







小白学Pytorch系列–Torch.nn API Loss Functions(14)

| 方法 | 注释 |
|---|---|
| nn.L1Loss | 创建一个标准,用于测量输入x和目标y中每个元素之间的平均绝对误差(MAE) |
| nn.MSELoss | 创建一个标准,测量输入x和目标y中每个元素之间的均方误差(L2范数的平方)。 |
| nn.CrossEntropyLoss | 该准则计算输入对数和目标之间的交叉熵损失。 |
| nn.CTCLoss | 联结主义时间分类丢失。 |
| nn.NLLLoss | 负对数似然损失。 |
| nn.PoissonNLLLoss | 目标泊松分布的负对数似然损失。 |
| nn.GaussianNLLLoss | 高斯负对数似然损失。 |
| nn.KLDivLoss | Kullback-Leibler散度损失。 |
| nn.BCELoss | 创建一个标准,测量目标和输入概率之间的二进制交叉熵 |
| nn.BCEWithLogitsLoss | 这种损失将Sigmoid层和BCELoss结合在一个类中。 |
| nn.MarginRankingLoss | 创建一个标准,用于测量给定输入x1、x2、两个1D小批量或0D张量以及一个标签1D小批次或0D Tensor y(包含1或-1)的损失。 |
| nn.HingeEmbeddingLoss | 测量给定输入张量x和标签张量y(包含1或-1)的损失。 |
| nn.MultiLabelMarginLoss | 创建一个标准,优化输入x(一个2D mini-batch Tensor)和输出y(一个目标类指标的2D Tensor)之间的多类多分类铰链损失(基于边缘的损失)。 |
| nn.HuberLoss | 创建一个标准,如果绝对元素误差低于delta,则使用平方项,否则使用delta缩放的L1项。 |
| nn.SmoothL1Loss | 创建一个标准,如果绝对元素误差低于β,则使用平方项,否则使用L1项。 |
| nn.SoftMarginLoss | 创建一个标准,优化输入张量x和目标张量y(包含1或-1)之间的两类分类逻辑损失。 |
| nn.MultiLabelSoftMarginLoss | 创建一个标准,该标准基于输入x和大小为(N,C)的目标y之间的最大熵来优化多标签一对一损失。 |
| nn.CosineEmbeddingLoss | 创建一个标准,测量给定输入张量x1,x2和值为1或-1的张量标签y的损失。 |
| nn.MultiMarginLoss | 创建一个标准,用于优化输入x(2D mini-batch张量)和输出y(它是目标类索引的1D张量,0≤y≤x.size(1)-1): |
| nn.TripletMarginLoss | 在给定输入张量x1,x2,x3和大于0的裕度的情况下,创建一个度量三元组损失的标准。 |
| nn.TripletMarginWithDistanceLoss | 创建一个标准,用于测量给定输入张量a、p和n(分别表示锚点、正数和负数)的三元组损失,以及用于计算锚点和正数之间关系的非负实数函数(“距离函数”)(“正距离”)以及锚点和反例(“负距离”)。 |
nn.L1Loss
功能: 计算输出y和真实标签target之间的差值的绝对值。
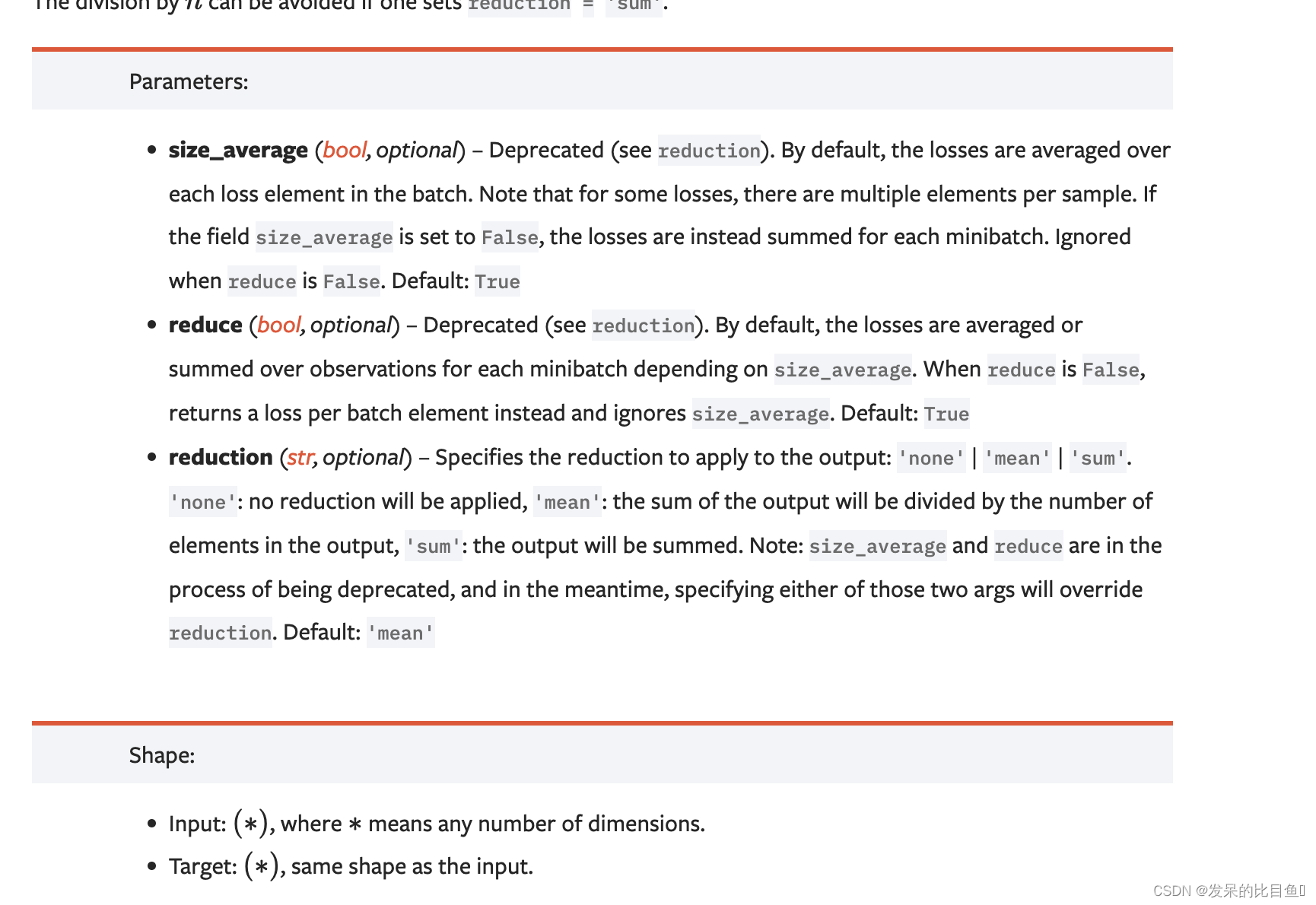
主要参数
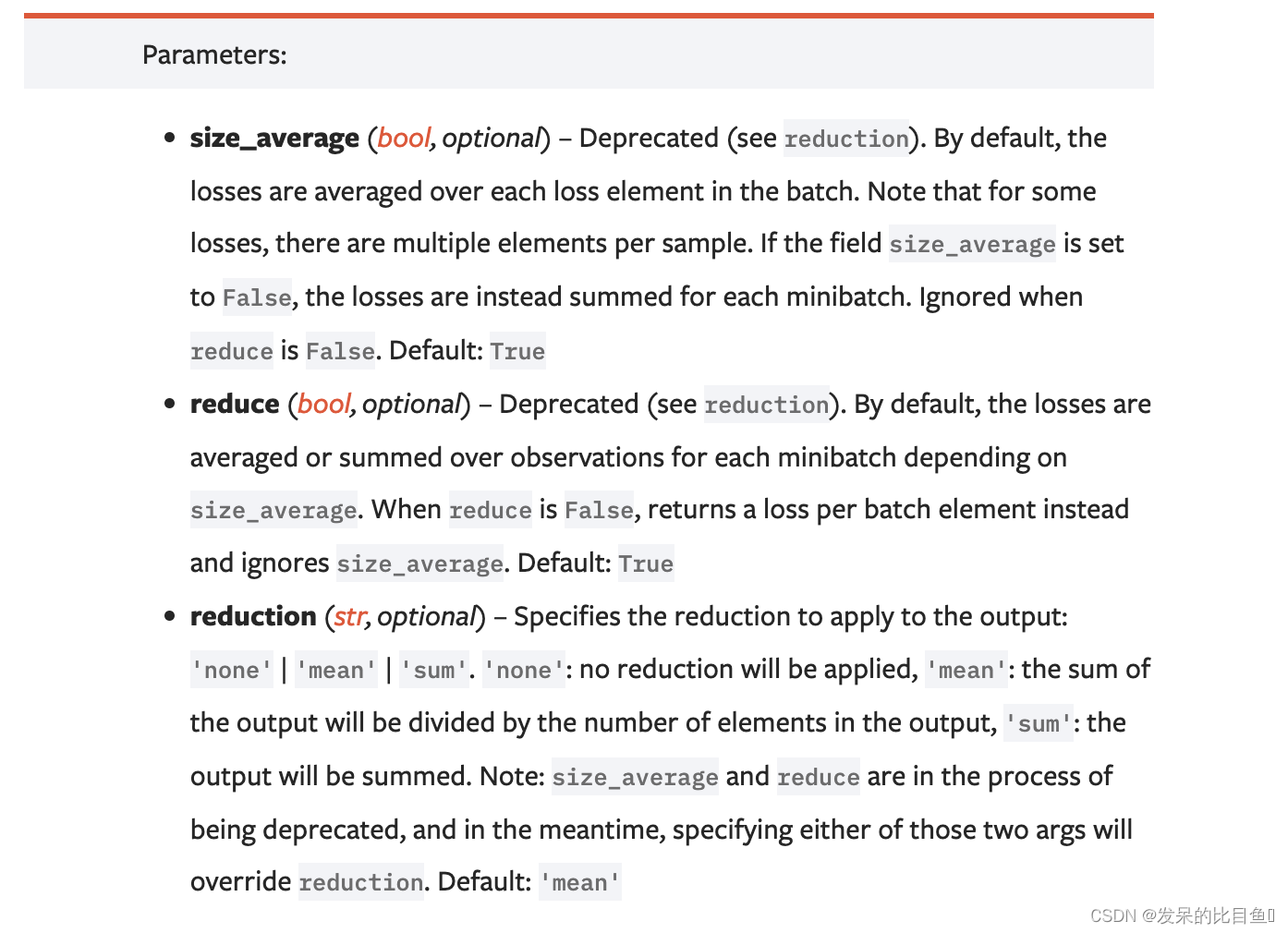
- reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。
- sum:所有元素求和,返回标量。
- mean:加权平均,返回标量。
如果选择none,那么返回的结果是和输入元素相同尺寸的。默认计算方式是求平均。
创建一个标准,用于测量输入x和目标y中每个元素之间的平均绝对误差(MAE)。


>>> loss = nn.L1Loss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
nn.MSELoss
功能: 计算输出y和真实标签target之差的平方。
和L1Loss一样,MSELoss损失函数中,reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。
sum:所有元素求和,返回标量。默认计算方式是求平均。
创建一个标准,测量输入x和目标y中每个元素之间的均方误差(L2范数的平方)。

>>> loss = nn.MSELoss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
nn.CrossEntropyLoss
功能: 计算交叉熵函数
主要参数:
- weight:每个类别的loss设置权值。
- size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
- ignore_index:忽略某个类的损失函数。
- reduce:数据类型为bool,为True时,loss的返回是标量。
该准则计算输入对数和目标之间的交叉熵损失。
它在用C类训练分类问题时很有用。如果提供,可选参数weight应该是一个1D张量,为每个类分配权重。当你有一个不平衡的训练集时,这是特别有用的。
输入应包含每个类的未规范化logits(通常不需要为正或求和为1)。输入必须是大小为(C)的张量,用于未缓冲输入,(minibatch, C)或(minibath, C,
d
1
d_1
d1,
d
2
d_2
d2,…,
d
K
d_K
dK),其中K≥1用于K维情况。最后一个对于更高维度的输入是有用的,例如计算2D图像的每个像素的交叉熵损失。
该标准期望的目标应该包含其中之一




logits = torch.randn(3, 5) # [bz, num_class]
target = torch.tensor([1, 4, 3])
num_label = 5
one_target = torch.nn.functional.one_hot(target, num_classes=5)
### one -hot 版本
loss_func = nn.CrossEntropyLoss()
one_hot_loss = loss_func(input, one_target.float())
one_hot_loss
### num_class版本
cross_loss = loss_func(input, target)
cross_loss
手动书写

output = torch.empty(input.size(0), dtype=torch.float32)
for i in range(input.size(0)):
output[i] = - (one_target[i]*input[i]).sum() + torch.log(torch.exp(input[i]).sum())
output.mean()
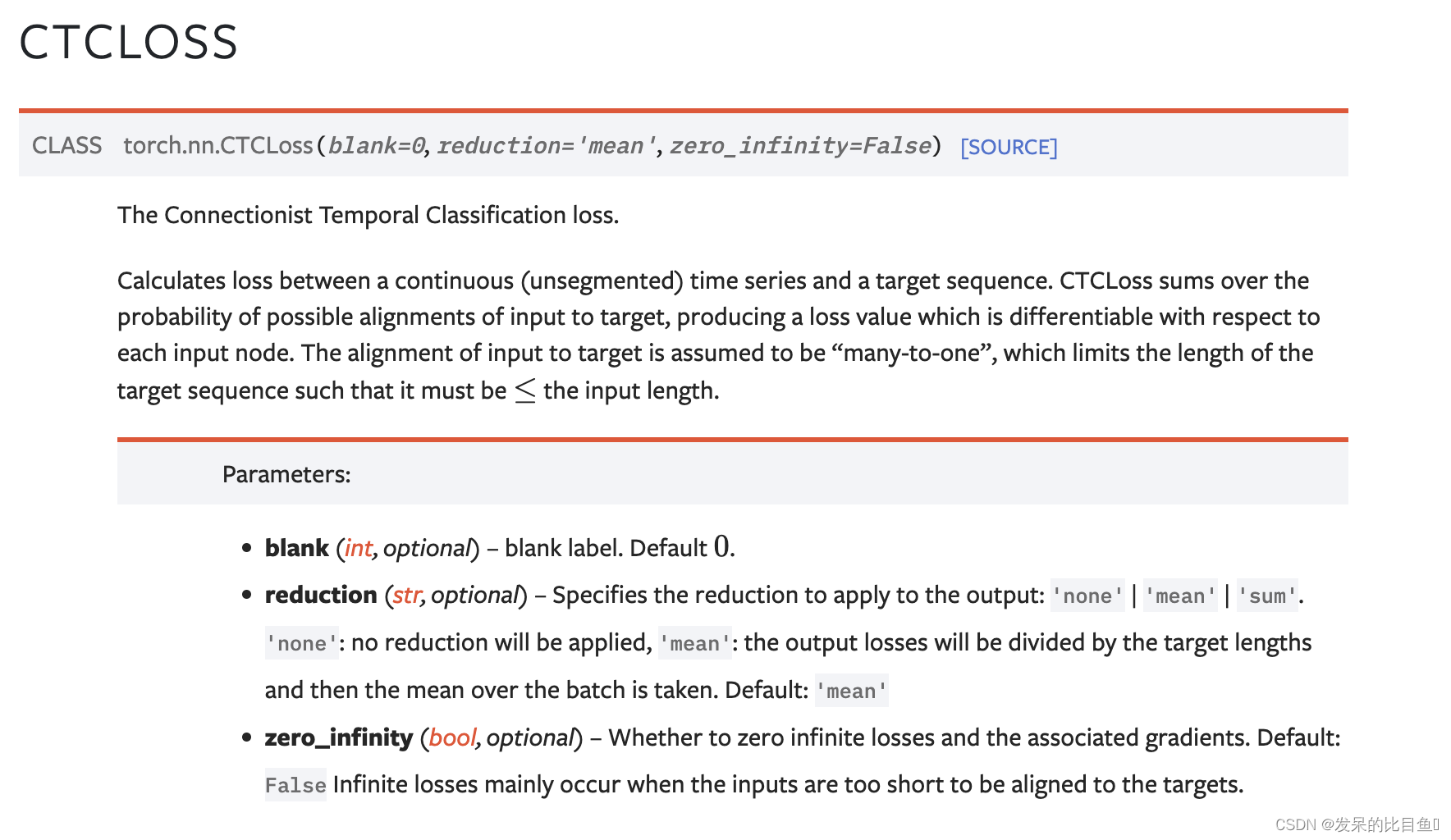
nn.CTCLoss
功能: 用于解决时序类数据的分类
计算连续时间序列和目标序列之间的损失。CTCLoss对输入和目标的可能排列的概率进行求和,产生一个损失值,这个损失值对每个输入节点来说是可分的。输入与目标的对齐方式被假定为 “多对一”,这就限制了目标序列的长度,使其必须是≤输入长度。
主要参数:
- reduction:计算模式,可为 none/sum/mean。
- blank:blank label。
- zero_infinity:无穷大的值或梯度值为

>>> # Target are to be padded
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>> N = 16 # Batch size
>>> S = 30 # Target sequence length of longest target in batch (padding length)
>>> S_min = 10 # Minimum target length, for demonstration purposes
>>>
>>> # Initialize random batch of input vectors, for *size = (T,N,C)
>>> input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
>>>
>>> input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
>>> target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
>>>
>>>
>>> # Target are to be un-padded
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>> N = 16 # Batch size
>>>
>>> # Initialize random batch of input vectors, for *size = (T,N,C)
>>> input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
>>> input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target_lengths = torch.randint(low=1, high=T, size=(N,), dtype=torch.long)
>>> target = torch.randint(low=1, high=C, size=(sum(target_lengths),), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
>>>
>>>
>>> # Target are to be un-padded and unbatched (effectively N=1)
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>>
>>> # Initialize random batch of input vectors, for *size = (T,C)
>>> input = torch.randn(T, C).log_softmax(2).detach().requires_grad_()
>>> input_lengths = torch.tensor(T, dtype=torch.long)
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target_lengths = torch.randint(low=1, high=T, size=(), dtype=torch.long)
>>> target = torch.randint(low=1, high=C, size=(target_lengths,), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
nn.NLLLoss
负对数似然损失。用C类训练分类问题是很有用的。
如果提供,可选参数weight应该是一个1D张量,为每个类分配权重。当你有一个不平衡的训练集时,这是特别有用的。



>>> m = nn.LogSoftmax(dim=1)
>>> loss = nn.NLLLoss()
>>> # input is of size N x C = 3 x 5
>>> input = torch.randn(3, 5, requires_grad=True)
>>> # each element in target has to have 0 <= value < C
>>> target = torch.tensor([1, 0, 4])
>>> output = loss(m(input), target)
## 或者
logits = torch.randn(3, 5, requires_grad=True)
ls = nn.Softmax()
input = torch.log(ls(logits))
print(input.shape)
output = loss(input, target)
output
>>> output.backward()
>>>
>>>
>>> # 2D loss example (used, for example, with image inputs)
>>> N, C = 5, 4
>>> loss = nn.NLLLoss()
>>> # input is of size N x C x height x width
>>> data = torch.randn(N, 16, 10, 10)
>>> conv = nn.Conv2d(16, C, (3, 3))
>>> m = nn.LogSoftmax(dim=1)
>>> # each element in target has to have 0 <= value < C
>>> target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C)
>>> output = loss(m(conv(data)), target)
>>> output.backward()
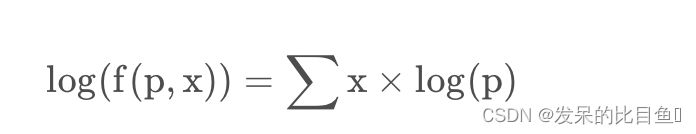
手写Nllloss
output = torch.empty(input.size(0))
one_target = F.one_hot(target, 5)
for i in range(input.size(0)):
output[i] = (input[i]*one_target[i]).sum()
output.mean()
nn.PoissonNLLLoss
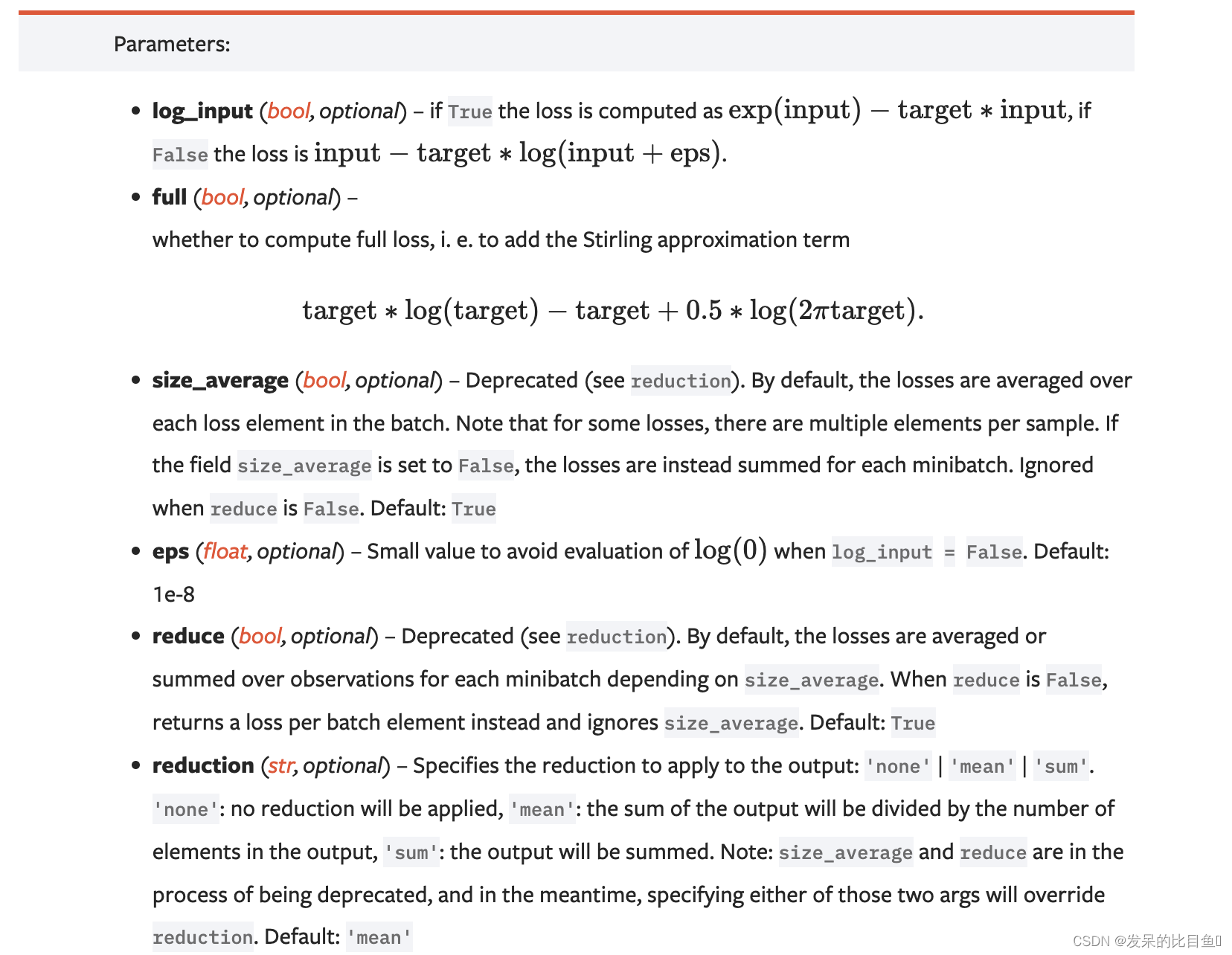
功能: 泊松分布的负对数似然损失函数
主要参数:
- log_input:输入是否为对数形式,决定计算公式。
- full:计算所有 loss,默认为 False。
- eps:修正项,避免 input 为 0 时,log(input) 为 nan 的情况。


>>> loss = nn.PoissonNLLLoss()
>>> log_input = torch.randn(5, 2, requires_grad=True)
>>> target = torch.randn(5, 2)
>>> output = loss(log_input, target)
>>> output.backward()
nn.GaussianNLLLoss


>>> loss = nn.GaussianNLLLoss()
>>> input = torch.randn(5, 2, requires_grad=True)
>>> target = torch.randn(5, 2)
>>> var = torch.ones(5, 2, requires_grad=True) # heteroscedastic
>>> output = loss(input, target, var)
>>> output.backward()
>>> loss = nn.GaussianNLLLoss()
>>> input = torch.randn(5, 2, requires_grad=True)
>>> target = torch.randn(5, 2)
>>> var = torch.ones(5, 1, requires_grad=True) # homoscedastic
>>> output = loss(input, target, var)
>>> output.backward()
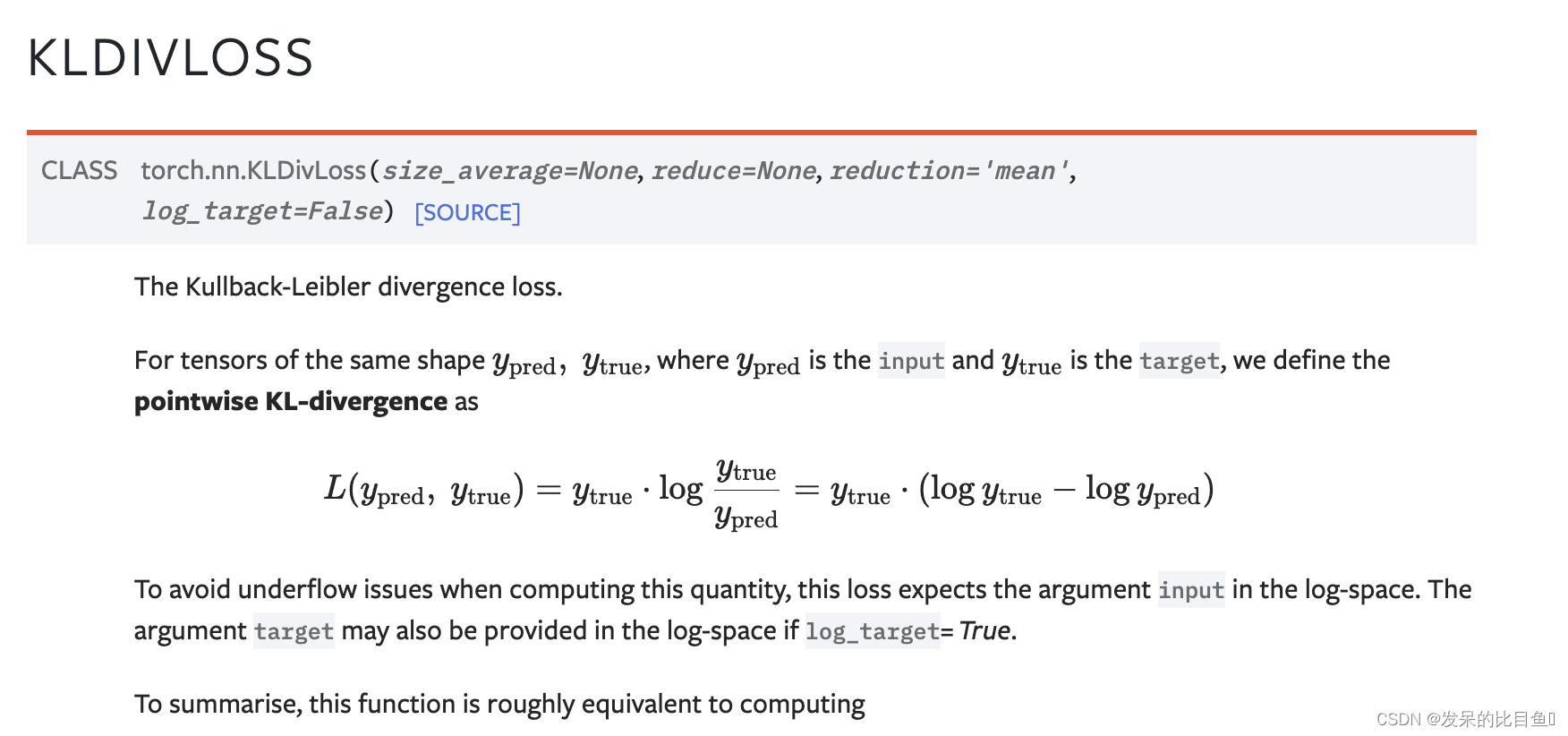
nn.KLDivLoss
功能: 计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
主要参数:
- reduction:计算模式,可为 none/sum/mean/batchmean。
- none:逐个元素计算。
- sum:所有元素求和,返回标量。
- mean:加权平均,返回标量。
- batchmean:batchsize 维度求平均值。
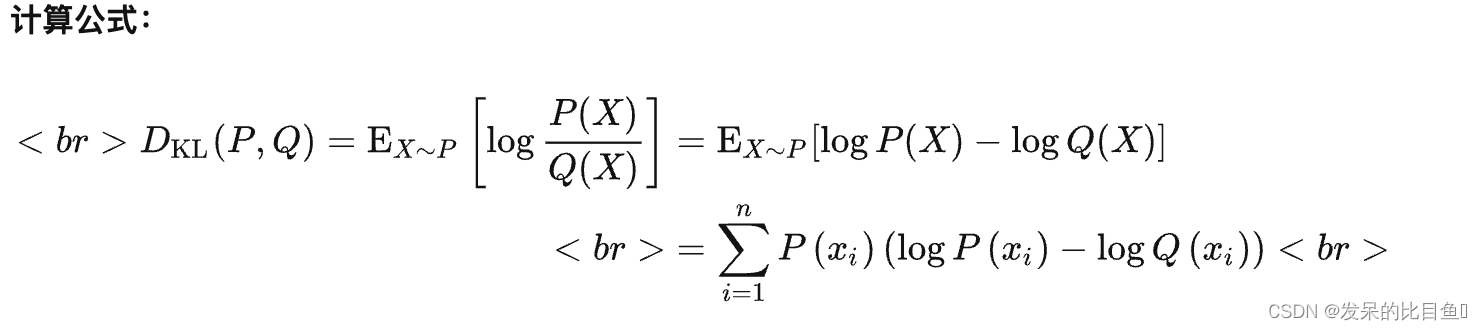


>>> import torch.nn.functional as F
>>> kl_loss = nn.KLDivLoss(reduction="batchmean")
>>> # input should be a distribution in the log space
>>> input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
>>> # Sample a batch of distributions. Usually this would come from the dataset
>>> target = F.softmax(torch.rand(3, 5), dim=1)
>>> output = kl_loss(input, target)
>>> kl_loss = nn.KLDivLoss(reduction="batchmean", log_target=True)
>>> log_target = F.log_softmax(torch.rand(3, 5), dim=1)
>>> output = kl_loss(input, log_target)
nn.BCELoss
功能:计算二分类任务时的交叉熵(Cross Entropy)函数。在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
主要参数:
- weight:每个类别的loss设置权值
- size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
- reduce:数据类型为bool,为True时,loss的返回是标量。
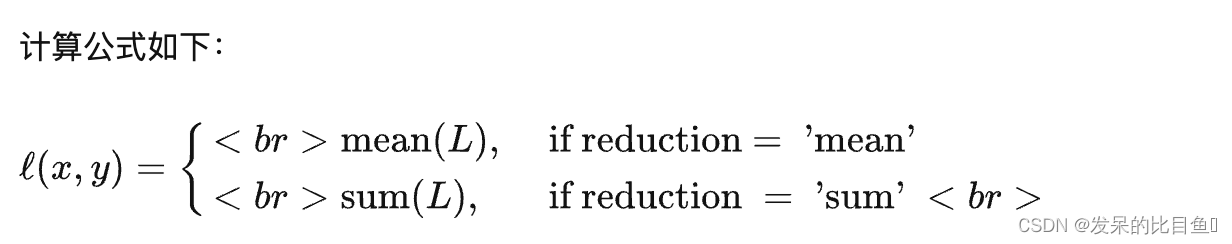



>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(m(input
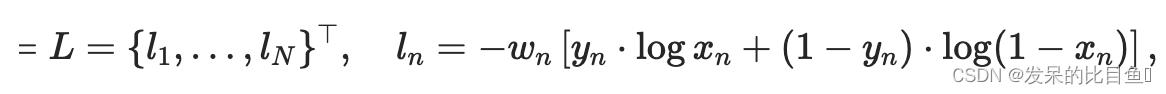
自定义
input = torch.randn(3)
target = torch.empty(3).random_(2)
m = nn.Sigmoid()
output = torch.empty(input.size(0))
sigmod_input = m(input)
for i in range(input.size(0)):
output[i] = -(target[i]*torch.log(sigmod_input[i]) + (1-target[i])*torch.log((1-sigmod_input[i])))
output.mean()
nn.BCEWithLogitsLoss


>>> target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10
>>> output = torch.full([10, 64], 1.5) # A prediction (logit)
>>> pos_weight = torch.ones([64]) # All weights are equal to 1
>>> criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight)
>>> criterion(output, target) # -log(sigmoid(1.5))
tensor(0.20...)

>>> loss = nn.BCEWithLogitsLoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(input,
nn.MarginRankingLoss
功能: 计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
主要参数:
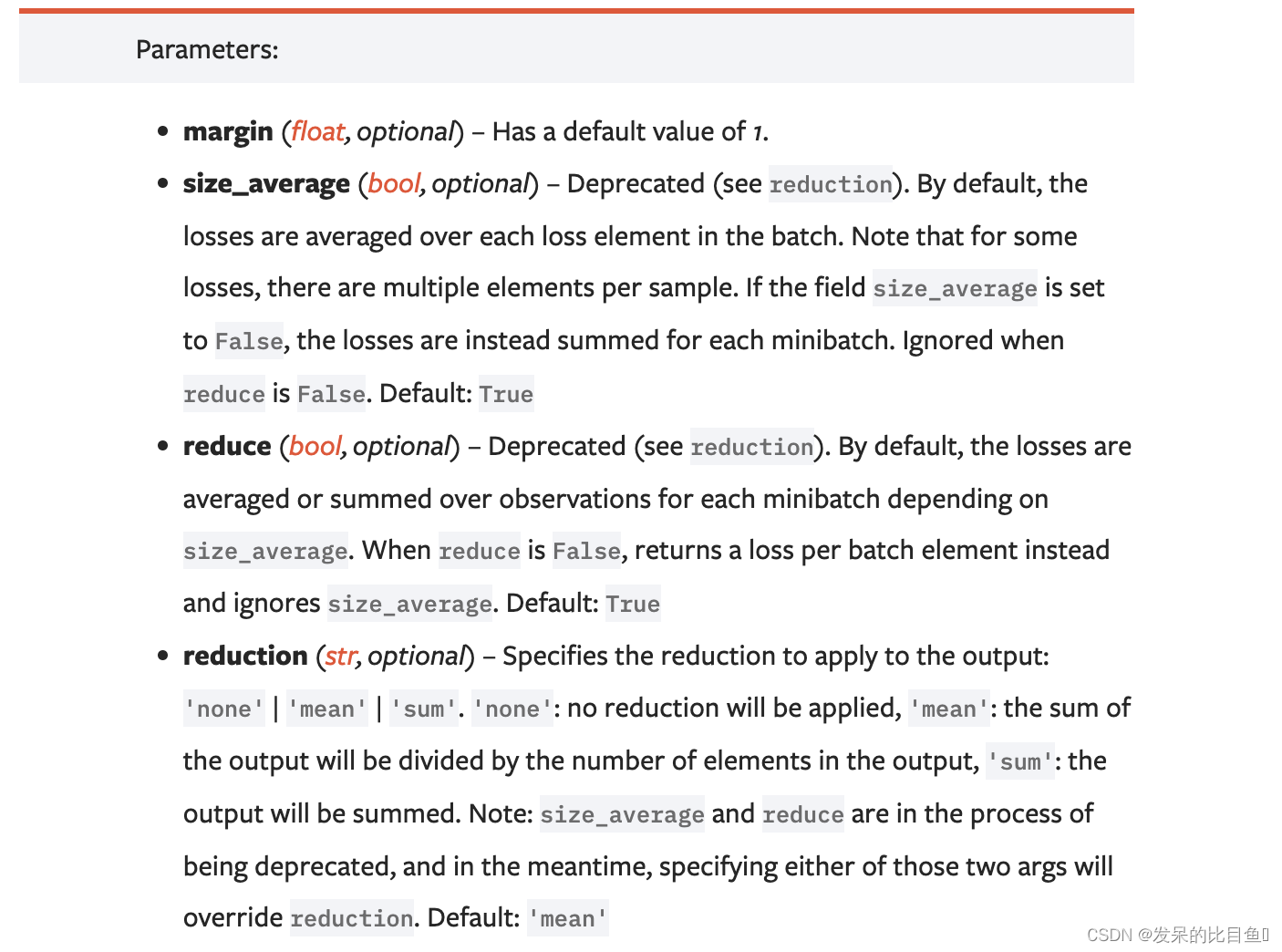
- margin:边界值, x 1 x_{1} x1与 x 2 x_{2} x2 之间的差异值。
- reduction:计算模式,可为 none/sum/mean。
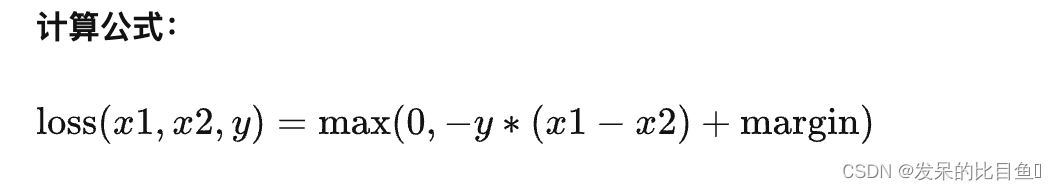


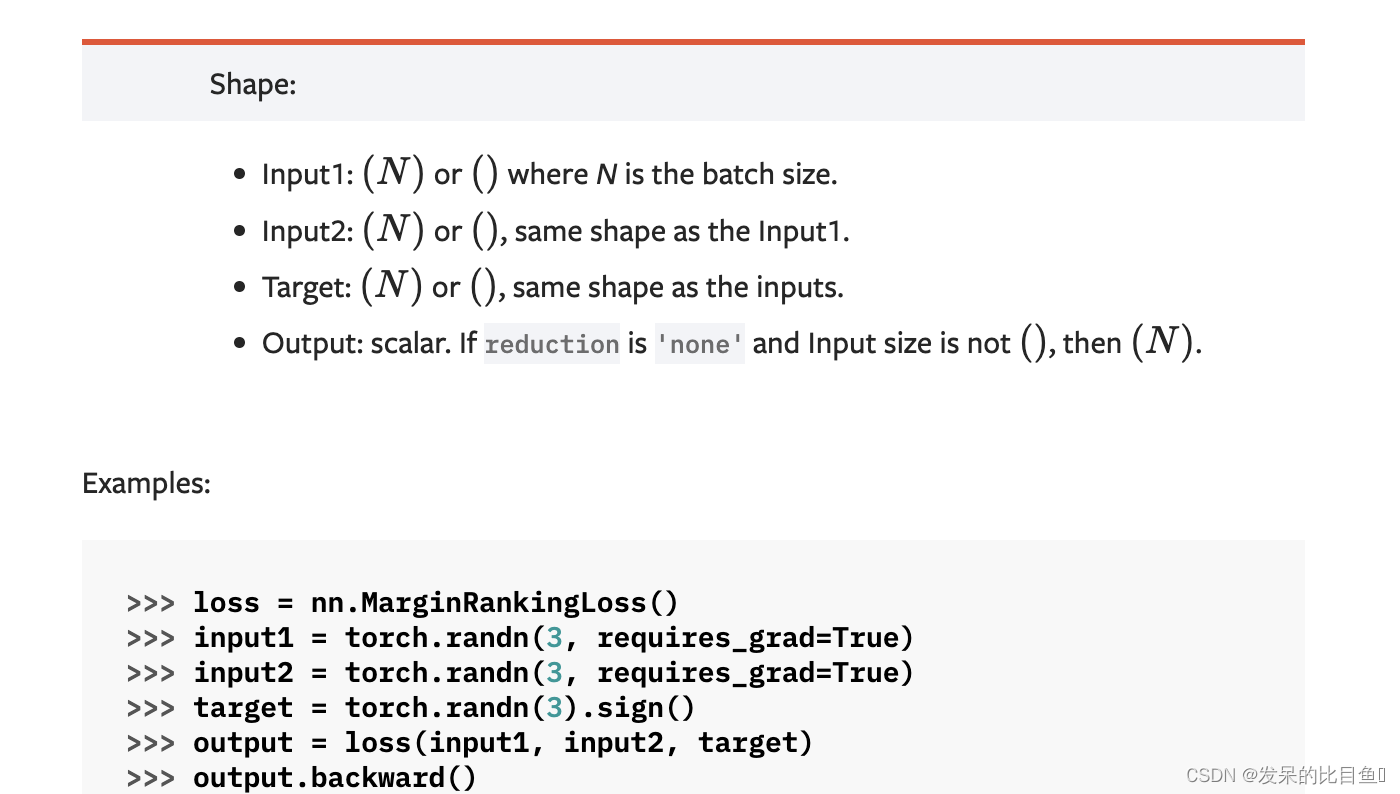
>>> loss = nn.MarginRankingLoss()
>>> input1 = torch.randn(3, requires_grad=True)
>>> input2 = torch.randn(3, requires_grad=True)
>>> target = torch.randn(3).sign()
>>> output = loss(input1, input2, target)
>>> output.backward()
nn.HingeEmbeddingLoss
功能: 对输出的embedding结果做Hing损失计算
主要参数:
- reduction:计算模式,可为 none/sum/mean。
- margin:边界值
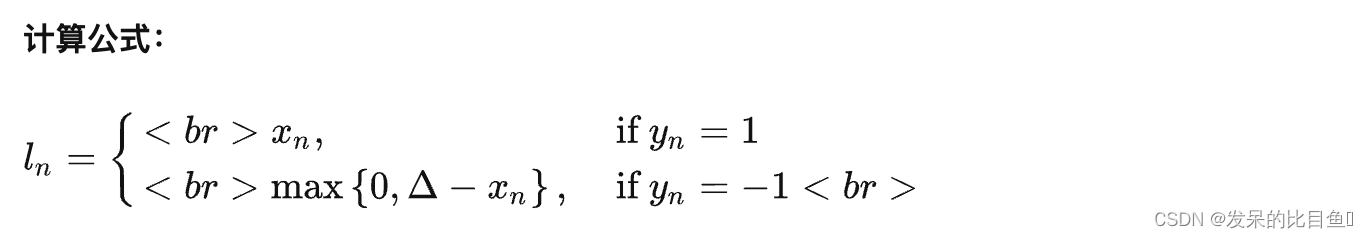


nn.MultiLabelMarginLoss
功能: 对于多标签分类问题计算损失函数。
主要参数:
- reduction:计算模式,可为 none/sum/mean。



loss = nn.MultiLabelMarginLoss()
x = torch.FloatTensor([[0.9, 0.2, 0.4, 0.8]])
# for target y, only consider labels 3 and 0, not after label -1
y = torch.LongTensor([[3, 0, -1, 1]])# 真实的分类是,第3类和第0类
output = loss(x, y)
print('MultiLabelMarginLoss损失函数的计算结果为',output)
MultiLabelMarginLoss损失函数的计算结果为 tensor(0.4500)
nn.HuberLoss
Huber Loss 集MAE与MSE的优势于一身
参考: https://zhuanlan.zhihu.com/p/554735911



nn.SmoothL1Loss
功能: L1的平滑输出,其功能是减轻离群点带来的影响
- reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。
- sum:所有元素求和,返回标量。默认计算方式是求平均。




nn.SoftMarginLoss
功能: 计算二分类的 logistic 损失。
主要参数:
- reduction:计算模式,可为 none/sum/mean。



nn.MultiLabelSoftMarginLoss

nn.CosineEmbeddingLoss
功能: 对两个向量做余弦相似度
主要参数:
- reduction:计算模式,可为 none/sum/mean。
- margin:可取值[-1,1] ,推荐为[0,0.5] 。
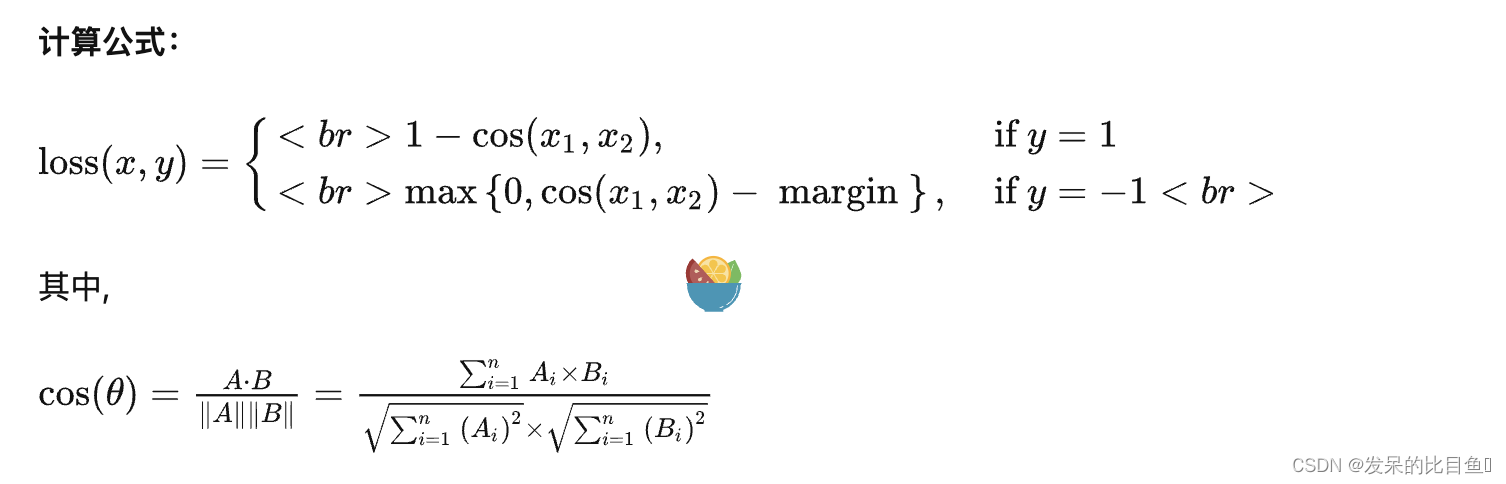


nn.MultiMarginLoss
功能: 计算多分类的折页损失
主要参数:
- reduction:计算模式,可为 none/sum/mean。
- p:可选 1 或 2。
- weight:各类别的 loss 设置权值。
- margin:边界值



inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]])
target = torch.tensor([0, 1], dtype=torch.long)
loss_f = nn.MultiMarginLoss()
output = loss_f(inputs, target)
print('MultiMarginLoss损失函数的计算结果为',output)
MultiMarginLoss损失函数的计算结果为 tensor(0.6000)
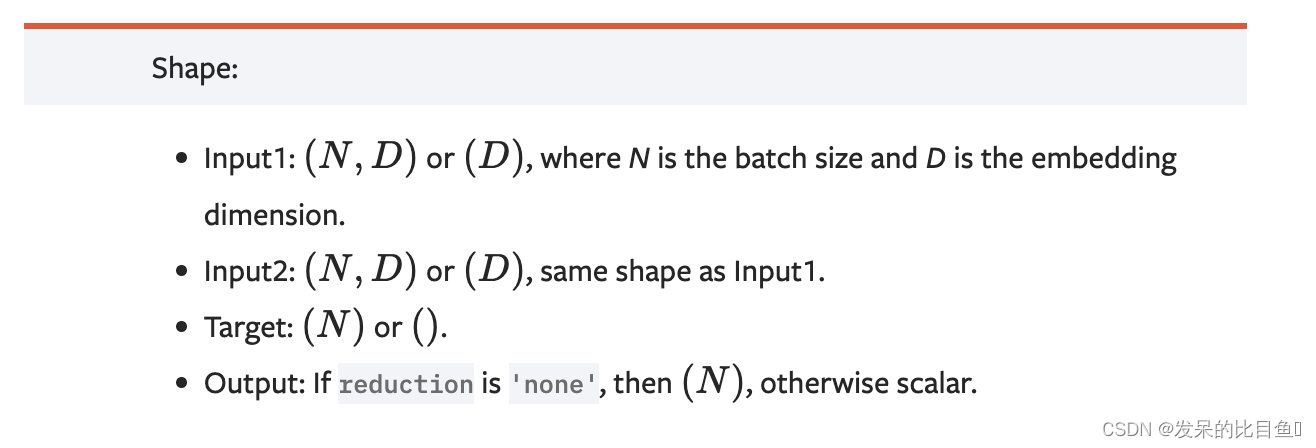
nn.TripletMarginLoss
功能: 计算三元组损失。
三元组: 这是一种数据的存储或者使用格式。<实体1,关系,实体2>。在项目中,也可以表示为< anchor, positive examples , negative examples>
在这个损失函数中,我们希望去anchor的距离更接近positive examples,而远离negative examples
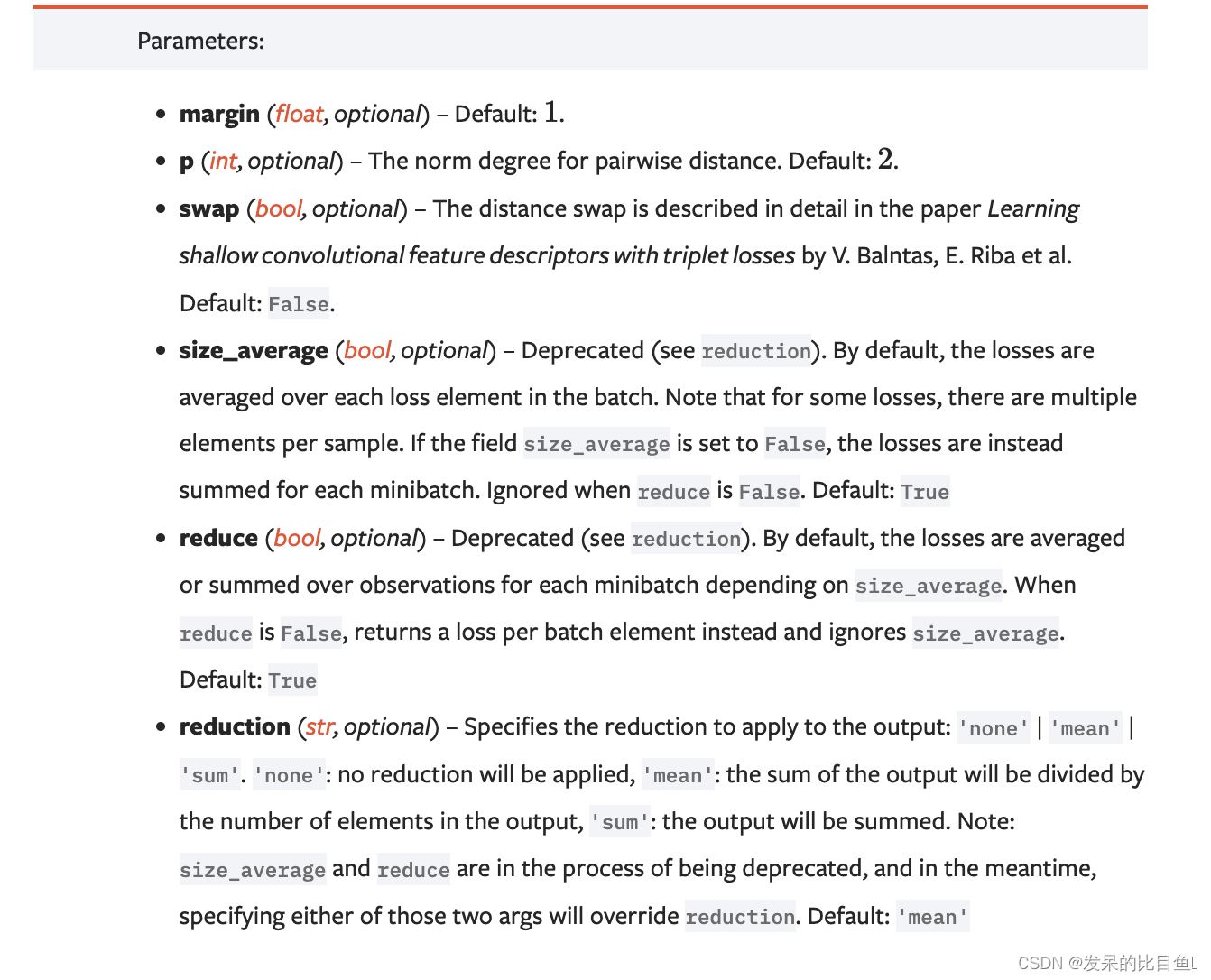
主要参数:
- reduction:计算模式,可为 none/sum/mean。
- p:可选 1 或 2。
- margin:边界值
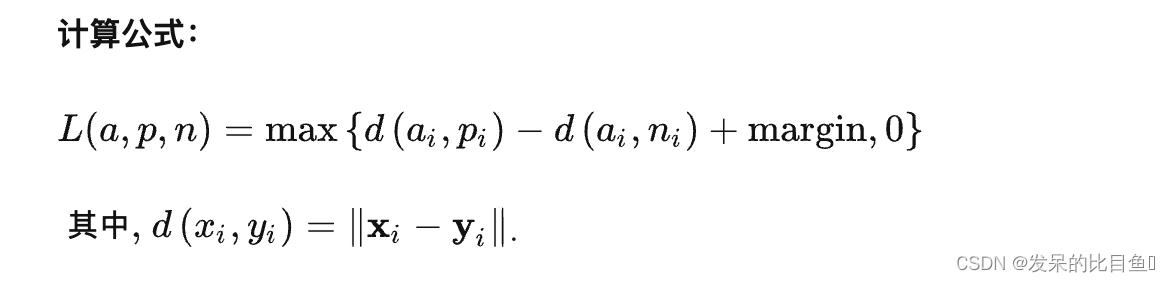

>>> triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2)
>>> anchor = torch.randn(100, 128, requires_grad=True)
>>> positive = torch.randn(100, 128, requires_grad=True)
>>> negative = torch.randn(100, 128, requires_grad=True)
>>> output = triplet_loss(anchor, positive, negative)
>>> output.backward()
nn.TripletMarginWithDistanceLoss


>>> # Initialize embeddings
>>> embedding = nn.Embedding(1000, 128)
>>> anchor_ids = torch.randint(0, 1000, (1,))
>>> positive_ids = torch.randint(0, 1000, (1,))
>>> negative_ids = torch.randint(0, 1000, (1,))
>>> anchor = embedding(anchor_ids)
>>> positive = embedding(positive_ids)
>>> negative = embedding(negative_ids)
>>>
>>> # Built-in Distance Function
>>> triplet_loss = \
>>> nn.TripletMarginWithDistanceLoss(distance_function=nn.PairwiseDistance())
>>> output = triplet_loss(anchor, positive, negative)
>>> output.backward()
>>>
>>> # Custom Distance Function
>>> def l_infinity(x1, x2):
>>> return torch.max(torch.abs(x1 - x2), dim=1).values
>>>
>>> triplet_loss = (
>>> nn.TripletMarginWithDistanceLoss(distance_function=l_infinity, margin=1.5))
>>> output = triplet_loss(anchor, positive, negative)
>>> output.backward()
>>>
>>> # Custom Distance Function (Lambda)
>>> triplet_loss = (
>>> nn.TripletMarginWithDistanceLoss(
>>> distance_function=lambda x, y: 1.0 - F.cosine_similarity(x, y)))
>>> output = triplet_loss(anchor, positive, negative)
>>> output.backward()
参考
https://zhuanlan.zhihu.com/p/483972065















 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











