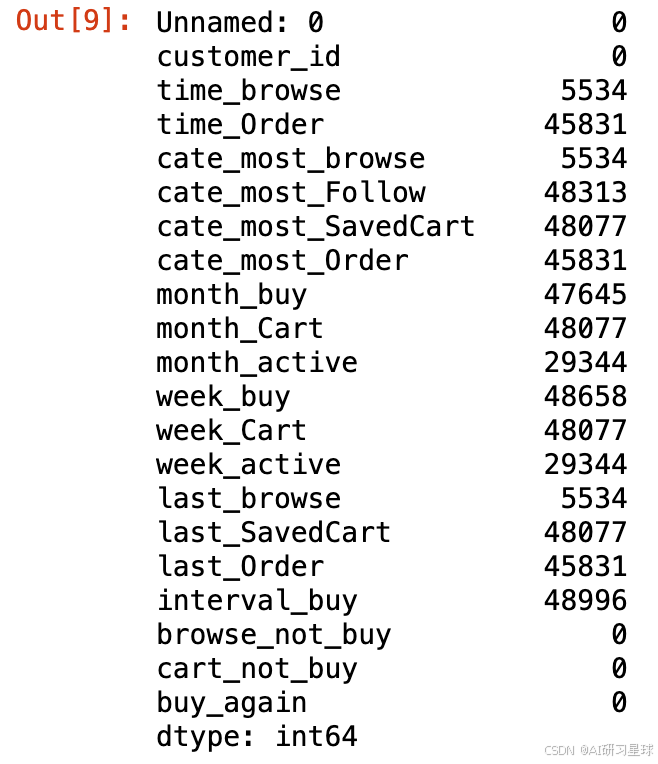
订单数据的部分数据展示
# 部分数据展示
df_short.head()
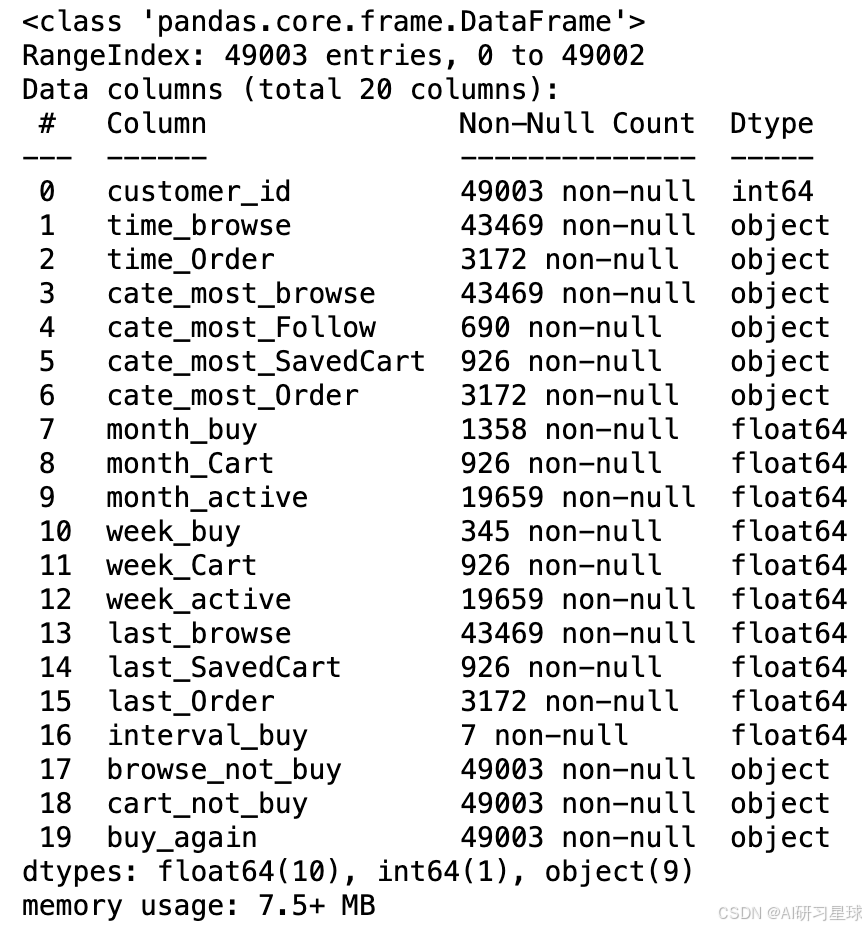
数据信息查看
# 数据信息查看
df_short.info()
b、用户偏好数据的数据处理
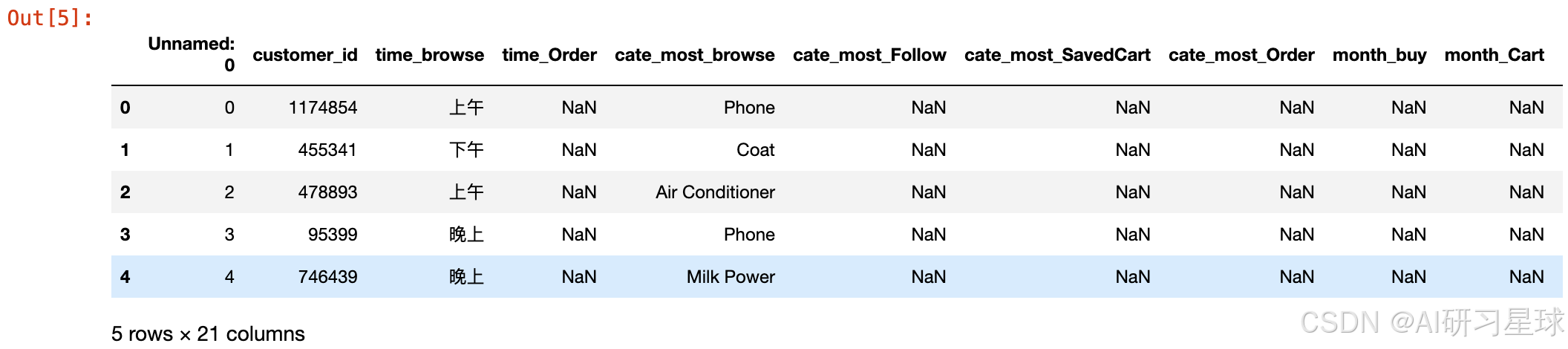
用户偏好数据的部分数据展示
# 部分数据展示
JD_labels.head()
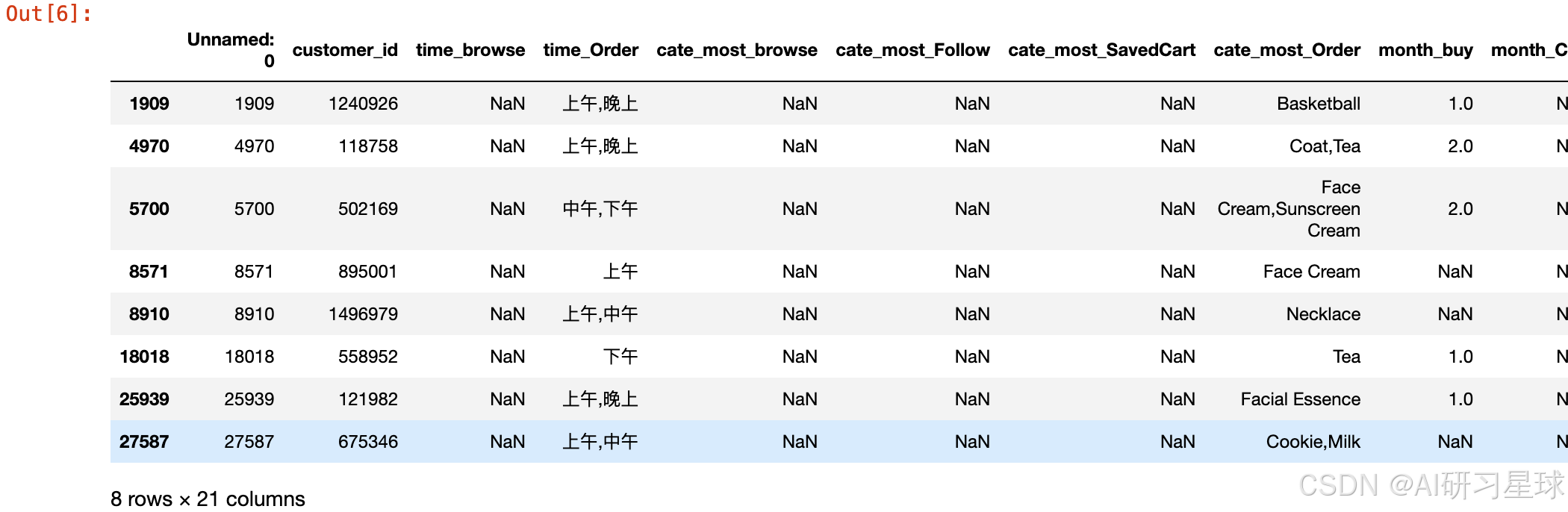
JD_labels.query('buy_again == "是"')
# 数据信息查看
JD_labels.info()
c、调研问题
针对第一个文件:用户实际产生购买的订单数据(约包含订单号、客户id、消费物品的类别(大类、小类)与牌子、购物日期等)
日常好奇问题:
- 在电商平台中,最受消费者喜爱的商品大类的分布,如:衣服、电子产品
- 针对最受喜欢的特定大类,其细分品类的分布,如:衣服中的 —— 大衣,电子产品中的 —— 手机
- 针对某些细分品类,最受消费者喜爱的品牌有哪些,销售量谁最高
时间序列
- 针对不同的日期,总体订单数的数量是怎么样的,变化是怎么样的
- 当从冬季跨越到春季之后(换季期间),衣服的购买数量是否会会远超其他的大类(什么比衣服还要重要?)
- 针对手机行业,不同日期中各大品牌的销量变化是怎么样的
日常好奇问题:
- 用户购买最多的商品是什么?
- 用户会愿意重复购买的商品有哪些?
- 用户浏览最多、收藏最多和添加到购物车最频繁的商品是什么?
- 用户浏览最多和添加到了购物车最多,但是没有购买的商品是什么?
时间序列
- 用户最喜欢在什么时间点浏览购物平台?
- 用户最喜欢在什么时间点购买商品?
- 用户活跃分布图(日、月)
2、数据处理
a、数据清洗
原始数据大概率会有缺失,我们需要进行一定的挑选、清洗,才能获取相对可用的数据
# 查看数据有无缺失 —— 没有数据缺失,第一个文件不需要数据清洗
df_short.isnull().sum()

# 查看数据有无缺失 —— 有数据缺失,但是因为数量太多,且大部分列有关联性,所以我们暂不处理
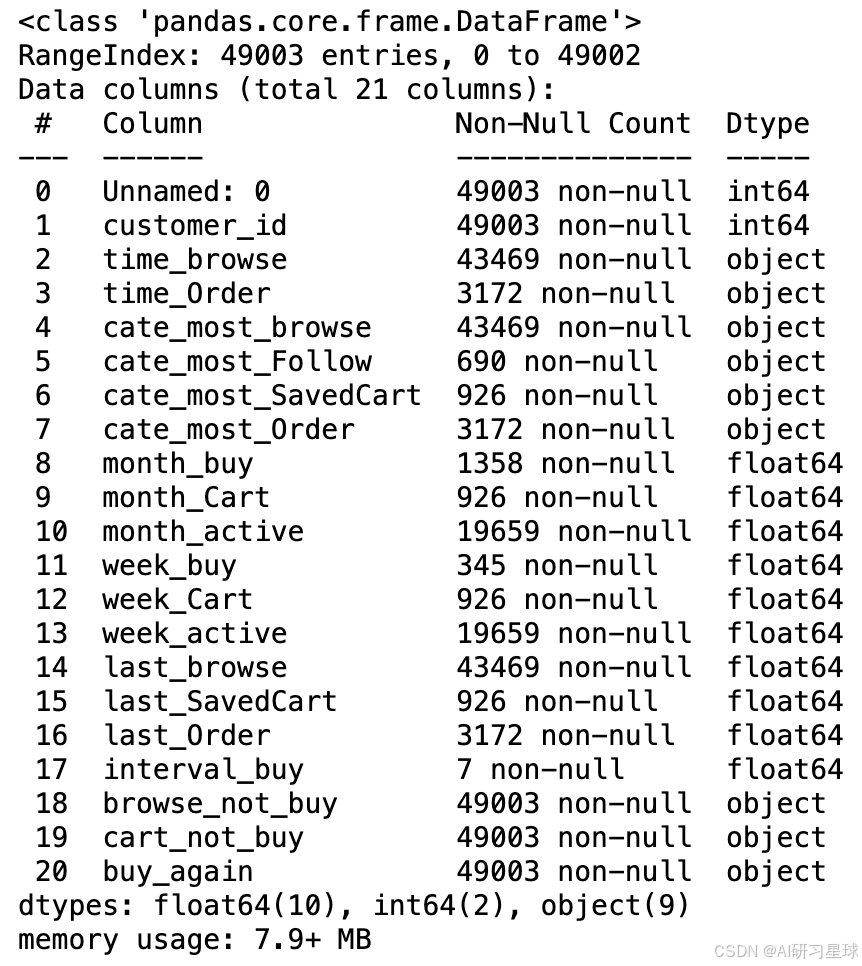
JD_labels.isnull().sum()
b、数据整理
经过清洗的相对可用数据并不一定能被直接运用于数据分析,我们需要把数据根据我们的需求再整理一遍,这样才能获取实际可用数据
# 第一个文件 —— Unnamed列不知道是什么内容,也与JD_labels无法对应上,删除。且时间可以转换为datetime。
df_short = df_short.drop('Unnamed: 0',axis=1)
df_short['date'] = df_short.date.apply(lambda x: pd.to_datetime(x))
df_short.head()
df_short.info()
# 第二个文件 —— Unnamed列不知道是什么内容,去除,其他的内容暂时保留
JD_labels = JD_labels.drop('Unnamed: 0',axis=1)
JD_labels.head()

JD_labels.info()
3、描述分析
借用可视化工具分析数据、展示数据、配合文字进行内容描述
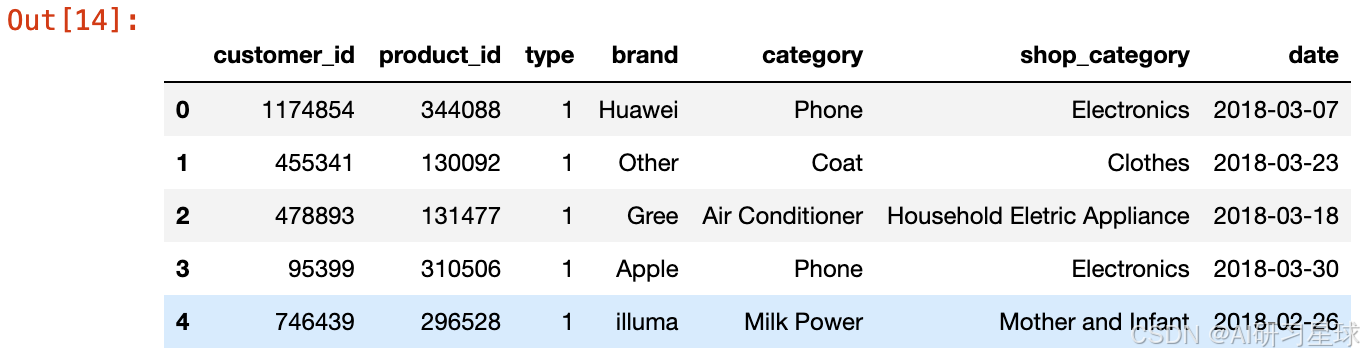
a、第一份文件:用户实际产生购买的订单数据
约包含订单号、客户id、消费物品的类别(大类、小类)与牌子、购物日期等
df_short.head()
Q1:在电商平台中,最受消费者喜爱的商品大类的分布
1. 了解目前商品大类有哪些
"""
1. 了解目前商品大类有哪些
2. 统计每一个大类的订单数量
3. 可视化展露 —— 饼图
"""
# 1. 了解目前商品大类有哪些
df_short.shop_category.unique()

2. 统计每一个大类的数量
# 2. 统计每一个大类的数量
shopCategoryCounts = df_short.shop_category.value_counts()
shopCategoryCounts

3. 可视化展露
# 3. 可视化展露
# 数据处理
data_pair_shopCategoryCounts = [list(i) for i in zip(shopCategoryCounts.keys(),shopCategoryCounts.values.tolist())]
# 可视化
shopCategoryCountsPie = (
Pie()
.add("商品大类",data_pair_shopCategoryCounts)
.set_global_opts(
title_opts=opts.TitleOpts(title="商品大类销售分布",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
shopCategoryCountsPie
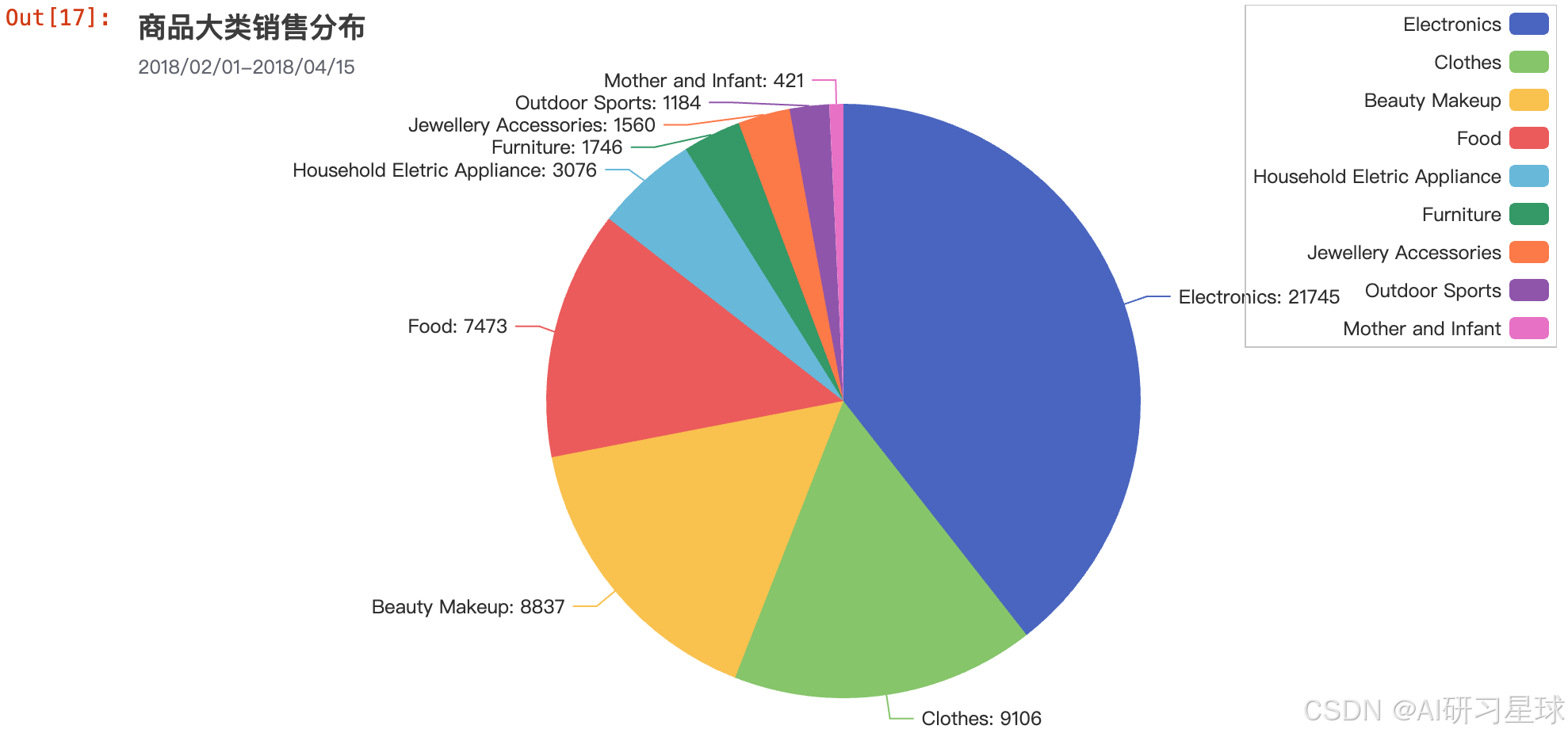
总结:
从此图中,我们可以看到电子产品的订单是最多的,约占1/3,依次递减的商品大类有:衣服、美妆产品、食物等.这四类的结合约占了总体的4/5
Q2:针对消费者最受喜欢的特定大类,其细分品类的分布
i、手机
1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Electronics)
"""
1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Electronics)
2. 看看最受欢迎的细分品类
3. 可视化 —— 饼图
"""
# 1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Electronics)
electronicsData = df_short[df_short['shop_category'] == 'Electronics']
electronicsData.category.unique()
array([‘Phone’, ‘Tablet’, ‘Xbox’, ‘Digital Camera’, ‘Notebook’, ‘Ipad’],dtype=object)
2. 看看最受欢迎的细分品类,并可视化
# 2. 看看最受欢迎的细分品类,并可视化
phoneCategoryCounts = electronicsData.category.value_counts()
phoneCategoryCounts

3. 可视化 —— 饼图
# 3. 可视化
# 数据处理
data_pair_categoryCounts = [list(i) for i in zip(phoneCategoryCounts.keys(),phoneCategoryCounts.values.tolist())]
# 可视化
phoneCategoryCountsPie = (
Pie()
.add("商品小类",data_pair_categoryCounts)
.set_global_opts(
title_opts=opts.TitleOpts(title="细分商品销售分布",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
phoneCategoryCountsPie
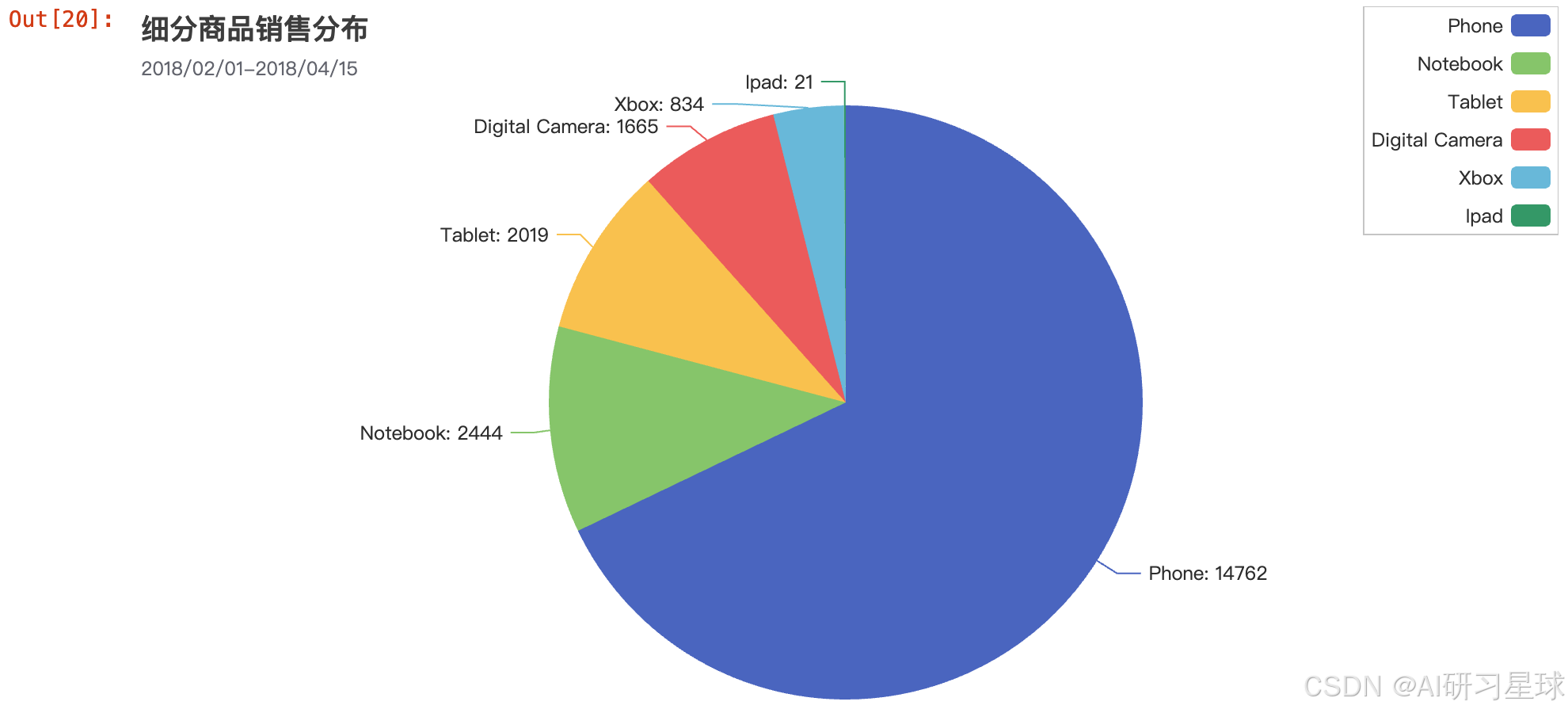
总结
从此图中,我们能明显看出手机在电子产品中的订单数是最多的,约占总体的2/3
ii、衣服
1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Clothes)
"""
1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Clothes)
2. 看看最受欢迎的细分品类
3. 可视化 —— 饼图
"""
# 1. 获取购买数量最多的大类数据,并了解有哪些细分品类(Clothes)
clothesData = df_short[df_short['shop_category'] == 'Clothes']
clothesData.category.unique()
array([‘Coat’, ‘T Shirt’, ‘Jeans’, ‘Sweater’, ‘Other’, ‘Skirt’, ‘Pants’], dtype=object)
2. 看看最受欢迎的细分品类
# 2. 看看最受欢迎的细分品类,并可视化
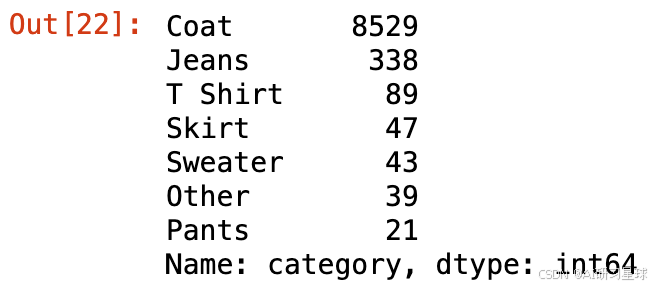
clothCategoryCounts = clothesData.category.value_counts()
clothCategoryCounts
可视化 —— 饼图
# 3. 可视化
# 数据处理
data_pair_clothesCategoryCounts = [list(i) for i in zip(clothCategoryCounts.keys(),clothCategoryCounts.values.tolist())]
# 可视化
clothesCategoryCountsPie = (
Pie()
.add("商品小类",data_pair_clothesCategoryCounts)
.set_global_opts(
title_opts=opts.TitleOpts(title="细分商品销售分布",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
clothesCategoryCountsPie
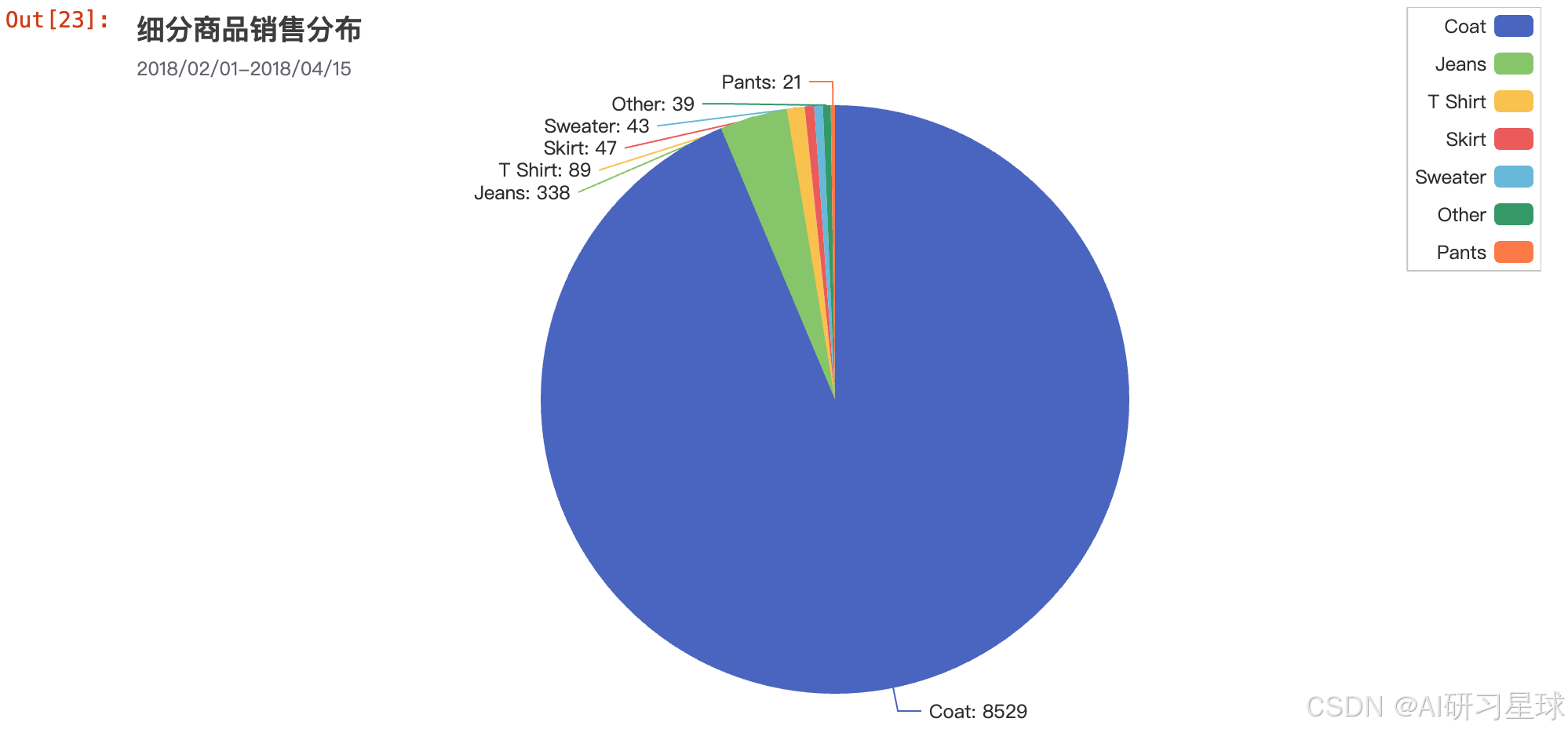
总结
从此图中,我们能明显看出外套在衣服中的订单数是最多的,绝大部分的订单都是外套,只有很小一部分留给其他衣服品类 —— 所以不需要做衣服种类的销售曲线图。
Q3:针对最受消费者喜爱细分品类,其品牌有哪些,销售量谁最高
1. 获取购买数量最多的细分品类数据,并了解有哪些品牌(Phone)
"""
1. 获取购买数量最多的细分品类数据,并了解有哪些品牌(Phone)
2. 查看各类品牌订单数量
3. 可视化 —— bar
"""
# 1. 获取购买数量最多的细分品类数据,并了解有哪些品牌(Phone) —— 提前审查过了,category为Phone的数量和本次筛选(category、shop_category)的数量一致,没有数据错误
phoneData = df_short.query('category == "Phone" and shop_category == "Electronics"')
phoneData.brand.unique()
array([‘Huawei’, ‘Apple’, ‘Other’, ‘Sumsung’, ‘Vivo’, ‘Redmi’, ‘OPPO’], dtype=object)
2. 查看各类品牌订单数量,并可视化
# 2. 查看各类品牌订单数量,并可视化
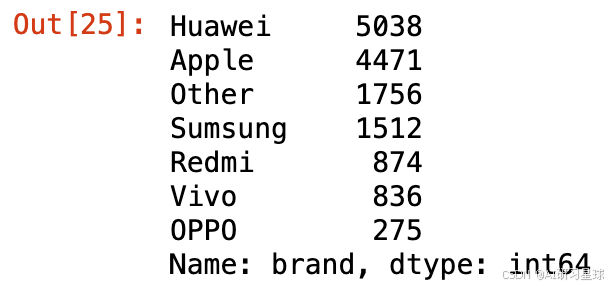
brandCounts = phoneData.brand.value_counts()
brandCounts
3. 可视化
# 3. 可视化
# 可视化
brandCountsBar = (
Bar()
.add_xaxis(brandCounts.keys().tolist())
.add_yaxis('Order_Num',brandCounts.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="各品牌手机订单数量",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
brandCountsBar
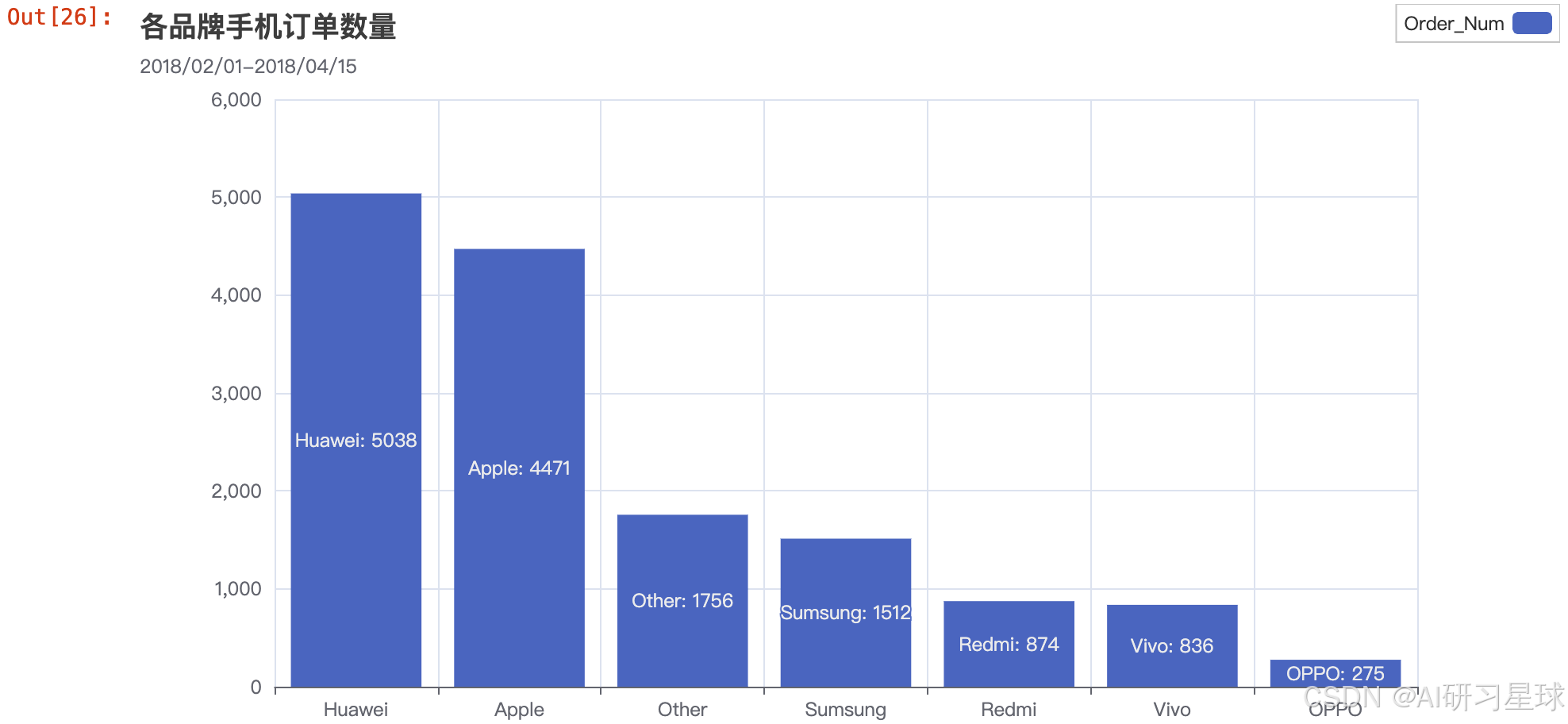
总结
从Bar图中我们可以看到华为手机于京东的订单是最多的,苹果其次
时间序列Q1:针对不同的日期,总体订单数的数量是怎么样的,变化是怎么样的?
"""
1. 以不同日期作为group,查看数据
2. 可视化
"""
# 1. 以不同日期作为group,查看数据
date_order_nums = df_short.date.value_counts().sort_index()
dates = np.array(date_order_nums.keys().astype(str))
date_order_nums.head()

# 2. 可视化
date_order_numsLine = (
Line()
.add_xaxis(dates)
.add_yaxis('Order_Num',date_order_nums.values.tolist(),is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="每天的订单数量",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.render_notebook()
)
date_order_numsLine
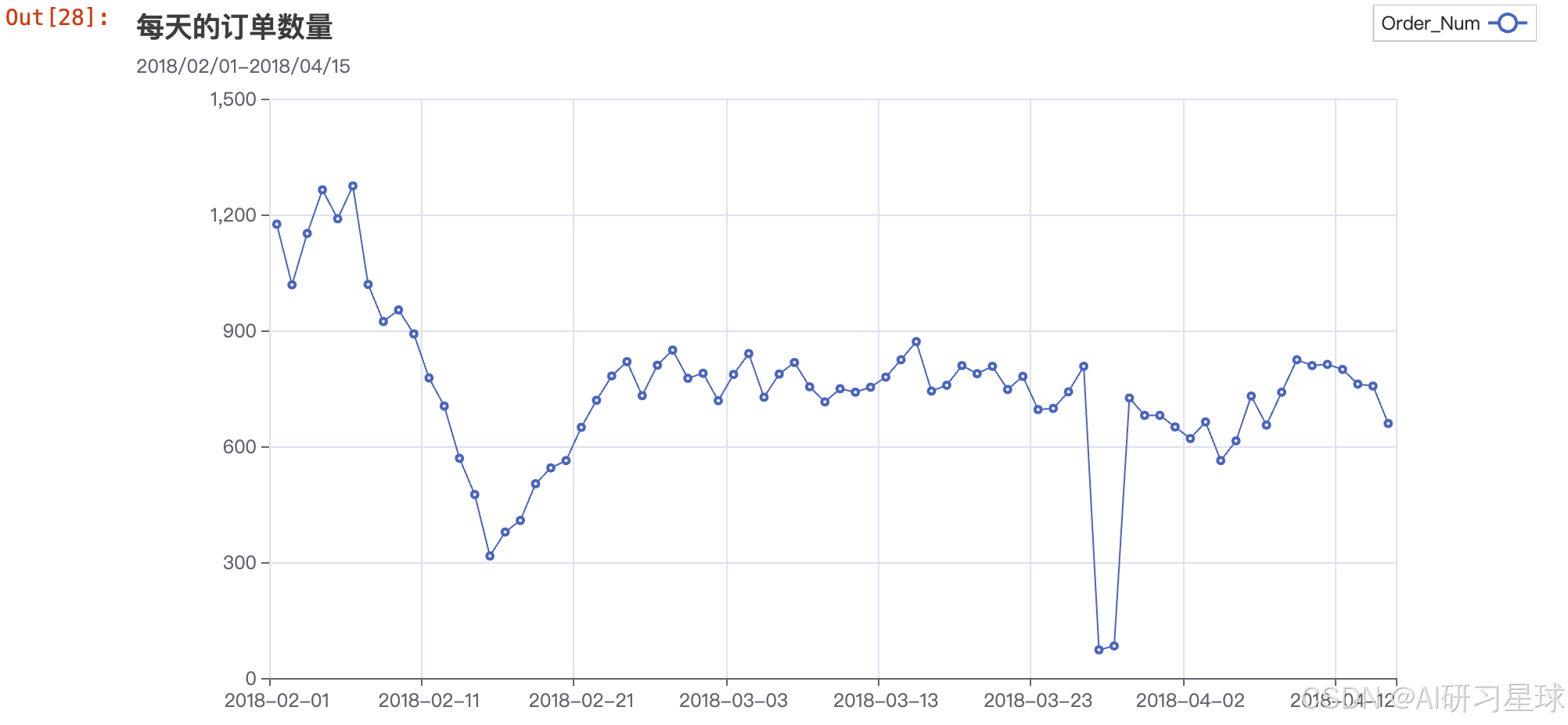
总结
- 此次拿到的数据显示,消费者在春节期间仍然有高购买欲望。订单数量在春节后有明显下降,之后逐渐趋于平稳(可能是因为促销活动的截止)。
- 在3月26后,订单数量有一个断崖式下降,目前原因不详 —— 怀疑可能与2018年3.26左右发生的事件相关,但是目前并没有查到原因
2018年3月26日:
- 早晨,武汉理工大学三年级研究生陶崇园疑因长期遭受导师压迫跳楼身亡[79]。
- 百度董事长李彦宏在中国发展高层论坛上表示“中国用户在个人隐私方面更加开放,一定程度上愿用隐私换方便和效率”,而其也会遵从法例指令等行事,引起舆论哗然指责其不能代表用家意见和无耻[80]。
- 外交部发布《中华人民共和国领事保护与协助工作条例(草案)》(征求意见稿),列明中国公民、法人和非法人组织获得领事保护与协助的,应当“自行承担”其食宿、交通、通讯、医疗、诉讼费用等。而坚持前往发布为高风险的国家或地区而需要协助的公民亦要自负费用。意见稿还提出要建立统一的“海外中国公民信息平台”,方便政府部门与驻外外交机构间的信息共享[81][82]。
时间序列Q2:换季期间,衣服的购买数量是否会会远超其他的大类
"""
1. 获取时间排列数据,查看所有大类的的每日销售情况
2. 可视化
"""
# 可视化
clothes_date_order_numsLine = Line()
clothes_date_order_numsLine.add_xaxis(dates)
clothes_date_order_numsLine.set_global_opts(
title_opts=opts.TitleOpts(title="不同大品类的商品每天的订单数量",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'))
for i in list(df_short.shop_category.unique()):
clothes_date_order_numsLine.add_yaxis(i,df_short[df_short['shop_category'] == i].date.value_counts().sort_index().values.tolist(),is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False))
clothes_date_order_numsLine.render_notebook()
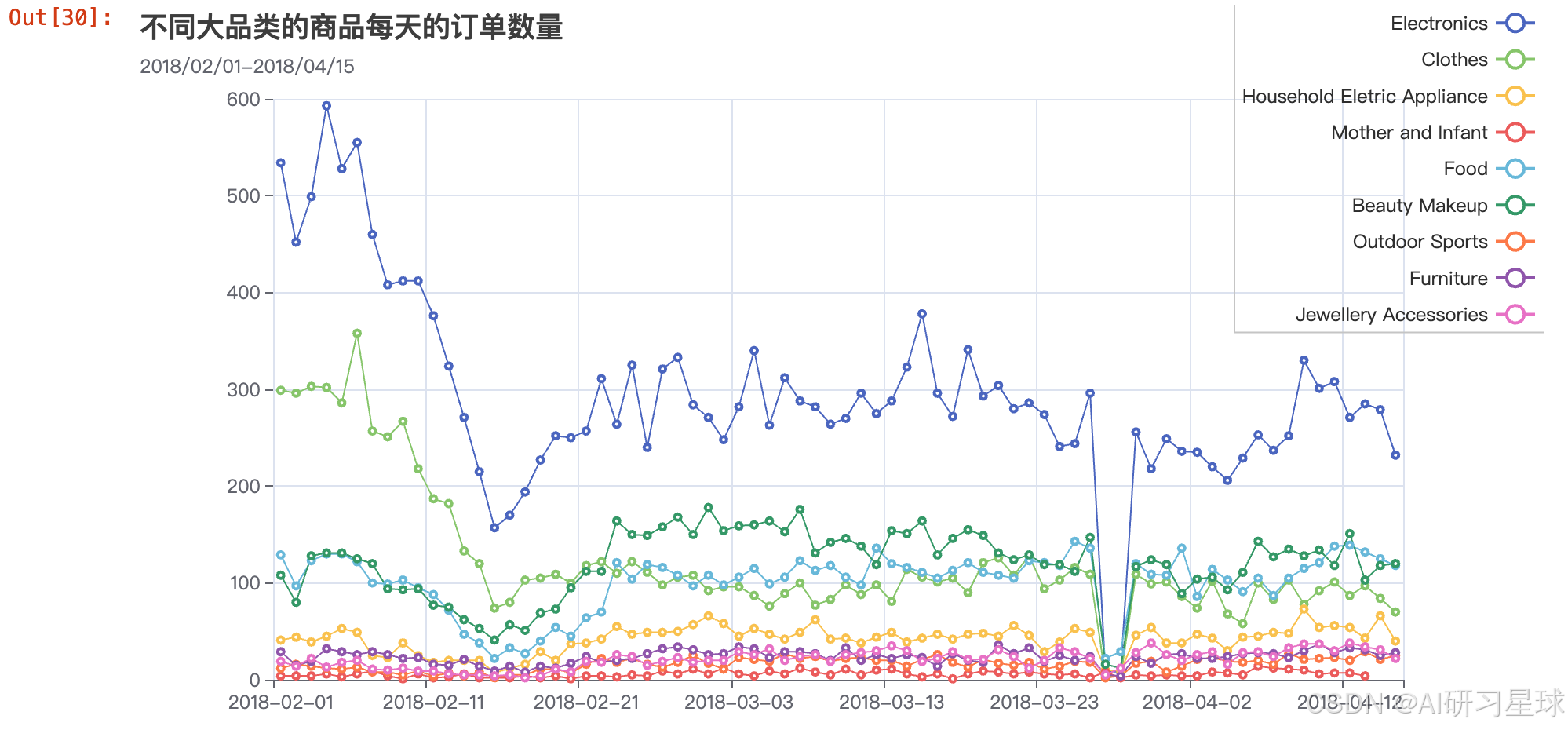
总结
我们能发现春节期间,衣服的订单数还是相对比较靠前的(排第二名),但是当春节一过之后,化妆品和食物的订单数会赶上来,逐渐与衣服的订单数持平。
时间序列Q3:针对手机行业,不同日期中各大品牌的销量变化是怎么样的
1. 利用之前Q3得到的phoneData,来分析手机不同品牌的销量变化
"""
1. 利用之前Q3得到的phoneData,来分析手机不同品牌的销量变化
2. 可视化
"""
phoneData.head()
2. 可视化
# 可视化
phone_brand_date_order_numsLine = Line()
phone_brand_date_order_numsLine.add_xaxis(dates)
phone_brand_date_order_numsLine.set_global_opts(
title_opts=opts.TitleOpts(title="不同手机品牌每天的订单数量",subtitle='2018/02/01-2018/04/15'),
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'))
for i in list(phoneData.brand.unique()):
phone_brand_date_order_numsLine.add_yaxis(i,phoneData[phoneData['brand'] == i].date.value_counts().sort_index().values.tolist(),is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False))
phone_brand_date_order_numsLine.render_notebook()
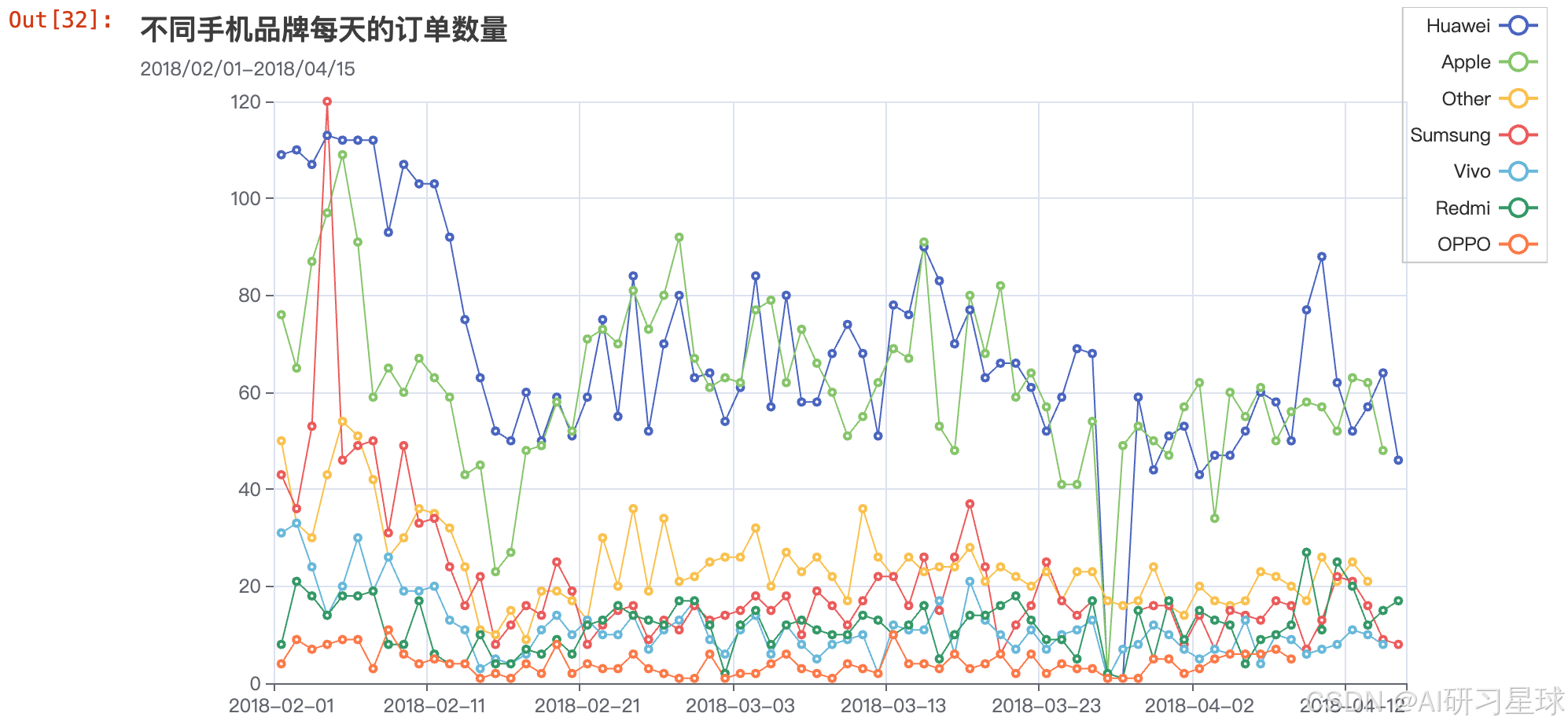
总结
- 华为和苹果的订单数量仍然是保持一定水准的,代表他们两家的粉丝可能相对较多,且这两家品牌的质量可能还不错。
- 三星的订单数量在春节期间曾上升到某日销量第一名,但是后续持续下跌,可以看看细节为什么
b、第二份文件:通过日常操作收集到的用户偏好数据
约包含用户id,用户偏好的细分类别,浏览的购物平台的时间,活跃度等
JD_labels.head()

# 代表了里面的每一个用户都是独立的
JD_labels.customer_id.nunique() == JD_labels.shape[0]
True
Q1、用户购买最多的商品是什么?
1. 获取用户实际购买数据
"""
1. 获取用户实际购买数据,查看商品购买数量 —— 因为购买商品太多了,所以只选购买次数大于100的
2. 可视化
"""
# 1. 获取用户实际购买数据(只要time_Order不为空,那就是下单了),查看商品购买数量(cate_most_Order)
actual_buy_data = JD_labels[JD_labels.time_Order.isnull() == False]
actual_buy_data_counts = actual_buy_data.cate_most_Order.value_counts()
actual_buy_data_counts = actual_buy_data_counts[actual_buy_data_counts > 100]
actual_buy_data_counts

2. 可视化
# 2. 可视化
# 可视化
actual_buy_data_countsBar = Bar()
actual_buy_data_countsBar.add_xaxis(actual_buy_data_counts.keys().tolist())
actual_buy_data_countsBar.add_yaxis("订单数",actual_buy_data_counts.values.tolist())
actual_buy_data_countsBar.set_global_opts(
title_opts=opts.TitleOpts(title="用户购买相对较多的商品"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"interval":"0"}),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
actual_buy_data_countsBar.render_notebook()
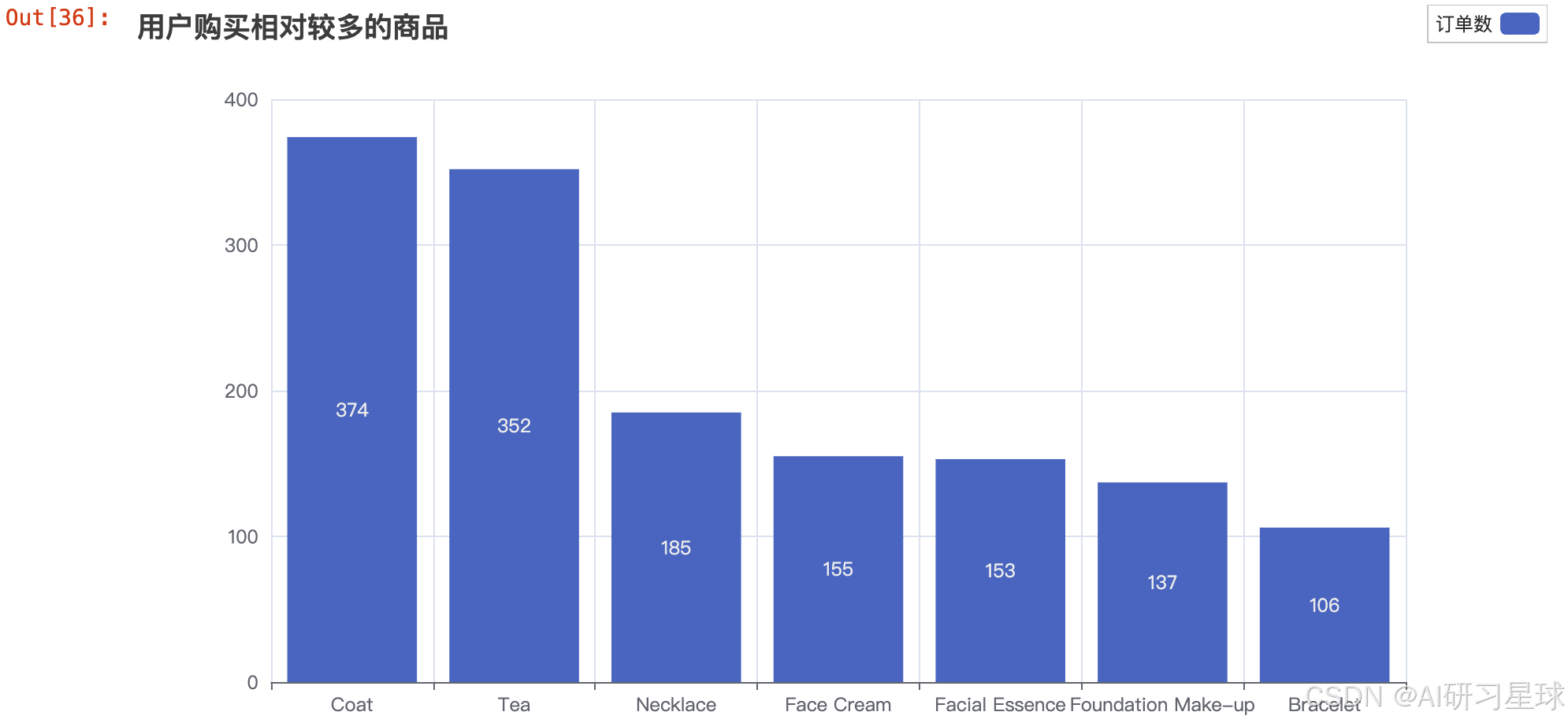
总结
用户购买最多的是大衣和茶
Q2:用户会愿意重复购买的商品有哪些?
JD_labels.cate_most_SavedCart
1. 看看buy_again属性有什么内容,挑选出重复购买的数据
"""
1. 看看buy_again属性有什么内容,挑选出重复购买的数据
2. 查看重复购买的数据,重新整理
"""
# 1. 看看buy_again属性有什么内容,挑选出重复购买的数据
JD_labels.buy_again.unique()
array([‘未购买’, ‘否’, ‘是’], dtype=object)
2. 查看重复购买的数据,重新整理
# 2. 查看重复购买的数据,重新整理
buy_again_data = JD_labels.query('buy_again == "是"')
buy_again_items = buy_again_data.cate_most_Order.value_counts()
buy_again_items

Q3:用户浏览最多、收藏最多和添加到购物车最频繁的商品是什么?
原本要算用户浏览最多和添加到了购物车最多,但是没有购买的商品是什么。但是后面发现因为后两列的否太多,应该是数据不确定的
"""
1. 分别获取用户浏览最多和用户收藏最多和收藏最多的商品,获取前五个都是什么
"""
# 1. 分别获取用户浏览最多和用户收藏最多和收藏最多的商品,获取前五个都是什么
JD_labels.cate_most_browse.value_counts().head(5)

总结:
用户浏览最多的五个单品: 手机、大衣、茶、笔记本电脑、平板电脑
JD_labels.cate_most_Follow.value_counts().head(5)
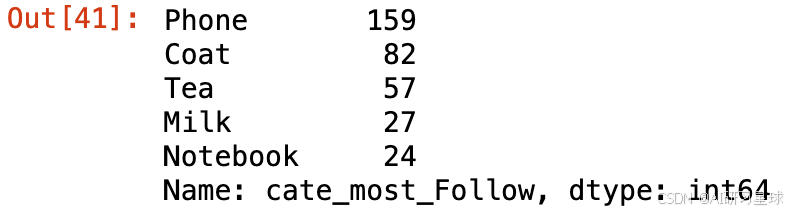
总结:
用户收藏最多的五个单品: 手机、大衣、茶、牛奶、笔记本电脑
JD_labels.cate_most_SavedCart.value_counts().head(5)
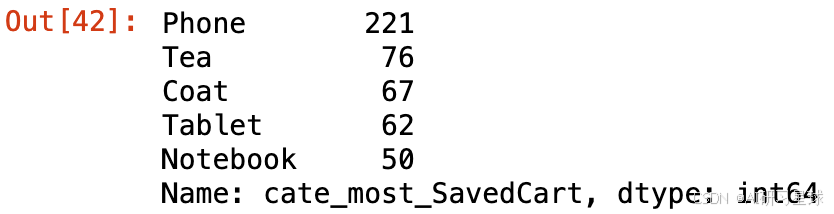
总结:
用户浏览最多的五个单品: 手机、茶、大衣、平板电脑、笔记本电脑
时间序列Q1:用户最喜欢在什么时间点浏览购物平台?
"""
1. 获取用户浏览时间数据
2. 可视化
"""
# 1. 获取用户浏览时间数据 —— 因为时间过多,所以我们选择最优先的五个时间点
user_browse_most_counts = JD_labels.time_browse.value_counts().head()
# 2. 可视化
# 可视化
user_browse_most_Bar = Bar()
user_browse_most_Bar.add_xaxis(user_browse_most_counts.keys().tolist())
user_browse_most_Bar.add_yaxis("浏览时间",user_browse_most_counts.values.tolist())
user_browse_most_Bar.set_global_opts(
title_opts=opts.TitleOpts(title="用户最喜欢浏览平台的时间段"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"interval":"0"}),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
user_browse_most_Bar.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
user_browse_most_Bar.render_notebook()

时间序列Q2:用户最喜欢在什么时间点购买商品?
"""
1. 获取用户购买时间数据
2. 可视化
"""
# 1. 获取用户购买时间数据 —— 因为时间过多,所以我们选择最优先的五个时间点
user_order_most_counts = JD_labels.time_Order.value_counts().head()
user_order_most_counts

# 2. 可视化
# 可视化
user_order_most_Bar = Bar()
user_order_most_Bar.add_xaxis(user_order_most_counts.keys().tolist())
user_order_most_Bar.add_yaxis("下单时间",user_order_most_counts.values.tolist())
user_order_most_Bar.set_global_opts(
title_opts=opts.TitleOpts(title="用户最喜欢下单的时间段"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"interval":"0"}),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
user_order_most_Bar.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
user_order_most_Bar.render_notebook()
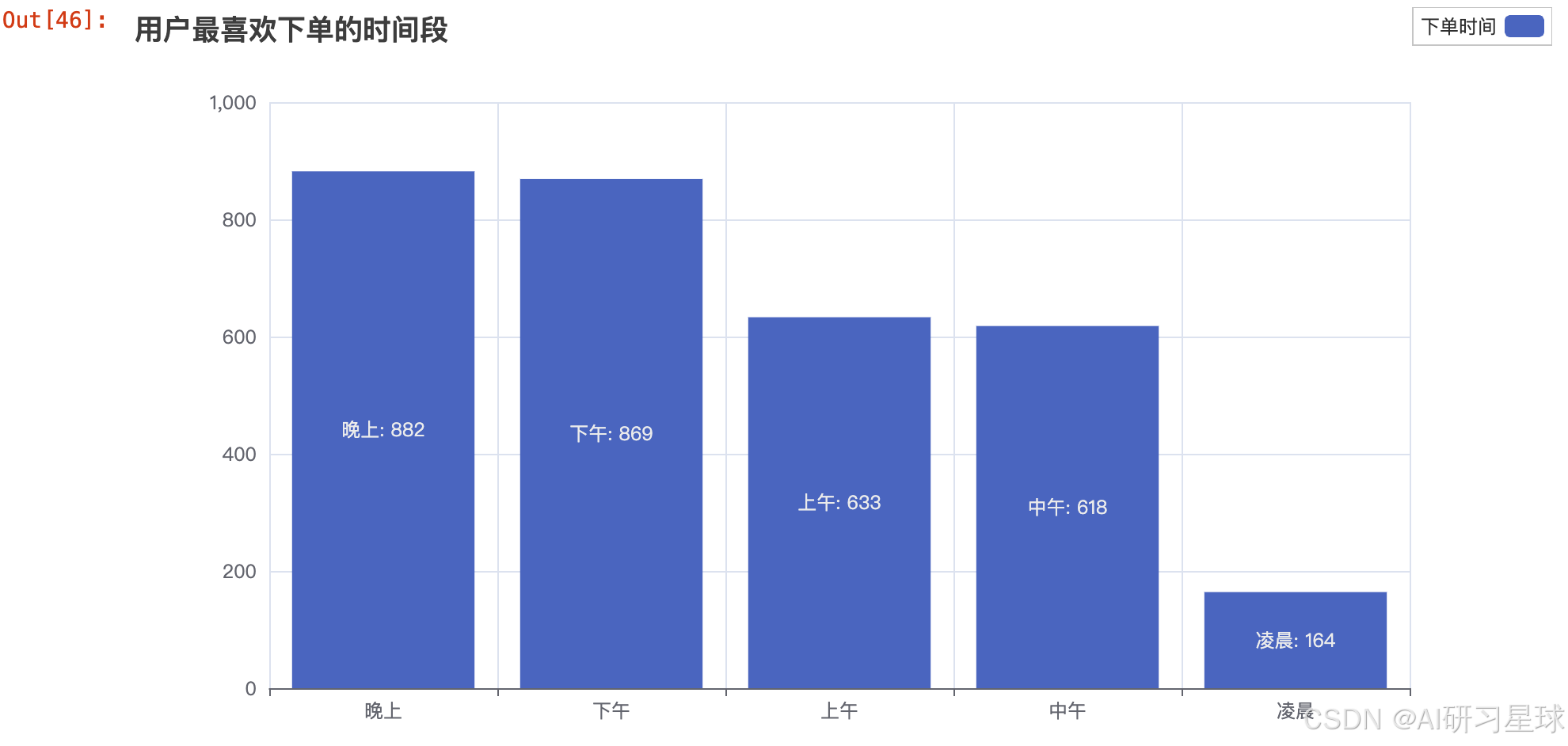
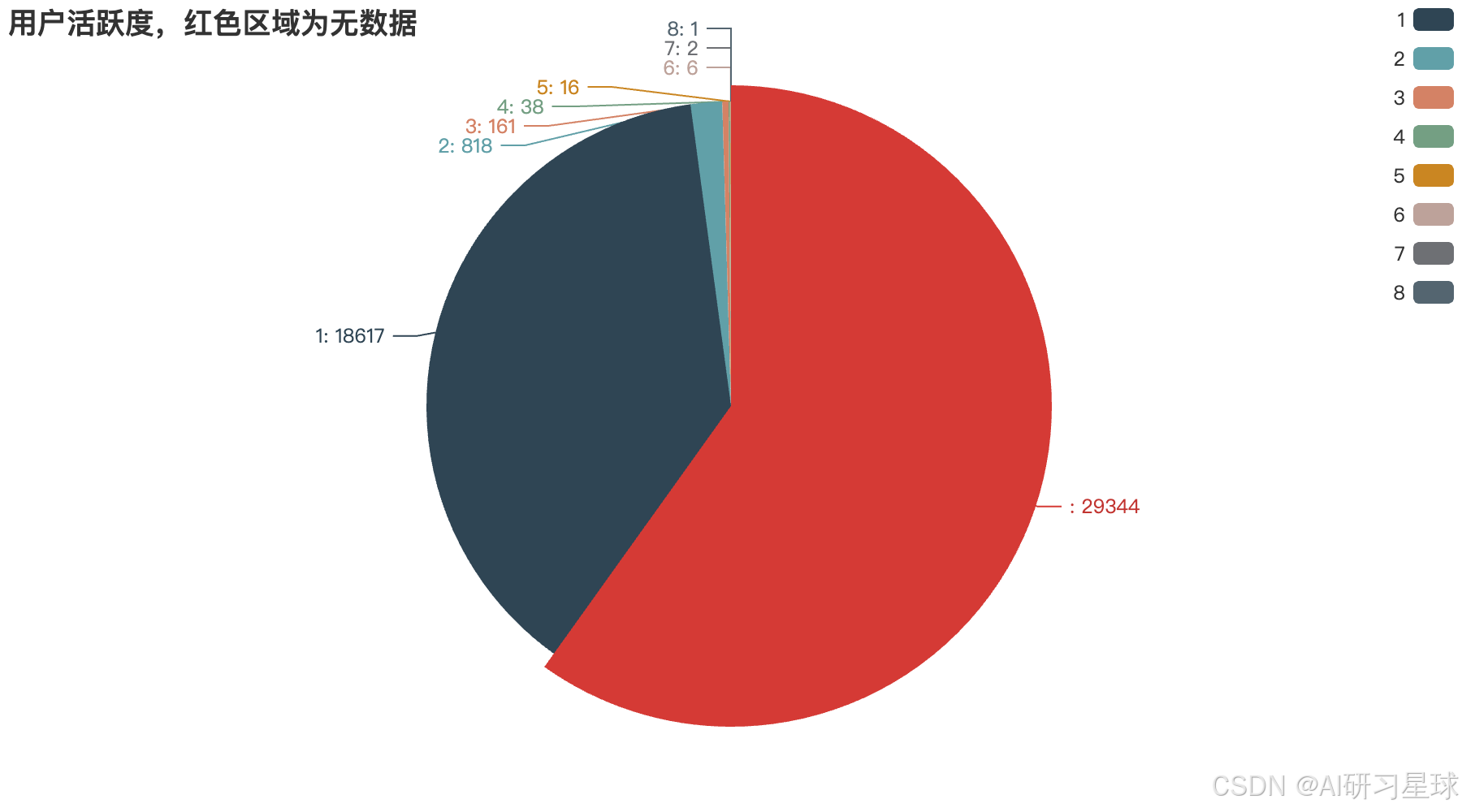
时间序列Q3:用户活跃分布图(日、月)
"""
1. 获取用户周活次数和用户月活数据
2. 可视化
"""
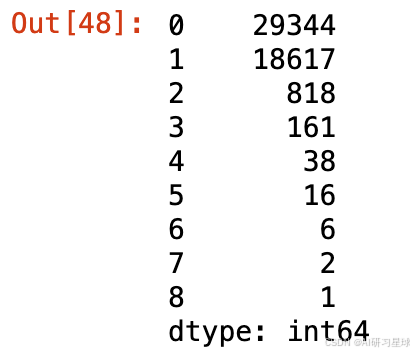
# 1. 获取用户周活次数和用户月活数据
user_active_inactive_week_data = JD_labels.week_active.value_counts()
user_active_inactive_month_data = JD_labels.month_active.value_counts()
user_inactive_week_num = JD_labels[JD_labels.week_active.isnull()].shape[0] # 和下面一样
user_inactive_month_num = JD_labels[JD_labels.month_active.isnull()].shape[0] # 和上面一样
# 因为数据一样,所以周活和月活只需要一个图就可以了
user_activity_week_data = pd.Series({'0.0':user_inactive_week_num})
user_activity_week_data = user_activity_week_data.append(user_active_inactive_week_data,ignore_index=True)
user_activity_month_data = pd.Series({'0.0':user_inactive_month_num})
user_activity_month_data = user_activity_month_data.append(user_active_inactive_month_data,ignore_index=True)
user_activity_week_data
# type(user_activity_week_data.values.tolist()[0])
# 2. 可视化
# 可视化
user_activity_Pie = (
Pie()
.add("活跃度",[list(i) for i in zip(user_activity_week_data.keys(),user_activity_week_data.values.tolist() )])
.set_global_opts(
title_opts=opts.TitleOpts(title="用户活跃度,红色区域为无数据"),
tooltip_opts=opts.TooltipOpts(trigger="axis",is_show=True,trigger_on="click",axis_pointer_type="cross",border_color="#FF0000",border_width=5),
legend_opts=opts.LegendOpts(type_="plain",is_show=True,orient="vertical",pos_left='right'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
user_activity_Pie
四、洞察结论: 观察可视化结构,得出阶段性总结
针对第一个文件:用户实际产生购买的订单数据(约包含订单号、客户id、消费物品的类别(大类、小类)与牌子、购物日期等)
a、日常好奇问题
1、在电商平台中,最受消费者喜爱的商品大类的分布,如:衣服、电子产品
- 答案:从图中,我们可以看到电子产品的订单是最多的,约占1/3,依次递减的商品大类有:衣服、美妆产品、食物等.这四类的结合约占了总体的4/5
2、针对最受喜欢的特定大类,其细分品类的分布,如:衣服中的 —— 大衣,电子产品中的 —— 手机
- 答案(1:电子产品大类中):从图中,我们能明显看出手机在电子产品中的订单数是最多的,约占总体的2/3
- 答案(2:衣服大类中):从图中,我们能明显看出外套在衣服中的订单数是最多的,绝大部分的订单都是外套,只有很小一部分留给其他衣服品类 —— 所以不需要做衣服种类的销售曲线图
3、针对某些细分品类,最受消费者喜爱的品牌有哪些,销售量谁最高
- 答案:从Bar图中我们可以看到华为手机于京东的订单是最多的,苹果其次
b、时间序列
1、针对不同的日期,总体订单数的数量是怎么样的,变化是怎么样的
- 此次拿到的数据显示,消费者在春节期间仍然有高购买欲望。订单数量在春节后有明显下降,之后逐渐趋于平稳(可能是因为促销活动的截止)。
- 在3月26后,订单数量有一个断崖式下降,目前原因不详 —— 怀疑可能与2018年3.26左右发生的事件相关,但是目前并没有查到原因
2、当从冬季跨越到春季之后(换季期间),衣服的购买数量是否会会远超其他的大类(什么比衣服还要重要?)
- 我们能发现春节期间,衣服的订单数还是相对比较靠前的(排第二名),但是当春节一过之后,化妆品和食物的订单数会赶上来,逐渐与衣服的订单数持平
3、针对手机行业,不同日期中各大品牌的销量变化是怎么样的
- 华为和苹果的订单数量仍然是保持一定水准的,代表他们两家的粉丝可能相对较多,且这两家品牌的质量可能还不错。
- 三星的订单数量在春节期间曾上升到某日销量第一名,但是后续持续下跌,可以看看细节为什么
针对第二个文件:通过日常操作收集到的用户偏好数据(约包含用户id,用户偏好的细分类别,浏览的购物平台的时间,活跃度等)
c、日常好奇问题
1、用户购买最多的商品是什么?
- 用户购买最多的是大衣和茶(具体看表格)
2、用户会愿意重复购买的商品有哪些?
- 项链、茶、面霜、篮球、防晒霜、大衣、茶、牛奶等(具体看表格)
3、用户浏览最多、收藏最多和添加到购物车最频繁的商品是什么?
- 用户浏览最多的五个单品: 手机、大衣、茶、笔记本电脑、平板电脑
- 用户收藏最多的五个单品: 手机、大衣、茶、牛奶、笔记本电脑
- 用户浏览最多的五个单品: 手机、茶、大衣、平板电脑、笔记本电脑
d、时间序列
1、用户最喜欢在什么时间点浏览购物平台?
- 从图中来看是晚上和下午最多
2、用户最喜欢在什么时间点购买商品?
- 从图中来看是晚上和下午最多
3. 用户活跃分布图(日、月)
- 无数据(可能不活跃)的用户占了一半以上,值得细究
e、行业洞察
- 用户对电子产品和衣服的消费热情是很大的,合理与这两块大区与各大品牌做联合促销,有一定可能性加强刺激消费(尤其针对手机厂商和主营大衣的厂商)
- 用户于春节中的消费购买力是很高的,但是节后的订单额度就会有一定下降,如果我们可以在春节后也有一定的铺垫活动,说不定可以重新刺激消费
- 用户一般来说喜欢在下午和晚上这个时间点进行电商平台的浏览和购买,广告的铺展在这块可以加大力度,预想的收成会比在其他时间段更好(同时这部分时间可以向卖家拿更高广告费,或者做为激励奖励)
- 如果无数据代表用户不活跃,则有一半以上的人数是没有怎么登陆过电商平台的,针对这部分人群可以额外研究(合理利用老顾客返回等营销),重新获取更多流量和收益 —— 因为电商平台的获利的根本就是客流量,客单价,留客时长。
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我



















 7744
7744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











