







 本文深入探讨了迁移学习的概念及其在解决大数据与标注、计算能力、模型适配及特定应用需求矛盾中的作用。迁移学习广泛应用于计算机视觉、自然语言处理等多个领域。Transformer模型,由Google在2017年提出,主要用于NLP任务,其核心亮点包括用注意力机制替代RNN,提出多头注意力机制,提高模型性能,并在WMT2014翻译任务中取得优秀成绩。Transformer摒弃RNN和CNN,利用self-attention实现序列处理的高效并行,解决了序列依赖的问题。
本文深入探讨了迁移学习的概念及其在解决大数据与标注、计算能力、模型适配及特定应用需求矛盾中的作用。迁移学习广泛应用于计算机视觉、自然语言处理等多个领域。Transformer模型,由Google在2017年提出,主要用于NLP任务,其核心亮点包括用注意力机制替代RNN,提出多头注意力机制,提高模型性能,并在WMT2014翻译任务中取得优秀成绩。Transformer摒弃RNN和CNN,利用self-attention实现序列处理的高效并行,解决了序列依赖的问题。
迁移学习
迁移学习干什么的?
迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。
Eg:学习识别苹果可能有助于识别梨,学习骑自行车可能有助于学习骑摩托车,学习打羽毛球可能有助于学习打网球。
找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域学习过的模型应用在新领域上,可以实现一个举一反三的效果。
为什么需要迁移学习?优势所在?
1.大数据与少标注的矛盾
在实际训练过程中,虽然有大量的数据可供使用,但往往都是没有标注的,人工进行数据标定过于耗时耗力,因此通过迁移学习,寻找与目标数据相近的有标注的数据,利用这些数据来进行建模,增加目标数据的标注。
2.大数据与弱计算的矛盾
普通人买不起3090,因此需要借助迁移学习,将Google这种大公司在大数据上训练好的模型,迁移到自己的学习任务中,之后针对任务进行微调,相当于自己也能在大数据上训练模型。将这些模型针对任务进行自适应更新,还可以取得更好的效果。
3.普适化模型与个性化需求的矛盾
退一万步将,就算是一个在学习任务中,一个模型也往往难以满足每个人的需求,比如特定的隐私设置,这就需要在不同人之间做模型的适配。通过自适应的学习,考虑到不同用户之间的相似性和差异性,对普适化模型进行灵活的调整。
4.特定应用的需求
为了满足特定领域应用的需求,可以从数据和模型上进行迁移学习。
迁移学习目前的应用
计算机视觉、文本分类、行为识别、自然语言处理、室内定位、视频监控、舆情分析、人机交互等。
如:
不同视角、背景、光照的图像识别
不同语言之间的翻译,德语翻译英语,英语翻译法语
不同领域和背景的文本翻译、舆情分析
不同用户、设备、位置的行为识别
不同用户、接口、情境的人机交互
不同场景、设备、时间的室内定位
Transformer模型
Transformer干什么的?
Transformer目前主要应用于NLP领域中,它是17年Google团队在论文《Attentionisallyourneed》中提出的。
读完这篇论文,总结了Transformer的三个主要亮点:
1.不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架
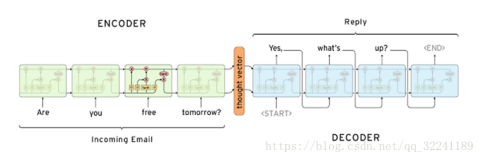
Transformer是一个带有self-attention机制的seq2seq模型, Seq2Seq模型它的输入是一个sequence,输出也是一个sequence,是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
如下:输入的中文长度为4,输出的英文长度为2
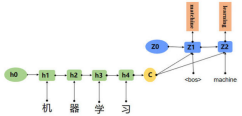
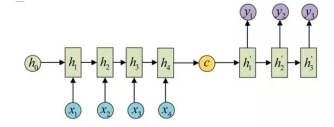
它的结构为encoder-decoder,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。
encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
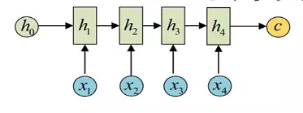
decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
2.提出了多头注意力(Multi-headedattention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-headedself-attention)。
context vector计算的是输入seq、目标seq间的关联,同时也成了限制模型性能的瓶颈,当要翻译的句子较长时,一个context可能存不下那么多信息,并且忽略了输入seq中文字间的关联、目标seq中文字间的关联性。因此引入注意力机制,将有限的认知资源集中到最重要的地方
注意力机制(Attention):
神经网络中的一种机制,模型可以通过选择性地关注给定的数据集来学习做出预测。
Eg:研表究明,汉字的序顺并不定一能影阅响读,比如当你看完这句话后,才发这现里的字全是都乱的。
上面的这段话,好几个词都存在顺序混乱,但是阅读的第一感受,不会感觉到这种乱序。因为大脑在识别文字的过程中,自动就把低可能的解释忽略了。

比如这张图,第一眼就会看见麻雀,主动的忽略掉了不重要的环境信息。
Attention机制可以它认为是一种资源分配的机制,可以理解为对于原本平均分配的资源根据Attention对象的重要程度重新分配资源,重要的单位就多分一点,不重要或者不好的单位就少分一点,在深度神经网络的结构设计中,Attention所要分配的资源就是权重。 在生成Target序列的每个词时,用到的中间语义向量context是Source序列通过Encoder的隐藏层的加权和,而不是只用Encoder最后一个时刻的输出作为context,这样就能保证在解码不同词的时候,Source序列对现在解码词的贡献是不一样的。
自注意力机制:
注意力机制关注的是重要特征,自注意力机制让每个输入都会彼此交互(自),然后找到它们应该更加关注的输入(注意力)。自注意力模块的输出是这些交互的聚合和注意力分数。
Eg:Thecathatesthemouses,iteatsit.
Attention关注的终点是cat和mouse,Self-Attention更加关注语句内部的交互联系,本来cat和mouse没有关系,但通过与hates的组合就能对这个句子的情感有认识,并且通过交互聚合,能将两个it和前面的cat与mouse联系起来。
多头注意力机制:
将多个自注意力连接起来,通过减低维度来减少总的计算消耗。
Eg:例子出处:https://blog.csdn.net/Oscar6280868/article/details/97623488
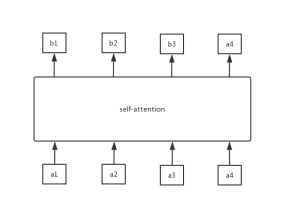
假设有x1、x2、x3和x4这四个序列,首先进行一次权重的乘法得到新的序列a1、a2、a3和a4。示意图如下所示:
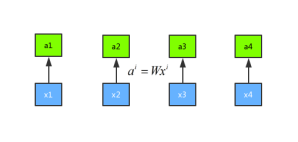
将输入a分别乘以三个不同的权重矩阵W分别得到q、k、v三个向量,这里面q表示的是query,是需要match其他的向量的;k表示的是key,是需要被q来match的,v表示value,表示需要被抽取出来的信息。
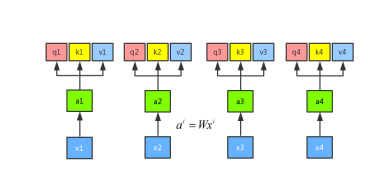
接下来将每一个query q对每一个key k做attention操作,目的是输入两个向量,输出一个分数,将这两个向量做内积。其中,Attention的操作可以用很多方法来做,论文中采用了scaled-dot-product,这里的d表示q和v的维度。

scaled-dot-product只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。
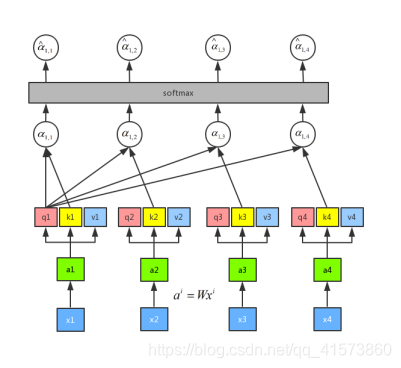
有了softmax 的输出之后,再将α1,i与Vi做点乘求和后就能得到b1
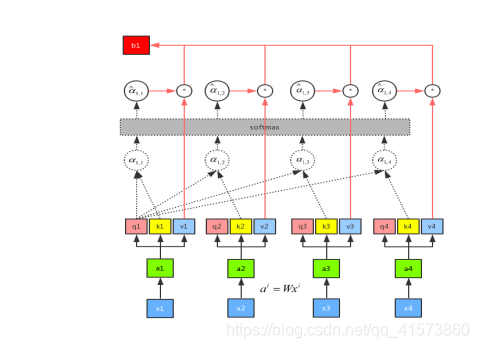
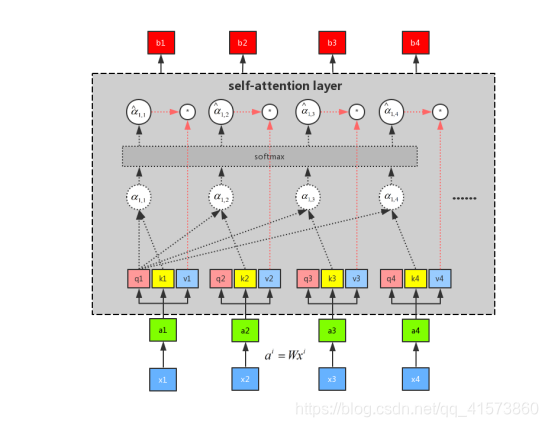
通过控制 α1,i 来控制当前输出所关注的序列权重,如果某一块序列需要被关注,那么就赋予对应 α值高权重,反之则相反。这是用q1做attention可以求得整个的输出b1,同理可以用q2、q3和q4分别做attention求得b2、b3和b4。而且b1、b2、b3和b4是平行被计算出来的,互相是没有先后顺序的影响的。所以整个中间的计算过程可以看做是一个self-attention layer,输入x1、x2、x3和x4,输出是b1、b2、b3和b4
接下来看论文中Transformer的结构:
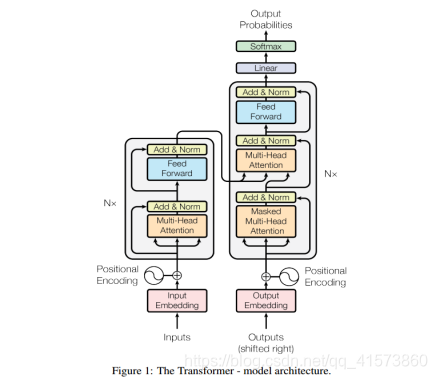
Encoder和Decoder各6层,每层结构一样。
Transformer舍弃掉了RNN与CNN,因此需要加入位置信息(相对位置或绝对位置)。
add & norm操作就是将muti-head attention的input和output进行相加,然后进行layer normalization操作。layer normalization和batch normalization刚好相反,batch normalization表示在一个batch里面的数据相同的维度进行normalization,而 layer normalization 表示在对每一个数据所有的维度进行normalization操作。
masked muti-head attention就是对之前产生的序列进行attention,之后再进行add&norm操作,之后再将encoder的输出和上一轮add&norm的操作进行muti-head attention和add&norm操作,最后再进行一个feed forward和add&norm操作,这整个的过程可以重复N次。输出的时候经过一个线性层和一个softmax层,就输出最终的结果了

V,K,Q首先通过一个线性变换,然后输入到放缩点积attention,做h次,也就是所谓的多头,每一次算一个头,每次Q,K,V进行线性变换的参数W是不一样的。将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。论文提出的多头attention的不同之处在于进行了h次计算而不仅仅算一次,说这样做的好处是可以允许模型在不同的表示子空间里学习到相关的信息 。所谓的muti-headattention就是可以同时生成多个q、k、v分别进行attention,可以获取更多的上下文信息,每个head可以关注各自所注意的重点所在。
3.在WMT2014语料中的英德和英法任务上取得了先进结果,并且训练速度比主流模型更快,在NLP领域中如语言模型和机器翻译领域表现优异。
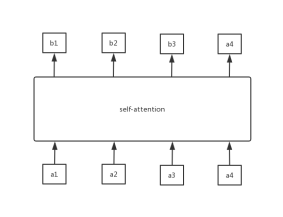
如果把self-attention替换成RNN,那么在输出b2的时候,那么一定会读取前一个序列的输出b1,输出b3的时候一定会先读取之前序列的输出b1和b2,同理在输出当前序列的时候,都要将之前序列的输出作为输入,所以在seq2seq模型中使用RNN,那么输出序列就不能高效的平行化。使用CNN就可以平行化输出序列了,使用CNN确实是可以将序列平行化,但是CNN的感受野有限,不能很好地兼顾序列前后的上下文关系,或者说是要很多层才能看到前后序列的关系,所以CNN也是有一定缺陷的。

















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









