







 知识图谱学习笔记前言知识库概念知识库问答(knowledge base question answering,KB-QA)知识库问答的主流方法语义解析(Semantic Parsing)什么是逻辑形式:语义解析KB-QA的方法框架:信息抽取(Information Extraction)如何回答问题如何确定候选答案如何对问题进行信息抽取如何构建特征向量对候选答案进行分类如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一
知识图谱学习笔记前言知识库概念知识库问答(knowledge base question answering,KB-QA)知识库问答的主流方法语义解析(Semantic Parsing)什么是逻辑形式:语义解析KB-QA的方法框架:信息抽取(Information Extraction)如何回答问题如何确定候选答案如何对问题进行信息抽取如何构建特征向量对候选答案进行分类如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一
知识图谱学习笔记
知识库概念
1.三元组(triple):实体entity,实体关系relation,实体entity
有时候会把一些实体称为topic。实体关系也可分为两种,一种是属性property,一种是关系relation。

图中蓝色方块表示topic,橙色椭圆包括属性值,蓝色直线表示关系,橙色直线表示属性,它们都统称为知识库的实体关系
2.知识库涉及到的两大关键技术是
实体链指(Entity linking) ,即将文档中的实体名字链接到知识库中特定的实体上。它主要涉及自然语言处理领域的两个经典问题实体识别 (Entity Recognition) 与实体消歧 (Entity Disambiguation),简单地来说,就是要从文档中识别出人名、地名、机构名、电影等命名实体。并且,在不同环境下同一实体名称可能存在歧义,如苹果,我们需要根据上下文环境进行消歧。
关系抽取 (Relation extraction),即将文档中的实体关系抽取出来,主要涉及到的技术有词性标注 (Part-of-Speech tagging, POS),语法分析,依存关系树 (dependency tree) 以及构建SVM、最大熵模型等分类器进行关系分类等
知识库问答(knowledge base question answering,KB-QA)
知识库问答的主流方法
语义解析(Semantic Parsing): 将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式。
 红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
信息抽取(Information Extraction): 抽取问题中的实体,在只知识库中查询以该实体为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案
向量建模(Vector Modeling):根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示:

语义解析(Semantic Parsing)
参考论文:Berant J, Chou A, Frostig R, et al. “Semantic Parsing on Freebase from Question-Answer Pairs”
语义解析KB-QA的思路是通过对自然语言进行语义上的分析,转化成为一种能够让知识库“看懂”的语义表示,进而通过知识库中的知识,进行推理(Inference)查询(Query),得出最终的答案。简而言之,语义解析要做的事情,就是将自然语言的问题,转化为一种能够让知识库“看懂”的语义表示,这种语义表示即逻辑形式(Logic Form)
什么是逻辑形式:
为了能够对知识库进行查询,我们需要一种能够“访问”知识库的逻辑语言,Lambda Dependency-Based Compositional Semantics ( Lambda-DCS)是一种经典的逻辑语言,它用于处理逻辑形式。如果我们把知识库看作是一个数据库,那么逻辑形式(Logic Form)则可以看作是查询语句的表示。
我们用z表示一个逻辑形式,用k表示知识库,e表示实体,p表示实体关系.
逻辑形式分为一元形式(unary)和二元形式(binary)。对于一个一元实体e,我们可以查询出对应知识库中的实体,给定一个二元实体关系p,可以查到它在知识库中所有与该实体关系[公式]相关的三元组中的实体对。并且,我们可以像数据库语言一样,进行连接Join,求交集Intersection和聚合Aggregate(如计数,求最大值等等)操作.

有了上面的定义,我们就可以把一个自然语言问题表示为一个可以在知识库中进行查询的逻辑形式,比如对于问句
“Number of dramas starring Tom Cruise?”
它对应的逻辑形式是
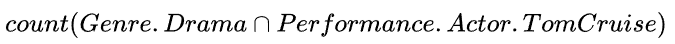
当自然语言问题转化为逻辑形式之后,通过相应的逻辑语言(转化为SPARQL query)查询知识库就可以得到答案。那么,语义解析要如何把自然语言问题正确地转化为相应的逻辑形式呢?
语义解析KB-QA的方法框架:
语法解析的过程可以看作是自底向上构造语法树的过程,树的根节点,就是该自然语言问题最终的逻辑形式表达。整个流程可以分为两个步骤:
- 词汇映射:即构造底层的语法树节点。将单个自然语言短语或单词映射到知识库实体或知识库实体关系所对应的逻辑形式。我们可以通过构造一个词汇表(Lexicon)来完成这样的映射。
- 构建(Composition):即自底向上对树的节点进行两两合并,最后生成根节点,完成语法树的构建
上图红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为词汇映射(Lexicon) 和 构建(Composition) 使用的操作,最终形成的语义解析树的根节点即语义解析结果。
信息抽取(Information Extraction)
参考论文:Xuchen Yao 1and Benjamin Van Durme 1,2Information “ Extraction over Structured Data:Question Answering with Freebase”
该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案。通过观察问题,依据某些规则或模板进行信息抽取,得到表征问题和候选答案特征的特征向量,建立分类器,通过输入特征向量对候选答案进行筛选,从而得出最终答案。
如何回答问题
如果有人问你 “what is the name of Justin Bieber brother?" ,并且给你一个知识库,你会怎么去找答案?显然,这个问题的主题(Topic)词就是Justin Bieber,因此我们会去知识库搜索Justin Bieber这个实体,寻找与该实体相关的知识(此时相当于我们确定了答案的范围,得到了一些候选答案)。接下来,我们去寻找和实体关系brother相关的实体,最后得到答案。下面介绍一种经典的方法Freebase
如何确定候选答案
根据我们人的思维,当我们确定了问句中的主题词,我们就可以去知识库里搜索相应的知识,确定出候选答案。如果我们把知识库中的实体看作是图节点,把实体关系看作是边,那么知识库就是一个庞大的图,通过问句中的主题词可以找到它在知识库中对应的图节点,我们将该图节点相邻几跳(hop)范围内的节点和边抽取出来得到一个知识库的子图,这个子图作者称为主题图(Topic graph),一般来说,这里的跳数一般为一跳或两跳,即与主题词对应的图节点在一条或两条边之内的距离。主题图中的节点,即是候选答案。接下来,我们需要观察问题,对问题进行信息抽取,获取能帮助我们在候选答案中筛选出正确答案的信息。
如何对问题进行信息抽取
还是这个例子,让我们先放慢脚步,想想我们人类是怎么对这个问题进行信息抽取和推理的。首先,我们会潜意识地对这个句子结构进行分析,下图是 “what is the name of Justin Bieber brother?" 这个问句的语法依存树(Dependency tree),语法依存树可以理解为句子成分的形式化描述方式。

这里nsubj代表名词性主语,prep_of代表of介词修饰,nn代表名词组合。
我们首先通过依存关系nsubj(what, name) 和 prep_of(name, brother) 这两条信息知道答案是一个名字,而且这个名字和brother有关,当然我们此时还不能判断是否是人名。进一步,通过nn(brother, justin bieber)这条信息我们可以根据justin bieber是个人,推导出他的brother也是个人,综合前面的信息,我们最终推理出来我们的答案应该是个人名。当确定了最终答案是一个人名,那么我们就很容易在备选答案中筛选出正确答案了。这种步骤实际上就是在对问题进行信息抽取。
- 首先我们要提取的第一个信息就是问题词(question word,记作qword), 例如 who, when, what, where, how, which, why, whom, whose,它是问题的一个明显特征 。
- 第二个关键的信息,就是问题焦点(question fucus, 记作qfocus),这个词暗示了答案的类型,比如name/time/place,我们直接将问题词qword相关的那个名词抽取出来作为qfocus,在这个例子中,what name中的name就是qfocus。
- 第三个我们需要的信息,就是这个问题的主题词(word topic,记作qtopic),在这个句子里Justin Bieber就是qtopic,这个词能够帮助我们找到freebase中相关的知识,我们可以通过命名实体识别(Named Entity Recognition,NER)来确定主题词,需要注意的是,一个问题中可能存在多个主题词
- 第四个我们需要提取的特征,就是问题的中心动词(question verb ,记作qverb),动词能够给我们提供很多和答案相关的信息,比如play,那么答案有可能是某种球类或者乐器。我们可以通过词性标注(Part-of-Speech,POS)确定qverb。
通过对问题提取问题词qword,问题焦点qfocus,问题主题词qtopic和问题中心动词qverb这四个问题特征,我们可以将该问题的依存树转化为问题图(Question Graph),如下图所示。

具体来说,将依存树转化为问题图进行了三个操作
- 将问题词qword,问题焦点qfocus,问题主题词qtopic和问题中心动词qverb加入相对应的节点中,如what -> qword=what。
- 如果该节点是命名实体,那就把该节点变为命名实体形式,如justin -> qtopic=person (justin对应的命名实体形式是person)。这一步的目的是因为数据中涉及到的命名实体名字太多了,这里我们只需要区分它是人名 地名 还是其他类型的名字即可。
- 删除掉一些不重要的叶子节点,如限定词(determiner,如a/the/some/this/each等),介词(preposition)和标点符号(punctuation)
从依存树到问题图的转换,实质是就是对问题进行信息抽取,提取出有利于寻找答案的问题特征,删减掉不重要的信息。
如何构建特征向量对候选答案进行分类
在候选答案中找出正确答案,实际上是一个二分类问题(判断每个候选答案是否是正确答案),我们使用训练数据问题-答案对,训练一个分类器来找到正确答案。那么分类器的输入特征向量怎么构造和定义呢?
特征向量中的每一维,对应一个问题-候选答案特征。每一个问题-候选答案特征由问题特征中的一个特征,和候选答案特征的一个特征,组合(combine)而成。
问题特征:我们从问题图中的每一条边e(s,t),抽取4种问题特征:s,t,s|t,和s|e|t。如对于边prep_of(qfocus=name,brother),我们可以抽取这样四个特征:qfocus=name,brother,qfocus=name|brother 和 qfocus=name|prep_of|brother。
候选答案特征:对于主题图中的每一个节点,我们都可以抽取出以下特征:该节点的所有关系(relation,记作rel),和该节点的所有属性(property,如type/gender/age)

(图中没有剪头的虚线表示属性,有箭头的实线表示关系,虚线框即属性值,实线框为topic node。在知识库中,如果同一个topic节点的同一个关系对应了多个实体,如Justin Bieber的preon.sibing_s关系可能对应多个实体,那么freebase中会设置一个虚拟的dummy node,来连接所有相关的实体)
例如,对于Jaxon Bieber这个topic节点,我们可以提取出这些特征:gender=male,type=person,rel=sibling 。可以看出关系和属性都刻画了这个候选答案的特征,对判断它是否是正确答案有很大的帮助。
问题-候选答案特征:
每一个问题-候选答案特征由问题特征中的一个特征和候选答案特征中的一个特征,组合(combine)而成(组合记作 | )。我们希望一个关联度较高的问题-候选答案特征有较高的权重,比如对于问题-候选答案特征 qfocus=money|node type=currency(注意,这里qfocus=money是来自问题的特征,而node type=currency则是来自候选答案的特征),我们希望它的权重较高,而对于问题-候选答案特征qfocus=money|node type=person我们希望它的权重较低。
接下来我们用WebQuestion作为训练数据,使用Stanford CoreNLP(JAVA语言)帮助我们对问题进行信息抽取。训练集中约有3000个问题,每个问题对应的主题图约含1000个节点,共计有3 million的节点和7 million种问题-候选答案特征,作者用带L1正则化的逻辑回归(logistic regression)作为分类器,训练每种问题-候选答案特征的权值(L1正则化的逻辑回归很适合处理这种稀疏的特征向量,作者表示其效果好于感知机Percptron和支持向量机SVM)。 训练完毕后,得到了3万个非零的特征,下表列出了部分特征和它相应的权值,可以看出问题特征和候选答案特征相关度较高时,其权值较高。

因此,在使用的时候,对于每一个候选答案,我们抽取出它的特征(假设有k个特征)后,再和问题中的每一个特征两两结合(假设有m个特征),那么我们就得到了km个问题-候选答案特征,因此我们的输入向量就是一个km-hot(即k*m维为1,其余维为0)的3万维向量。
在提取候选答案的特征时,我们对每个实体提取了它的关系和属性,此外还可以计算候选答案和问题的相关性作为特征。对于由词向量w组成的问题Q,我们想要找出最可能回答问题的关系R,即最大化概率 P ( R ∣ Q ) P(R \mid Q) P(R∣Q)。比如who is the father of King George
VI 最有可能的关系是people.person.parents,但对于问题who is
the father of the Periodic Table,最有可能的关系变为law.invention.inventor。 这就说明问题的每一个词w都有可能影响对提问产生影响。所以有 P ( Q ) = ∏ i = 1 ∣ Q ∣ P ( w i ) P(Q)=\prod_{i=1}^{|Q|} P\left(w_{i}\right) P(Q)=∏i=1∣Q∣P(wi)
由朴素贝叶斯,backoff model,的思想和假设,对于 R = r 1 ⋅ r 2 ⋅ r 3 … R=r_{1} \cdot r_{2} \cdot r_{3} \ldots R=r1⋅r2⋅r3…这种复合关系,如people.person.parents也采用backoff的思想, P ( R ) = ∏ P ( r ) P(R)=\prod P(r) P(R)=∏P(r)这个概率进行近似。即
P ~ backoff ( R ∣ Q ) ≈ P ~ ( r ∣ Q ) ≈ ∏ r P ~ ( r ∣ Q ) ∝ ∏ r P ~ ( Q ∣ r ) P ~ ( r ) ≈ ∏ r ∏ w P ~ ( w ∣ r ) P ~ ( r ) \begin{aligned} \tilde{P}_{\text {backoff }}(R \mid Q) & \approx \tilde{P}(\mathbf{r} \mid Q) \\ & \approx \prod_{r} \tilde{P}(r \mid Q) \\ & \propto \prod_{r} \tilde{P}(Q \mid r) \tilde{P}(r) \\ & \approx \prod_{r} \prod_{w} \tilde{P}(w \mid r) \tilde{P}(r) \end{aligned} P~backoff (R∣Q)≈P~(r∣Q)≈r∏P~(r∣Q)∝r∏P~(Q∣r)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1822
1822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









