







 该博客通过分析电商历史数据,运用机器学习算法,特别是决策树,预测客户未来消费可能性。介绍了销售响应预测、预测方法、选择的算法模型及其应用场景,并详细讲解了数据处理过程和评估指标。最终确定决策树为最佳分类模型。
该博客通过分析电商历史数据,运用机器学习算法,特别是决策树,预测客户未来消费可能性。介绍了销售响应预测、预测方法、选择的算法模型及其应用场景,并详细讲解了数据处理过程和评估指标。最终确定决策树为最佳分类模型。
1.销售预测
通过电商过去的数据,主要了解总体的销售情况,用户消费现状、产品销售现状、流量现状、风控现状、市场竞争现状
这里主要对客户进行一个销售响应预测,把握客户未来的消费可能性。
2.预测方法
专家经验预测法、机器学习算法预测、时间序列预测、线性回归预测
这里采用机器学习算法预测
3.机器学习算法选择
算法模型的选择主要根据数据的数据量、特征数、维度之间的相关性,目的是获取高的预测准确率,没有最完美的分类器,只有最合适的分类器,下面简要说一下常用分类算法的思路和应用场景。
【KNN】
思路 ——根据待判断点附近的几个点的类型去决定待判断的类型
场景 ——需要比较容易解释的模型
【Bayes】
思路——根据条件概率判断待判断点的类型
场景 ——容易理解,不同维度之间相关性较小的模型
【决策树】
思路——根据特征进行切分,随着层层切分,越分越细
场景——分析师查看基于特征划分的树状结果,但容易被攻击,人为更改的因素容易分类错误
【随机森林】
思路——首先随机选取不同的特征和训练样本,生产大量决策树,然后综合分类
场景——数据维度相对低(几十维),同时对准确性有较高要求时,不需要调整很多参数就能达到效果,不知道使用哪种算法时可尝试
【SVM】
思路——找到不同类别之间的分界面,使得两类样本尽量落在面的两边且远离
场景——利用核函数改良的SVM跟随机森林一样可优先尝试
【神经网络】
思路——利用训练样本来逐步低完善参数。
场景——数据量大,参数之间存在内在联系的时候
【AdaBoost】
思路——从最基础的分类器开始,每次寻找一个最能解决错误分类的分类器,再加权进去
场景——自带特征选择,新手常用
4.分类算法评价指标
分类结果由TP(正分正)、TN(错分错)、FP(错分正)、FN(正分错)组成
accuracy准确率——TP+TN/(TN+TP+FP+FN)
auc_score——ROC曲线下的面积,也只能分0和1的二值矩阵,3分类及以上要用Binarize
f1_scoreF1得分——2*(P*R)/(P+R)
precision_score精确度P——TP/TP+FP
recall_score召回率R——TP/TP+FN
5.数据处理过程
这里同时采用决策树算法和其中经过训练筛选通过准确率来简要筛选一种算法来预测数据,这里我们先用决策树算法画出树状类型的图来展示一个分类的基本逻辑,便于理解,再选择一个合适的算法模型来预测。
模块——导入库、数据集特征查看、数据空值处理、数据类型转换、数据二值化、决策树画图、选择合适的算法模型、选择最好的算法模型、数据保存
应用的库——【sklearn】sklearn.metrics、sklearn.ensemble、sklearn.selection、sklearn.featute_selection、sklearn.model_selection、sklearn.pipeline
还有numpy、pandas、matplotlib、prettytable、pydotplus(用于画树状图的库)、time
应用的算法KNeighborsClassifier,DecisionTreeClassifier,SVC,AdaBoostClassifier,RandomForestClassifier,GradientBoostingClassifier
6.数据处理结果
6.1训练数据特征与预处理
查看数据基本特征

查看数据描述性统计
查看数据类型以及空值情况
Total number of NA lines is :12
处理后检查Na
Check NA exists:
0
查看相应分类结果
Labels samples count:
response
0 30415
1 9584
Name: value_level, dtype: int64
转换类型后的数据结果
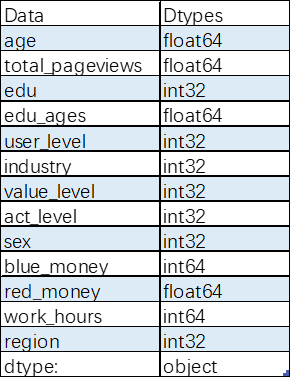
6.2训练数据特征与预处理
查看数据的基本特征

查看数据的描述性统计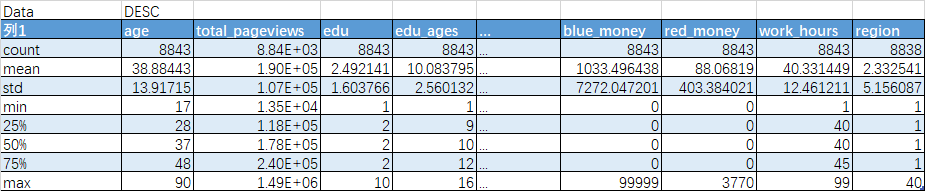
查看数据的数据类型以及空值情况

Total number of NA lines is :7
数据处理后检查空值
Check NA exists:
0
转换类型后的结果
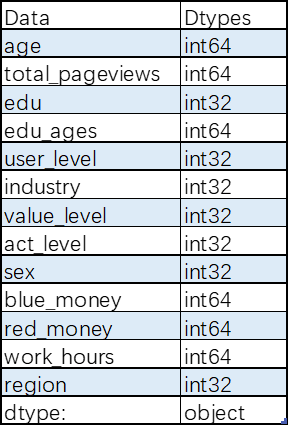
6.3决策树模型结果
核心评价指标

混淆矩阵
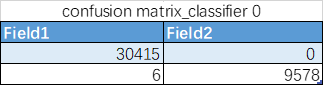
AUC曲线及重要特征图

决策树逻辑图

6.4合适的算法模型
各种算法结果
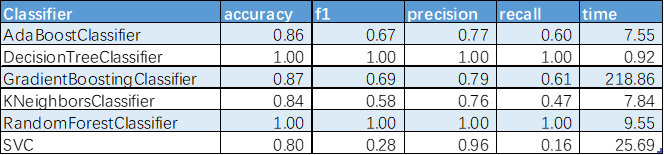
所以选择DecisionTreeClassifier作为分类模型
6.5选择最好的分类算法模型
已经知道决策树是最好的分类模型,那么不需要再进行调节了
预测结果 7.1数据特征
7.1数据特征
特征变量数:13
训练数据记录数:39999条
预测数据记录数:8843条
特征变量解释:
age:年龄,整数型变量。
total_pageviews:总页面浏览量,整数型变量。
edu:教育程度,分类型变量,值域【1,10】
edu_ages:受教育年限,整数型变量。
user_level:用户等级,分类型变量,值域【1,7】
industry:用户行业划分,分类型变量,值域【1,15】
value_level:用户价值度分类,分类型变量,值域【1,6】
act_level:用户活跃度分类,分类型变量,值域【1,5】
sex:性别,值域【1,0】
blue_money:历史订单的蓝券用券订单金额(优惠券的一种),整数型变量。
red_money:历史订单的红券用券订单金额(优惠券的一种),整数型变量。
work_hours:工作时间长度,整数型变量。
region:地区,分类型变量,值域【1,4】
目标变量response,1代表用户相应,0代表用户没有相应。
7.2数据预处理
导入库
import pandas as pd
import numpy as np
import prettytable
import pydotplus
import time
from sklearn.model_selection import train_test_split
#导入分类算法
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn import semble import RandomForestClassifier,GradientBoostingClassifier,AdaBoostClassifier
from sklearn.metrics import accuracy_score,auc,f1_score,precision_score,recall_score #导入分类算法评价指标
from sklearn.model_selection import StratifiedKFold,cross_val_score #导入交叉检验算法
from sklearn.feature_selection import SelectPercentile,f_classif #导入特征选择方法库
from sklearn.pipeline import Pipeline #导入Pieline库
查看数据集的记录数、维度数、前2条数据、描述性统计和数据类型
def set_summary(df):
'''查看数据集的记录数、维度数、前2条数据、描述性统计和数据类型
return 无'''
print('Data Overview')
print('Records:{0}\tDimension{1}'.format(df.shape[0],df.shape[1]-1))
print('-'*30)
print(df.head(2))
print('-'*30)
print('Data DESC')
print(df.describe())
print('Data Dtypes')
print(df.dtypes)
print('-'*60)
查看数据集的缺失数据列、行记录数
def na_summary(df):
'''查看数据集的缺失数据列、行记录数
return 无'''
na_col=df.isnull().any(axis=0)
print('Na_cols:')
print(na_col)
print('-'*30)
print(df.count())
print('-'*30)
na_lines =df.isnull().any(axis=1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









