






目录



Mask R-CNN主体结构还是Faster R-CNN,后端并联了一个mask分支

Mask R-CNN有两种:一种不带FPN特征金字塔结构的,一种带FPN的,现今以采用FPN结构的为主
RoIAlign
RoIAlign的提出是为了解决在网络两次取整操作中所导致的Misalignments问题

将原图点映射到特征层上,步距为32,会出现无法整除,RoIPooling进行四舍五入这样就会导致误差。

同样将原图点映射到特征层上,出现小数不进行四舍五入直接对应特征图上,例如(0.3125,3.875)带小数的形式。将蓝色的矩形框均分为2X2几个子区域,由于2X2均分不存在四舍五入操作。对于每个子区域要求取输出涉及到sampleing ratio参数,即每个子区域需要采样多少个点。原论文sampleing ratio=2,此处假设sampleing rati=1找到四个点的中心点,如橙色点,确定距离橙色点最近的四个特征点。利用双线性插值计算公式获取距离橙色点的数值。
RoIAlign的结果对于采样点位置以及采样点的个数并不敏感。
Mask分支
Mask R-CNN包括两个分支,一个是类别分支一个是Mask分支

Mask分支与分类分支不共用一个RoI,Mask分支需要更多的细节信息所以没有池化到7X7大小,而是池化到14 X14的大小

Mask分支针对每个类别都预测了一个模板且模板大小均为28X28。
MaskRCNN之前的网络对每一个像素每一个类别都会预测一个概率分数,之后会对每一个像素沿channel方向做一个softmax处理,会得到每一个像素归属每一个类别的概率分数,这样不同类别间存在竞争关系,每一个像素沿channel方向的概率之和等于1,所以各个类别存在竞争关系。MaskRCNN不会对每一个像素沿channel方向做一个softmax处理,而是针对类别分支预测的类别信息带入Mask分支中,将针对该类别的模板提取出来使用,类别间不存在竞争关系。

预测的时候只需要最准确的目标边界框
Mask R-CNN损失

相较于之前的FaterRCNN增加了一个Mask分支

图片输入给骨干网络通过下采样得到最终不同特征层的特征图,通过RPN得到多个Proposals这里的Proposals都是正样本,将这些Proposals送入RoIAlign,会根据Proposals大小在对应的特征层进行裁剪得到14X14的特征。再将特征送入Mask分支,就会每一个类别都预测一个Mask,因此得到Mask分支得到的logits。虽然Mask分支没有进行softmax处理,但是会经过sigmoid激活,即将每一个点映射到[0,1]之间。Proposals回到原图去裁剪对应的区域,在缩放到28x28大小得到真实Mask,真实Mask中目标区域为1,真实区域为0。与预测Mask送入损失函数中去计算损失。
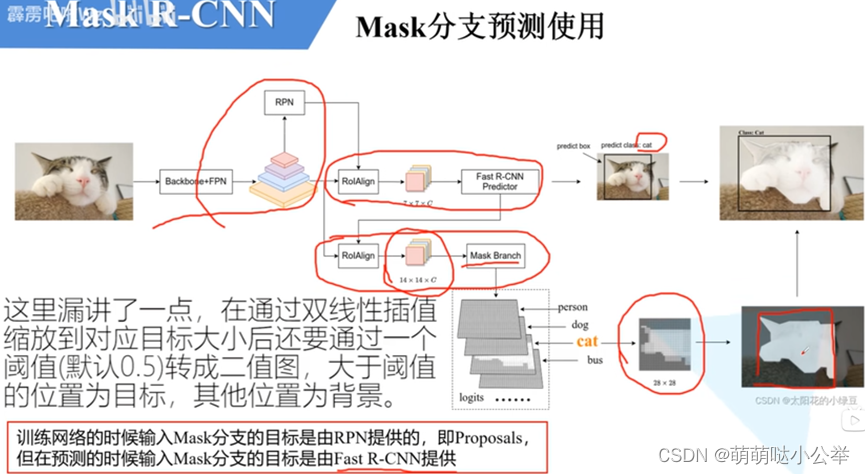
得到Mask为28X28大小,经过双线性插值放大到与预测边界框一样大小,放到原图对应的位置区域。
一些浅显的总结,后续还会继续完善。。。
文章内容主要来源于:Mask R-CNN网络详解_哔哩哔哩_bilibili















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









