










LMDeploy 大模型量化部署实践
大模型部署背景
模型部署
定义:
1、将训练好的模型在特定的软硬件环境中启动的过程,使模型能够接收输入并返回预测效果
2、为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速
产品形态
云端、边缘计算端,移动端等
计算设备
CPU,GPU,NPU,TPU等
大模型特点
内存开销巨大
庞大的参数量。7B模型仅权重就需要14+G的内存
采用自回归生成token,需要缓存Attention 的k/v
带来巨大的内存开销
动态shape
请求数不固定
Token诸葛生成,且数量不定
相对视觉模型,LLM结构简单
Transformers 结构,大部分是decoder-only
大模型部署挑战
设备
如何应对巨大的存储问题?低存储设备(消费级显卡,手机等)如何部署?
推理
如何加速token的生成速度
如何解决动态shape,让推理可以不间断(多个batch中token长度可能不一样,不可能让token短的等token长的完成后才能继续下一个)
如何有效管理和利用内存
服务
如何提升系统整体吞吐量?
对于个体用户,如何降低响应时间?
大模型部署方案
技术点
模型并行:transformer计算和访存优化
低比特量化:Continuous Batch(解决动态shape问题)
Page Attention
方案
huggingface transformers
专门的推理加速框架
LMDeploy 简介
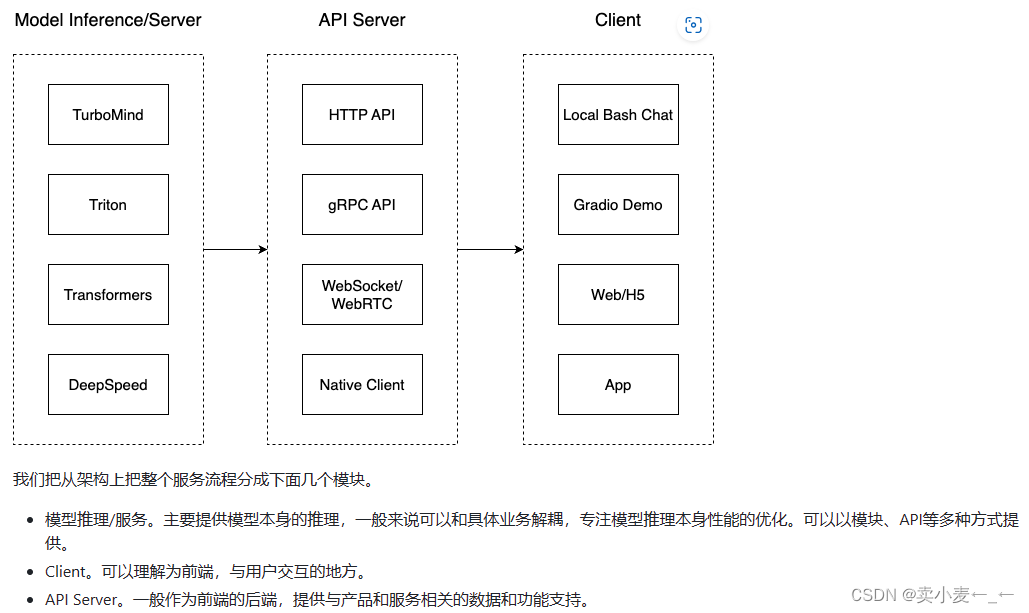
LMDeploy 是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。

高效推理引擎
持续批处理技巧
Blocked k/v cache
深度优化的计算kernels
动态分割与融合
完备易用的工具链
量化、推理、服务全流程
无缝对接opencompass评测推理精度
多维度推理速度评测工具
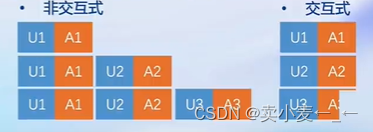
支持交互式推理,不为历史对话买单
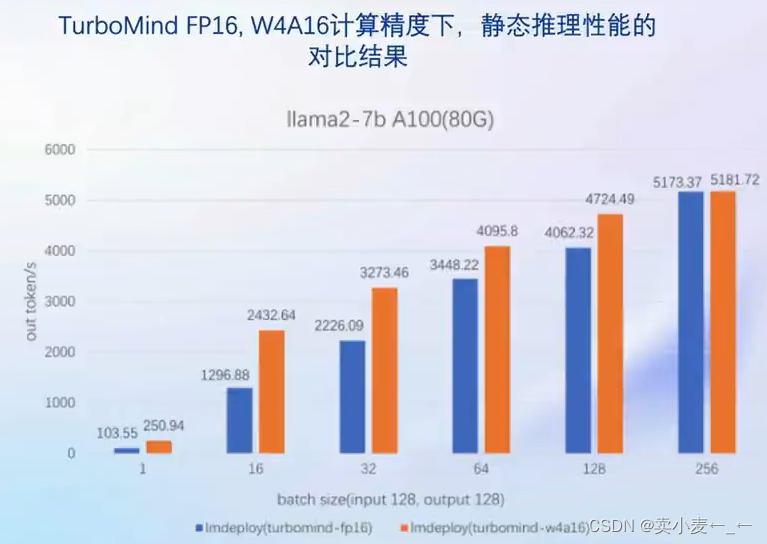
推理性能
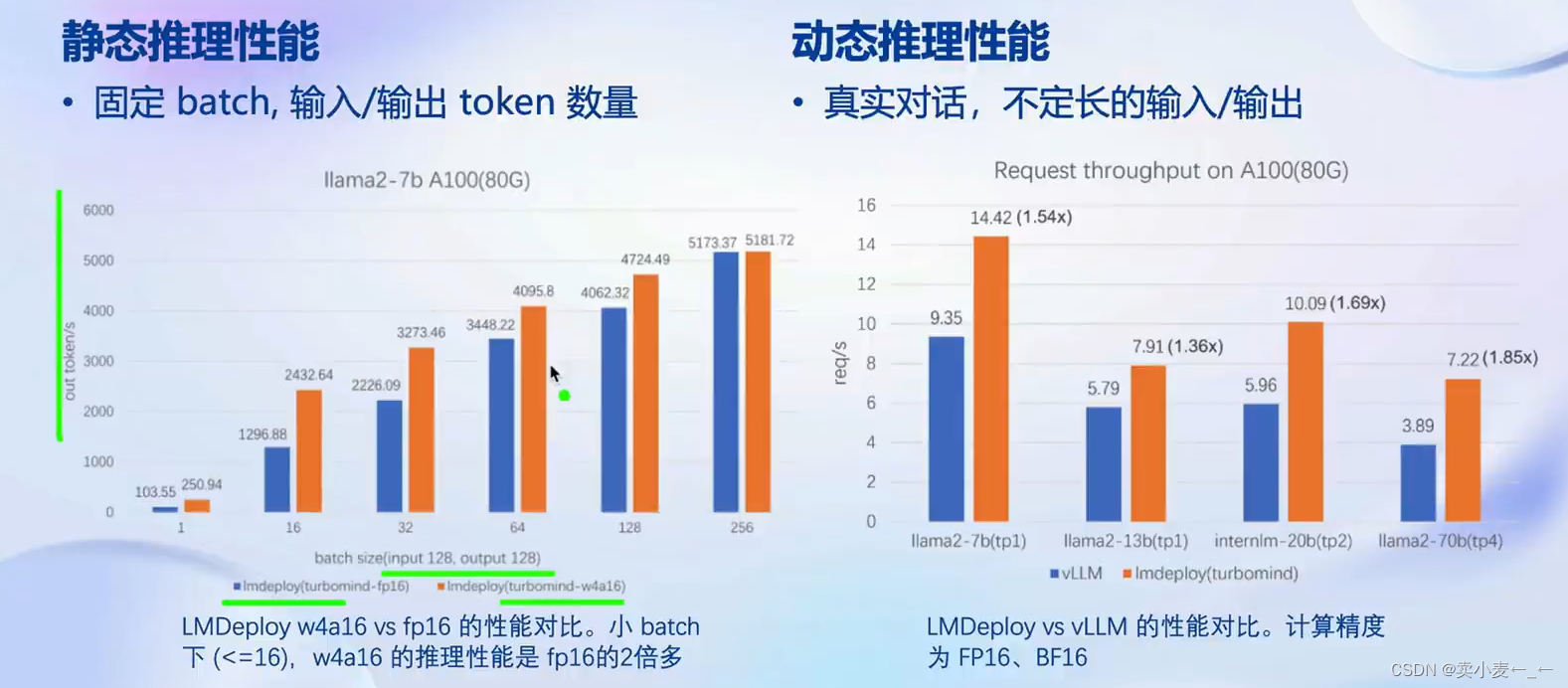
核心功能
量化
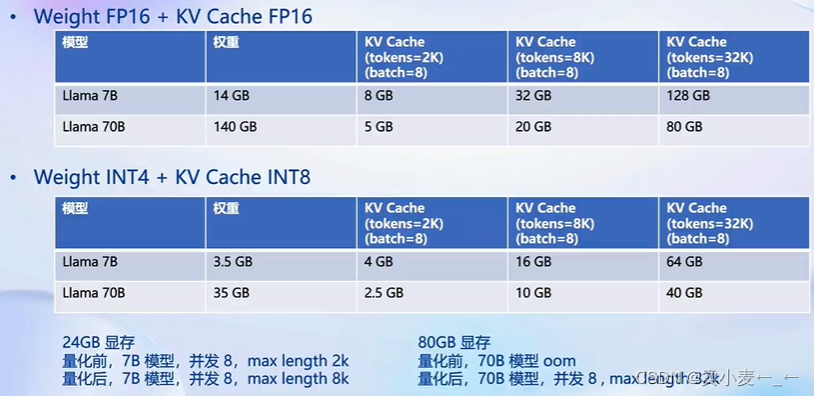
为什么要做量化?
最直观的答案是我爱我的显存,我希望有限的显存能做更多的事
如下图所示,量化后的模型权重缩小,节省显存,并且提高推理速度
两个基本概念
计算密集:推理的绝大部分时间消耗在数值计算上;针对计算密集场景,可以通过使用更快的硬件计算单元来提升计算速度,比如量化为W8A8使用INT8 Tensor Core 来加速计算
访问密集:推理时,绝大部分时间消耗在数据读取上;针对访问密集型场景,一般是通过提高计算访存比来提升性能
LLM是典型的访存密集型任务
常见的LLM模型是Decoder only架构。推理时大部分时间消耗在逐token生成阶段(Decoding 阶段),是典型的访存密集型场景。
Weight Only量化一举多得
- 4bit weight Only量化,将FP16的模型权重量化为int4,访存量直接将为FP16模型的1/4,大幅降低了访存成本,提高Decoding的速度
- 加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度
如何做Weight Only量化?
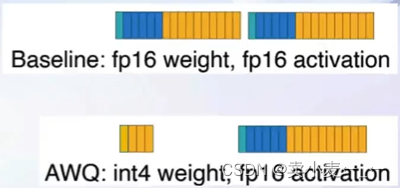
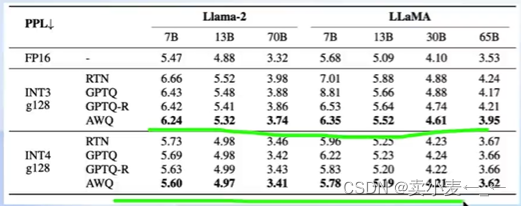
- LMdeploy使用MIT HAN LAB开源的AWQ算法,量化为4bit模型(核心思想是一小部分最重要的参数不量化,这样性能得到最大的保留,同时显存占用也有显著的下降)
- 推理时,先把4bit权重,反量化为FP16(在Kernel内部进行,从Global Memory读取时仍是4bit),依旧使用的是FP16计算
- 相比于社区使用较多的GPTQ算法,AWQ的推理速度更快,量化的时间更短
推理引擎 TurboMind
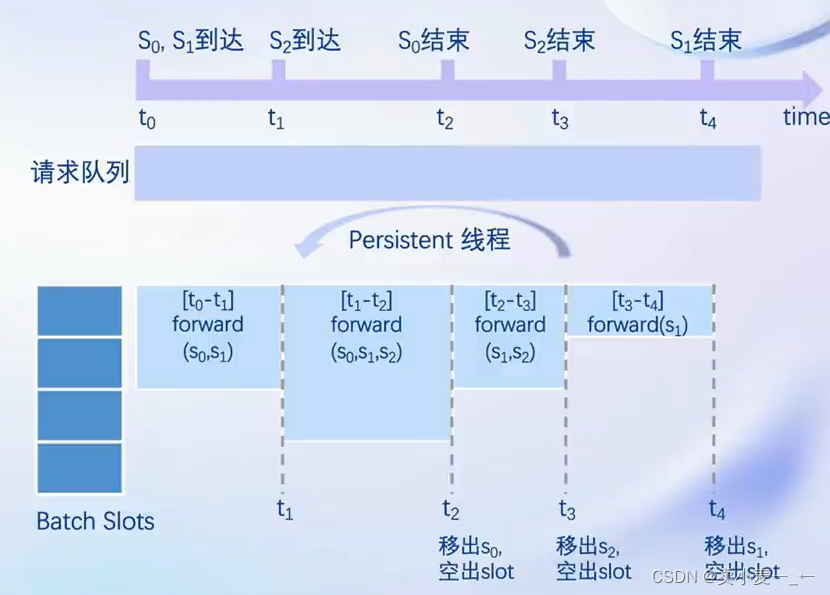
持续批处理
请求可以及时加入batch中推理
Batch中已经完成推理的请求及时退出
请求队列
推理时请求首先加入到请求队列中
Persistent线程
1、若batch中有空闲槽位,从队列拉取请求,尽量填满空闲槽位。若无,继续对当前batch中的请求进行forward
2、Batch每forward完一次,判断是否有request推理结束。结束的request,发送结果,释放槽位,继续步骤1
有状态的推理
对话token被缓存在推理侧
用户侧请求无需带上历史对话记录

第一个请求U1到达,创建新的序列。推理完成后输入,输出token以及k/v block会保存下来
当后续请求U1,U2到达,命中序列。推理完成后,输入、输出token更新到序列的token数组,新申请的k/v block加入到序列的block数组中
即server端会帮你保存上下文,并且理论上token是无限长的,具体性能要看服务器支持
Blocked k/v cache
Attention 支持不连续的 k/v block(Paged Attention)

Block状态:
Free 未被任何序列占用
Active 被正在推理的序列占用
Cache 被缓存中的序列占用

高性能 cuda kernel
Flash Attention 2
Split-K decoding
高效的w4a16,kv8 反量化kernel
算子融合
推理服务 api server
一行代码调用api
lmdeploy serve api_server InternLM/internlm-chat-7b --model-name internlm-chat-7b --server-port 8080
Swagger地址:http://0.0.0.0:8080
通过swagger ui查看并体验api server的RESTful接口。前3个和openai接口保持一致,后面的是lmdeploy专有api
动手实践环节
安装
创建开发机
这里 /share/conda_envs 目录下的环境是官方未大家准备好的基础环境,因为该目录是共享只读的,而我们后面需要在此基础上安装新的软件包,所以需要复制到我们自己的 conda 环境(该环境下我们是可写的)。
$ conda create -n CONDA_ENV_NAME --clone /share/conda_envs/internlm-base
然后激活环境。
$ conda activate lmdeploy
lmdeploy 没有安装,我们接下来手动安装一下,建议安装最新的稳定版。 如果是在 InternStudio 开发环境,需要先运行下面的命令,否则会报错。
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
由于默认安装的是 runtime 依赖包,但是我们这里还需要部署和量化,所以,这里选择 [all]。
pip install 'lmdeploy[all]==v0.1.0'
部署
模型转换
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
在线转换
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
# 需要能访问 Huggingface 的网络环境
export HF_ENDPOINT=https://hf-mirror.com
# 加载使用 lmdeploy 量化的版本
lmdeploy chat turbomind internlm/internlm-chat-20b-4bit --model-name internlm-chat-20b
# 加载其他 LLM 模型
lmdeploy chat turbomind Qwen/Qwen-7B-Chat --model-name qwen-7b
直接启动本地的 Huggingface 模型,如下所示。
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
离线转换
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式
# 转换模型(FastTransformer格式) TurboMind
lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b
这里我们使用官方提供的模型文件,就在用户根目录执行,如下所示。
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
weights 和 tokenizer 目录分别放的是拆分后的参数和 Tokenizer
执行 lmdeploy convert 命令时,可以通过 --tp 指定(tp 表示 tensor parallel),该参数默认值为1(也就是一张卡)。
关于Tensor并行
简单来说,就是把一个大的张量(参数)分到多张卡上,分别计算各部分的结果,然后再同步汇总。
Tensor并行一般分为行并行或列并行
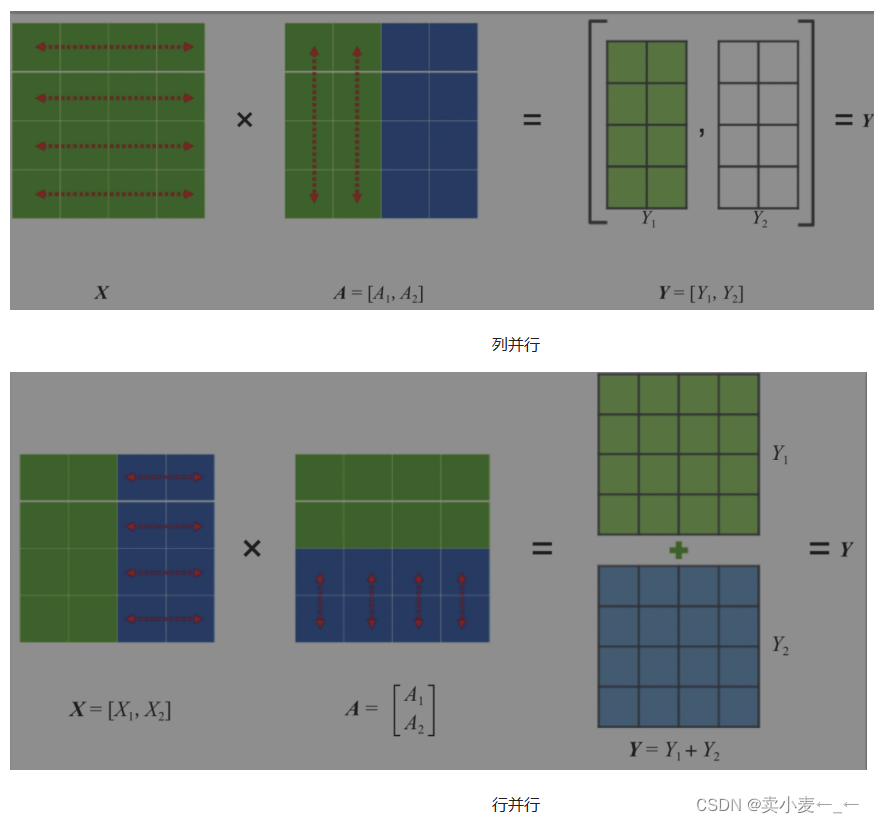
TurboMind 推理+命令行本地对话
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind
这里支持多种方式运行,比如Turbomind、PyTorch、DeepSpeed。但Pytorch/DeepSpeed 目前功能都比较弱,不具备生产能力,不推荐使用。
执行命令如下。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace
启动后就可以和它进行对话了
TurboMind推理+API服务
在上面的部分我们尝试了直接用命令行启动 Client,接下来我们尝试如何运用 lmdepoy 进行服务化。
通过下面命令启动服务。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
上面的参数中 server_name 和 server_port 分别表示服务地址和端口,tp 参数我们之前已经提到过了,表示 Tensor 并行。还剩下一个 instance_num 参数,表示实例数,可以理解成 Batch 的大小
新开一个窗口,执行以下命令
lmdeploy serve api_client http://localhost:23333
既然是 API Server,自然也有相应的接口。可以直接打开 http://{host}:23333 查看
由于 Server 在远程服务器上,本地需要做一下 ssh 转发才能直接访问,命令如下:
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的ssh端口号>
网页 Demo 演示
这一部分主要是将 Gradio 作为前端 Demo 演示。在上一节的基础上,我们不执行后面的 api_client 或 triton_client,而是执行 gradio。
TurboMind 服务作为后端
API Server 的启动和上一节一样,这里直接启动作为前端的 Gradio。
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
TurboMind 推理作为后端
当然,Gradio 也可以直接和 TurboMind 连接,如下所示。
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
可以直接启动 Gradio,此时没有 API Server,TurboMind 直接与 Gradio 通信
TurboMind 推理 + Python 代码集成
前面介绍的都是通过 API 或某种前端与”模型推理/服务“进行交互,lmdeploy 还支持 Python 直接与 TurboMind 进行交互,如下所示。
from lmdeploy import turbomind as tm
# load model
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
query = "你好啊兄嘚"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)
在上面的代码中,我们首先加载模型,然后构造输入,最后执行推理
加载模型可以显式指定模型路径,也可以直接指定 Huggingface 的 repo_id,还可以使用上面生成过的 workspace。这里的 tm.TurboMind 其实是对 C++ TurboMind 的封装。
构造输入这里主要是把用户的 query 构造成 InternLLM 支持的输入格式,比如上面的例子中, query 是“你好啊兄嘚”,构造好的 Prompt
"""
<|System|>:You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
<|User|>:你好啊兄嘚
<|Bot|>:
"""
最佳实践
方案实践
执行我们提供的 infer_compare.py 脚本,示例如下。
# 执行 Huggingface 的 Transformer
python infer_compare.py hf
# 执行LMDeploy
python infer_compare.py lmdeploy
- 我想对外提供类似 OpenAI 那样的 HTTP 接口服务。推荐使用 TurboMind推理 + API 服务。
- 我想做一个演示 Demo,Gradio 无疑是比 Local Chat 更友好的。推荐使用 TurboMind 推理作为后端的Gradio进行演示)。
- 我想直接在自己的 Python 项目中使用大模型功能。推荐使用 TurboMind推理 + Python。
- 我想在自己的其他非 Python 项目中使用大模型功能。推荐直接通过 HTTP 接口调用服务。也就是用本列表第一条先启动一个 HTTP API 服务,然后在项目中直接调用接口。
- 我的项目是 C++ 写的,为什么不能直接用 TurboMind 的 C++ 接口?
模型配置实践
模型相关的配置信息
模型属性相关的参数不可更改,主要包括下面这些。
model_name = llama2
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128
和数据类型相关的参数也不可更改,主要包括两个。
weight_type = fp16
group_size = 0
weight_type 表示权重的数据类型。目前支持 fp16 和 int4。int4 表示 4bit 权重。当 weight_type 为 4bit 权重时,group_size 表示 awq 量化权重时使用的 group 大小
- KV int8 开关:
- 对应参数为 quant_policy,默认值为 0,表示不使用 KV Cache,如果需要开启,则将该参数设置为 4。
- KV Cache 是对序列生成过程中的 K 和 V 进行量化,用以节省显存。我们下一部分会介绍具体的量化过程。
- 当显存不足,或序列比较长时,建议打开此开关。
- 外推能力开关:
- 对应参数为 rope_scaling_factor,默认值为 0.0,表示不具备外推能力,设置为 1.0,可以开启 RoPE 的 Dynamic NTK 功能,支持长文本推理。另外,use_logn_attn 参数表示 Attention 缩放,默认值为 0,如果要开启,可以将其改为 1。
- 外推能力是指推理时上下文的长度超过训练时的最大长度时模型生成的能力。如果没有外推能力,当推理时上下文长度超过训练时的最大长度,效果会急剧下降。相反,则下降不那么明显,当然如果超出太多,效果也会下降的厉害。
- 当推理文本非常长(明显超过了训练时的最大长度)时,建议开启外推能力。
- 批处理大小:
- 对应参数为 max_batch_size,默认为 64,也就是我们在 API Server 启动时的 instance_num 参数。
- 该参数值越大,吞度量越大(同时接受的请求数),但也会占用更多显存。
- 建议根据请求量和最大的上下文长度,按实际情况调整
量化
我们可以使用 KV Cache 量化和 4bit Weight Only 量化(W4A16)。KV Cache 量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用
KV Cache 量化
KV Cache 量化是将已经生成序列的 KV 变成 Int8,使用过程一共包括三步:
第一步:计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况
由于默认需要从 Huggingface 下载数据集,国内经常不成功。所以我们导出了需要的数据,大家需要对读取数据集的代码文件做一下替换。共包括两步:
第一步:复制 calib_dataloader.py 到安装目录替换该文件:
cp /root/share/temp/datasets/c4/calib_dataloader.py /root/.conda/envs/lmdeploy/lib/python3.10/site-packages/lmdeploy/lite/utils/
第二步:将用到的数据集(c4)复制到下面的目录:
cp -r /root/share/temp/datasets/c4/ /root/.cache/huggingface/datasets/
第一步执行命令如下:
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output
第二步:通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值(zp)和缩放值(scale)。
zp = (min+max) / 2
scale = (max-min) / 255
quant: q = round( (f-zp) / scale)
dequant: f = q * scale + zp
其实就是对历史的 K 和 V 存储 quant 后的值,使用时在 dequant
执行命令如下:
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1
第三步:修改配置。也就是修改 weights/config.ini 文件,这个我们在模型配置实践中已经提到过了(KV int8 开关),只需要把 quant_policy 改为 4 即可。
这一步需要额外说明的是,如果用的是 TurboMind1.0,还需要修改参数 use_context_fmha,将其改为 0
W4A16 量化
量化步骤
第一步:同上
第二步:量化权重模型。利用第一步得到的统计值对参数进行量化,具体又包括两小步:
缩放参数,主要是性能上的考虑。
整体量化。
第二步的执行命令如下:
# 量化权重模型
lmdeploy lite auto_awq \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--w_bits 4 \
--w_group_size 128 \
--work_dir ./quant_output
命令中 w_bits 表示量化的位数,w_group_size 表示量化分组统计的尺寸,work_dir 是量化后模型输出的位置。这里需要特别说明的是,因为没有 torch.int4,所以实际存储时,8个 4bit 权重会被打包到一个 int32 值中。所以,如果你把这部分量化后的参数加载进来就会发现它们是 int32 类型的。
最后一步:转换成 TurboMind 格式。
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128
这个 group-size 就是上一步的那个 w_group_size。如果不想和之前的 workspace 重复,可以指定输出目录:–dst_path,比如:
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128 \
--dst_path ./workspace_quant
最佳实践
量化的最主要目的是降低显存占用,主要包括两方面的显存:模型参数和中间过程计算结果
量化在降低显存的同时,一般还能带来性能的提升,因为更小精度的浮点数要比高精度的浮点数计算效率高,而整型要比浮点数高很多。
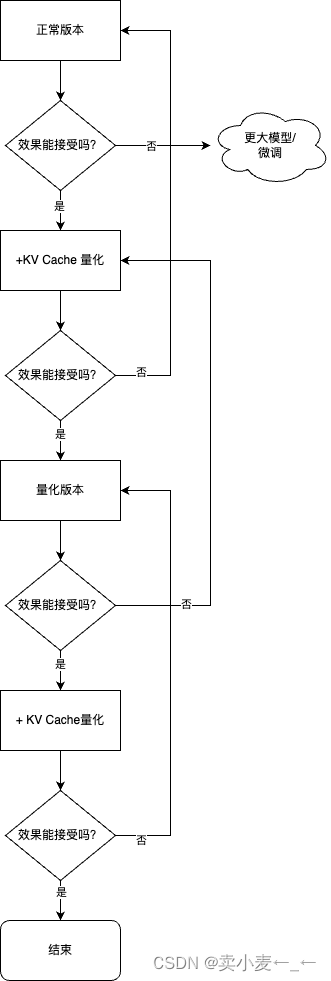
所以我们的建议是:在各种配置下尝试,看效果能否满足需要。这一般需要在自己的数据集上进行测试。具体步骤如下。
Step1:优先尝试正常(非量化)版本,评估效果。
如果效果不行,需要尝试更大参数模型或者微调。
如果效果可以,跳到下一步。
Step2:尝试正常版本+KV Cache 量化,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step3:尝试量化版本,评估效果。
如果效果不行,回到上一步。
如果效果可以,跳到下一步。
Step4:尝试量化版本+ KV Cache 量化,评估效果。
如果效果不行,回到上一步。
如果效果可以,使用方案。
根据实践经验,一般情况下:
-
精度越高,显存占用越多,推理效率越低,但一般效果较好。
-
Server 端推理一般用非量化版本或半精度、BF16、Int8 等精度的量化版本,比较少使用更低精度的量化版本。
-
端侧推理一般都使用量化版本,且大多是低精度的量化版本。这主要是因为计算资源所限。
以上是针对项目开发情况,如果是自己尝试(玩儿)的话: -
如果资源足够(有GPU卡很重要),那就用非量化的正常版本。
-
如果没有 GPU 卡,只有 CPU(不管什么芯片),那还是尝试量化版本。
-
如果生成文本长度很长,显存不够,就开启 KV Cache
TritonServer 作为推理引擎
把TurboMind 换成了 TritonServer















 6913
6913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









