







2020-AAAI-ASAP : Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations

ASAP:用于学习分层图表示的自适应结构感知池
作者提出了ASAP(自适应结构感知池化),这是一种稀疏且可微分的池化方法,解决了以前图形池化架构的局限性。ASAP利用新颖的自我注意网络以及修改的GNN(LeConv)公式来捕获给定图中每个节点的重要性。它还学习每层节点的稀疏软集群分配,以有效地池化子图以形成池化图。实验结果表明,将现有的GNN架构与ASAP相结合,可以在多个图分类基准上获得最先进的结果。与当前稀疏分层的最新方法相比,ASAP的平均改进率为4%。
模型
如图1(b)所示,ASAP最初考虑给定输入图具有固定感受野的所有可能的局部簇。然后,它使用注意机制计算节点的群集成员。然后使用GNN对这些集群进行评分,如图1(c)所示。此外,得分最高的集群中的一小部分被选为合并图中的节点,并在相邻集群之间计算新的边缘权重,如图1(d)所示。
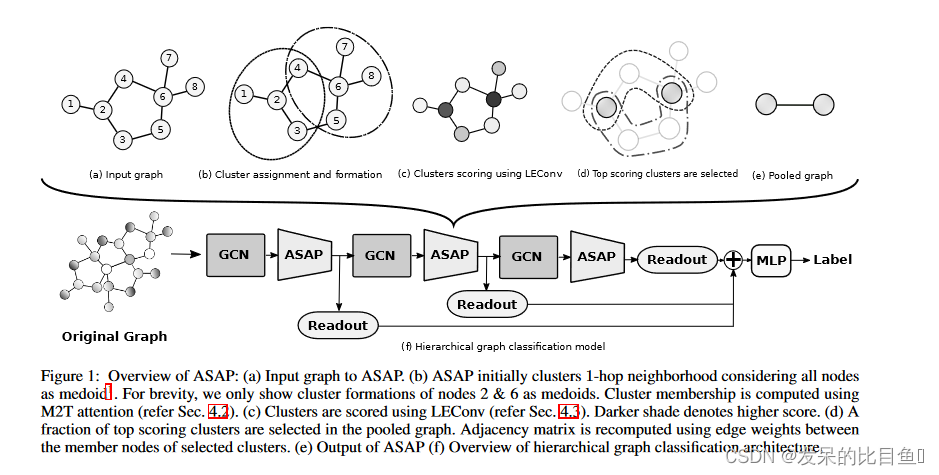
群集分配
首先,将图中的每个节点 v i v_i vi 视为聚类 c h ( v i ) c_h(v_i) ch(vi) 的中心点,使得每个聚类只能表示 h h h 跳的固定半径内的局部邻居 N N N,即 c h ( v i ) = N h ( v i ) c_h(v_i) = N_h(v_i) ch(vi)=Nh(vi)。设 x i c x^c_i xic 是以 v i v_i vi 为中心的聚类 c h ( v i ) c_h(v_i) ch(vi) 的特征表示。将 G c ( V , E , X c ) G^c(V,E,X^c) Gc(V,E,Xc)定义为具有节点特征矩阵 X c ∈ R N × d X^c \in R^{N×d} Xc∈RN×d和邻接矩阵 A c = A A^c=A Ac=A的图。用 S ∈ R N × N S \in R^{N×N} S∈RN×N 表示集群分配矩阵,其中 S i , j S_{i,j} Si,j 表示集群 c h ( v j ) c_h(v_j) ch(vj) 中节点 v i ∈ V v_i \in V vi∈V 的成员资格。保持集群分配矩阵 S S S 的稀疏性,类似于原始图邻接矩阵 A A A,即 S S S 和 A A A 的空间复杂度均为 O ( ∣ E ∣ ) O(|E|) O(∣E∣)。
使用 Master2Token 形成集群
给定一个聚类
c
h
(
v
i
)
c_h(v_i)
ch(vi),作者通过自我注意机制学习聚类赋值矩阵
S
S
S。任务是通过关注集群中的相关节点来学习集群
c
h
(
v
i
)
c_h(v_i)
ch(vi)的整体表示。作者提出了一种新的自注意力变体,称为Master2Token(M2T)。在 M2T 框架中,首先创建一个主查询
m
i
∈
R
d
m_i \in R^d
mi∈Rd,它代表集群中的所有节点:
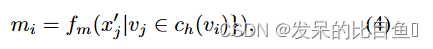
其中
x
′
j
x′_j
x′j 是在通过单独的 GCN 通过
x
j
x_j
xj 以捕获簇
c
h
(
v
i
)
c_h(v_i)
ch(vi) 中的结构信息后获得的。
f
m
f_m
fm是一个主函数,它组合和转换
v
j
∈
c
h
(
v
i
)
v_j \in c_h(v_i)
vj∈ch(vi)的特征表示以找到
m
i
m_i
mi。在这项工作中,作者尝试了最大主函数,定义为
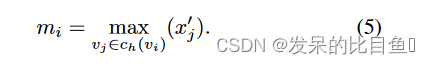
m
i
m_i
mi使用加法关注所有组成节点
v
j
∈
c
h
(
v
i
)
v_j \in c_h(v_i)
vj∈ch(vi)。
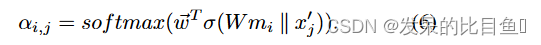
其中
w
⃗
T
\vec{w}^T
wT 和
W
W
W 分别是可学习向量和矩阵。计算出的注意力得分
α
i
,
j
α_{i,j}
αi,j表示聚类
c
h
(
v
i
)
c_h(v_i)
ch(vi)中节点
v
j
v_j
vj的成员强度。因此,作者使用此分数来定义上面讨论的聚类分配矩阵,即
S
i
,
j
=
α
i
,
j
S_{i,j} = α_{i,j}
Si,j=αi,j。
c
h
(
v
i
)
c_h(v_i)
ch(vi) 的聚类表示
x
i
c
x^c_i
xic 计算如下:
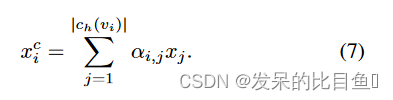
使用 LEConv 进行集群选择
我们使用适应度函数
f
φ
f_φ
fφ (类似TopK方法)根据图中
G
c
G^c
Gc 中每个聚类计算的聚类适应度分数
φ
i
φ_i
φi 对聚类进行采样。对于给定的池化比率
k
∈
(
0
,
1
]
k \in(0,1]
k∈(0,1],选择顶部的
[
k
N
]
[kN]
[kN] 簇并将其包含在池化图
G
p
G^p
Gp 中。为了计算适应度分数,作者引入了局部极值卷积(LEConv),这是一种可以捕获局部极值信息的图卷积方法。LEConv 用于计算
φ
φ
φ,如下所示:
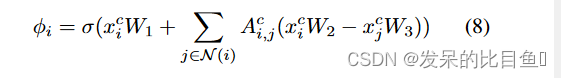
其中
N
(
i
)
N(i)
N(i) 表示
G
c
G^c
Gc 中第 i 个节点的邻域,
W
1
W_1
W1、
W
2
W_2
W2、
W
3
W_3
W3 是可学习的参数,
σ
(
.
)
σ(.)
σ(.) 是某个激活函数。适应度向量
Φ
=
[
φ
1
,
φ
2
,
.
.
.
,
φ
N
]
T
Φ = [φ_1, φ_2, ..., φ_N ]^T
Φ=[φ1,φ2,...,φN]T 乘以聚类特征矩阵
X
c
X^c
Xc 以使
f
φ
f_φ
fφ 可学习,即:

其中,
⊙
\odot
⊙是broadcasted hadamard product。函数
T
O
P
k
(
.
)
TOPk(.)
TOPk(.) 对适应度分数进行排序,并给出
G
c
G^c
Gc 中前
[
k
N
]
[kN]
[kN] 个选定簇的索引
i
^
\hat{i}
i^ ,如下所示:
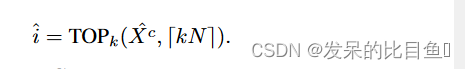
池化图
G
p
G^p
Gp 是通过选择这些顶部
[
k
N
]
[kN]
[kN] 簇形成的。修剪后的集群分配矩阵
S
∈
R
N
×
[
k
N
]
S \in R^{N×[kN]}
S∈RN×[kN] 和节点特征矩阵
X
p
∈
R
[
k
N
]
×
d
X^p \in R^{[kN]×d}
Xp∈R[kN]×d 由下式给出:
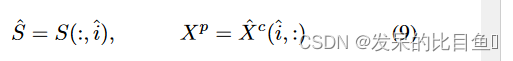
其中
i
^
\hat{i}
i^ 用于索引切片。
维护图连接
作者通过以下方式使用
S
^
\hat{S}
S^ 和
A
^
c
\hat{A}^c
A^c 找到合并图
G
p
G^p
Gp 的新邻接矩阵
A
p
A^p
Ap:

其中
A
^
c
=
A
c
+
I
\hat{A}^c = A^c + I
A^c=Ac+I。
A
i
,
j
p
=
∑
k
,
l
S
^
k
,
i
A
^
k
,
l
c
S
^
l
,
j
A^p_{i,j} = \sum_{k,l} \hat{S}_{k,i} \hat{A}^c_{k,l}\hat{S}_{l,j}
Ai,jp=∑k,lS^k,iA^k,lcS^l,j如果集群
c
h
(
v
i
)
c_h(v_i)
ch(vi) 和
c
h
(
v
j
)
c_h(v_j)
ch(vj) 中有任何公共节点,或者如果集群中的任何组成节点是原始图
G
G
G 中的邻居,则此公式确保
G
p
G^p
Gp 中的任何两个集群
i
i
i 和
j
j
j 是连接的(图 1(d))。因此,簇之间的连接强度由组成节点的成员关系通过
S
^
\hat{S}
S^ 和边权重
A
c
A^c
Ac 决定。请注意,
S
^
\hat{S}
S^ 是一个稀疏矩阵,因此可以有效地实现上述操作。
实验
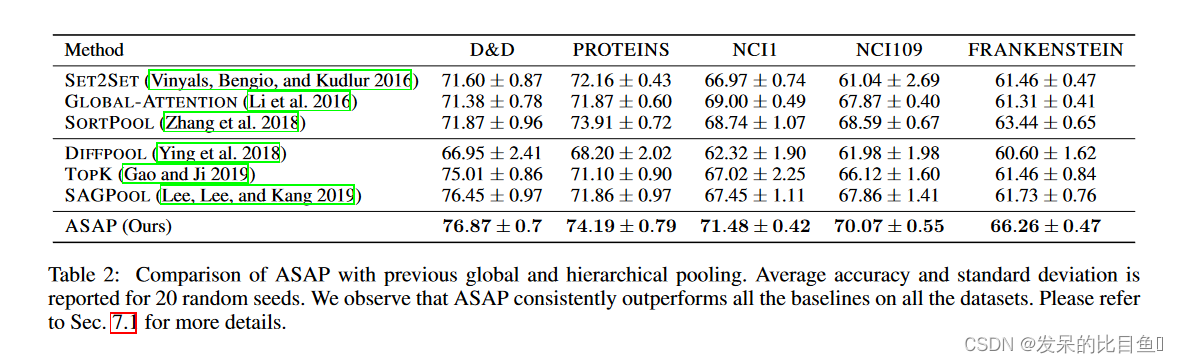
该论文对比了我们上面提到的几种典型的全局池化方法和层次化池化方法,从外部比较结果来看,ASAP方法具有明显的效果提升。结果如下表:
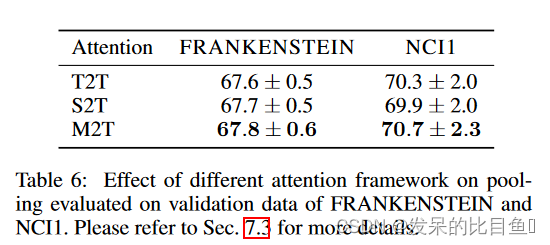
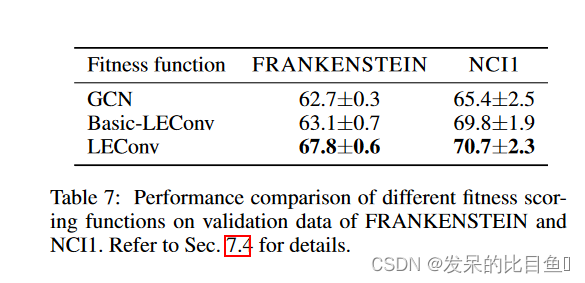
此外,该论文也分别设计了消融实验来分析其设计的自注意力方法Master2Token和GCN方法LEConv的有效性,结果分别如下面两表。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











