







 通过对电商销售数据的分析,揭示客户消费行为的模式和趋势。重点在于理解客户总体和个体消费情况,发现高价值用户,优化运营策略。分析显示,客户在活动期间大量涌入,但留存率低,一次性购买比例高,表明需要改进客户保留策略。
通过对电商销售数据的分析,揭示客户消费行为的模式和趋势。重点在于理解客户总体和个体消费情况,发现高价值用户,优化运营策略。分析显示,客户在活动期间大量涌入,但留存率低,一次性购买比例高,表明需要改进客户保留策略。
一、分析背景
为了提高店铺的收益,进行准确的客户运营策略,使用店铺201910至202002的销售数据进行分析,根据客户的消费趋势、消费习惯把握客户的消费现状和心理,挖掘出高价值用户群体,完善销售运营策略。
简单说明一下,客户分析包括基本属性、交易行为、浏览行为、服务体验、社交分享这几个方面的分析,主要应用场景是客户画像、客户忠诚度提升策略设计、客户数增长、精准运营。
这里只进行客户消费行为分析,主要来了解是客户在总体和个体上的消费情况以及客户的消费习惯,能对目前客户的消费现状以及销售指标变化背后原因有一个更深的认识,并进行新老顾客划分以及基于RFM模型的客户分群,利于后续的精准运营策略设计。
二、客户消费行为分析思路
2.1思路
数据分析最重要的是思路,思路通了,一切变得清晰明了。
首先学会描述行为:时间、地点、人物、动作、对象
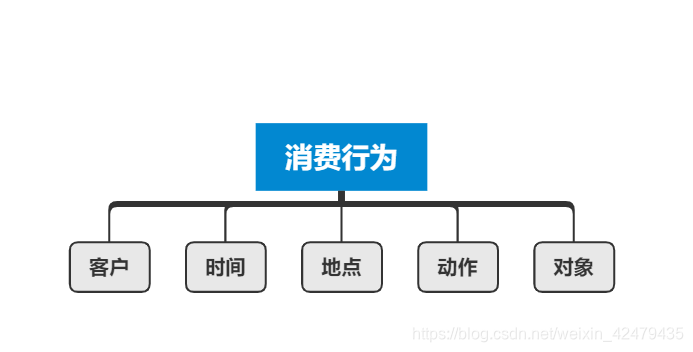
2.2描述
消费行为就是:客户(人物)在什么时间在什么地点购买了什么特性的产品(对象)
这里主要是了解客户,就是通过购买时间、购买地点、购买产品这三大维度去了解客户
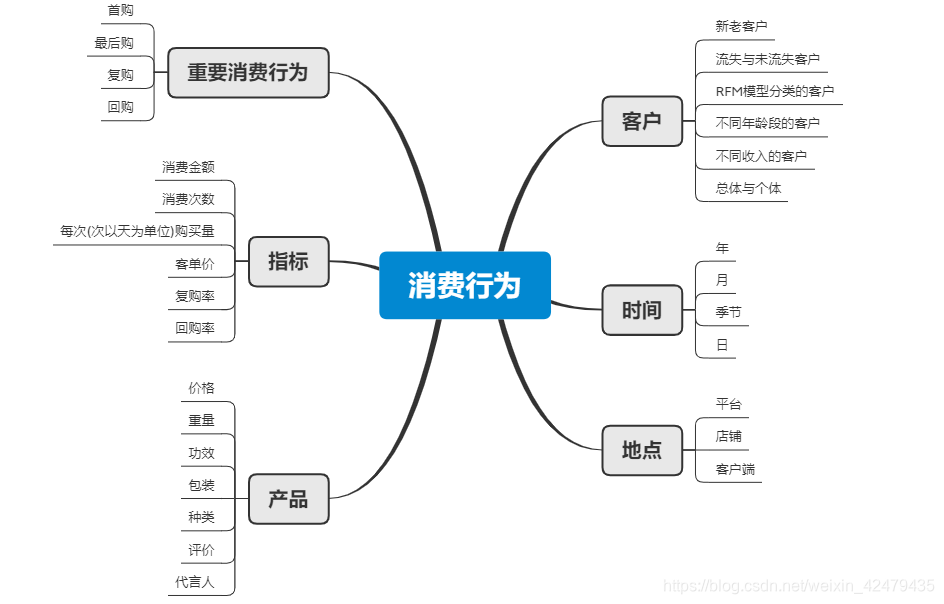
消费行为的类型:
1、复杂的购买行为。
2、减少失调感的购买行为。
3、寻求多样化的购买行为。
4、习惯性的购买行为。
三、分析步骤
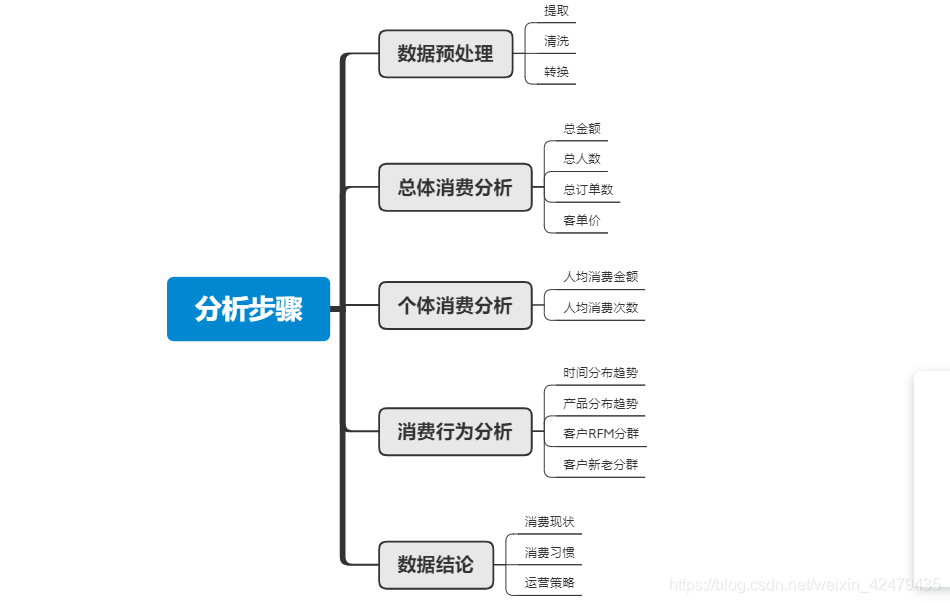
四、数据预处理
数据来源:这里采用了Kaggle上面的eCommerce Events History in Cosmetics Shop的数据集,此数据集包含一家中型化妆品在线商店5个月(2019年10月至2020年2月)的行为数据。数据网址
一共有五个文件
2019-Oct.csv
2019-Nov.csv
2019-Dec.csv
2020-Jan.csv
2020-Feb.csv

4.1读取数据-只需要event_type为purchase的数据
data_all=[]
years=[2019,2020]
filenames=['Oct','Nov','Dec','Jan','Feb']
for year in years:
for filename in filenames:
filepath=r'%d-%s.csv' %(year,filename)
try:
data=pd.read_csv(filepath)
except:
continue
data_all.append(data)
data_alls=pd.concat(data_all,ignore_index=True)
data_alls_purchase=data_alls[data_alls.event_type=='purchase']
4.2查看数据情况
查看数据类型、数据长度、数据大小
data_alls_purchase.info() #查看数据类型、数据长度、数据大小
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1286880 entries, 0 to 1286879
Data columns (total 9 columns):
event_time 1286880 non-null object
event_type 1286880 non-null object
product_id 1286880 non-null int64
category_id 1286880 non-null int64
category_code 17214 non-null object
brand 737314 non-null object
price 1286880 non-null float64
user_id 1286880 non-null int64
user_session 1286880 non-null object
dtypes: float64(1), int64(3), object(8)
memory usage: 117.8+ MB
查看各列缺失情况
有brand、category_code两列值缺失
data_alls_purchase.isnull().any()#查看各列缺失情况
event_time False
event_type False
product_id False
category_id False
category_code True
brand True
price False
user_id False
user_session False
dtype: bool
查看缺失列的缺失情况
这两列缺失严重,在消费产品维度上分析受到了影响
data_alls_purchase.brand.isnull().value_counts()
False 737314
True 549566
Name: brand, dtype: int64
data_alls_purchase.category_code.isnull().value_counts()
True 1269666
False 17214
Name: category_code, dtype: int64
查看数据有效性并转换
price的取值范围应是>0
data_alls_purchase=data_alls_purchase[data_alls_purchase.price>0]
event_time的时间范围应是
2019-10-01 00:00:00至
2020-02-29 23:59:59
通过pd.to_datetime函数进行转换,转换成功说明没有问题
data_alls_purchase.iloc[0]
event_time 2019-10-01 00:06:35 UTC
event_type purchase
product_id 5619862
category_id 1487580006895846315
category_code NaN
brand runail
price 5.32
user_id 474232307
user_session 445f2b74-5e4c-427e-b7fa-6e0a28b156fe
Name: 0, dtype: object
查看重复值
没有重复项
data_alls_purchase.duplicated().value_counts()
False 1286880
dtype: int64
把时间转换成合理的格式
def get_datetime(data):
datetime= ' '.join((data.split(' ')[0],data.split(' ')[1]))
return (pd.to_datetime(datetime)).strftime('%Y-%m-%d %H:%M:%S')
data_alls_purchase.event_time=data_alls_purchase.event_time.map(get_datetime)
由于后续需要进行按月分组和时间段的操作,这里进行提取月份、日期、时间、小时
data_alls_purchase['year_month']=data_alls_purchase.event_time.apply(lambda x:'-'.join((x.split('-')[0],x.split('-')[1])))
data_alls_purchase['time']=data_alls_purchase.event_time.apply(lambda x:x.split(' ')[1])
data_alls_purchase['date']=data_alls_purchase.event_time.apply(lambda x:x.split(' ')[0])
data_alls_purchase['hour']=data_alls_purchase.event_time.apply(lambda x:(x.split(' ')[1]).split(':')[0])
五、客户总体消费情况分析
5.1五个月的销售总体指标
#求出销售总金额、总单数、总人数
all_amount=data_alls_purchase.price.sum()
all_count=data_alls_purchase.price.count()
all_customers=len(data_alls_purchase.user_id.drop_duplicates())
print('{:*^30}'.format('销售总指标'))
print('销售总金额:',all_amount)
print('销售总单数:',all_count)
print('购买总人数:',all_customers)
************销售总指标*************
销售总金额: 6351830.290000002
销售总单数: 1286880
购买总人数: 110518
5.2客户每月消费趋势
#求出销售总金额、总单数、总人数的月趋势
month_amount=data_alls_purchase.price.sum()/5
month_count=data_alls_purchase.price.count()/5
month_customers=len(data_alls_purchase.user_id.drop_duplicates())/5
print('{:*^30}'.format('月均销售指标'))
print('月均销售总金额:',month_amount)
print('月均销售总单数:',month_count)
print('月均购买总人数:',month_customers)
************月均销售指标************
月均销售总金额: 1270366.0580000004
月均销售总单数: 257376.0
月均购买总人数: 22103.6
fig,axes=plt.subplots(1,3,figsize=(12,6))
ax1=axes[0]
ax2=axes[1]
ax3=axes[2]
#作出客户每月消费金额趋势图
data_alls_purchase.groupby('year_month').price 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









