







 本文详细介绍了OpenAI模型中token的概念、计数规则,探讨了tiktoken工具在计数中的作用,以及不同编码方式对文本处理的影响。同时,提供了如何使用Python计算和处理token的实例,以及在调用GPT模型时的token考虑因素。
本文详细介绍了OpenAI模型中token的概念、计数规则,探讨了tiktoken工具在计数中的作用,以及不同编码方式对文本处理的影响。同时,提供了如何使用Python计算和处理token的实例,以及在调用GPT模型时的token考虑因素。
- 👉👉👉承接各类AI相关应用开发项目(包括但不限于大模型微调、RAG、AI智能体、NLP、机器学习算法、运筹优化算法、数据分析EDA等) !!!
- 👉👉👉 有意愿请私信!!!
一、关于token
1.1 什么是token
token可以被认为是单词(词语)的片段, 在用户对大语言模型提出问题的时候,我们的输入(prompt)会被分解成一组token, 在英语的句子中单词之家存在空格,一些常见的单词可能会被切割成独立的token, 但并非所有的单词都会被切割成独立的token, 有时候一个单词可能会被切割成多个token, token可以包含尾随在单词后面空格甚至子单词。以下是一些帮助理解token长度的经验规则:
- 1 个token ~= 4 个英文字符
- 1 个token ~= 3/4 个单词
- 100 个token ~= 75 个单词
或者
- 1-2 个句子 ~= 30 tokens
- 1个段落 ~= 100 tokens
- 1500个单词 ~= 2048 tokens
因此可以这么认为一个句子,或者一篇文章它们的token总数往往会大于句子或者文章的单词总数。
1.2 token的计数规则
Token的计数方式与所使用的语言有关。例如,西班牙语中的“Cómo estás”(意为"How are you") 包含5个Token(共10个字符)。对于非英语语言,更高的Token与字符比率可能会使得使用API的成本更高。下面我们看一个例子:

在上面这个例子中句子:"My favorite color is red." 被用不同颜色分割,不同单词所在的色块中有的单词前面包含了空格如" red",有的单词前后都不包含空格如"My",句子末尾的句点被单独分配了一个色块。那么整个句子可以被认为是被切割成了6个token,每个token的id由上图中的list表示如:[3666,4004,3124,318,2266,13]。再看下面的例子:

在上面这个例子中我们发现句子中的单词" red" 由原来小写变成了大写的“ Red”, 因此它的tokenId也发生了变化(由原来的2266变成了2297), 这说明单词的大小写也会产生不通的token。再看下面的例子:
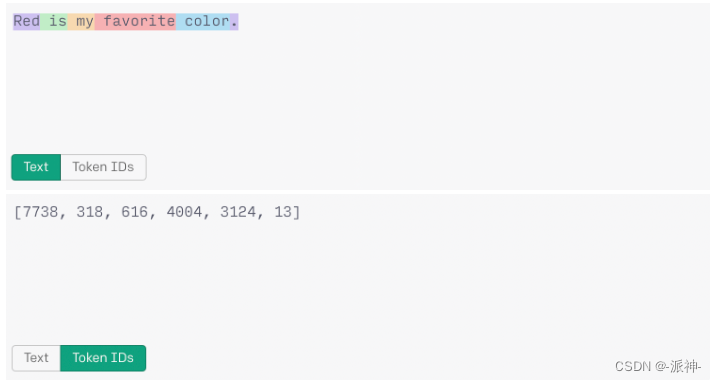
在上面的例子中单词"Red" 前后都没有包含空格它的tokenId是7738,这与之前包含前导空格的" Red"的tokenId(2297)是不同的。
token出现的可能性/频率越高,分配给它的token编号就越低:
- 在所有 3 个句子中,相同的tokenId只有一个("13")即句号的tokenId。 这是因为,从上下文来看,整个语料库数据中使用的句号方式非常相似。
- 为“red”生成的token根据其在句子中的位置而变化:
句子中间小写的"red"(tokenId:“2266”)
句子中间大写的"Red" (tokenId:“2297”)
句子开头大写的"Red"(tokenId:“7738”)
1.4 token的限制
根据所使用的模型,调用OpenAI的模型可以使用最多128000个Token,包括模型在输入(prompt)和输出(completion)之间的共享。某些模型,如GPT-4 Turbo,对输入和输出Token有不同的限制。
二、token计数
tiktoken 是 OpenAI 推出的快速开源token计数器工具。比如给定一个文本字符串(例如,“tiktoken is great!”)和编码(encoding 比如,“cl100k_base”),分词器可以将文本字符串拆分为token列表(例如, ["t", "ik", "token", " is", " great", "!"])。将文本字符串拆分为token非常有用,因为 GPT 模型以token的形式理解文本。 了解文本字符串中有多少个token可以告诉您 (1) 该字符串是否太长而无法让文本模型处理,以及 (2) OpenAI API 调用的成本是多少(因为使用量是按token使用数量来定价的)。
编码(Encodings)
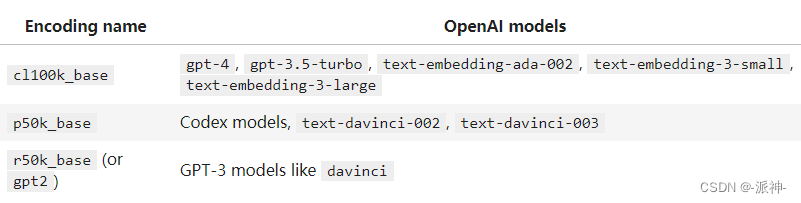
编码(Encodings)的作用是将文本转换为token的技术。 不同的模型使用不同的编码。tiktoken 支持 OpenAI 模型使用的三种编码:
您可以使用 tiktoken.encoding_for_model() 检索模型的编码,如下所示:
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
请注意,p50k_base 与 r50k_base 基本重叠,对于非代码应用程序,它们通常会给出相同的token。
如何将字符串转换成token
在英语中,token的长度通常从一个字符到一个单词不等(例如,“t”或“great”),尽管在某些语言中,token的长度可以短于一个字符或长于一个单词。通常空格会被保留在一个单词的开头,比如: " is"(空格在单词开头),一般不会是"is "(空格在单词尾部) 或者" " + "is"(拆分成两个token,空格和"is")。您可以在OpenAI Tokenizer或第三方Tiktokenizer web应用程序中快速检查字符串是如何被转换成token的:
1.安装 tiktoken
pip install --upgrade tiktoken
pip install --upgrade openai2.加载encoding
使用tiktoken.get_encoding()按名称加载编码。第一次运行时,它将需要互联网连接进行下载。后续运行不需要互联网连接。
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
#使用tiktoken.encoding_for_model()函数可以自动加载给定模型名称的正确编码。
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
3.将文本转为token
使用. encode()方法将文本字符串转换为token整数列表。
encoding.encode("tiktoken is great!")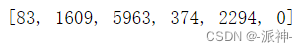
通过计算.encode()返回的列表的长度来统计token数量。
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""返回文本字符串中的Token数量"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
4. 将token转换为文本
使用.decode()将一个token整数列表转换为字符串。
encoding.decode([83, 1609, 5963, 374, 2294, 0])![]()
注意:虽然.decode()可以应用于单个token,但是,对于不在utf-8边界上的token,它可能是有损的。对于单个token使用 .decode_single_token_bytes()方法可以安全地将单个整数token转换为它所表示的字节。
[encoding.decode_single_token_bytes(token) for token in [83, 1609, 5963, 374, 2294, 0]]![]()
(在字符串前面的b表示这些字符串是字节字符串。)
5. 编码比较
不同的编码方式在分割单词、处理空格和非英文字符方面存在差异。通过上述方法,我们可以比较几个示例字符串在不同的编码方式下的表现。
def compare_encodings(example_string: str) -> None:
"""Prints a comparison of three string encodings."""
# print the example string
print(f'\nExample string: "{example_string}"')
# for each encoding, print the # of tokens, the token integers, and the token bytes
for encoding_name in ["r50k_base", "p50k_base", "cl100k_base"]:
encoding = tiktoken.get_encoding(encoding_name)
token_integers = encoding.encode(example_string)
num_tokens = len(token_integers)
token_bytes = [encoding.decode_single_token_bytes(token) for token in token_integers]
print()
print(f"{encoding_name}: {num_tokens} tokens")
print(f"token integers: {token_integers}")
print(f"token bytes: {token_bytes}")
compare_encodings("antidisestablishmentarianism")
compare_encodings("2 + 2 = 4") 
compare_encodings("お誕生日おめでとう")
6. 调用openai模型时的token计数
像gpt-3.5-turbo和gpt-4这样的ChatGPT模型使用token的方式与旧的补全模型(completions model)相同,但由于其基于消息的格式,很难准确计算对话中将使用多少个token。
下面是一个示例函数,用于计算传递给gpt-3.5-turbo或gpt-4的消息中的token数量。
请注意,从消息中计算token的确切方式可能因模型而异。请将下面函数中的计数视为估计值,并非一直正确。特别地,在使用可选功能输入(input)的请求上方会消耗额外的token。
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"):
"""Return the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model in {
"gpt-3.5-turbo-0613",
"gpt-3.5-turbo-16k-0613",
"gpt-4-0314",
"gpt-4-32k-0314",
"gpt-4-0613",
"gpt-4-32k-0613",
}:
tokens_per_message = 3
tokens_per_name = 1
elif model == "gpt-3.5-turbo-0301":
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
elif "gpt-3.5-turbo" in model:
print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0613.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613")
elif "gpt-4" in model:
print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.")
return num_tokens_from_messages(messages, model="gpt-4-0613")
else:
raise NotImplementedError(
f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens."""
)
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens# let's verify the function above matches the OpenAI API response
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as env var>"))
example_messages = [
{
"role": "system",
"content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.",
},
{
"role": "system",
"name": "example_user",
"content": "New synergies will help drive top-line growth.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Things working well together will increase revenue.",
},
{
"role": "system",
"name": "example_user",
"content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Let's talk later when we're less busy about how to do better.",
},
{
"role": "user",
"content": "This late pivot means we don't have time to boil the ocean for the client deliverable.",
},
]
for model in [
"gpt-3.5-turbo-0301",
"gpt-3.5-turbo-0613",
"gpt-3.5-turbo",
"gpt-4-0314",
"gpt-4-0613",
"gpt-4",
]:
print(model)
# example token count from the function defined above
print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().")
# example token count from the OpenAI API
response = client.chat.completions.create(model=model,
messages=example_messages,
temperature=0,
max_tokens=1)
print(f'{response.usage.prompt_tokens} prompt tokens counted by the OpenAI API.')
print()


















 5871
5871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











