







文章目录
一、什么是智能体(AI Agent)?
从技术角度来说,**智能体(AI Agent)**是一种软件实体,旨在代表用户或其他程序自主或半自主地执行任务。这些代理利用人工智能做出决策、采取行动并与环境或其他系统进行交互。智能体的主要特征有:
自治:智能体无需人工干预即可运行。一旦被赋予目标,它们就可以独立执行任务。
决策:智能体使用算法、规则和人工智能模型, 根据自己的感知和目标做出决策。这包括评估不同的选择并选择最佳行动方案。
学习:许多智能体采用机器学习技术来提高其性能。它们可以从过去的经验中学习并适应新情况。
交互:智能体可以与用户、其他智能体或系统进行通信和协作。这种交互可能涉及自然语言处理、发送和接收数据或执行协调任务。
专业化:智能体可以专门用于特定任务或领域。例如,某些智能体可能专为网页浏览而设计,而其他智能体则可能处理数据库交互、执行复杂计算或生成图像。
目标导向:智能体通常被设定有特定的目标或目的。它们通过一系列动作和决策来实现这些目标。

总之,智能体是强大的工具,可以自动化和增强广泛的活动,从简单的重复任务到复杂的问题解决场景,这使得它们在各种应用和行业中具有无价的价值。
想象一下,将上述所有概念整合在一起,共同朝着预先确定的目标努力,实现预期结果。这些任务可以按顺序或分层流程执行,所有智能体都像一个协调的团队一样工作。这种强大的协作可以彻底改变我们处理复杂问题的方式,使流程更高效,结果更有效。这就是 CrewAI框架发挥作用的地方。
二、Ollama介绍&配置
Ollama是一款开源应用程序,可让您使用 MacOS、Linux 和 Windows 上的命令行界面在本地运行、创建和共享大型语言模型。
Ollama 可以直接从其库中访问各种 LLM,只需一个命令即可下载。下载后,只需执行一个命令即可开始使用。这对于工作量围绕终端窗口的用户非常有帮助。如果他们被困在某个地方,他们可以在不切换到另一个浏览器窗口的情况下获得答案。
2.1 特点和优点
这就是为什么 OLLAMA 是您的工具包中必备的工具:
简单 :OLLAMA 提供简单的设置过程。您无需拥有机器学习博士学位即可启动和运行它。
成本效益 :在本地运行模型意味着您无需支付云成本。您的钱包会感谢您。
隐私 :使用 OLLAMA,所有数据处理都在您的本地机器上进行。这对于用户隐私来说是一个巨大的胜利。
多功能性 :OLLAMA 不只是为 Python 爱好者准备的。它的灵活性使其可以用于各种应用程序,包括 Web 开发。
2.2 安装ollama
点击前往网站 https://ollama.com/ ,下载ollama软件,支持win、Mac、linux
2.3 下载LLM模型
默认情况下,Openai Models 在 CrewAI 中用作 llm。有经费、有网络、不担心数据泄露等条件下, 力求达到最佳性能,可考虑使用 GPT-4 或 OpenAI 稍便宜的 GPT-3.5。
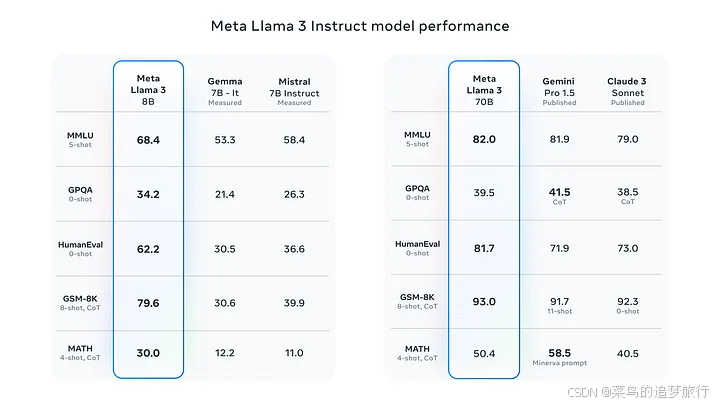
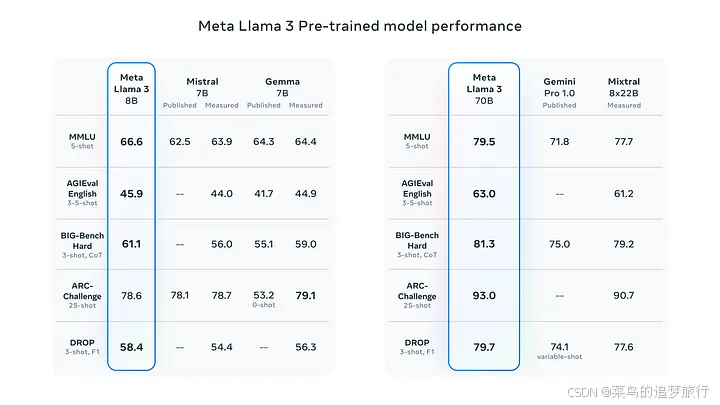
但本文是要 本地部署, 因此我们将使用 Meta Llama 3,这是迄今为止功能最强大的公开 LLM。Meta Llama 3 是 Meta Inc. 开发的模型系列,是最新推出的模型,具有 8B 和 70B 两种参数大小(预训练或指令调整)。Llama 3 指令调整模型针对对话/聊天用例进行了微调和优化,并且在常见基准测试中胜过许多可用的开源聊天模型。
打开Ollama模型页面 https://ollama.com/library, 第一个就是 Metal 近期发布的 LLama3.1 模型。
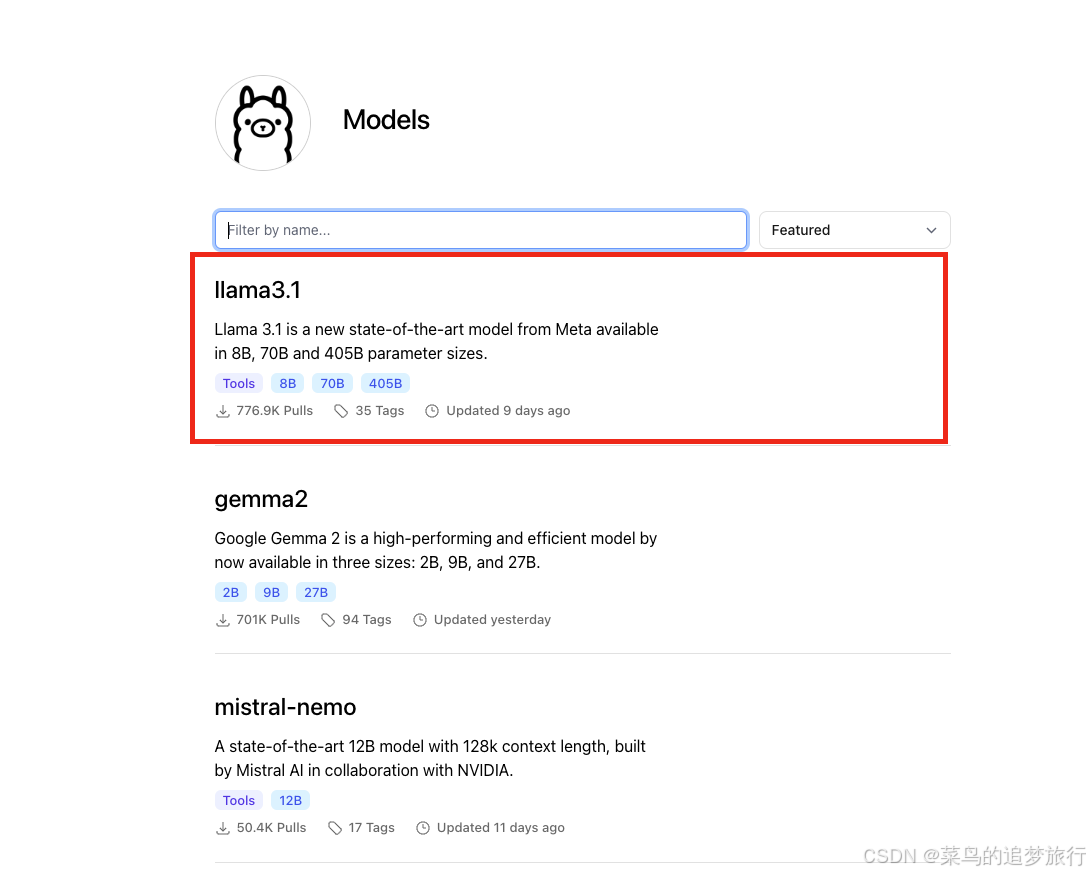
以llama3为例,根据自己电脑显存性能, 选择适宜的版本。如果不知道选什么,那就试着安装,不合适不能用再删除即可。

打开电脑命令行cmd(mac是terminal), 网络是连网状态,执行模型下载(安装)命令
ollama pull llama3.1:8b
等待 llama3.1:8b 下载完成。
2.3 启动ollama服务
ollama服务有两种启动方式,即鼠标启动ollama服务 和 命令行启动ollama服务 。
2.3.1 鼠标启动ollama服务
在电脑中找到ollama软件,双击打开,就开启了ollama本地服务。
2.3.2 命令行启动ollama服务
在Python中调用本地ollama服务,需要先启动本地ollama服务, 打开电脑命令行cmd(mac是terminal), 执行
ollama serve
Run
2024/06/14 14:52:24 routes.go:1011: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/Users/deng/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"
time=2024-06-14T14:52:24.742+08:00 level=INFO source=images.go:725 msg="total blobs: 18"
time=2024-06-14T14:52:24.742+08:00 level=INFO source=images.go:732 msg="total unused blobs removed: 0"
time=2024-06-14T14:52:24.743+08:00 level=INFO source=routes.go:1057 msg="Listening on 127.0.0.1:11434 (version 0.1.44)"
time=2024-06-14T14:52:24.744+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/var/folders/y0/4gqxky0s2t94x1c1qhlwr6100000gn/T/ollama4239159529/runners
time=2024-06-14T14:52:24.772+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [metal]"
time=2024-06-14T14:52:24.796+08:00 level=INFO source=types.go:71 msg="inference compute" id=0 library=metal compute="" driver=0.0 name="" total="72.0 GiB" available="72.0 GiB"
cmd(mac是terminal)看到如上的信息,说明本地ollama服务已开启。
三、CrewAI框架介绍
CrewAi 是一个用于协调角色扮演、自主 AI 代理的尖端框架。通过促进协作智能,CrewAI 使代理能够无缝协作,解决复杂的任务。
3.1 安装crew
打开电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip3 install crewai
pip3 install langchain_openai
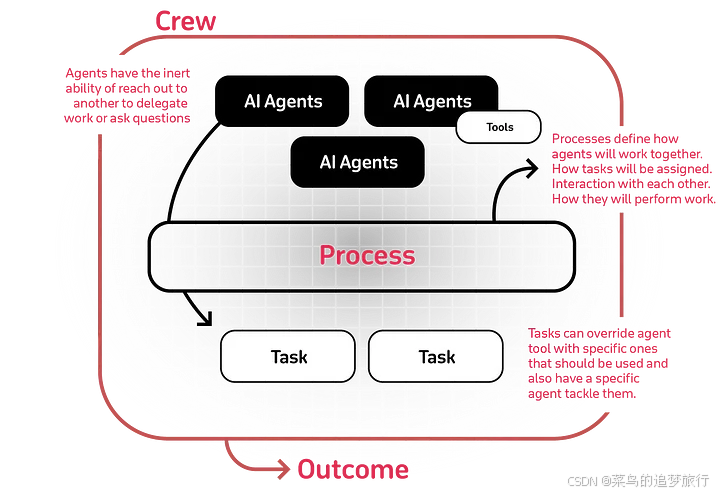
3.2 CrewAI核心概念
- 智能体(Agents):这些是经过编程的独立单元,用于执行任务、做出决策和与其他代理进行通信。它们可以使用的 工具Tools
可以是简单的搜索功能,也可以是涉及其他链、API 等的复杂集成。 - 任务(Tasks):任务是智能体需要完成的任务或工作。它们可以包含其他信息,例如哪个代理应该执行该任务以及它们可能需要哪些工具。
- 团队(Crew) 一个团队是由一群智能体组成的,每个 智能体(Agent)
都有特定的角色,他们齐心协力实现共同目标。组建团队的过程包括召集代理、定义他们的任务以及建立任务执行顺序。
四、实验代码
大邓是一个技术博主,运营着公众号,每天要消耗大量的时间进行选题、创作、编辑。随着LLM的流行, 能否让LLM替我进行选题、创作、编辑,从此进入躺平式人生新阶段。在实验章节, 代码内容将分为
- 调用llm
- 设置agent
- 设置task
- 组装成crew
- 最终运行
4.1 调用LLM
在Python中调用开启的ollama服务, 为crewai调用llm做准备。
from langchain_openai import ChatOpenAI
import os
#将ollama的api转化为OPENAI式的api,方便crewai调用
#设置系统环境变量OPENAI_API_BASE和OPENAI_API_KEY
os.environ["OPENAI_API_BASE"] = "http://localhost:11434/v1"
os.environ["OPENAI_API_KEY"] = "NA"
llama_model = ChatOpenAI(model = "llama3.1:8b")
4.2 设置Agent
大邓运营的公众号的日常,一个人身兼数个职位。 大致拆分成三个员工(智能体)
- 内容策划专员
- 内容创作专员
- 内容编辑专员
from crewai import Agent
planner = Agent(
role = "内容策划专员",
goal = "策划有关{topic}的引人入胜且事实准确的内容",
backstory = (
"您是一名内容策划专员,正在计划撰写一篇主题为“{topic}”的博客文章, "
"文章将发布在 'https://medium.com/'。"
"您收集的信息可帮助受众了解某些内容,使受众能因此做出明智的决定。"
"您必须准备一份详细的大纲,博客文章中应包含的相关主题和子主题。"
"您的工作是内容创作专员撰写此主题文章的基础。"
"工作语言是中文。"
),
llm = llama_model,
allow_delegation = False,
verbose = True
)
writer = Agent(
role = "内容创作专员",
goal = "撰写主题{topic}的评论文章,要深刻且事实准确",
backstory = (
"您是一名内容编辑专员,正在撰写一篇主题 “{topic}” 的新观点文章, "
"文章将发表在 'https://medium.com/'。"
"内容策划师提供了有关该主题的大纲和相关背景。"
"您创作内容时,请遵循内容策划师提供的大纲为主要目标和方向。"
"同时您将提供客观公正的见解,并使用内容策划师提供的信息支持您的见解。"
"您在观点文章中承认您的陈述是意见,而不是客观陈述。"
"工作语言是中文。"
),
allow_delegation = False,
llm = llama_model,
verbose = True
)
editor = Agent(
role = "内容编辑专员",
goal = "编辑给定的博客文章,以符合网站 'https://medium.com/' 的写作风格",
backstory = (
"您是一名内容编辑专员,收到内容创作专员发来的博客文章。"
"您的目标是审核博客文章,确保其符合新闻业最佳实践,"
"在发表意见或主张时提供平衡的观点,并尽可能避免重大争议话题或意见。"
"工作语言是中文。"
),
llm = llama_model,
allow_delegation = False,
verbose = True
)
参数解读
crewai.Agent(role, goal, backstory, llm, tools, function_calling_llm=None, maxter=25, max_execution_time=None, verbose=False, allow_delegation=True, step_callback=None, cache=True, max_retry_limit=2)
- role: 定义代理在团队中的职能。它决定了代理最适合执行的任务类型。
- goal : 代理希望实现的个体目标。它指导代理的决策过程。
- backstory:为代理的角色和目标提供背景,丰富互动和协作动力。
- llm:(可选)表示将运行代理的语言模型。它从OPENAI_MODEL_NAME环境变量中动态获取模型名称,如果未指定,则默认为
“gpt-4”。 - tools:(可选)代理可用于执行任务的功能或函数集。应为与代理的执行环境兼容的自定义类的实例。工具使用空列表的默认值进行初始化。
- function_calling_llm:(可选)指定处理此代理的工具调用的语言模型,如果已传递,则覆盖工作人员函数调用 LLM。默认值为
None。 - maxter:(可选)代理在被迫给出最佳答案之前可以执行的最大迭代次数。默认值为25。
- max_rpm:(可选)代理每分钟可以执行的最大请求数,以避免速率限制。它是可选的,可以不指定,默认值为None。
- max_execution_time:(可选)代理执行任务的最大执行时间。它是可选的,可以不指定,默认值为 None,表示没有最大执行时间
- verbose:(可选)将其设置为 True配置内部记录器以提供详细的执行日志,帮助调试和监控。默认值为False。
- allow_delegation: (可选)代理可以相互委派任务或问题,确保每项任务都由最合适的代理处理。默认值为True。
- step_callback:
(可选)代理每执行一步后调用的函数。可用于记录代理的操作或执行其他操作。它将覆盖工作人员step_callback。默认值None。 - cache: (可选)指示代理是否应使用缓存来使用工具。默认值为True
4.3 设置Task
大邓三个智能体角色(内容策划专员、内容创作专员、内容策划专员), 都各自有对应的 任务(plan、write、edit)。 这里需要设置每种任务,的工作任务(内容)、预期产出。
from crewai import Task
plan = Task(
description = (
"1. 优先考虑“{topic}”的最新趋势、关键参与者和值得关注的新闻。\n"
"2. 确定目标受众,考虑他们的兴趣和痛点。\n"
"3. 制定详细的内容大纲,包括简介、要点和行动号召。\n"
"4. 包括 SEO 关键字和相关数据或来源。"
),
expected_output = "一份全面的内容计划文档,其中包含大纲、受众分析、SEO 关键字和参考资源。",
agent = planner,
)
write = Task(
description = (
"1. 使用内容策划专员的内容策划,撰写一篇关于“{topic}”的引人入胜的博客文章。\n"
"2. 自然地融入 SEO 关键词。\n"
"3. 章节/副标题以引人入胜的方式正确命名。\n"
"4. 确保文章结构合理,有引人入胜的介绍、有见地的正文和总结性结论。\n"
"5. 校对语法错误并与品牌调性保持一致。\n"
),
expected_output = "一篇写得很好的、准备发布的 Markdown 格式的博客文章,每个部分应该有 2 或 3 个段落。",
agent = writer,
)
edit = Task(
description = (
"校对给定的博客文章"
"检查其语法错误并与品牌调性保持一致。"
),
expected_output = "一篇写得很好的、准备发布的 Markdown 格式的博客文章,每个部分应该有 2 或 3 个段落。",
agent = editor
)
参数解读
crewai.Task(description, agent, expected_output, tools=None, async_execution=False, context=None, config=None, output_json=None, output_pydantic=None, output_file=None, human_input=False)
- description: 对任务内容的清晰、简洁的陈述。
- agent :负责该任务的代理人,可直接指派或由机组人员流程指派。
- expected_output : 任务完成情况的详细描述。
- tools:(可选)代理可以利用执行任务的功能或能力。默认值None。
- async_execution:(可选)如果设置,任务将异步执行,允许进展而无需等待完成。默认值False。
- context: (可选)指定其输出用作此任务的上下文的任务。默认值None。
- config:(可选)执行任务的代理的附加配置详细信息,允许进一步定制。默认值None。
- output_json:(可选)输出 JSON 对象,需要 OpenAI 客户端。只能设置一种输出格式。默认值None。
- output_pydantic:(可选)输出 Pydantic 模型对象,需要 OpenAI
客户端。只能设置一种输出格式。默认值None。 - output_file:(可选)将任务输出保存到文件。如果与Output JSON或一起使用Output
Pydantic,则指定如何保存输出。默认值None。 - callback:(可选)在完成任务后,使用任务的输出执行的 Python 可调用函数。默认值None。
- human_input:(可选)表示任务是否在最后需要人工反馈,对于需要人工监督的任务很有用。默认值False。
4.4 组装&运行
将大邓三个角色(planner, writer, editor) 及对应的任务(plan, write, edit)组装成一个整体crew, 并试着让程序以 「topic: Python做文本分析」 为题进行创作。
#组装成CREW
crew = Crew(
agents = [planner, writer, editor],
tasks = [plan, write, edit],
verbose = 2
)
#撰写一个Topic: "在管理学领域,如何用Python做文本分析" 的文章
inputs = {"topic": "Python文本分析"}
result = crew.kickoff(inputs=inputs)
Run
请看原文链接
五、渲染内容
将智能体生成的内容渲染, 一起欣赏AI生成的内容。
from IPython.display import Markdown,display
display(Markdown(dict(dict(result)['tasks_output'][0])['raw']))

生成的内容一般, 看来暂时还无法躺平。虽然做不了太难的事情,但是我感觉让智能体做数据标注、信息提取, 应该问题不大。 大家可以再试试。希望通过本文的实战案例, 让大家快速熟悉并上手 Ollama 和 CrewAI框架 , 力争让大家都能自己在本地搭建多智能体自动化工具。
相关内容
arXiv2024 | 使用大语言模型自动进行定性研究中的扎根理论开发
实验 | 使用本地大模型从文本中提取结构化信息
实验 | 使用本地大模型DIY制作单词书教案PDF
实验 | 使用本地大模型从论文PDF中提取结构化信息
LIST | 可供社科(经管)领域使用的数据集汇总
LIST | 社科(经管)数据挖掘文献资料汇总
推荐 | 文本分析库cntext2.x使用手册
付费视频课 | Python实证指标构建与文本分析

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









