







MATCH: Metadata-Aware Text Classification in A Large Hierarchy
1、背景
1、作者(第一作者和通讯作者)
Zhang Yu, Shen Zhihong
2、单位
Univ. of Illinois at Urbana-Champaign
3、年份
2021
4、来源
WWW会议
2、四个问题
1、要解决什么问题?
现有的研究大多只对文本信息进行建模,少数尝试利用元数据或层次信号,但没有同时利用两者。在本文中,通过形式化大标签层次结构(例如,有数万个标签)中支持元数据的文本分类问题来弥补这一差距。
2、用了什么方法解决?
提出了MATCH解决方案—一个利用元数据和层次结构信息的端到端框架。
3、效果如何?
在两个具有大规模标签层次结构的海量文本数据集上的大量实验证明了MATCH的有效性,超过了最先进的深度学习基线。
4、还存在什么问题?
论文笔记
1 INTRODUCTION

文本分类是文本挖掘的一项基本任务。论文借用一些文献的例子引出目前的研究方法存在的不足之处,紧接着引出了论文的研究方法。论文通过形式化大标签层次结构(例如,有数万个标签)中支持元数据的文本分类问题来弥补这一差距。为了解决这个问题,我们提出了MATCH解决方案—一个利用元数据和层次结构信息的端到端框架。为了合并元数据,我们预先训练文本和元数据在同一空间的嵌入,并利用完全连接的注意来捕捉它们之间的相互关系。为了利用标签层次结构,我们提出了不同的方法来规范每个子标签的参数和父标签的输出概率。
本文贡献:
(1)用文档的元数据和大规模的标签层次来形式化文本分类问题,这在现有的研究中通常不会同时建模。
(2)设计了一个端到端的MATCH框架,该框架包含文档元数据和用于文本分类任务的大型标签层次结构。
(3)大量在线文本数据集上进行了大量实验,以证明所提出的MATCH框架及其设计选择的有效性。
2 PROBLEM DEFINITION
论文研究了多标签文本分类问题。传统上,这个问题被形式化为仅使用文档的文本信息作为推断其标签的输入。但是,文档的元数据和标签的层次结构通常也可以在实际应用程序中使用。
形式上,我们将文档d的文本信息表示为单个单词序列 W d = w 1 w 2 ⋅ ⋅ ⋅ w N W_d=w_1w_2···w_N Wd=w1w2⋅⋅⋅wN,将其所有文本字段连接起来,并将其所有元数据表示为一个集合 M d = ( m 1 , m 2 , ⋅ ⋅ ⋅ , m M ) M_d=(m_1,m_2,···,m_M) Md=(m1,m2,⋅⋅⋅,mM)标签层次结构可以表示为树或指定标签之间的上位词-下位词关系的有向无环图 (DAG)。在这两种情况下,标签层次都可以通过映射 ϕ : L → 2 L \phi :ℒ→2^ℒ ϕ:L→2L其中 ϕ ( l ) 是 l ∈ L \phi(l)是l∈ℒ ϕ(l)是l∈L的父标签集。如果 l 在 L l在ℒ l在L中没有任何父标签,即 𝑙 是树的根,我们设置 ϕ ( l ) = 0 \phi(l)=0 ϕ(l)=0
给定一个训练语料库 D = ( d 1 , . . . , d ∣ D ∣ ) D=(d_1,...,d_{|D|}) D=(d1,...,d∣D∣),标签空间ℒ及其层次结构 ϕ \phi ϕ,其中每个文档 𝑑 与其文本信息 W𝑑 、元数据 M𝑑和标签 ℒ𝑑 ⊆ ℒ 相关联,目标是学习一个多标签分类器fclass,它将文档映射到ℒ的子集上。论文任务的主要挑战是如何同时将文档的元数据和标签层次结构合并到一个统一的学习框架中。
3 THE MATCH FRAMEWORK
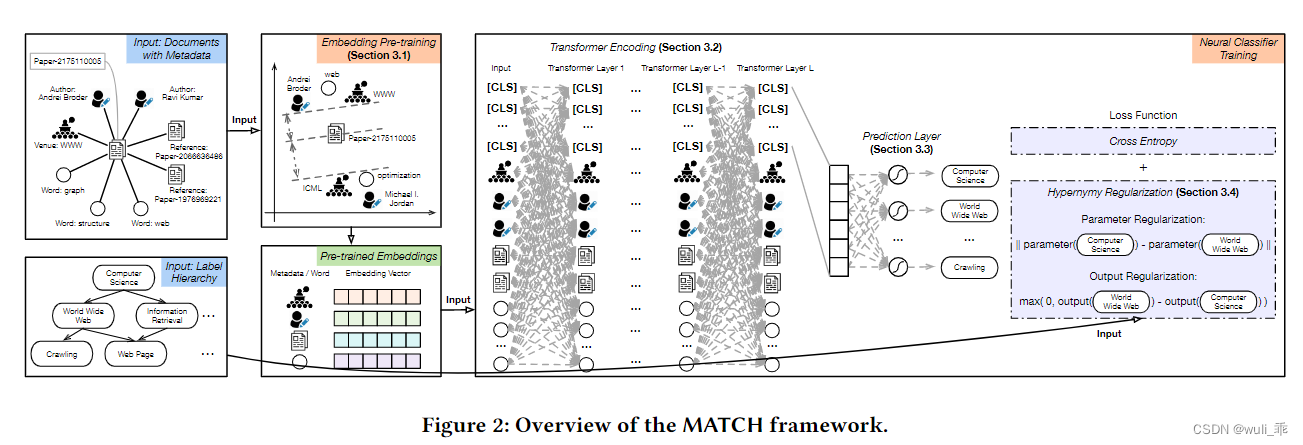
上图是MATCH的整个框架。为了合并文档的元数据,MATCH 将元数据、文本和标签的嵌入联合预训练到相同的潜在空间中,然后将其进一步输入到 Transformer 模型中,以生成用于预测的文档表示。为了利用标签的层次结构,MATCH 通过其父标签规范了每个子标签的参数和输出概率。
MATCH 可以分解为四个模块:(1)元数据感知嵌入预训练,(2)Transformer 编码,(3)预测,以及(4)上位词正则化。
3.1 Metadata-Aware Embedding Pre-Training
在论文中,需要捕获文本与其元数据之间的关系,并且最好将它们嵌入到相同的潜在空间中。为了实现这一点,作者提出了一个元数据感知嵌入预训练模块,通过考虑它们之间的几种接近度来共同学习它们的表示。
文档和元数据: 为了在联合嵌入空间中保持文档 𝑑 与其元数据实例 𝑚 ∈ M𝑑之间的接近度,公式为:

其中 V𝑚是与𝑚共享相同类型的元数据实例的集合(例如,如果 𝑚 表示一个场所,则 Vm是出现在训练集中的所有场所的集合); 𝒆𝑚和𝒆𝑑分别是元数据和文档嵌入向量。
论文的目标是在嵌入学习期间最大化对数似然 l o g p ( m + ∣ d ) logp(m_+ |d) logp(m+∣d)。为此,作者采用以下基于边际的排名损失:

𝑚−是文档𝑑的负元数据上下文; 𝛾 > 0 是一个超参数,指示正对(𝑑,𝑚+)和负对(𝑑,𝑚−)之间的预期边距。基于公式中𝑝 (𝑚|𝑑) 的定义。有以下

文档元数据接近的目标函数可以定义如下

文件和标签: 嵌入预训练步骤可以通过结合这些文档-标签关系来设计为一个监督过程。

文档和文字: 文档嵌入𝒆𝑑可以被认为是𝑑主题的表示。给定一个主题,作者写下与整个文本的含义一致的单词。

Wd是文档𝑑的文本序列,W是整个单词的词汇。
单词和上下文: 给定一个文本序列 W d = w 1 w 2 ⋅ ⋅ ⋅ w N W_d=w_1w_2···w_N Wd=w1w2⋅⋅⋅wN,单词wi的语义不仅取决于文档主题,还取决于其在本地上下文窗口中的周围单词 C ( w i ) = ( w i + j ∣ − x ≤ j ≤ x , j ≠ 0 ) C(w_i)=(w_{i+j}|-x≤j≤x,j≠0) C(wi)=(wi+j∣−x≤j≤x,j=0),其中x是窗口大小。假设每个单词都有一个中心词嵌入ew,和一个上下文嵌入cw。为了鼓励单词与其本地上下文之间的紧密性,可以提出以下目标。

给定每种关系的目标,我们的嵌入预训练模块可以表述为一个联合优化问题,如下所示。

使用 L2 范数约束来控制嵌入向量的规模。
**优化:**在每次迭代中,我们通过随机采样正对(例如,(𝑑,𝑚+))和相应的负对(例如,(𝑑,𝑚-))来交替优化一个部分(例如,JDM)。给定这两对,我们可以计算嵌入的欧几里得梯度∇𝐸。以JDM为例,梯度向量如下。
其中1(·) 是指标函数。在优化其他部分时,可以用类似的方法计算欧几里得梯度。
根据以下等式根据欧几里德梯度 ∇𝐸 在球体上计算黎曼梯度 ∇𝑅:

以以下形式更新嵌入向量:

其中𝛼𝑡是步骤𝑡的学习率。
3.2 Transformer Layers
Transformer 提出了一种完全连接的注意力机制来支持序列中任意两个令牌之间的这种交换。因此,我们将文档的所有元数据实例与其单词序列连接起来以形成层输入。此外,我们在每个输入序列的开头添加 [CLS] 标记。首次在 BERT中提出,这种特殊标记的最终状态被用作分类任务的聚合序列表示。当标签空间很大(例如,10K)时,一个 [CLS] 标记(例如,100 维向量)可能不足以提供足够的信息来预测相关标签。层输入H是:

H ∈ R δ × ( C + ∣ M d ∣ + ∣ W d ∣ ) H∈R^{δ\times (C+|M_d|+|W_d|)} H∈Rδ×(C+∣Md∣+∣Wd∣),其中𝛿是嵌入空间的维度。
Intuition behind the Metadata-aware Input Sequence: 给定一个输入序列S,S是Md、Wd和[CLS]标记的并集。因此,注意力机制允许每个 [CLS] 令牌聚合来自所有元数据实例和单词的信息。此外,如果我们将每个输入文档视为文档节点 𝑑 的自我网络,我们的嵌入预训练步骤本质上捕获了 𝑑与其邻居之间的一阶接近度,而这里的全连接注意力机制描述了二阶在𝑑附近订购邻近。换句话说,我们的 Transformer 层促进了元数据实例和单词之间的高阶交互。
Multi-head Attention:
K
=
H
W
K
,
V
=
H
W
V
矩阵
W
K
和
W
V
K=HW^K,V=HW^V矩阵W^K和W^V
K=HWK,V=HWV矩阵WK和WV是要学习的参数。
与 CNN 中的多通道思想类似,Transformer 使用多头注意力从 𝑯 中提取更多信号。
||表示连接操作,矩阵
W
i
Q
,
W
i
K
,
W
i
V
W_i^Q,W_i^K,W_i^V
WiQ,WiK,WiV是可学习的参数。
**Document Encoding:**使用多头注意力,对于每个输入标记 𝑖 ∈ 𝑯,我们根据其预先训练的嵌入 𝒆𝑖 更新其表示。
这里,LayerNorm(·) 是层归一化算子,FFN(·) 是位置前馈网络。为了结合令牌的位置信息,我们进一步将其正弦位置嵌入与其输入嵌入𝒆𝑖连接起来。
3.3 Prediction Layer
在Transformer层之后,我们连接所有 [CLS] 标记的最终状态,以获得最终的文档表示
h
^
d
\hat{h}_d
h^d。

为了进行分类,我们在 Transformer 的输出上添加了一个全连接层。最后一层连接到|ℒ| sigmoid 函数,对应于ℒ中的所有标签。
在给定输出概率的情况下,通过将多标签分类任务视为|ℒ|二分分类子任务,我们的模型最小化了二进制交叉熵(BCE)损失。

其中ydl=1表示文档d具有标签,否则为0。
3.4 Hypernymy Regularization
为了将标签层次结构合并到 MATCH 中,论文建议通过其父标签对每个非根标签进行正则化。具体来说,正则化应用于参数空间和输出空间。
Regularization in the Parameter Space:
其中 Φ(𝑙) 表示 𝑙 的父标签集。
Regularization in the Output Space:

基于 BCE 损失和两个提议的正则化项,我们使用以下目标来学习我们的神经架构的参数:

4 EXPERIMENTS
4.1 Setup
Datasets:

4.2 Performance Comparison

消融实验:

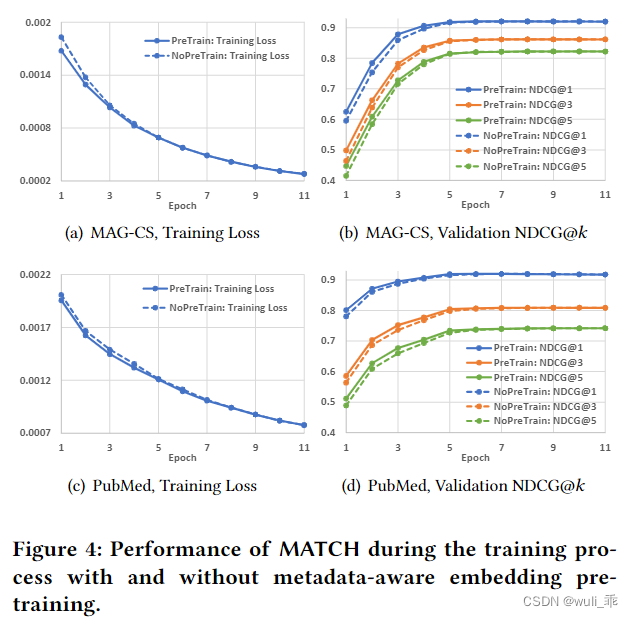
MATCH 和 MATCHNoPreTrain 在训练过程中的性能














 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









