







中药垂直大模型汇总
2023
ShenNong-TCM

Paper: ShenNong-TCM: A Traditional Chinese Medicine Large Language Model
Data: https://huggingface.co/datasets/michaelwzhu/ShenNong_TCM_Dataset
Code:https://github.com/michael-wzhu/ShenNong-TCM-LLM
ShenNong-TCM由华东师范大学计算机科学与技术学院智能知识管理与服务团队完成,旨在推动大型语言模型在中医药领域的发展和落地,提升大型语言模型的在中医药方面的知识与回答医学咨询的能力,同时推动大模型赋能中医药传承。
BenTsao

Paper: https://ar5iv.labs.arxiv.org/html/2304.06975
Code: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
Data: 未开源;原始来源:知识图谱数据: https://github.com/king-yyf/CMeKG_tools
本草大模型由哈尔滨工业大学社会计算与信息检索研究中心健康智能组合作研发。项目开源了经过中文医学指令精调/指令微调的大语言模型集,包括LLaMA、Alpaca-Chinese、Bloom、活字模型等。基于医学知识图谱以及医学文献,结合ChatGPT API构建了中文医学指令微调数据集,并以此对各种基模型进行了指令微调,提高了基模型在医疗领域的问答效果。
TCMLLM
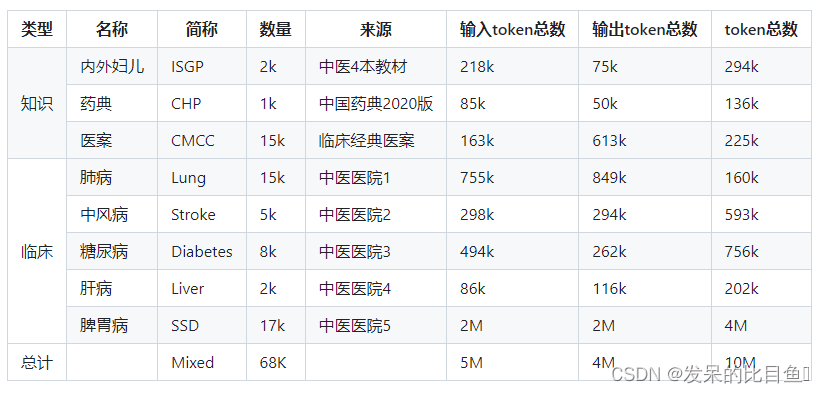
由北京交通大学计算机与信息技术学院医学智能团队开发的中医药大语言模型项目(TCMLLM)拟通过大模型方式实现中医临床辅助诊疗(病证诊断、处方推荐等)中医药知识问答等任务,推动中医知识问答、临床辅助诊疗等领域的快速发展。目前针对中医临床智能诊疗问题中的处方推荐任务,发布了中医处方推荐指令微调大模型TCMLLM-PR。研发团队整合了8个数据来源,涵盖4本中医经典教科书《中医内科学》、《中医外科学》、《中医妇科学》和《中医儿科学》、2020版中国药典、中医临床经典医案数据、以及多个三甲医院的涵盖肺病、中风病、糖尿病、肝病、脾胃病等多病种的临床病历数据,构建了包含68k数据条目(共10M token)的处方推荐指令微调数据集,并使用此数据集,在ChatGLM大模型上进行大规模指令微调,最终得到了中医处方推荐大模型TCMLLM-PR。
Paper
Data:
Code:https://github.com/2020MEAI/TCMLLM
HHuangDi
Paper: https://www.cnki.com.cn/Article/CJFDTotal-TSGL20240123001.htm
Code:https://github.com/Zlasejd/HuangDI
Data: https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
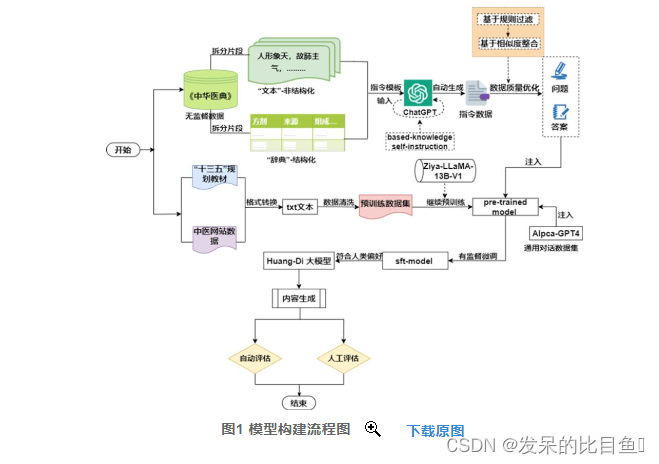
在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库,训练出一个具有中医知识理解力的预训练语言模型(pre-trained model),之后在此基础上通过海量的中医古籍指令对话数据及通用指令数据进行有监督微调(SFT),使得模型具备中医古籍知识问答能力。
TCM-GPT
Paper: https://arxiv.org/abs/2311.01786
Code:
Data:
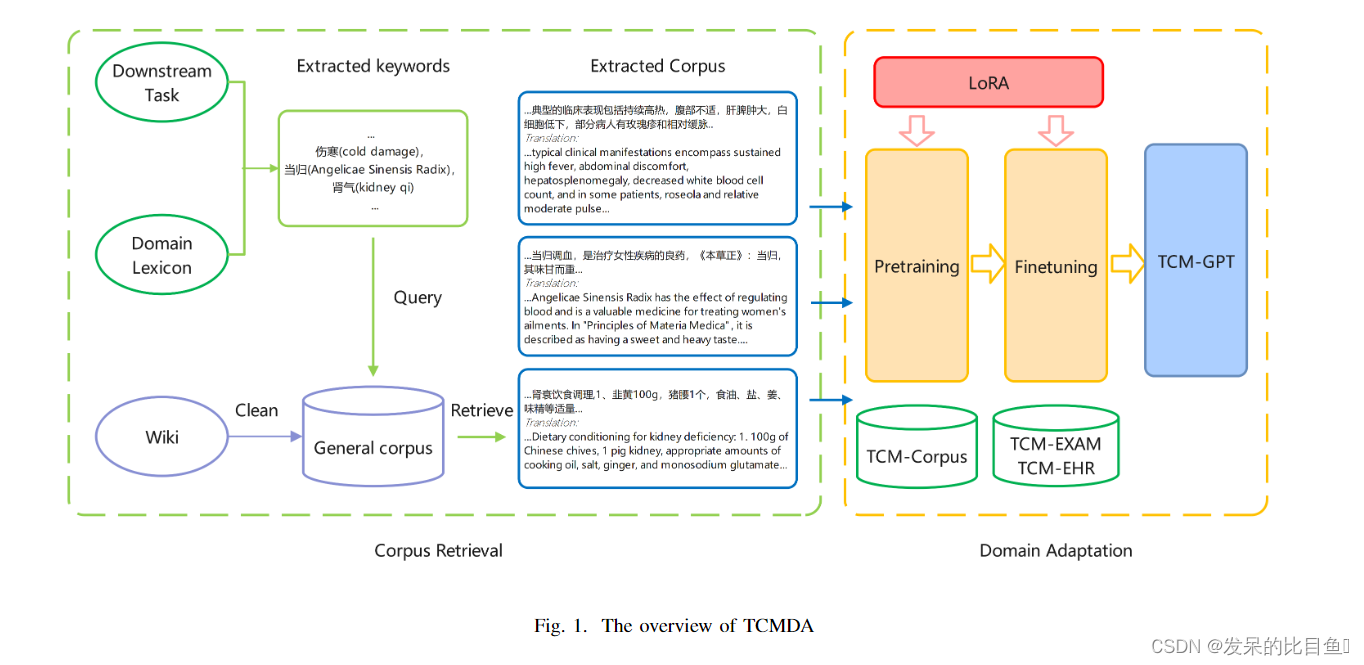
由北京邮电大学团队研发,该论文提出了一种新颖的面向传统中医领域的自适应预训练方法TCMDA。通过构建大规模特定领域的中医语料库TCM-Corpus-1B,并使用LoRA技术对特定领域进行高效的预训练和微调,从而有效应用于中医领域。在中医考试和中医诊断两个任务上,TCM-GPT-7B模型相对于其他模型分别提高了17%和12%的准确率,表现最好。该研究成功验证了在中医领域中使用70亿参数的大规模语言模型进行领域自适应的先驱性工作。
2024
Qibo
Paper:https://arxiv.org/pdf/2403.16056
GitHub:
Dataset:
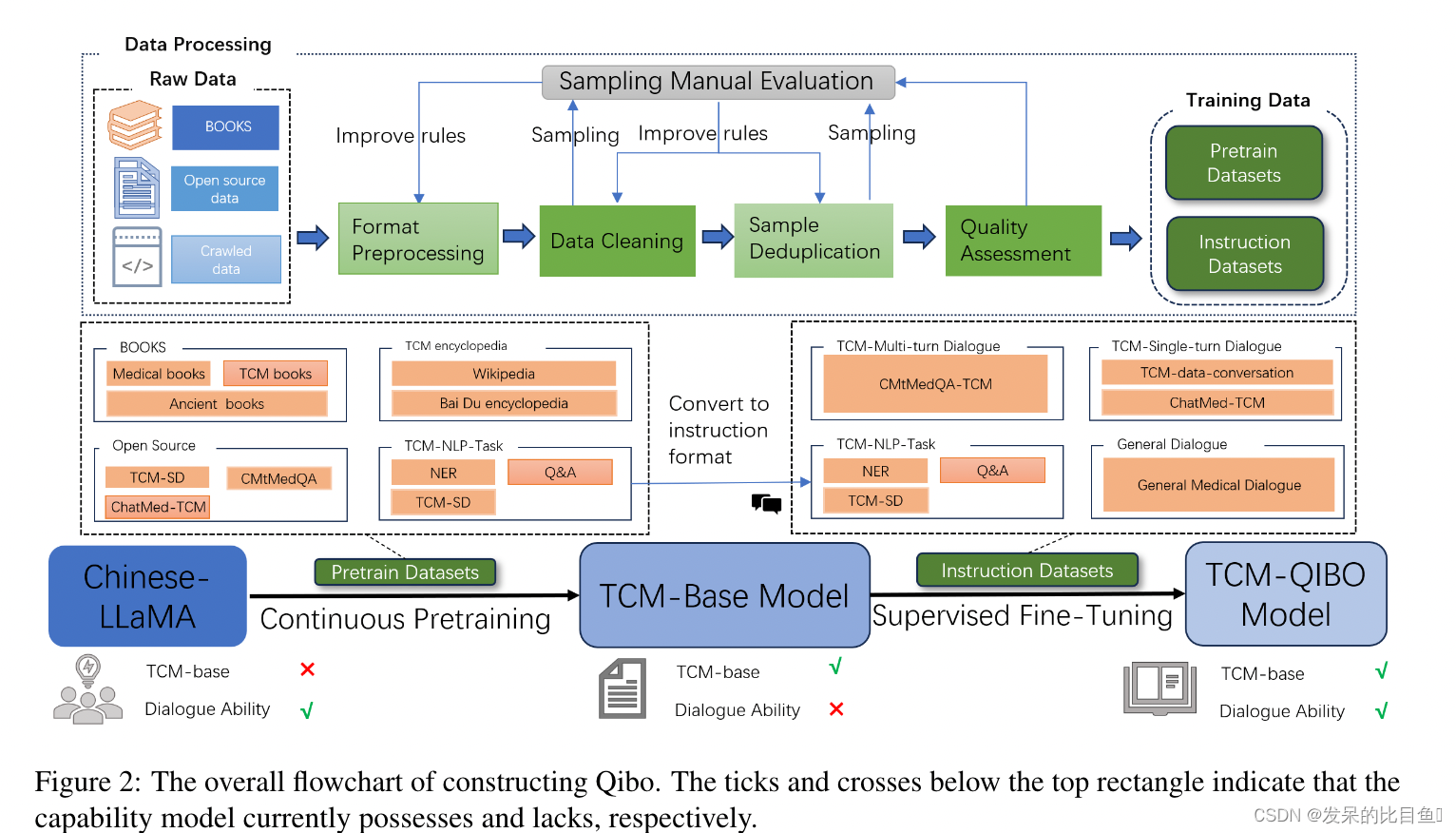
Qibo由天津中医药团队完成, 主要以中医药领域的教科书为基础,构建了中医药领域的评估基准,并提供了不同科目的客观选择题,以评估中医药领域的基本知识能力,此外还验证了中药的识别能力,以及阅读和理解中药的能力, 中药辩证的能力,以及使用 GPT-4 来评估其答案的专业性、安全性和流畅性。
MedChatZH
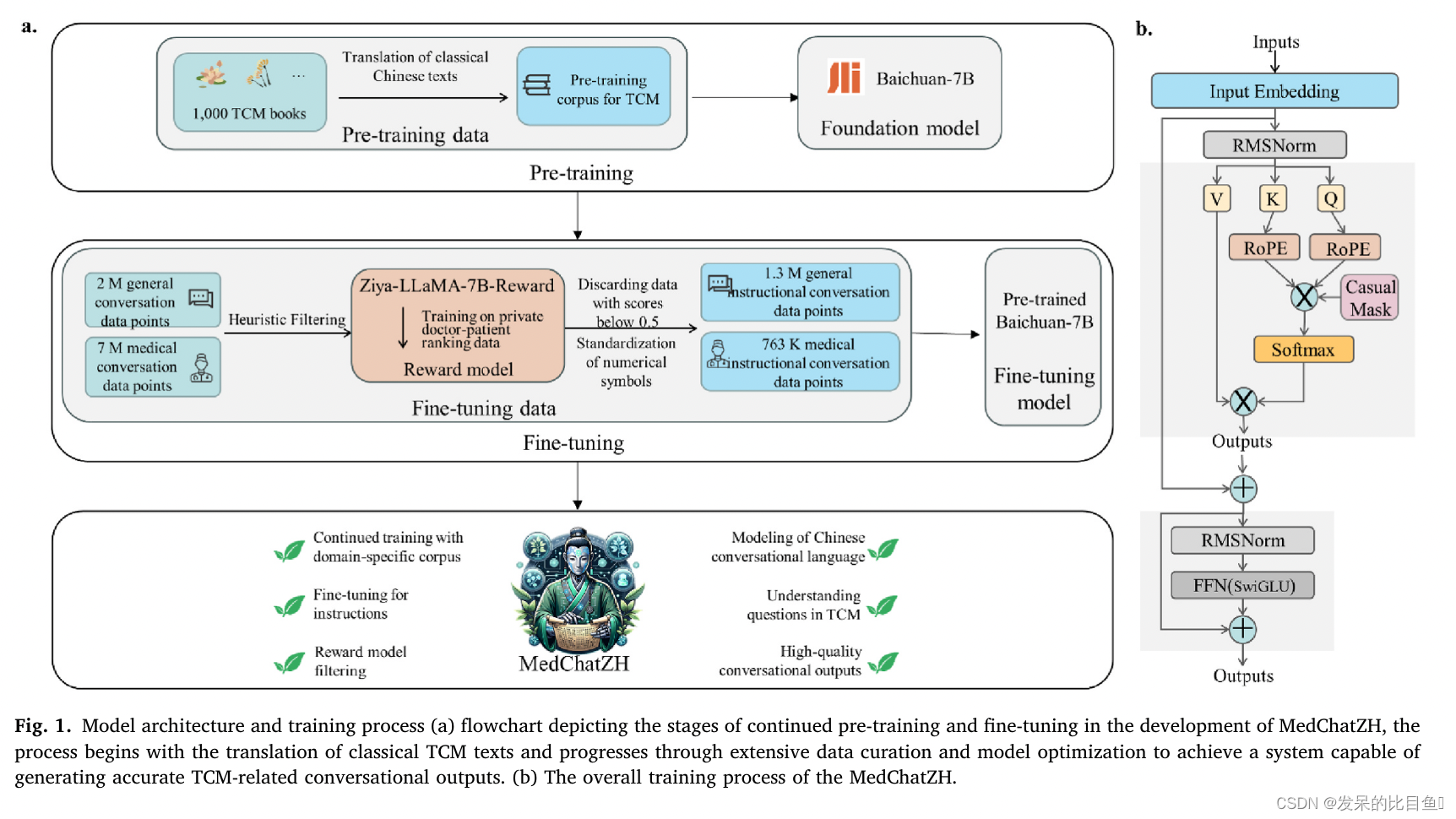
Paper:https://www.sciencedirect.com/science/article/abs/pii/S0010482524003743
GitHub: https://github.com/tyang816/MedChatZH
Dataset:https://huggingface.co/tyang816/MedChatZH
- 收集并整理大量中医文本形成预训练语料库,构建通用对话与医学对话相结合的高质量数据集。该数据集经过启发式和基于奖励的评估,以过滤掉敏感信息和低质量的口语回答。
- 从互联网和中国各医院收集了超过 700 万条医疗质量保证指令。
- 评估 MedChatZH 在真实世界的中国医学 QA 基准数据集上的性能,证明其在多个评估指标上优于其他基线模型。
BianCang-TCM-LLM
Paper:
Code: https://github.com/QLU-NLP/BianCang-TCM-LLM?tab=readme-ov-file
Data:
扁仓中医大模型的训练数据包含两部分:
- (1)中医药指令数据集 (2)由心内科病历构建的中医辅助诊断数据集(将在未来开源)。
- 扁仓中医大模型以阿里通义千问Qwen-7B-Chat为底座,采用全参微调得到。
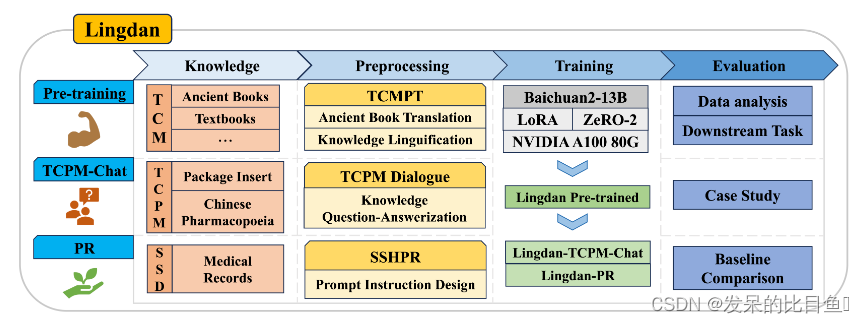
LingdanLLM
 、
、
Paper:
Code: https://github.com/TCMAI-BJTU/LingdanLLM
Data: https://github.com/TCMAI-BJTU/LingdanLLM/blob/main/data
本项目旨在通过继续对百川2号模型进行预训练。训练数据集包括中医古籍、教科书和中国药典。这一过程不仅增强了模型对中医知识的理解,也为其深入掌握中医理论和实践提供了坚实的基础
其他相关数据集
TCM-SD 中医领域辨证数据集(/data/中医辨证数据集.zip)
中医治疗新冠流感支原体感染等有效病历集(/data/新冠、流感、支原体中医有效数据集.json)
中医文献问题生成数据集(/data/中医文献问题生成数据集.json)
参考
https://zhuanlan.zhihu.com/p/669025474?utm_id=0



















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











