







Slurm–资源管理系统
- 开源软件 SLURM
- 全称 Simple Linux Utility for Resource Management
- 开源分布式资源管理软件
- 可用于大型计算节点集群的高度可伸缩的集群管理器和作业调度系统
- 提供高效的资源与作业管理
- 状态监控
- 资源管理
- 作业调度
- 是用户使用计算资源的接口
- 作业提交 / 运行
- 任务加载
- 作业控制
- 状态查看
主要组成部分
- 控制进程
- 记账存储进程
- 节点监控进程
- 作业管理进程
- 命令工具
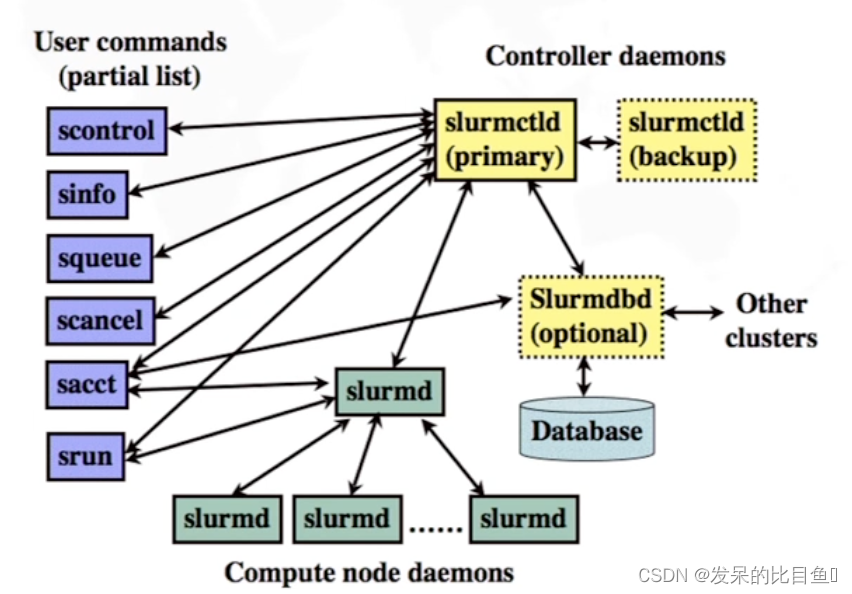
控制进程: Slurmctld
- 运行在管理节点
- 是资源管理系统的控制中枢
- 记录节点状态
- 进行分区管理
- 进行作业管理、作业调度、资源分配
记账存储进程: Slurmdbd
- 运行在管理节点
- 将作业信息保存到数据库
- 记录用户、帐号、资源限制、QOS 等信息
节点监控进程: Slurmd
- 运行在每个计算节点
- 监控节点状态,并向控制进程报告
- 接收来自控制进程与用户的请求并进行处理
作业管理进程: Slurmstepd
- 加载计算任务时由节点监控进程启动
- 管理一个作业步的所有任务
- 启动计算任务进程
- 标准 I/0 转发
- 信号传递
- 任务控制
- 资源使用信息收集
命令工具
- sacct:查看历史作业信息
- salloc: 资源分配
- sbatch: 提交批处理作业
- scance1: 取消作业
- scontrol: 系统控制
- sinfo: 节点与分区状态查看
- squeue: 队列状态查看
- srun:任务加载
实体: 管理对象
- 节点
- 分区
- 作业
- 作业步

节点: Node
- 即指计算节点
- 包含处理器、内存、磁盘空间等资源
- 具有空闲、分配、故障等状态
- 使用节点名字标识,如 node1
分区: Partition
- 节点的逻辑分组
- 提供一种管理机制,可设置资源限制、访问权限、优先级等
- 分区可重叠, 提供类似于队列的功能
- 使用分区名字标识, 如 MIC/GPU/CPU
- 系统有一个默认分区,带标记 - batch
作业: Job
- 一次资源分配
- 位于一个分区中,作业不能跨分区
- 排队调度后分配资源运行
- 通过作业 ID 标识,如 123
作业步: Jobstep
- 通过 srun 进行的任务加载
- 作业步可只使用作业中的部分节点
- 一个作业可包含多个作业步,可并发运行
- 在作业内通过作业步 ID 标识,如 123.0
关联: Association
- 关联是系统实施资源限制的一个基础概念
- 由〈cluster, account, user, partition〉构成的四元组
- 每个作业都有对应的关联,因为作业都是由用户使用对应帐号提交到系统的一个 分区中
帐号、用户的资源限制,在实现上最终以关联进行记录
- 节点数量
- 作业数量
- 时间限制
资源管理系统使用
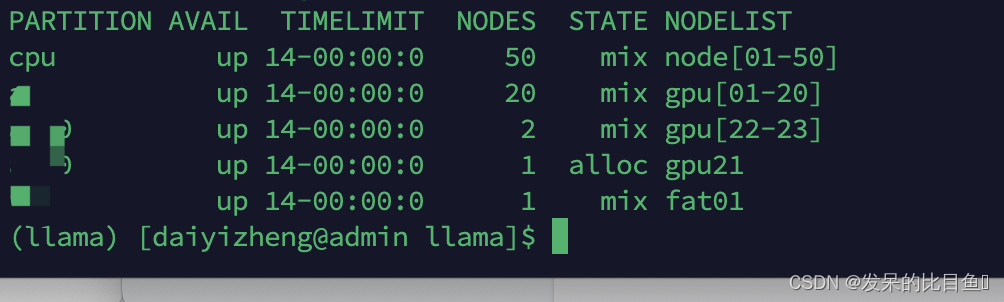
使用 sinfo命令查看节点状态

sinfo
sinfo -t 状态值(comp, drain…)
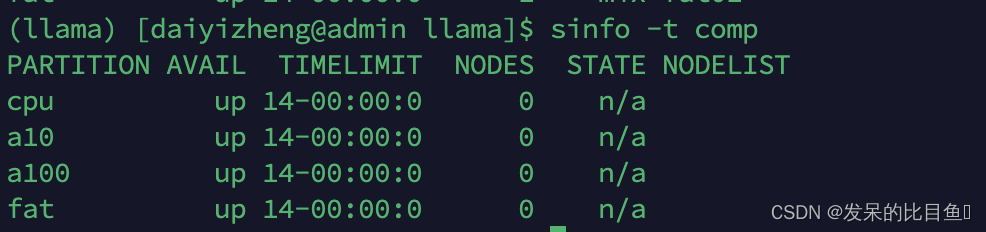
节点基本状态值
- UNKNOWN: 末知, unk
- IDLE: 空闲, idle
- ALLOCATED: 已分配, alloc
- DOWN: 故障, down
状态标识
- DRAIN: 不再分配,drain/drng
- COMPLETING: 有作业正在退出, comp
- NO_RESPOND:无响应, *
使用 sinfo命令查看分区状态
- 分区名
- 分区状态
- UP、DOWN、DRAIN、 INACTIVE
- DEFAULT/*
- 运行时间限制
- 查看指定分区
sinfo -p 分区名
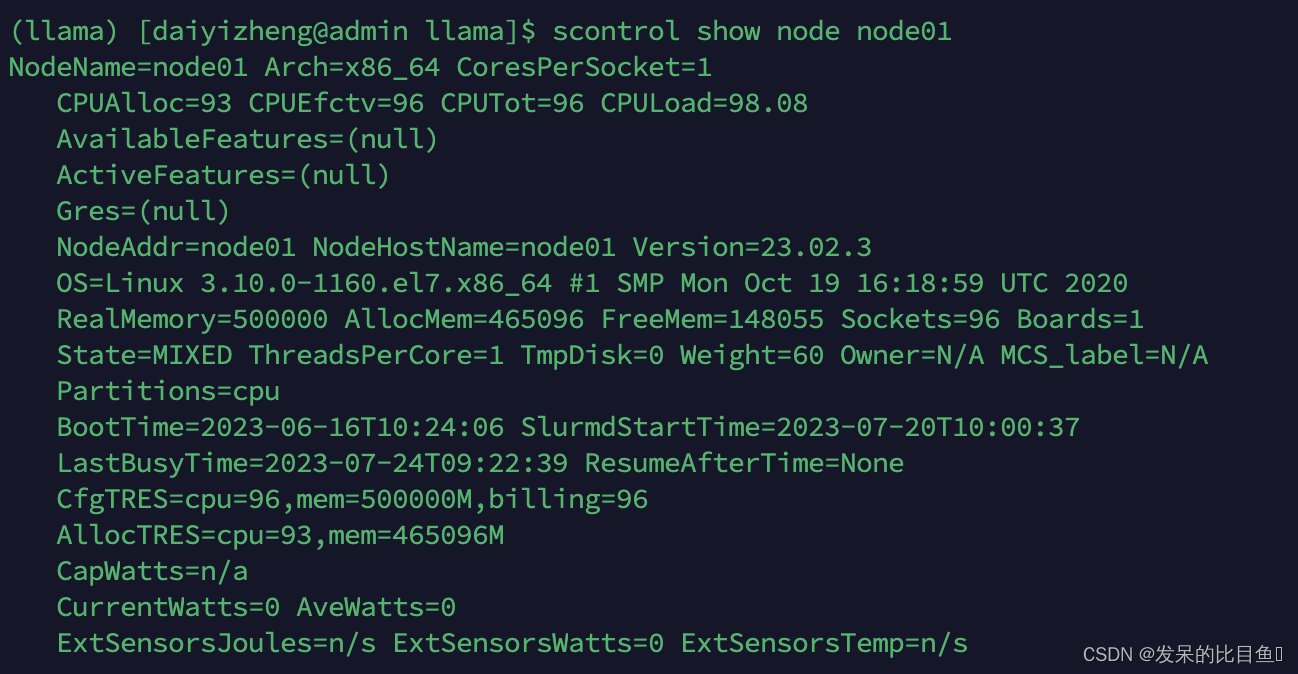
使用scontrol命令查看节点详细信息
scontrol show node node01
使用scontrol命令查看分区属性

- 节点列表
- 状态: UP/DOWN
- 隐藏分区
- 访问权限
- Root0nly
- AllowGroups
- 资源限制
- 节点范围
- 运行时间
- 优先级
- 共享节点
- 默认分区
作业 – 资源分配请求
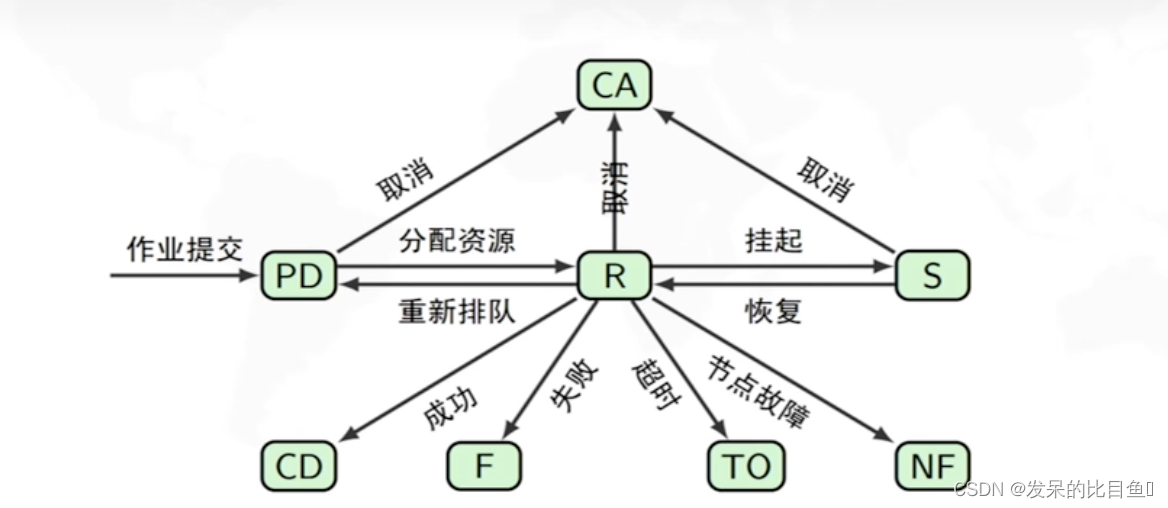
- 提交:申请资源
- 排队:等待资源
- 运行: 分配资源 (无论是否执行程序)
- 挂起:暂时释放资源
- 结束:释放资源
作业运行模式
交互模式-适合调试场景–srun
批处理模式一作业提交建议场景–sbatch
分配模式一满足特殊需求场景–salloc
只是用户使用方式区别–管理、调度、记账时同等对待
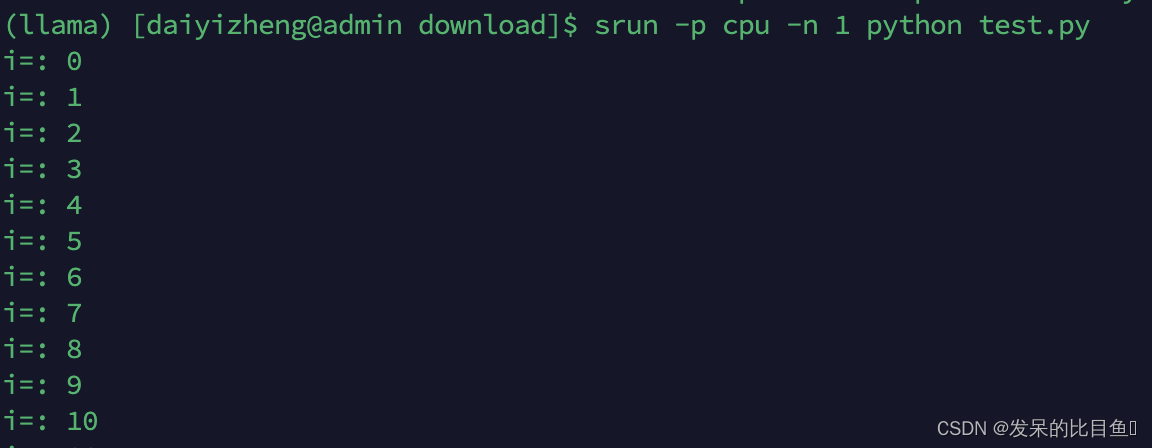
交互模式 - srun
- 在终端提交资源分配请求,指定资源数量与限制
- 等待资源分配
- 获得资源后,加载计算任务
- 运行中,任务I/0传递到终端
- 可与任务进行交互: I/0,信号
- 任务执行结束后,资源被释放
一个srun (一次资源分配) 生成一个作业步(一次任务加载)
srun -p cpu -n 1 python test.py
批处理模式 - sbatch
批处理模式
- 用户编写作业脚本
- 提交作业
- 作业排队等待资源分配
- 分配资源后,在首节点加载执行作业脚本
- 脚本执行结束,释放资源
- 运行结果定向到指定的文件中记录
脚本中可通过srun加载计算任务
- 一个作业可使用多个srun生成多个作业步
- 也可以不包含srun命令,这样脚本只会在首节点运行
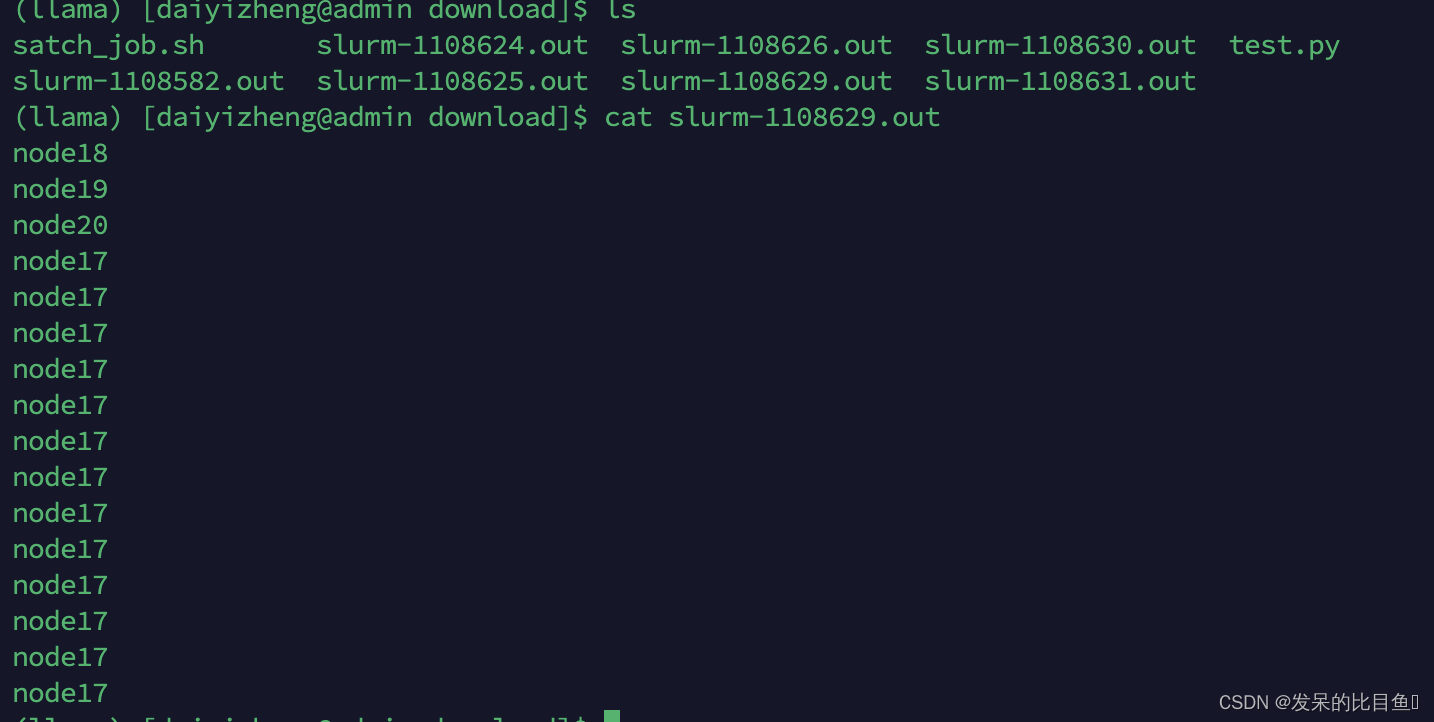
#!/bin/sh
#SBATCH -p cpu -N 4 -t 100 -n 16
srun -n 16 hostname

sbatch satch_job.sh

分配模式 - salloc
分配模式
- 提交资源分配请求
- 作业排队等待资源分配
- 执行用户指定的命令
- 命令执行结束,释放资源
交互模式作业与批处理模式作业的结合
- 一个作业可包含多个作业步
- 可通过srun加载计算任务
- 可与任务进行交互
- 命令在用户提交作业的节点上执行
- 便于指定明确的节点进行集中操作的场景
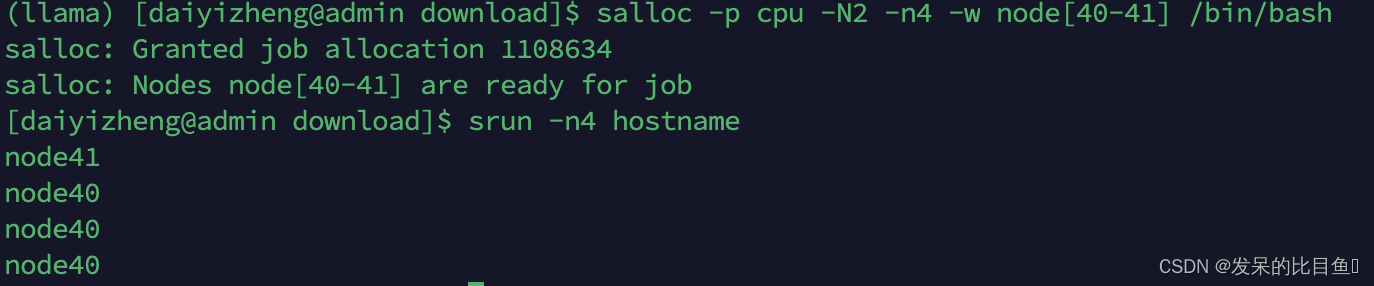
通过salloc命令运行
salloc -p cpu -N2 -n4 -w node[40-41] /bin/bash
srun -n4 hostname
-
节点数量: -N, --nodes min[-max]
- 如末指定, 则根据其他需求, 分配足够的节点
-
处理器数量: 由几个参数组合决定
- 作业要加载的任务数 -n, --ntasks, 不指定则默认每个节点一个
- 每个任务需要的处理器数 -c, --cpus-per-task, 默认为 1
- 系统将根据参数计算, 分配足够处理器数目的节点
-
节点与处理器数目约束
-
运行时间:
-t, --time -
单位为分钟
-
超出时间限制的作业将被终止
-
应尽可能准确估计:调度时用此估计时间进行backfi11判断与优先级设置
-
分区: -p,–partition
- 从指定分区中分配节点
- 使用指定分区的资源限制 / 访问权限进行检查
- 作业必须位于一个分区中, 不能跨分区
-
节点:
- -w, --nodelist : 指定分配给作业的资源中至少要包含的节点
- -F, --nodefile:指定分配给作业的资源中至少要包含文件中定义的节点(此选 项仅对salloc和 sbatch可用)
-
- x, --exclude : 指定分配给作业的资源中不要包含的节点
- –contiguous : 表示作业需要被分配连续的节点
-
作业名字
- 默认: 加载的程序 / 批处理脚本文件名 / 执行的命令
- -J, --job-name: 指定名字
sbatch -p cpu -N 4 job.sh
sbatch -p cpu -N 8 -j myjob job.sh

- 工作目录
- -D, --chdir: 指定任务/脚本/命令的工作目录
- 默认: srun/sbatch/salloc 的工作目录
sbatch -p batch -N 4 -D /batch/test/devel/bin job.sh
-
启动时间
- -begin: 作业在指定时间之后才能运行
-
依赖关系
- -d,–dependency:指定作业的依赖关系
- after: jobid: 在指定作业开始之后
- afterok: jobid: 在指定作业成功结束之后
- afternotok: jobid: 在指定作业不成功结束之后
- afterany: jobid: 在指定作业结束之后
- 满足依赖关系的作业才能运行
- 不可能满足依赖关系的作业将被取消
- -d,–dependency:指定作业的依赖关系
-
节点故障容忍
- 默认:节点失效时将终止作业
- 失效节点变为 DOWN 状态
- 主要针对 MPI 程序的执行, 及时释放资源
- -k, --no-kill: 容忍节点故障
- 程序自身容错
- 正在执行的作业步失败后,继续运行后续作业步
- 默认:节点失效时将终止作业
-
-l,–label选项
- 区分作业步的标准输出或标准错误由哪个任务生成
srun -p cpu -N 4 hostname
srun -l -p cpu -N 4 hostname
作业状态查看

- 常用查询选项
- -p: 指定分区
- -u: 指定用户
- -t : 指定状态
- -w:指定包含的节点
- -j: 指定作业id号
- -J : 指定作业名
使用scontrol命令查看作业详细信息
scontrol show job 967

使用 squeue与scontrol命令查看作业步
squeue -s

scontrol show steps 967.0

- 作业步仅在运行时存在, 运行结束后从系统中删除
- 使用 sacct 命令可查看历史作业步信息
使用sacct命令查看历史作业信息

- -S, --starttime: 查询开始时间
- -E, --endtime: 查询截止时间
- -s, --state: 指定查询的作业状态列表
- -e, --helpformat: 查看可支持定制输出的信息项
- -o, --format: 定制输出信息项列表
sacct --starttime=2023-07-10T12:00:00 --endtime=2023-07-23T12:00:00 --state=completed
排队状态原因
- Priority:优先级不够高
- Dependency:作业的依赖关系末满足
- Resources:当前可用资源不能满足作业需求
- PartitionNodeLimit:作业请求的节点数超过分区的作业节点数限制
- PartitionTimeLimit:作业请求的运行时间超过分区作业运行时间限制
- PartitionDown:作业所在的分区处于 DOWN 状态
- JobHeld:作业被阻止调度
- BeginTime:作业请求的启动时间还末到达
- AssociationJobLimit: 关联的作业限制已满
- AssociationResourcelimit: 关联的资源限制已满
- AssociationTimeLimit: 关联的运行时间限制已满
- ReqNodeNotAvai1:作业请求的节点不可用
取消作业
scancel 命令取消作业 / 作业步
- 排队作业: 标记为 CANCELLED 状态
- 运行 / 挂起作业: 终止所有作业步; 标记为 CANCELLED 状态; 回收资源
- 使用 scancel之后, 系统将定期重复发送 SIGKILL 到作业步任务, 直到其退出
- 显示为 CG 状态的作业已经结束, 不用再取消
scancel 123456
scancel 789.1
scancel -u test
scancel -p debug -t pd
其他技巧补充
在 Slurm 的 cstat 命令输出中,以下是涉及到你提到的参数的解释:
Partition: 计算节点所属的分区(Partition)。分区是集群中逻辑划分的一个方式,用于将计算资源划分为不同的逻辑组,以便更好地管理作业的调度和资源分配。
- Nodes: 分区中计算节点的总数。
- IdleN: 分区中处于空闲状态(Idle)的计算节点数。
- CPUS: 分区中计算节点的总 CPU 核心数。
- IdleC: 分区中空闲 CPU 核心的数量。
- PDC: 分区中正在运行的作业(Pending)的数量。
- GPUS: 分区中计算节点上的 GPU 数量。
- IdleG: 分区中空闲 GPU 的数量。
- PDG: 分区中正在运行的需要 GPU 资源的作业(Pending GPU)的数量。
要查看特定计算节点上空闲的 GPU 数量,你可以使用 scontrol 命令。以下是一个示例命令,用于查看指定计算节点上的 GPU 空闲个数:
scontrol show node=gpu23 | grep "AllocTRES"
















 2640
2640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











