







caffe训练总(10)
当我们安装了 Caffe 框架,经过了 MNIST,和 cifar10 练手以后,开始慢慢熟悉这个经典的框架了,不过总是有需要训练自己准备的图片集和网络的时候,下面是我在使用时个人的一些小总结,以及用到的一些小脚本文件,若有错误之处或者建议意见,欢迎留言,互相交流学习。
注:下面每个过程内容不全是连续的,可能文件名看着有些乱,但是每个步骤的操作都是一样的,只要对应这自己修改相应文件的路径和名字就行了,本文主要介绍操作步骤,没有很详细的相关概念的解说,后续还会进行补充。
一、图片集的制作
1. 图片分文件夹
还是以 Cifar10 的原图集为例,现在我们首先分 train 和 test 两个图片集(bacthes.meta.txt 包含的是 cifar10 的10个类别名字,此处可以忽略)以及其中包含图片的情况:
train 文件下为50000张图片,10个类别:
test文件夹下为10000张图片,10个类别:
注:此处只是为了方便说明,所以按这个 cifar10 数据集的分法,只分了 train 和 test 两个文件夹,如果是自己采集制作,用来研究的数据集,合理的分法还是按照一定比例(6:2:2或者其他比例)分成 train(训练) , val(验证) , test(测试)会更科学一点,这个分法 CS231n 课程中也有提到是比较合理的。
2.打标签
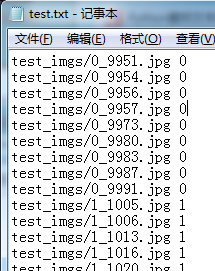
因为上面数据集的名字是有规律的,开头的数字就是这个图片的分类,所以这里我用一个Python小程序直接读取一下就行了,以 test_imgs 为例:
import os
path_img=r'C:\Users\chriszhang\Desktop\cifar_jpg\cifar_jpg\cifar-10-jpg\test_imgs'
ls = os.listdir(path_img)
b=['0','1','2','3','4','5','6','7','8','9']
print(len(ls))
with open('test.txt', 'a+') as f:
for i in ls:
if i[1] in b:
f.write('test_imgs/'+i+" "+i[0:2]+'\n' )
else:
f.write('test_imgs/'+i+ " "+ i[0] + '\n')
f.close()
就会有生成test.txt。
当我们数据集的图片并没有规律时,我一般都是用最原始的办法,先将可以打同一标签的图片放在一个文件夹中,然后运行一个 .bat 脚本批量进行标签,因为脚本运行一次,只能批量打一种标签,所以需要运行多次,再对生成的 .txt 稍加修改,再拼凑在一起,类别少的时候还是很好操作的,但是类别多的话就很麻烦了,后续编写出直接用的python小程序也会更新出来,下面贴出我使用的脚本:
生成不带绝对路径的标签脚本:
我们可以新建一个 .txt 文件,在里面输入下面的代码,然后将后缀改成 .bat,放在图片的目录下,Windows 下双击运行就可以了,下面代码的意思是寻找所有后缀名是 .jpg 的图片 然后在在他们的名字后面加 0,并写入 Label_0.txt,相应的图片格式(.jpg),标签数(0),生成文件名(Label_0.txt)都可以根据我们的要求进行修改:
@echo off
for /f "delims=" %%a in ('dir /b/a-d/oN *.jpg*') do echo %%a 0 >>Label_0.txt

生成带绝对路径的标签脚本:
具体修改项同上。
@echo off
for /f "delims=" %%a in ('dir /b/s/oN *.jpg*') do echo %%a 1 >>Label_1.txt

可以根据需求进行选择。
注:用上面脚本的时候在标签的后面还会有一个空格,这样是在生成 lmdb 文件时是会导致找不到图片的,所以还需要用文本编辑器查找替换“0 ”替换成“0”,其他标签同样。
3. 制作 lmdb 文件
当我们准备好图片和对应的标签以后,我们就可以用 Caffe 自带的函数来制作lmdb 或是 leveldb 训练使用的文件了,这里以 lmdb 为例。
如果直接输入命令行也可以转换,但是每次转换都需要输入长长的命令行,很麻烦,为了下次还能方便使用,我们需要 3 个文件,create_train_lmdb.sh , create_test_lmdb.sh, mean.sh来分别制作,train_lmdb , test_lmdb , mean.binaryproto 文件,等到下次需要制作 lmdb 文件时直接修改相应的路径运行就可以了。
create_train_lmdb.sh
#!/usr/bin/en sh
#图片和标签的路径
imgs_path="/home/t702/zrx/DeepID/dataset/cifar/cifar-10-jpg/"
list_file="/home/t702/zrx/DeepID/dataset/cifar/train.txt"
#保存 lmdb 文件的路径
dst_lmdb_file="/home/t702/zrx/DeepID/dataset/cifar10_12_45_train_lmdb"
#Caffe 文件的路径
toos_path="/home/t702/caffe/build/tools/"
rm -rf $dst_lmdb_file
$toos_path/convert_imageset --shuffle --backend="lmdb" \
--resize_height=32 --resize_width=32 $imgs_path $list_file $dst_lmdb_file
–resize_height , --resize_weight 表示调整训练时的图片大小,–shuffle 表示需要混合一下,还可以加入 --gray 将数据集编程灰度图片,具体用发参见 convert_imageset 函数的用法。
将上面的对应路径换成你的电脑相对应的路径就可以了。
然后命令行输入:
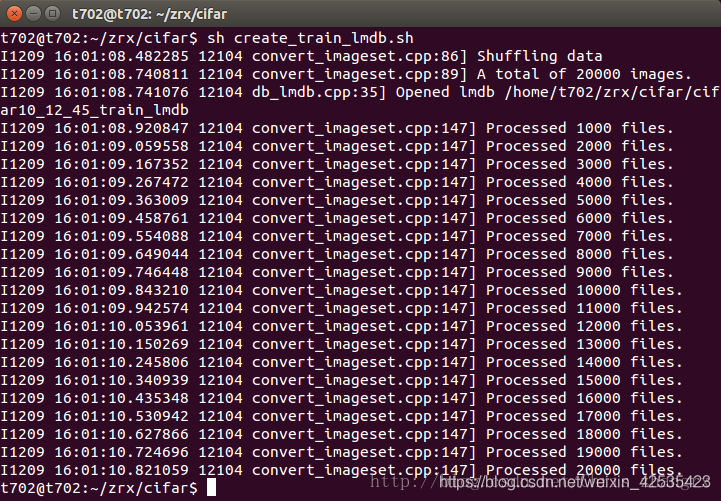
sh create_train_lmdb.sh
就会得到:
create_test_lmdb.sh
#!/usr/bin/en sh
#图片和标签的路径
imgs_path="/home/t702/zrx/cifar/cifar-10-jpg/"
list_file="/home/t702/zrx/cifar/test.txt"
#保存 lmdb 文件的路径
dst_lmdb_file="/home/t702/zrx/cifar/cifar10_12_56_test_lmdb"
#Caffe 文件的路径
toos_path="/home/t702/caffe/build/tools"
rm -rf $dst_lmdb_file
$toos_path/convert_imageset --shuffle --backend="lmdb" \
--resize_height=31 --resize_width=31 $imgs_path $list_file $dst_lmdb_file
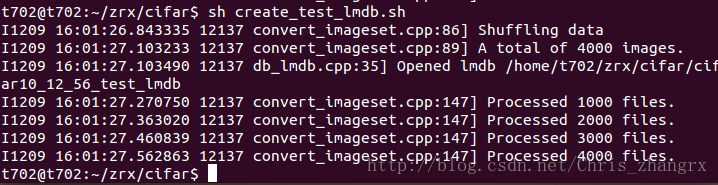
然后输入:
sh create_test_lmdb.sh
就会得到:
mean.sh
/home/t702/caffe/build/tools/compute_image_mean cifar10_train_lmdb cifar10_mean.binaryproto
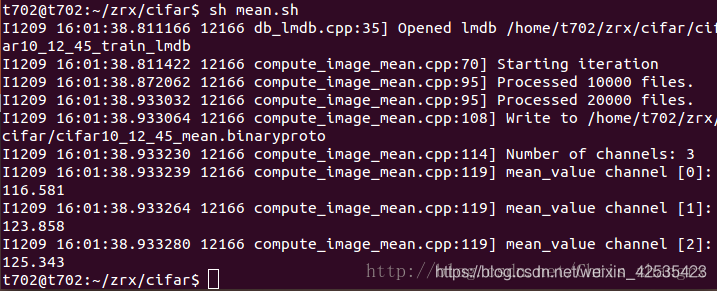
我们要用 train_lmdb 文件来计算图像均值。
然后输入:
sh mean.sh
就会得到:
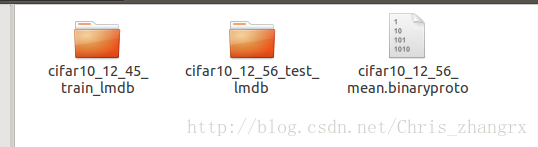
最后会得到下面3个文件:
二、训练网络
4. 开始训练
训练时我们需要train_val.prototxt ,solver.prototxt,deploy.prototxt三个文件,其中前面两个训练时是必需的,deploy.prototxt 一般只在caffemodel被调用的时候需要用到。
同样的,仿照前面生成 lmdb 时的方法,我们使用 train.sh 来训练,方便后续训练的使用。
train.sh
#!/usr/bin/en sh
/home/t702/caffe/build/tools/caffe train --solver=/home/t702/zrx/DeepID/network_gender/solver.prototxt -gpu 0 2>&1| tee train.txt
2>&1| tee train.txt 是将训练的日志同时输出到 train.txt 文件中,方便我们后续查看和调用。
三、测试性能
5. 查看 Accuracy 和 Loss
这个需要我们用 4 中的训练方法,生成一个训练日志 train.txt,然后更改后缀名,将文件名改为 train.log 。可以看到 caffe 路径下:caffe/tools/extra 文件夹下包含了下面 3 个文件: extract_seconds.py , parsh_log.sh , plot_training_log.py.example 。
将上面3个文件复制出来,放在 train.log 的路径下,然后依次运行:
sh parsh_log.sh train.log
会生成下面2个文件:
./plot_training_log.py.example 0 save.png train.log
刚开始遇到了问题报错,然后我将 train.log 文件名改为 log.log 重新尝试还是出现了一下报错:
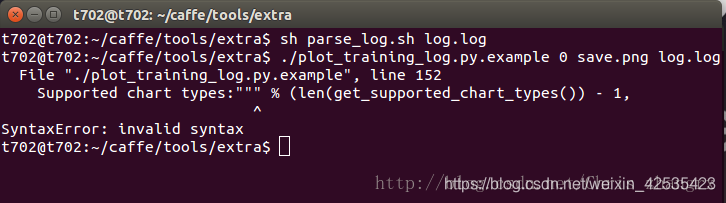
因为我目前的 Python 版本是3.6 , 而 Caffe 是在2.7版本下编译的,所以改成下面的命令:

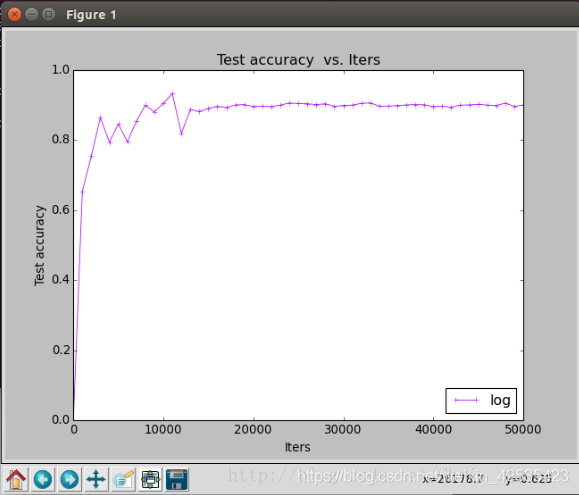
就可以正常输出下面的图片,并且将其保存为 save.png :
还有其他命令可以选择,只要更改官方说明如下:
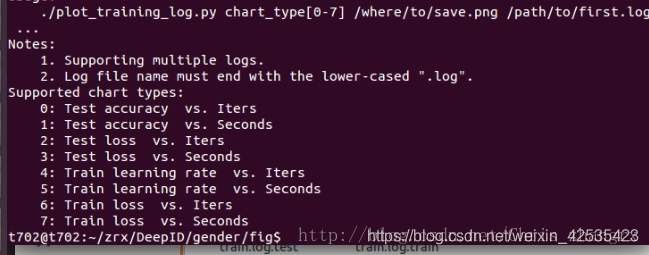
如果我们还想看 Test loss vs. Iters 直接修改为下面的命令就行了,以此类推:
./plot_training_log.py.example 2 Testloss.png train.log
6. 验证模型的准确率
上面提到,当我们自己做研究时,最合理的方法是分3个数据集,分别为,train, val, test , train用来训练, val用来调参,最后用 test 可以用来验证模型的是否出现过拟合(overfitting)/欠拟合(underfitting),以及模型的泛化性。所以在使用前我们先写一个 test.sh 文件。
#!/usr/bin/en sh
/home/t704/Downloads/caffe/build/tools/caffe test -model=/home/t704/zrx/ShuffleNet/test/test.prototxt -weights=/home/t704/zrx/ShuffleNet/snapshot/ShuffleNet_iter_100000.caffemodel
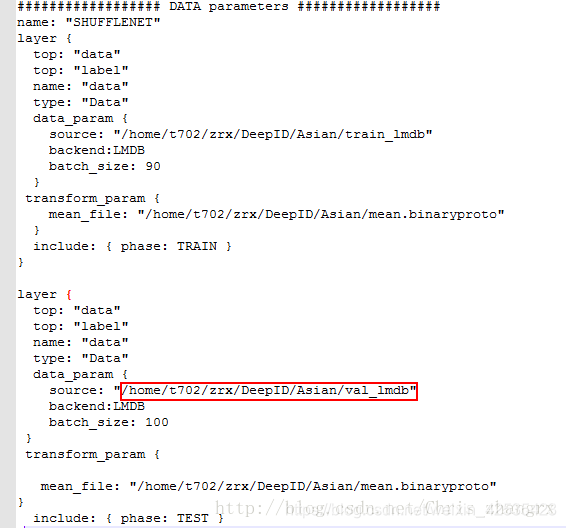
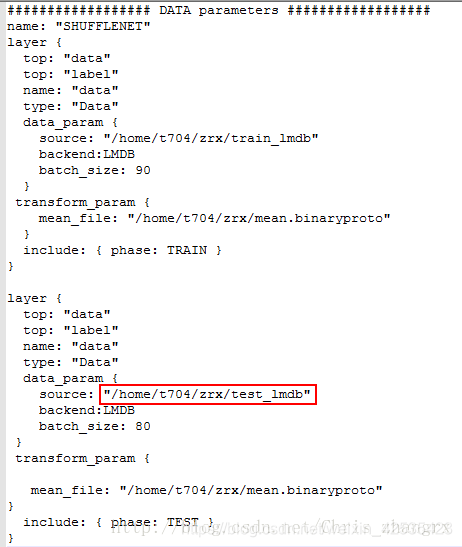
此处 test.prototxt 和 训练时的 train_val.prototxt 基本一样不同点就是,将改成测试阶段的数据集改了就行了:
train_val.prototxt:
test.prototxt:
然后:
sh test.sh
就会有如下输出:

原文链接:https://blog.csdn.net/Chris_zhangrx/article/details/78760200















 9923
9923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









