







Hello Flink (二)
胡汉三带着Java回来了,毕竟官网的文档示例都是Java,咱还是得虚心从Java开始。
一、WordCount
最为大数据界的Hello World,WC还是有必要重温一下,用它来学习大数据框架太合适了。
既然说起来大数据处理,一定避不开两个问题:流处理or批处理。这里我就先试一下批处理的方式,实现一个简单的WC。
public class BatchWordCount {
// 1、创建一个执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2、从文件中读取数据
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
// 3、将每行数据拆分成单词,转换成二元组(word, 1)
FlatMapOperator<String, Tuple2<String, Integer>> wordTuples = lineDataSource.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
// 4、按照单词分组
UnsortedGrouping<Tuple2<String, Integer>> wordGroup = wordTuples.groupBy(0);
// 5、对分组后的数据进行聚合
wordGroup.sum(1).print();
}
从上面的代码可以看到,整体流程还是贴近spark的感觉,执行环境->创建输入DS->处理逻辑;但是细节又有不同,比如DS里面泛型直接给到String,flatMap传入的函数,还有函数内的收集器Collector,再加上Flink准备的Tuple,如果没有Tuple我可能要吐槽一百遍。里面的returns是我没想到的,竟然还需要指定返回的数据类型,其实不加这个代码也可以获取到同样类型的返回,但就是会报错提示不能自动转换,我得研究一下子。
二、DataSet
上面用到的DataSource其实和FlatMapOperator底层都是DataSet,在早期的Flink批处理代码里很常见,后面应该也会经常接触到,它们同属于DataSet系列的算子(我先这么称呼它们吧)。
我已经感觉到DataSet应该是一个比较重要的东西,于是我翻开了它的类,打算先看一下里面的基本功能。
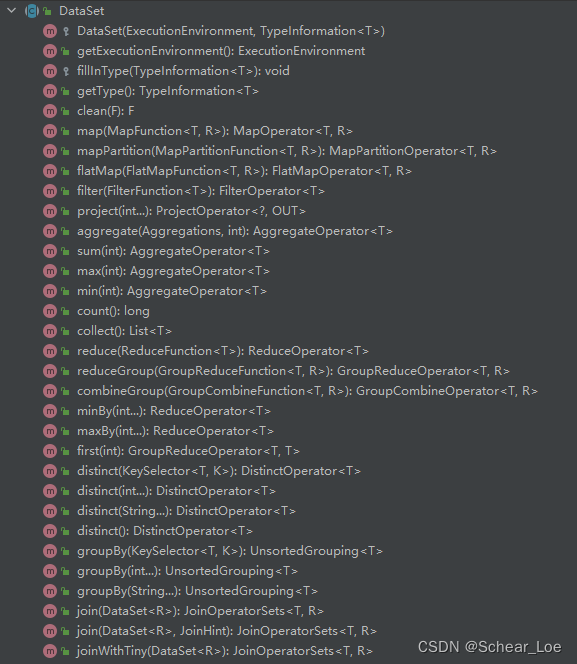
嗯,确实不少,而且看起来都很眼熟,有map、filter、groupBy……就是不知道用起来是否和以前一样,慢慢了解吧!
根据方法的功能,大致可以将 DataSet 的方法分为以下几类:
1、数据转换
- map:对 DataSet 中的每个元素进行映射操作,返回一个新的 DataSet。
- flatMap:对 DataSet 中的每个元素进行扁平化操作,生成多个元素,返回一个新的 DataSet。
- filter:对 DataSet 中的元素进行过滤。
- distinct:对 DataSet 中的元素进行去重。
- join:将两个 DataSet 进行连接操作。
2、数据分组
- groupBy:按照指定的键进行分组操作。
3、数据聚合
- reduce:按照指定的键进行 reduce 操作。
- aggregate:按照指定的键进行聚合操作。
- sum/min/max:计算 DataSet 中的最小值、最大值或总和。
4、数据排序
- sortPartition:对 DataSet 进行分区排序。
- sortGroup:对 GroupedDataSet 进行排序。
5、数据分区
- partitionByHash:按照哈希函数对 DataSet 进行分区。
- partitionByRange:按照指定的字段对 DataSet 进行范围分区。
6、数据输出
- print:将 DataSet 中的元素输出到控制台。
- writeAsText:将 DataSet 中的元素写入文本文件中。
三、下课
今天的自习课结束了,各位小伙伴是因为什么开始自习的呢?















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









