






这是一个简单的学习总结,核心逻辑以及V1 V2差异总结,主要从计算的角度总结FlashAttention怎么做到save memory & perf speedup的,讲一些其他文章提的比较少的点,不提供等效计算变换的公式证明。
摸了一下FlashAttention的CUTLASS实现(https//github.com/Dao-AILab/flash-attention/blob/main/csrc/flash_attn/src/flash_bwd_kernel.h)和Triton实现(https//github.com/openai/triton/blob/main/python/triton/ops/flash_attention.py),之前做过FlashAttention V1和V2算法下,这两种框架最终的Kernel Perf benchmark(A100 & H100)所以对V1和V2的差异很好奇,本文是一个简单的学习总结,主要从计算的角度总结FlashAttention怎么做到save memory & perf speedup的,讲一些其他文章提的比较少的点,不提供等效计算变换的公式证明(这部分知乎其他大佬写的非常详细清晰了)。
理解FlashAttention核心逻辑
本节列举从0搞懂FlashAttention的核心步骤
首先需要理解Naive Attention是怎么计算的:

- Google Research的工作重点在减少整个过程的memory footprint;FlashAttention重点在减少memory reads/writes次数。可以说FlashAttention主要是从GPU block/thread并行度的视角对访存进行了优化。
- Google Research的工作每个block会产出一份中间结果,所有block执行完毕之后,再将他们的中间结果计算获得一个最终结果;FlashAttention则采用类似滑动窗口的方式,第i个block会将累积的中间结果传递给第 i+1 个block,也就是说最后一个block计算完毕后,可以保证整行的Softmax逻辑计算正确性。锐评:我认为这个点并没有什么独创性,Google Research这么考虑的原因也大概率是因为TPU的计算逻辑粒度适合沿sequence length切并行,切的越小越有利于TPU并行,最后再有一个逻辑来处理中间数据很正常。
- Google Research的工作在后向backward的时候做了一些冗余计算,FlashAttention把后向的计算简化了,减少了backward阶段的memory traffic。
FlashAttention V1的公式和推导不细嗦了,其他文章讲得非常好。列一下个人觉得从0开始的最佳学习路线:
首先看文章,公式推导和Tiling细节强烈这篇文章:From online softmax to FlashAttention(https//courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf),写的非常好,由浅入深,公式推导这块看完这篇其他都不用看了。然后辅助看一些知乎文章把不明白的地方搞清楚。
理解From online softmax to FlashAttention需要四个步骤
- softmax
- safe softmax
- online softmax Tiling
- FlashAttention Tiling
总之:FlashAttention之所以可以省显存(显存开销随Seq length线性增加),是因为解开了softmax以及后面GEMM的行方向依赖,并且通过辅助数组保存的辅助信息re-scale到正确的数值。
其次,了解一些背景信息,这里附一下其他可能便于理解FlashAttention项目发展的背景信息:
- FlashAttention V1 在NVIDIA apex fmha基础上实现(最早的FlashAttention Alpha Realease(https//github.com/Dao-AILab/flash-attention/blob/1fcbe6f0d088d807ba585ddb850eb3497cd7b65b/csrc/stream_attn/src/fmha_kernel.h)),V2基于CUTLASS 3.0 & CUTE 重构(CUTE真是个好东西)
- FlashAttention目前最方便的调库途径主要有两个
- 最新实现在ops里面(https//github.com/openai/triton/blob/main/python/triton/ops/flash_attention.py)
- 稳定的实现在tutorial里面(https//github.com/openai/triton/blob/main/python/tutorials/06-fused-attention.py)
- 【更新】最近测了一下,H100上tutorial速度也很快,看上去tutorial的kernel算法也经常有小优化
- pip install flash-attn,官方的库,编译时间稍长,基于CUTLASS有大量的模板,如果想进一步魔改(比如加bias或者加mask,或者稀疏化等)学习和Debug成本比较大
- 使用Triton的实现,性能实测非常不错
最后,看代码,跑代码,Profile Kernel with Nsight Compute,改代码...
这里我推荐基于Triton FlashAttention(https//github.com/openai/triton/blob/main/python/tutorials/06-fused-attention.py)上手,原因如下:
- Tri-Dao的FlashAttention基于CUTLASS 3.0重构,新手小白想要编译跑起来首先要搞定几个环境问题;里面一个头文件几千行,想看懂需要首先搞懂CUTLASS的基本用法,想改代码更需要一些模板猿编程debug技巧,想优化性能的话...你得学学CUTE,再学学各种GPU Features...如果你只是想学习一下FlashAttention,或者只是想基于这个Fusion idea定制你自己的kernel,没必要从CUTLASS开始。CUTLASS适合CUDA熟手并且期望拿到Peak Performance的玩家。
- Triton语法很容易上手,方便魔改你自己的Attention Kernel,或者你有其他的想法也很容易实践实验。例子:FlagAttention(https//github.com/FlagOpen/FlagAttention),Sparse Flash Attention(https//github.com/epfml/dynamic-sparse-flash-attention) (所以非常适合发paper啦,至少迭代CUDA kernel速度直接飙升,加快idea的反馈。从实验时间成本来说,用CUDA写半个月的Kernel+调一个月性能 >> 用CUTLASS写一周Kenrel+调两天性能 >> 用Triton写3天Kernel+调1天性能)
- Triton FlashAttention在Hopper-Triton PR(https//github.com/openai/triton/commit/f1512bded1934e34f104bf1ac8547e97e24b2fe8)之后,目前main分支已经集成了大量的Hopper相关的优化Pass,相比官方库还没有稳定实现Hopper features来说,在某些problem size下可能有优势。
- 关于Triton推荐阅读:杨:谈谈对OpenAI Triton的一些理解(https://zhuanlan.zhihu.com/p/613244988),杨:OpenAI Triton Conference参会随感兼谈Triton Hopper(https://zhuanlan.zhihu.com/p/659348024)
OK,进入正题
FlashAttention V2相比V1有哪些改进

FlashAttention V1 前向后向 Kernel示意草图
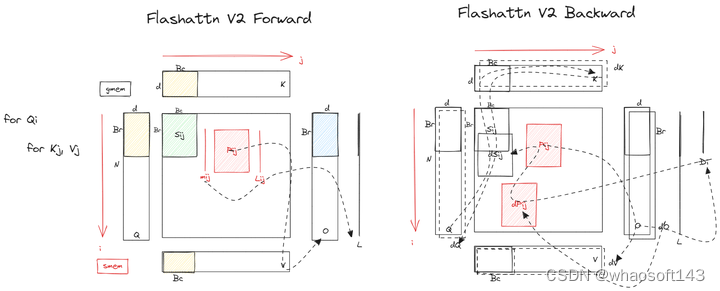
FlashAttention V2 前向后向 Kernel示意草图
V2主要从两个方面改进:
算法的改进
fwd和bwd都简化了非matmul计算,这里也是对rescale重新优化了一下;其中bwd不需要m了,只需要logsumexp L 即可。
其实FlashAttention不管V1还是V2都有一个缺点,就是为了rescale方便并行,需要把很多计算逻辑顺序排在后面(尤其是浮点数的乘除),这会改变计算的数值精度稳定性,造成在某些使用到Attention结构的网络中收敛不了的问题。
fwd和bwd都根据casual mask的特性尽可能减少冗余计算和访存:
- 右侧上三角block无须计算,直接跳过;
- 每行只用对最后一个block设定casual mask的逻辑即可。

FlashAttention V1 & V2 forward

FlashAttention V1 & V2 backward
红框的就是这里算法部分的优化和改动(左图多了mask和droupout的逻辑,忽略即可)
这个优化其实不是critical path,所以提升并不大。fwd做2个GEMM,bwd做5个GEMM,整个Kernel fwd & bwd都是memory bound,此时应该优化的是GEMM相关的memory dependency,做multi-stages,更灵活的异步调度(比如warp specialization),最后可能还需要考虑优化data reuse,优化L2 cache等等,当然一切都需要基于Nsight Compute结果分析,不然都是幻觉。
Sequence Length 并行
非常赞同@方佳瑞(https://www.zhihu.com/people/8c89d6f733cb2b81ce36a2daf0a81a82) 方佳瑞:大模型训练加速之FlashAttention系列:爆款工作背后的产品观(https://zhuanlan.zhihu.com/p/664061672#:~:text=我觉得V2最重要的提升点是参考Phil Tillet的Tirton版本,更改了Tiling循环的顺序,也就是笔者本文图1的效果。) 提到的,V2 能够把特定输入下的一个CUDA Kernel提升2X,这只能说明baseline(V1)选的太好了(笑),总之,就是因为改变了Tiling循环的顺序,把Q循环挪到了最外层,所以刚好就可以把Q循环直接给到Thread Block并行维度来计算了,本来这个方向没有依赖就是可以并行的。话说我最开始的也很纳闷,这个idea其实最早就有了,PyTorch的实现以及NV Apex FMHA的实现都有这个版本的kernel。
考虑一下,为什么K/V上的seq length方向不给到Thread Block做并行?答案是,如果可以在Q seq length上拆block并行了,那么一般来说GPU occupancy已经够了,再多拆K/V的话也不是不行,但是会额外带来通信开销;Flash Decoding其实就是在inference阶段,面对Q的seq length=1的情况,在K/V方向做了block并行,来提高GPU Utilization从而加速的。

FlashAttention V1 - Tile and 2D-Loop
Thread Block Level 并行
交换了Q loop顺序到最外层之后,最大的好处是可以把这一维度的并行度从串行的loop改成并行的thread block。
所以,FlashAttention V2的实现中,fwd除了在Batch和Head上分配Thread Block并行,还在seq length上增加了一维并行度(之前是需要M N方向做loop的,现在只在N方向loop了,横着切),注意:bwd没有改变这里的循环,跟V1一样,但是也在seq length上增加了一维并行度(N方向并行,竖着切)。
造成fwd和bwd区别的主要原因是:
- fwd的目的是计算QK GEMM之后沿着行方向online softmax,所以需要沿着行方向loop,不然就需要额外的reduce逻辑了。因此fwd kernel选择一行Tile为一个block。如下左图一行同色块为一个block。

细节1:从V1 (KV外循环,QO内循环) 到V2 (Q外循环,KV内循环,O在 smem初始化,最后只写出一次), memory traffic是否降低了? memory traffic of V1:

细节2:现在确定了fwd kernel要在B, H, Q_N_CTX三个维度Launch Kernel了,有两种选择:grid_dim = [Q_N_CTX, B, H], grid_dim = [B, H, Q_N_CTX],哪种更好?
答案是第一种更好,因为Q_N_CTX放ThreadBlock.X维度的话,对于同一个B和H的Q_N_CTX是连续调度的,也就是说算第一行用到的K/V Tile大概率还在L2上,第二行计算可以直接从L2拿到,这样可以显著提高L2 cache hit rate。这个优化在大seq_length的时候优化很明显。
Warp Level 并行
说完了thread block的并行,再来看一个block内的warp怎么并行的

把V横着画,有一种上下对称的美感
首先看fwd,相比V1,V2改进了Warp Partition:4个warp会从smem的K/V tile load同样的数据做mma计算,但是load 不同Q,把V1 sliced-K sliced-V 改成了v2 sliced-Q,V1的做法是需要warp之间产生同步通信的,因为在计算QK结果乘V的时候,如图所示需要跨warp reduction得到O的结果,而且fwd的目的是沿着行方向计算softmax,行方向信息最后要汇总的,这也需要跨warp不同。V2就不需要了,这样可以减少同步开销。
对于bwd来说,如果按照右图做warp partition:1、QK的结果是P,dV=P x dO,计算dV也是需要cross warp sync的;2、dO x V的结果是dP,跟P是对称的,计算dS = P o(点乘) dP的时候不需要cross warp sync;3、计算dQ是dS x K,不需要cross warp sync;4、计算dK = dS x Q,需要cross warp sync;
如果按照左图来做warp partition,那么:1、计算dV不需要cross warp sync;2、计算dS不需要cross warp sync;3、计算dQ,需要cross warp sync;4、计算dK,不需要cross warp sync;
这里有个疑问,对于bwd来说,左图不需要cross warp sync的场景是更多的,如果Br Bc d这三个reduction的维度差不多,按道理来说bwd kernel更应该采用V1的方式做warp partition,原文:
Similarly for the backward pass, we choose to partition the warps to avoid the "split-K" scheme. However, it still requires some synchronization due to the more complicated dependency between all the different inputs and gradients Q, K, V, O, dO, dQ, dK, dV. Nevertheless, avoiding "split-K" reduces shared memory reads/writes and again yields speedup
但作者并没有细说,也没有实验数据证明这里确实提升了bwd kernel性能,感到困惑。以后有空再测一下这里的策略是不是负优化(笑
其他优化
Sequence Parallel
https//github.com/openai/triton/blob/main/python/triton/ops/flash_attention.py
这是一个没有放在FlashAttentionV2 Release的优化点(应该,反正V2 paper没提到)。之前提到的bwd中,对dQ的计算是需要跨Block做全局Atomic Reduction的,如果Block数太多,就会产生Atomic竞争,效率很低(AtomicAdd指令吞吐和延迟都比正常的LDG慢2X,而且如果dQ的数据类型是fp16或者bf16,进行Atomic操作将是性能灾难);所以如果想避免使用Atomic指令做Reduction,有两种方案:
Loop n
最简单的方式,就是bwd不要seq length方向并行度了,直接串行循环就ok;
Sequence Parallel
把dQ开大一维度,N方向有多少列block就开几个buffer,并且N方向纯block并行,最后开另外一个kernel做一个reduce,这个逻辑体现在Triton代码里就是:
https//github.com/openai/triton/blob/f9b2b822dfc0980df4c39286713414dfcd27cf8e/python/triton/ops/flash_attention.py%23L323C1-L361C1
Atomic和Sequence Parallel肯定是两个极端了,所以根据不同的problem size取个折中肯定会有机会拿到更好的性能,根据具体的计算任务和GPU型号,还有些取巧的方式来避免Atomic,比如把即将冲突的Atomic Tile安排在不同的wave上,这样GPU也不会因为Atomic带来性能损耗。
Flash Decoding优化的核心跟这里的Sequence Parallel很类似:K/V Seq Length 方向切并行度做forward softmax并且最后使用一个reduction kernel对output进行累加和rescale。
指令级别的优化
基于FlashAttentionV2继续优化下去(假设把mma相关指令和memory latency掩盖的很好的话),最后大概率会bound在softmax相关的指令上,这个时候细扣这些浮点数计算指令也是有帮助的:
- FMUL+MUFU.EX2指令替换为fastmath指令expf
- 把scale相关的数据在cpu提前计算好,省一条GPU指令
- 把FMUL和FADDs合成FFMA指令
其实还有很多点可以优化FlashAttention的性能,不过都是些没有profile kernel的拍脑袋幻觉,就不讲了,之后有空做了实验可以再写一篇。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









