







Get To The Point: Summarization with Pointer-Generator Networks

paper:https://arxiv.org/pdf/1704.04368
code: http://www.github.com/abisee/pointer-generator
摘要
神经序列-序列模型为抽象文本摘要提供了一种可行的新方法(这意味着它们不局限于从原始文本中简单地选择和重新排列段落)。然而,这些模型有两个缺点:它们容易不准确地再现事实细节,而且它们往往重复。在这项工作中,提出了一个新的体系结构,以两种正交的方式扩充标准序列到序列注意模型。首先,我们使用了一个混合指针-生成器网络,它可以通过指针从源文本中复制单词,这有助于信息的准确复制,同时保留了通过生成器生成新单词的能力。其次,我们使用覆盖率来跟踪已经总结的内容,这就不鼓励重复。我们将模型应用于CNN /Daily Mail摘要任务,优先于最新模型至少2个点。
模型
seq2seq+attention(baseline)
PNG网络实在seq2seq+attention的基础上构建的,其架构图如下:

图2:基线序列到序列模型。该模型可以根据源文本中的相关词生成新词,例如,在摘要德国队2-0击败阿根廷队的模型中产生新颖单词beat,可能关注原文中的单词 victorious和win。
文章
w
i
w_i
wi的tokens被一个接一个地馈送到编码器(一个单层双向LSTM),产生一个编码器隐藏状态序列
h
i
h_i
hi。在每一步
t
t
t上,解码器(单层单向LSTM)接收到前一个词的词嵌入(在训练时,这是参考摘要的前一个词;在测试时,它是解码器发出的前一个单词),并具有解码器状态
s
t
s_t
st。
a
t
a^t
at的注意分布按Bahdanau et al.(2015)计算:

其中
v
v
v、
W
h
W_h
Wh、
W
s
W_s
Ws和
b
a
t
n
b_{atn}
batn为可学习参数。注意力分布可以看作是源单词的概率分布,它告诉解码器从哪里寻找下一个单词。接下来,注意力分布被用来产生编码器隐藏状态的加权和,称为上下文向量
h
t
∗
h_t^*
ht∗.

上下文向量可以被看作是从源代码中读取的内容的固定大小的表示,它与解码器状态
s
t
s_t
st连接在一起,并通过两个线性层提供给它,以产生词汇表分布
P
v
o
c
a
b
P_{vocab}
Pvocab,如下图所示:

其中
V
V
V、
V
′
V'
V′、
b
b
b和
b
′
b'
b′是可学参数。
P
v
o
c
a
b
P_vocab
Pvocab是词汇表中所有单词的概率分布,它为我们提供了预测单词
w
w
w的最终分布。

在训练过程中,时间步长
t
t
t的损失是目标词
w
t
w_t
wt在该时间步长的负对数可能性

整个序列的总损失是

Pointer-generator network

指针生成器网络是基线和指针网络的混合体(Vinyals,2015),因为它既允许通过指向额外单词,也允许从固定词汇表中生成单词。在指针-生成器模型(如图3所示)中,
a
t
a^t
at和上下文向量
h
t
∗
h^*_t
ht∗的注意分布计算方法如2.1节所示。此外,从上下文向量
h
t
h_t
ht、解码器状态
s
t
s_t
st和解码器输入
x
t
x_t
xt计算出
t
t
t时刻的生成概率
p
g
e
n
∈
[
0
,
1
]
p_{gen} \in [0,1]
pgen∈[0,1]:

其中向量
w
h
w_h
wh、
w
s
w_s
ws、
w
x
w_x
wx和标量
b
p
t
r
b_{ptr}
bptr为可学参数,
σ
σ
σ为sigmoid函数。接下来,
p
g
e
n
p_gen
pgen被用作软作用,通过
P
v
o
c
a
b
P_{vocab}
Pvocab从词汇表中抽样生成单词,或者通过
a
t
a^t
at注意分布从输入序列中复制单词。对于每个文档,让扩展词汇表表示词汇表和出现在源文档中的所有词汇的联合。在扩展的词汇表上,我们得到以下概率分布:

注意,如果
w
w
w是一个词汇表外的单词(OOV),那么
P
v
o
c
a
b
(
w
)
P_{vocab}(w)
Pvocab(w)是零;类似地,如果
w
w
w没有出现在源文档中,则
Σ
i
:
w
i
=
w
a
i
t
\Sigma_{i:w_i=w}a_i^t
Σi:wi=wait为零。能够生成OOV单词是指针生成器模型的主要优势之一。相比之下,像我们的基线这样的模型被限制在它们预先设定的词汇表中。损失函数如式(6)和式(7)所示,但根据式(9)中给出的修正概率分布P(w)。
Coverage mechanism
重复是序列到序列模型的常见问题。尤其是在生成多句文本时。采用Tu et al.(2016)的coverage模型来解决这个问题。
在coverage模型中,我们保持一个coverage向量
c
t
c_t
ct,它是所有先前解码器时间步上的注意力分布的总和。直观地说,
c
t
c_t
ct是源文档单词的(非标准化)分布,表示这些单词迄今为止从注意机制中获得的coverage程度。请注意,
c
0
c^0
c0是一个零向量,因为在第一个时间步中,没有涉及任何源文档。

将coverage向量作为注意力机制的额外输入,将式(1)改为

其中
w
c
w_c
wc是一个与
v
v
v长度相同的可学习参数向量。这确保了注意力机制的当前决策(选择下一个注意地点)被先前决策的提醒通知(汇总在
c
t
c_t
ct中)。这将使注意力机制更容易避免重复注意相同的位置,从而避免产生重复的文本。附加定义一个coverage损失,以惩罚重复单词。

请注意,覆盖率损失是有界的,特别是
c
o
v
e
r
a
g
e
t
≤
σ
i
a
i
t
=
1
coverage_t≤\sigma_i a^t_i = 1
coveraget≤σiait=1 等式(12)与机器翻译中使用的coverage损失不同。在MT中,我们假设应该有一个大致一对一的翻译率;因此,如果最终的coverage平均向量大于或小于1,则会受到惩罚。
我们的损失功能更灵活:因为总结不应该要求统一的coverage范围,所以我们只惩罚了每个注意分布之间的coverage和迄今为止防止重复注意的coverae范围。最后,通过超参数
λ
λ
λ对覆盖损失进行加权,将coverage损失添加到主损失函数中,得到一个新的复合损失函数
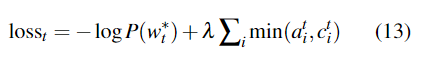
实验
在所有的实验中,我们的模型有256维的隐藏状态和128维的词嵌入。

ROUGE是唯一可以与Nallapati等人的工作进行比较的方法。然而,考虑到lead-3得分差距分别为(+1.1 ROUGE-1, +2.0 ROUGE-2, +1.1 ROUGE-L)分,其最佳模型得分比Nallapati等人(2016)多出(+4.07 ROUGE-1, +3.98 ROUGE-2, +3.73 ROUGE-L)分,可以估计,比之前唯一的抽象系统至少多出2个ROUGE点。

尽管覆盖训练阶段很短(约占总训练时间的1%),但重复问题几乎完全消除了,这可以从定性(图1)和定量(图4)上看到。然而,我们最好的模型并没有完全超过lead-3基线的ROUGE分数,也不是目前最好的提取模型(Nallapati et al., 2017)。
实验效果

蓝色的字体表示的是参考摘要,三个模型的生成摘要的结果差别挺大;
红色字体表明了不准确的摘要细节生成(UNK未登录词,无法解决OOV问题);
绿色的字体表明了模型生成了重复文本。















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











