






该论文于2017年发表在ACL,主要讲了智能问答在sq和wq两个数据集上的性能提升,本人研究生方向为这个,故翻译此论文,希望对大家有用。
论文地址:Improved Neural Relation Detection for Knowledge Base Question Answering
摘要
关系检测是包括知识库(KBQA)在内的许多NLP应用程序的核心组件。在本文中,我们提出一种利用残差学习增强的递归递阶神经网络来检测给定输入问题的知识库关系。我们的方法使用深度剩余双向LSTMs通过不同的抽象级别来比较问题和关系名。另外,我们提出了一个简单的KBQA系统,该系统集成了实体链接和我们提出的关系检测器,使两个组件相互增强。我们的实验结果表明,我们的方法不仅实现了杰出的关系检测性能,更重要的是,它帮助我们的KBQA系统在单关系(简单问题)和多关系(WebQSP) QA基准测试方面达到了最先进的精度。
1 介绍
知识库问答(KBQA)系统通过从知识库元组获取信息来回答问题(Berant et al., 2013;Yao et al., 2014;Bordes等人,2015;巴斯特和豪斯曼,2015;Yih et al., 2015;徐等人,2016)。对于输入问题,这些系统通常生成一个KB查询,可以执行该查询从KB中检索答案。图1演示了在KBQA系统中解析两个示例问题的过程:(a)单个关系问题,可以用单个<head-entity, relation, tail-entity> KB tuple (Fader et al., 2013;Yih等,2014;Bordes等人,2015);以及(b)更复杂的情况,即需要为问题中的多个实体处理一些约束。图中的KBQA系统执行两个关键任务:(1)实体链接,它将问题中的n-gram链接到KB实体;(2)关系检测,它识别问题所引用的KB关系。
这项工作的主要重点是改进关系检测子任务,并进一步探索它如何对KBQA系统做出贡献。虽然一般的关系检测方法在NLP社区中得到了很好的研究,但这些研究通常没有考虑到KBQA的最终任务。因此,一般关系检测研究与kb特异性关系检测存在显著差异。首先,在大多数一般的关系检测任务中,目标关系的数量是有限的,通常小于100。相反,在KBQA中,即使是很小的KB,比如Freebase2M (Bor- des et al., 2015),也包含了6000多个关系类型。其次,KBQA的关系检测常常成为零起点的学习任务,因为一些测试实例可能在训练数据中存在不可见的关系。例如,简单问题(Bordes et al., 2015)数据集拥有黄金训练元组中未观察到的14%的黄金测试关系。第三,如图1(b)所示,对于一些KBQA任务,如WebQuestions (Berant et al., 2013),我们需要预测一个关系链,而不是单个关系。这增加了tar- get关系类型的数量和候选关系池的大小,进一步增加了检测KB关系的难度。由于这些原因,与一般的关系检测任务相比,KB关系检测任务具有更大的挑战性。
针对上述问题,本文对知识库关系检测进行了改进。首先,为了处理不可见的关系,我们提出将关系名分解成词序列进行问题-关系匹配。其次,注意到原始关系名有时有助于匹配较长的问题上下文,我们建议同时构建关系级和单词级关系表示。第三,我们使用深度双向概念LSTMs (BiLSTMs)来学习不同层次的问题表示,以匹配不同层次的关系信息。最后,我们提出了一种序列匹配的残差学习方法,使得模型训练更简单,问题表示更抽象(更深入),从而改进了层次匹配。
为了评估改进后的关系检测对KBQA终端任务的效果,我们还提出了一个简单的KBQA实现,该实现由两步关系检测组成。给定一个输入问题,检索一组候选实体的实体链接器问题的基础上,我们提出了关系检测模型KBQA过程中扮演着重要角色:(1)根据评估实体的候选人是否完全nect高自信关系检测到从原始问题文本检测的关系模型。这一步对于处理实体链接结果中通常出现的歧义非常重要。(2)重新排序后,从一个小得多的候选实体集合中找到每个主题entity2选择的核心关系(链)。当问题不能由单个关系(例如,问题中的多个实体)回答时,上述步骤之后是一个可选的约束检测步骤。最后,上面步骤中得分最高的查询用于查询知识库以获得答案。
当问题不能由单个关系(例如,问题中的多个实体)回答时,上述步骤之后是一个可选的约束检测步骤。最后,上面步骤中得分最高的查询用于查询知识库以获得答案。
我们的主要贡献包括:
(1)通过问题与残差学习关系的层次匹配,提出了一种改进的关联检测模型;
(2)我们证明,改进后的关系检测器可使我们简单的KBQA系统在处理单关系和多关系的KBQA任务时达到最新的效果。
2 相关工作
关系抽取是信息抽取的一个重要子领域。这一领域的一般研究通常针对一个(小的)预定义关系集,给定一个文本段落和两个目标实体,目标是确定文本是否表示实体之间的任何类型的关系。因此,RE通常被表述为一个分类任务。传统的再制造方法依赖于大量的手工特征(Zhou et al., 2005;Rink and Harabagiu, 2010;Sun等人,2011)。最近的研究从深度学习的进步中获益良多:从词嵌入(Nguyen和Grishman, 2014;向CNNs、LSTMs等深度网络(Zeng et al., 2014;dos Santos等人,2015;(Vu等,2016)和atten- tion模型(Zhou等,2016;Wang et al., 2016)。
上述研究假设存在一组固定(封闭)的关系类型,因此不需要零距离学习能力。关系的数量通常不大:广泛使用的ACE2005具有11/32粗/细粒度关系;SemEval2010 Task8有19个关系;tack - kbp2015有74个关系,尽管它考虑了开放域Wikipedia的关系。所有这些都比KBQA的数千个关系少得多。因此,这一领域的工作很少关注处理大量的关系或不可见的关系。Yu等(2016)提出在低秩张量方法中使用关系嵌入。但是它们的关系嵌入仍然是在监督的方式下进行训练,并且在实验中关系的数量并不多。
KBQA系统中的关系检测KBQA的关系检测也从功能丰富的方法开始(Yao和Van Durme, 2014;Bast和Haussmann, 2015)对深层网络用法的研究(Yih et al., 2015;许等,2016;Dai等,2016)和注意力模型(Yin等,2016;Golub and He, 2016)。许多上述的关系检测研究可以很自然地支持大的关系词汇表和开放的关系集(尤其是像ParaLex这样的使用OpenIE KB的QA (Fader等,2013)),以满足开放域问题回答的目标。
不同的KBQA数据集对上述开放域容量有不同的要求。例如,大部分网络问题中的黄金测试关系可以在训练中观察到,因此之前的一些工作也采用了与一般RE研究类似的闭域假设。而对于简单问题和ParaLex这样的数据集,支持大型关系集和不可见关系的能力变得更加必要。最后,有两个主要的解决方案:(1)使用预先训练好的关系嵌入(如来自TransE (Bordes et al., 2013)),如(Dai et al., 2016);(2)将关系名分解为序列,将关系检测表示为序列匹配和排序任务。这种因式分解之所以有效,是因为关系名称通常包含有意义的单词序列。例如Yin等人(2016)将关系拆分为单词序列进行单关系检测。Liang等人(2016)也在端到端神经编程模型中使用字级关系表示的WebQSP上取得了良好的性能。Yih等人(2015)使用char- acter三元组作为问题和关系方面的输入。Golub和He(2016)提出了单关系KBQA的生成框架,该框架使用字符级序列到序列模型预测关系。
KBQA和general RE中的关系检测的另一个区别是general RE研究假设两个参数实体都是可用的。因此,它通常受益于功能(Nguyen和Grishman, 2014;基于实体信息(如实体类型或实体嵌入)的注意机制(Wang et al., 2016)。对于KBQA中的关系检测,这种信息通常是缺失的,因为:(1)一个问题通常包含一个参数(主题实体),(2)一个KB实体可以有多个类型(类型词汇表大小大于1500)。这使得KB实体类型本身成为一个难题,因此以前没有在关系检测模型中使用实体信息。
3 背景:KB关系的不同粒度
(Yih et al., 2015;Yin等人(2016)将KB关系检测定义为一个序列匹配问题。然而,尽管这些问题是自然单词序列,如何将关系表示为序列仍然是一个具有挑战性的问题。在这里,我们概述了在以前的工作中常用的两种类型的关系序列表示。
(1)关联名作为单个标记(关联级)。在这种情况下,每个关系名都被视为唯一的标记。该方法的问题是由于训练数据量有限,关系覆盖率低,不能很好地推广到大量的开放域关系。例如,在图1中,当治疗关系名称作为单一的令牌,它将很难匹配问题关系名称“episodes written”和“starring roles”,如果这些名字没有出现在训练数据——他们的关系嵌入小时将随机向量从而不可比性问题嵌入的hqs。
**(2)单词序列关系(单词级)。**在本例中,关系被视为来自标记关系名称的单词序列。该方法具有较好的泛化能力,但由于原始关系名缺乏全局信息而存在缺陷。例如,在图1(b)中,当只进行单词级匹配时,与不正确的“产生的”关系相比,很难将目标关系“主演角色”排在更高的位置。这是因为错误的关系中包含了单词“play”,它更类似于嵌入空间中的问题(包含单词“play”)。另一方面,如果训练中目标关系与“tv appearance”相关问题同时出现,将整个关系作为token(即关系id),我们可以更好的了解这个token与“tv show”、“play On”等短语之间的对应关系。
这两种关系表示包含不同的抽象层次。如表1所示,词级更关注局部信息(单词和短语),关系级更关注全局信息(长短语和跳跃图),但数据稀疏。由于这两种粒度级别都有各自的优缺点,因此我们提出了一种用于KB关系检测的层次匹配方法:对于候选关系,我们的方法将输入问题与单词级和关系级表示匹配,以获得最终的排名分数。第4节给出了我们建议的方法的细节。
4 改进的KB关系检测
本节描述了我们的层次序列匹配与残差学习方法的关系检测。为了将问题匹配到关系的不同方面(具有不同的抽象级别),我们处理了以下三个关于学习问题/关系表示的问题。
4.1不同粒度的关系表示
我们为模型提供了两种类型的关系表示:单词级和关系级。因此,输入关系成为r=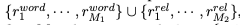 ,第一个M1标记语言(例如{集,写}),例如,{集写}或{主演的角色,系列}(当目标链像图1 (b))。我们变换每个令牌上面的字嵌入然后使用两个BiLSTMs(使用共享参数)让他们隐藏表示
,第一个M1标记语言(例如{集,写}),例如,{集写}或{主演的角色,系列}(当目标链像图1 (b))。我们变换每个令牌上面的字嵌入然后使用两个BiLSTMs(使用共享参数)让他们隐藏表示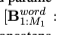
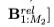 (每个行向量之间的连接是βi向前/向后表示我)。我们初始化序列LSTMs的关系最终状态表示词的序列,为退下看不见的关系。我们在这两组向量r上应用一个最大池,得到最终的关系表示。
(每个行向量之间的连接是βi向前/向后表示我)。我们初始化序列LSTMs的关系最终状态表示词的序列,为退下看不见的关系。我们在这两组向量r上应用一个最大池,得到最终的关系表示。
4.2问题表示的不同抽象
从表1可以看出,关系的不同部分可以匹配不同的问题文本上下文。通常,关系名可以匹配问题中的长短语,关系词可以匹配短短语。然而,不同的单词可能匹配不同长度的短语。
因此,我们希望问题表征也可以包含汇总各种短语信息长度(不同的抽象级别)的向量,以便匹配不同粒度的关系表示。我们通过在问题上应用深度的Bi-LSTMs来处理这个问题。BiLSTM作品的第一层疑问词的词嵌入q = {q1,···, qN}和被隐藏的表示公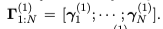 示。第二层Bi-LSTMΓ工作(1)第二组Γ1隐藏表示:N。自从第二次Bi-LSTM从第一层的隐藏向量开始,直观地比第一层学习更一般、更抽象的信息。
示。第二层Bi-LSTMΓ工作(1)第二组Γ1隐藏表示:N。自从第二次Bi-LSTM从第一层的隐藏向量开始,直观地比第一层学习更一般、更抽象的信息。
请注意,问题表示的第一层(第二层)并不一定对应于词(关系)级关系表示,相反,问题表示的任何一层都可能与关系表示的任何一层匹配。这就增加了在不同层次的关系/问题表示之间进行匹配的难度;下面的部分给出了我们处理这个问题的建议。
4.3关系与问题的层次匹配
现在我们有问题上下文的不同长度编码在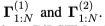 。与使用深层BiLSTMs的标准用法(在最后一层中使用表示法进行预测)不同,这里我们期望两层问题表示法可以互相补充,并且都应该与关系表示法空间(层次匹配)进行比较。这对我们的任务很重要,因为每个关系标记可以对应不同长度的短语,这主要是由于语法变化。例如,在表1中,可以将关系词written与问题中的相同单个单词或更长的短语be author of匹配。
。与使用深层BiLSTMs的标准用法(在最后一层中使用表示法进行预测)不同,这里我们期望两层问题表示法可以互相补充,并且都应该与关系表示法空间(层次匹配)进行比较。这对我们的任务很重要,因为每个关系标记可以对应不同长度的短语,这主要是由于语法变化。例如,在表1中,可以将关系词written与问题中的相同单个单词或更长的短语be author of匹配。
我们可以执行上述分级匹配通过计算每一层之间的相似性分别Γ和人力资源和做之间的(加权)和两个分数。然而,这并没有带来明显的改善(见表2)。我们在第6.2节的分析表明,这种幼稚的方法存在训练困难的问题,证据是该模型的收敛训练损失远高于单层基线模型。这主要是因为(1)深层BiLSTMs并不保证两层问题隐藏表象具有可比性,训练通常落在局部最优,其中一层具有良好的匹配分数,另一层的权值总是接近于0。(2)















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









