






欢迎关注微信公众号InfiniReach,这里有更多AI大模型的前沿算法与工程优化方法分享

attention

(1)(2)设计矩阵乘法,计算复杂度都是
O
(
d
N
2
)
O(dN^2)
O(dN2)(仅乘法),复杂度随序列长度的增长呈二次方增长
GPU的显存即HBM带宽为1.5-2.0TB/s;片上SRAM的带宽约为19TB/s。在attention计算中涉及大量访存事务:
- 读QK,写S
- 读S,写P
- 读PV,写O
访存复杂度 O ( 2 d N + N 2 + N 2 + N 2 + N 2 + d N + d N ) = O ( d N + N 2 ) O(2dN + N^2 + N^2+N^2+N^2+dN+dN) =O(dN+N^2) O(2dN+N2+N2+N2+N2+dN+dN)=O(dN+N2)
flash attention 1
FlashAttention将优化重点放在了降低存储访问开销,为了减少对HBM的读写,FlashAttention将参与计算的矩阵进行分块送进SRAM,减少了HBM访存,来提高整体读写速度。
softmax时涉及计算每行元素最大值m(x),计算 ∑ i e x i − m ( x ) \sum_i e^{x_i - m(x)} ∑iexi−m(x),将QK划分成块后,只能计算局部,设置长为N的全局max(x)和全局 ∑ i e x i − m a x ( x ) \sum_i e^{x_i - max(x)} ∑iexi−max(x),每次计算完局部后,更新这俩全局向量,更新的方法就是乘 e m a x ( x ) o l d − m a x ( x ) n e w e^{max(x)_{old}-max(x)_{new}} emax(x)old−max(x)new,消掉原来的局部max。
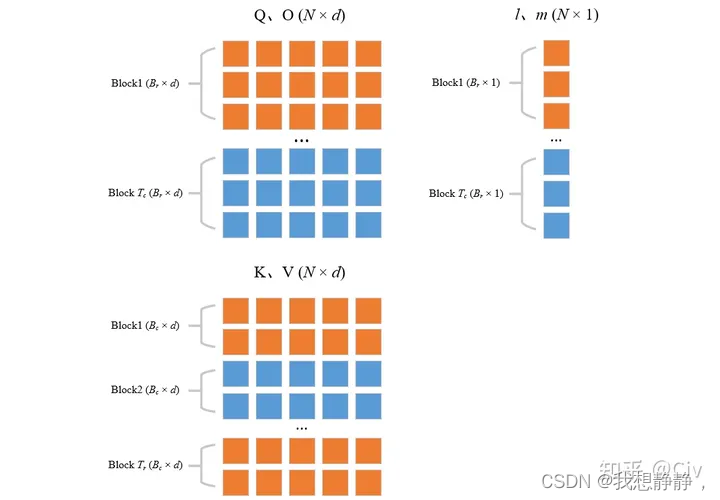
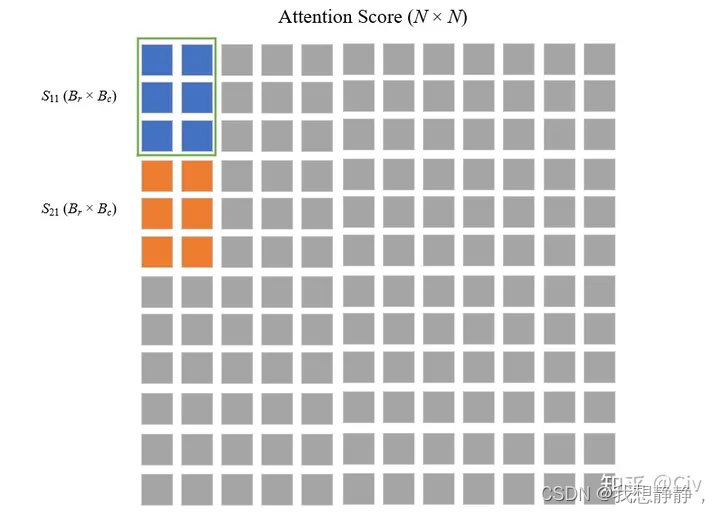
外层循环KV,内层循环QO,计算内层访存复杂度,内存循环一次访存Nd,外层循环
N
B
c
=
4
d
N
M
\frac{N}{B_c}=\frac{4dN}{M}
BcN=M4dN,共计
O
(
N
2
d
B
−
1
)
=
O
(
N
2
d
2
M
−
1
)
O(N^2dB^{-1})=O(N^2d^2M^{-1})
O(N2dB−1)=O(N2d2M−1)。 M(100KB)通常远远大于 d(数K),所以FlashAttention的MAC远小于标准的Transformer
O
(
d
N
+
N
2
)
O(dN+N^2)
O(dN+N2)。
FlashAttention 的 向后传递需要SP矩阵来计算 Q,K,V 的梯度。然而由于空间复杂度是 O(N^2) ,没有显式存储。使用输出 O 和 softmax 归一化统计 (m,ℓ),利用SRAM中的 Q,K,V 重新计算 S 和 P 矩阵。这个过程使用更多的flop,由于减少HBM访问,重新计算也加快了反向传播的速度。
FlashAttention 的速度优化原理是怎样的? - Civ的回答 - 知乎
https://www.zhihu.com/question/611236756/answer/3132304304
flash attention 2
-
减少了non-matmul FLOPs的数量(消除了原先频繁rescale)。虽然non-matmul FLOPs仅占总FLOPs的一小部分,但它们的执行时间较长,这是因为GPU有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的16倍。因此,减少non-matmul FLOPs并尽可能多地执行matmul FLOPs非常重要。
-
提出了在序列长度维度上并行化。该方法在输入序列很长(此时batch size通常很小)的情况下增加了GPU利用率。即使对于单个head,也在不同的thread block之间进行并行计算。
-
在一个attention计算块内,将工作分配在一个thread block的不同warp上,以减少通信和共享内存读/写。
-
原版设置长为N的全局max(x)和全局 ∑ i e x i − m a x ( x ) \sum_i e^{x_i - max(x)} ∑iexi−max(x),需要每次更新这俩。新版里先不计算分母,即softmax没分母,等最后再除以分母:
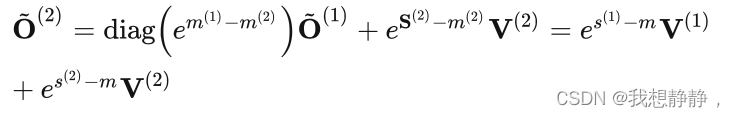
GPU的Tensor Cores FP16/BF16矩阵乘法的最大理论吞吐量为312 TFLOPs/s,但FP32非矩阵乘法仅有19.5 TFLOPs/s,即每个no-matmul FLOP比mat-mul FLOP昂贵16倍。
- FlashAttention-2还在序列长度这一维度上进行并行化,显著提升了计算速度。此外,当batch size和head数量较小时,在序列长度上增加并行性有助于提高GPU占用率。
FlashAttention在batch和heads两个维度上进行了并行化:使用一个thread block来处理一个attention head,总共需要thread block的数量等于batch size × number of heads。但是在处理长序列输入时,由于内存限制,通常会减小batch size和head数量,这样并行化成都就降低了。
- 原版外层循环是KV,内存循环是QO,O需要刷新外层循环的次数;所以把QO设为外层循环,KV设为内层循环。将FlashAttention的Q共享,KV切4个warp,改进为Q切4个warp,共享kv,warp之间不再需要通信,减少了share memory读写,带来了性能提升
https://zhuanlan.zhihu.com/p/645376942















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









