






 本文针对小目标检测的挑战,提出了一种结合上下文信息和注意力机制的深度学习方法。通过融合多尺度特征获取上下文信息,利用注意力模块聚焦目标,提升了小目标检测的准确性。实验表明,该方法在SSD基础上显著提高了小目标检测的精度,特别是在PASCALVOC2007测试集上取得了78.1%的map。
本文针对小目标检测的挑战,提出了一种结合上下文信息和注意力机制的深度学习方法。通过融合多尺度特征获取上下文信息,利用注意力模块聚焦目标,提升了小目标检测的准确性。实验表明,该方法在SSD基础上显著提高了小目标检测的精度,特别是在PASCALVOC2007测试集上取得了78.1%的map。
原论文下载:https://arxiv.org/pdf/1912.06319.pdf
摘要
在各种环境中应用目标检测算法有很多局限性。特别是小目标的检测仍然是一个挑战,因为它们的分辨率低,信息有限。为了提高小目标检测的准确性,我们提出了一种基于上下文的目标检测方法。该方法通过融合多尺度特征,利用不同层次的附加特征作为上下文信息。我们还提出了一种基于注意力机制的目标检测方法,该方法能够聚焦于图像中的目标,并且能够包含目标层的上下文信息。实验结果表明,该方法比传统的SSD在检测小目标上的精度更高。此外,在PASCAL VOC2007测试集上,对于300×300的输入,我们的map达到了78.1%。

一、介绍
目标检测是计算机视觉中的关键问题之一,其目标是找到目标的bounding box,并在给定图像的情况下对目标进行分类。近年来,在深度学习技术的引领下,目标检测的精度和速度都有了很大的提高:Faster R-CNN达到了73.2%的map,YOLO v2达到了76.8%的MAP,SSD达到了77.5%的map。然而,在检测小物体方面仍然存在重大挑战。例如,SSD在检测小目标上map只能达到20.7%。图1展示了SSD无法检测到小目标时的失败案例。所以在小目标检测方面还有很大的提升空间。
小目标检测的难度很大,因为它的分辨率低,像素有限。例如,如果只看图2上的对象,人类甚至很难识别这些对象。然而,如果考虑到物体所处的天空环境,那么目标将可以被识别为鸟类,因此,我们认为解决这一问题的关键在于如何将上下文作为额外信息来帮助检测小物体。
在本文中,我们提出使用上下文信息来解决小目标检测这一具有挑战性的问题。首先,为了提供足够的关于小对象的信息,我们从小对象的周围像素中提取上下文信息,利用更高层次的抽象特征作为对象的上下文。我们通过连接小目标的特征和上下文的特征增加了小目标的信息,以便检测器能够更好地检测目标。其次,为了聚焦于小目标,我们在浅层特征图使用了一种注意力机制。这也有助于减少背景中不必要的浅层特征信息。在我们的实验中,我们选择了SSD作为我们的基线。然而,这个想法可以推广到其他网络。为了评估我们所提出的模型的性能 ,我们在PASCAL VOC2007和VOC2012进行训练,并与VOC2007上的基线方法和最新方法进行了比较。

二、相关工作
1、基于深度学习的目标检测
深度学习技术的进步极大地提高了目标检测的准确率,基于深度学习目标检测的第一次尝试是R-CNN。R-CNN使用卷积神经网络(CNN)处理通过选择性搜索生成的区域建议(region proposals)。然而,由于每个建议的区域都顺序地通过CNN,因此对于实时应用来说,R-CNN的速度就太慢了。Fast R-CNN比R-CNN更快,因为它对所有区域建议只执行了一次特征提取阶段。但R-CNN 和Fast RCNN这两项工作仍然使用单独的阶段进行区域建议,这也就成为了Faster R-CNN的主要攻击点。Faster R-CNN将区域建议阶段和分类阶段合并为一个阶段,因此它也被称为端到端的学习。YOLO和SSD显示出足以进行实时目标检测的高性能,甚至加速了目标检测技术的发展。然而,它们对于小物体仍然没有表现出良好的性能。
2 、小目标检测
最近,关于小目标检测,人们提出了一些想法。Liu 等人通过减小大目标数量来增加小目标数量,以此来克服数据不足的问题,除了数据增强的方法之外,还有一些努力是在不增加数据集的情况下增加所需信息。DSSD将反卷积技术应用于SSD的所有特征图来得到分辨率更高的特征图。然而,由于所有的特征图都要使用反卷积模块,所有DSSD模型具有增加模型复杂度和降低速度的局限性。R-SSD通过pooling 和deconvolution技术融合了不同尺度的feature map,与DSSD相比,获得了更高的精度和速度。李等人使用生成对抗网络(GAN),将低分辨率的特征作为GAN的输入来生成高分辨率的特征。
3 、视觉注意网络
深度学习中的注意力机制可以广义地理解为只关注解决特定任务的部分输入,而不是看它的全部输入。因此,注意力机制与我们看到或听到的东西非常相似。Xu 等人使用视觉注意力来生成图像字幕。为了生成与图像相对应的字幕,他们使用了LSTM,LSTM提取给定图像的相关部分。Sharm等人应用注意力机制来识别视频中的动作。Wang 等人通过堆叠残差注意力模块,提高了ImageNet数据集的分类性能。
三、方法
本节将讨论基线网络SSD,然后介绍我们建议用于提高小对象检测能力的组件。首先,SSD引入特征融合来获取上下文信息,我们命名该网络为F-SSD。第二,带有注意力模块的SSD使网络能够专注于重要部分,这里我们命名此网络为A-SSD。第三,我们将特征融合和注意力模块结合起来,称为FA-SSD。
3.1 Single Shot Multibox Detector (SSD)
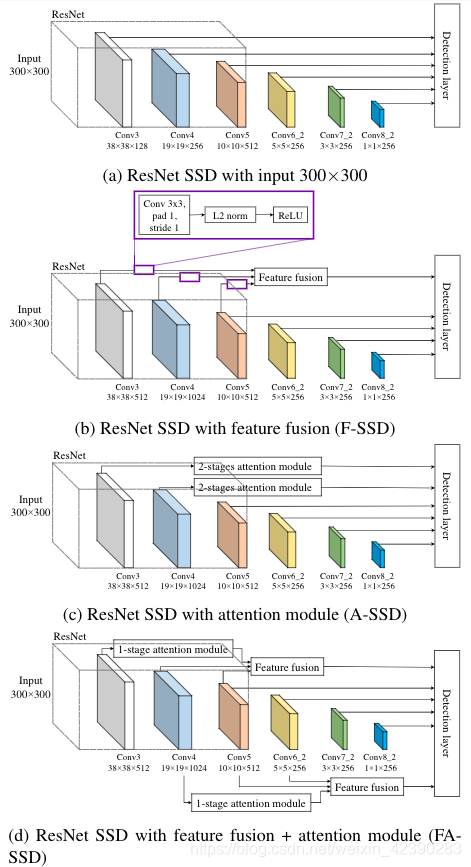
在这一部分,我们回顾了SSD算法,我们知道我们要提高对小物体的检测能力。像YOLO一样,SSD也是one-stage检测算法,其目标是提高检测速度,同时还通过处理不同层次的特征图来提高不同尺度下的检测效果,如图3a所示。其思想是利用浅层特征图的高分辨率来检测较小的目标,而利用分辨率较低的较深层特征来检测较大的目标。
SSD以VGG16作为backbone,并且通过额外增加层来获取不同分辨率的特征图,如图3a所示。根据每个特征图,通过一个附加的卷积层来匹配输出通道,网络预测包含边界框回归和对象分类的输出。
然而,SSD在小目标上的检测性能仍然很低,在VOC 2007数据集上为20.7%,因此,SSD算法还有很多需要改进的地方。我们认为造成小目标检测性能较低主要有两个原因,首先是缺乏上下文信息来检测小目标。此外,用于小目标检测的特征是从缺乏语义信息的浅层特征中提取的。我们的目标是通过添加特征融合来改进SSD,以解决这两个问题。此外,为了进一步改进SSD算法,我们增加了注意力机制,使网络只关注重要的部分。
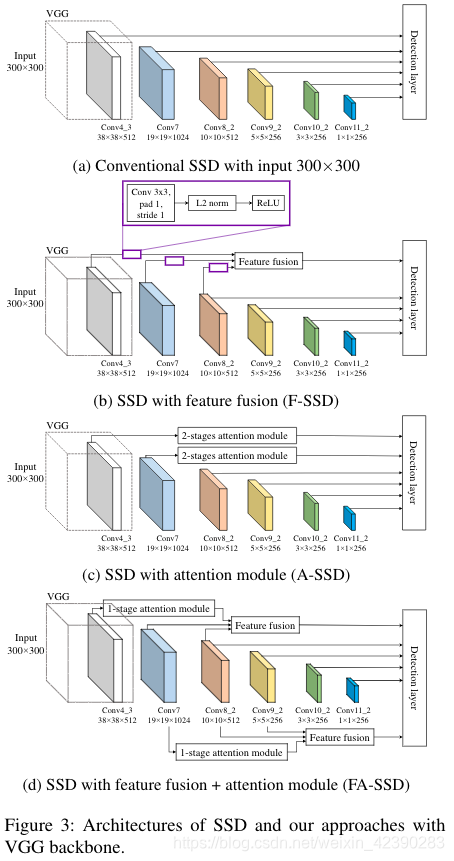
3.2 F-SSD: SSD with context by feature fusion
为了在我们想要检测目标的给定特征图(target feature map)上添加上下文信息,我们将其与含有上下文特征的深层特征图进行融合。例如在SSD中,给定我们来自conv4_3的目标特征图,我们的上下文特征层来自conv7_2、conv8_2两层(如图3b所示)。虽然我们的特征融合可以推广到任何目标特征及其任何更高的特征。然而,这些特征图具有不同的size,因此我们提出了如图4所示的融合方法。
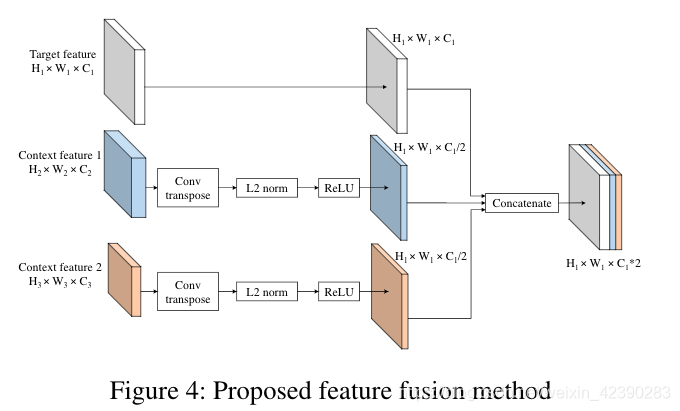
在通过concat融合之前,我们通过对含有上下文信息的feature map进行deconvolution操作,使其与目标特征图(target feature map)拥有相同的size,我们将上下文特征通道数设置为目标特征的一半,因此上下文信息量不会超过目标特征本身。对于F-SSD,我们还在不改变target feature map大小和通道数的情况下,在目标特征(target feature map)上增加了一个额外的卷积层。此外,在连接特征图之前,归一化步骤也非常重要,因为不同层中的每个特征值都有不同的尺度。因此,我们对每一层进行批量归一化和RELU操作。最后,通过对目标特征图和上下文特征图进行concat操作,实现了目标特征和上下文特征的融合。
3.3 A-SSD: SSD with attention module
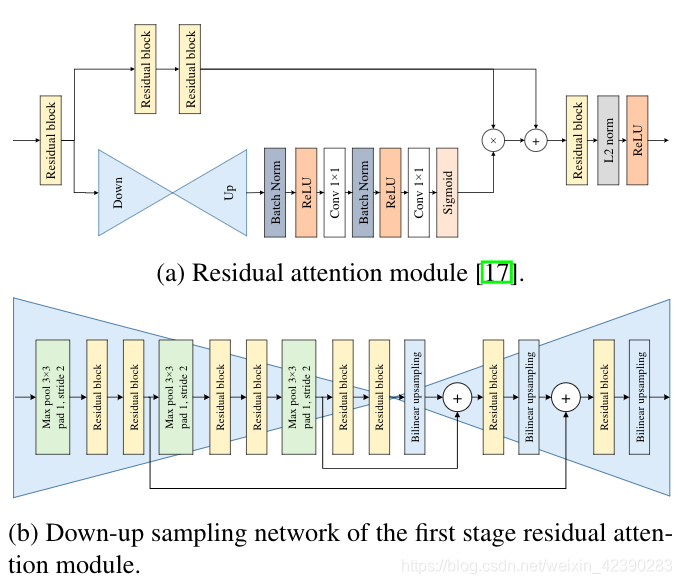
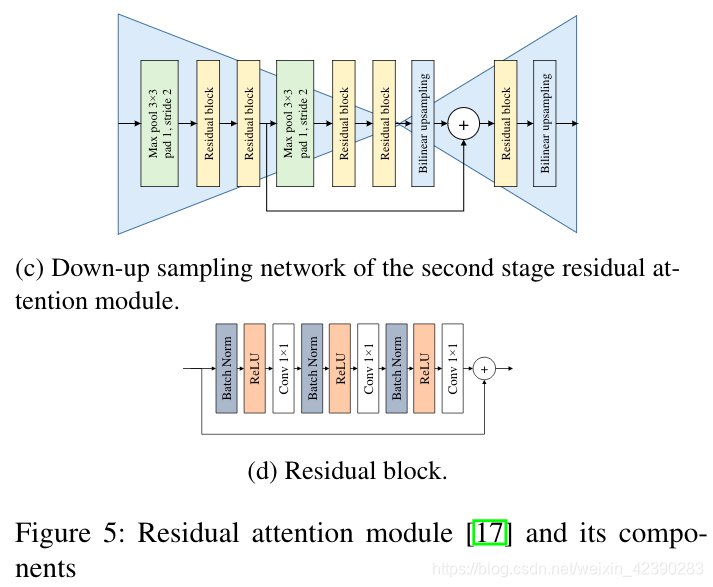
视觉注意机制允许聚焦于图像的一部分,而不是看到整个区域。受到Wang 等人提出的残差注意力模块成功的启发,我们也将残差注意力机制应用到了目标检测中。对于我们的A-SSD(如图3c所示),虽然残差注意力模块可以推广到任何一层,但我们只分别在conv4_3和conv7之后放置了two-stage的残差注意力模块。每一个残差注意力阶段都可以在图5中描述,它包含了trunk分支和mask分支。trunk分支有两个residual block,每个block中包含3个卷积层(如图5d所示)。mask分支通过利用残差连接执行下采样和上采样来输出注意图(图5b为第一阶段,图5c为第二阶段),然后利用sigmod函数激活,残差连接可以保持下采样阶段的特征。然后将来自mask分支的注意图与trunk分支的输出相乘,生成已参与的特征。最后,将参与网络的特征经过residual模块、L2标准化和ReLU。
3.4 FA-SSD: Combining feature fusion and atten-tion in SSD
我们提出了一种新的方法,该方法连接了章节3.2和3.3中提到的特征,它可以考虑来自目标层和不同层的上下文信息。与F-SSD相比,我们不是在目标特征图上执行一个卷积层,而是设置了一个one-stage注意力模块,如图3d所示,特征融合方式如图4。
四、实验
4.1 实验环境
除非特别指明,否则我们使用VGG16作为backbone,输入大小为300x300的SSD。对于FA-SSD,我们将特征融合方法应用于SSD的conv4_3和conv7。我们以conv4_3为target feature,conv7和conv8_2为上下文特征,以conv7为target feature,conv8_2和conv9_2为上下文特征。在较低的两层特征图应用注意力机制检测小目标。注意模块的输出与target feature的大小相等。我们在PASCAL VOC2007和VOC2012的训练验证集上训练我们的网络,第一个80000次迭代的学习率为10^−3,然后对于100000和120000次迭代学习率降为10^-4和10^-5,batch size为16。所有测试结果均是在VOC2007的测试集上测试得到,我们采用COCO标准对目标大小分类,小目标面积小于32*32,大目标面积大于96*96。我们使用PyTorch和Titan XP进行训练和测试。
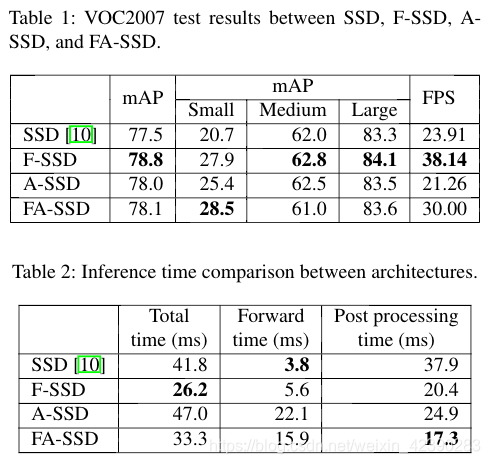
4.2 消融研究
为了测试特征融合和注意力机制对SSD的重要性,我们比较了SSD、F-SSD、A-SSD和FA-SSD的性能。Table 1显示所有F-SSD、A-SSD都优于SSD,这意味着特征融合和注意力机制都有助于baseline的提高。虽然特征融合和注意力机制相结合的FA-SSD并没有表现出比F-SSD更好的整体性能,但是FA-SSD在小目标检测方面表现出了最好的性能和显著的提升。
4.3 运行时间
Table 1中结果的一个有趣之处在于,组件越多,速度并不总是越慢。这促使我们更加详细的了解了推理时间。检测中的推理时间分为网络推理和包含非极大值抑制(NMS)的后处理两部分。根据Table 2,虽然SSD的forward 时间最快,但它在后处理过程中最慢,因此总体上仍然比F-SSD和A-SSD慢。
4.4 运行结果
图7显示了SSD和FA-SSD之间的定性比较,其中当FA-SSD成功时,SSD无法检测到小对象。

4.5 Attention visualization
为了对注意力机制有更好的理解,我们可视化了来自FA-SSD的注意力 mask。该注意力 mask是在图5a中sigmoid函数之后进行的。注意力mask上有许多通道,在conv4_3上有512个通道,conv7上有1024个通道。每个通道都关注不同的东西,既有对象也有上下文。在图8中,我们对于注意力mask的一些样本进行了可视化。

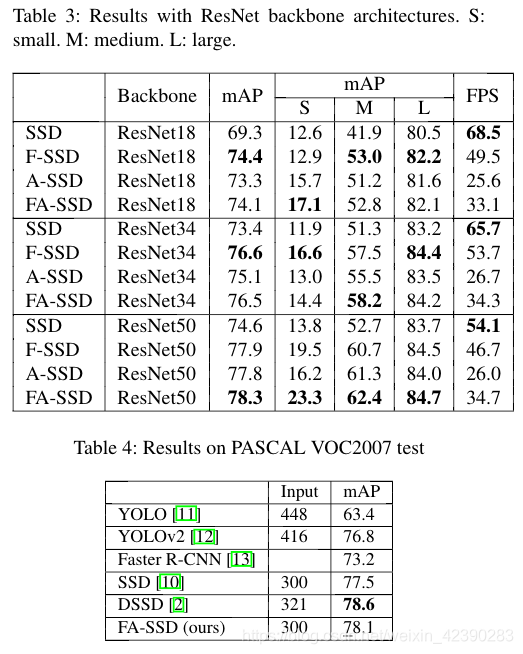
4.6 以ResNet为backbone
为了了解SSD不同backbone的通用性,我们对ResNet结构进行了实验,特别是ResNet18、ResNet34和ResNet50。为了使特征图大小与以VGG16为backbone的原始SSD的特征图大小相同,我们从layer2的结果(如图6a)中提取特征,然后F-SSD(图6b)、A-SSD(图6c)和FA-SSD(图6d)只需遵循以VGG16为backbone的版本。如表3所示,除了以ResNet34为backbone的版本在小目标上的性能不是最好之外,其他一切都跟随表1中以VGG16为backbone的版本的趋势。
4.7 VOC2007测试结果
为了与其他作品进行比较,我们在表4中进行了比较。所有比较的方法都用VOC2007 的trainval和VOC2012 的trainval数据集进行训练。虽然与DSSD相比我们的性能更低,但我们的方法运行的FPS为30,而DSSD为12 。
五、结论
在本文中,为了提高小目标检测的准确率,我们提出了给SSD增加上下文感知信息的方法。该方法通过融合多尺度特征获取不同层次上的上下文信息,通过注意机制获取目标层上的上下文信息。实验表明,与传统的SSD相比,目标检测的准确率有了很大的提高,特别是对小目标的检测精度有了很大的提高。

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









