






鉴于LLM与RL两者间在整体学习范式、学习目标、模型结构的差异化与统一的考量,业内不少的思路尝试将两种思想融合在一起以期待AGI的突破,但结合后要么看着不是很巧妙,要不就是看起来很僵硬,总感觉像是一个过渡性的方法,并且看起来并没有以终为始,也没有太多从底层第一性原理出发点上进行融合,因此想要尝试探寻一下两种学习方法是否能更巧妙的相互结合与统一。
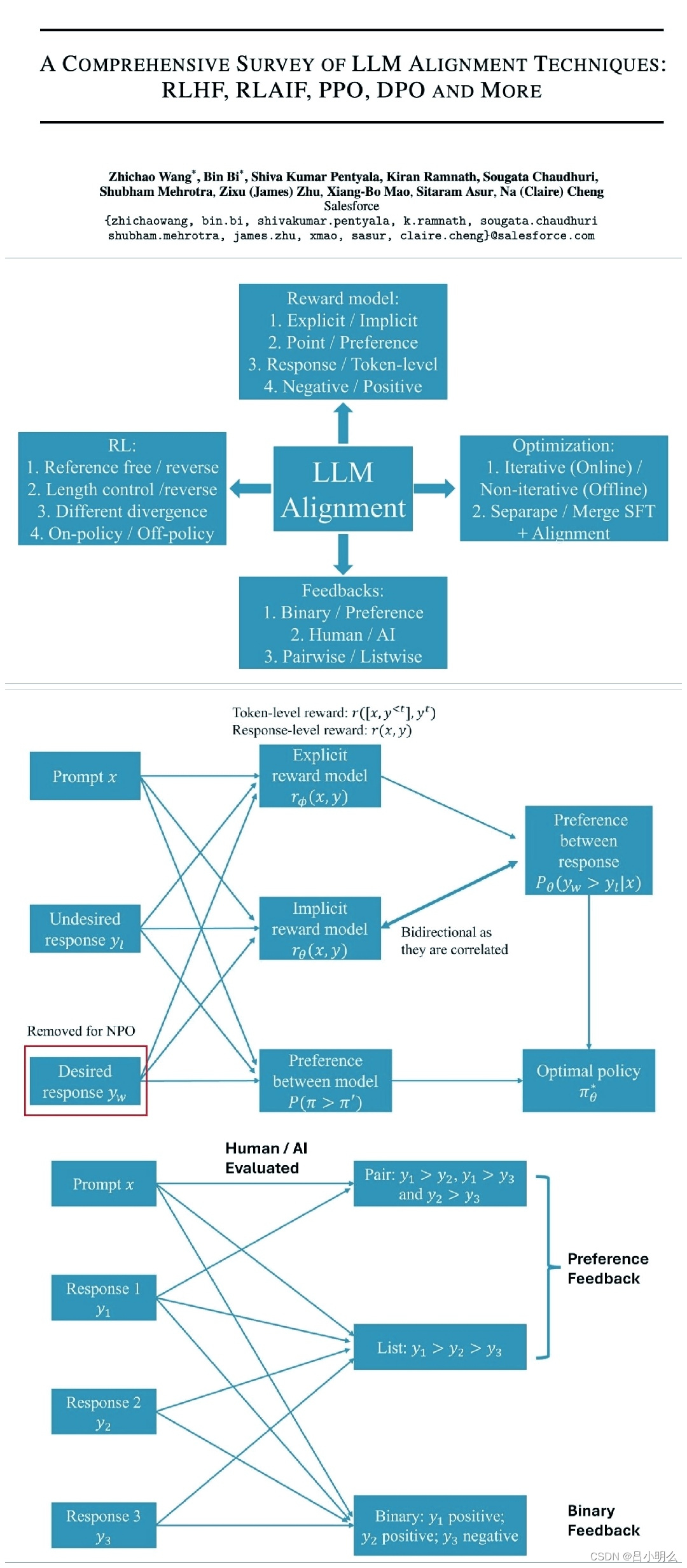
当前业内产业界或学术界均在逐步探索对于LLM采用强化学习思想进行其推理能力的延展,包括「融合RL与LLM思想,探寻世界模型以迈向AGI·上篇」中提到的最初Algorithm Distillation所运用的思想和方法,后续基于各种XoT思想的Agent或Muti-Agent框架,包括一些基于Agent框架思想下的复杂场景化模型优化的尝试,如Google之前推出的AMIE学习框架再到Med-Gemini、前不久的清华大学AI医院小镇,以及近期MIT提出的基于博弈论思想改进提升LLM生成能力准确性与内部一致性的尝试,甚至之前OpenAI神秘的草莓QQ糖项目,各种Q*在探索与利用的尝试...RLIHF、RLAIF、PPO、DPO and more..
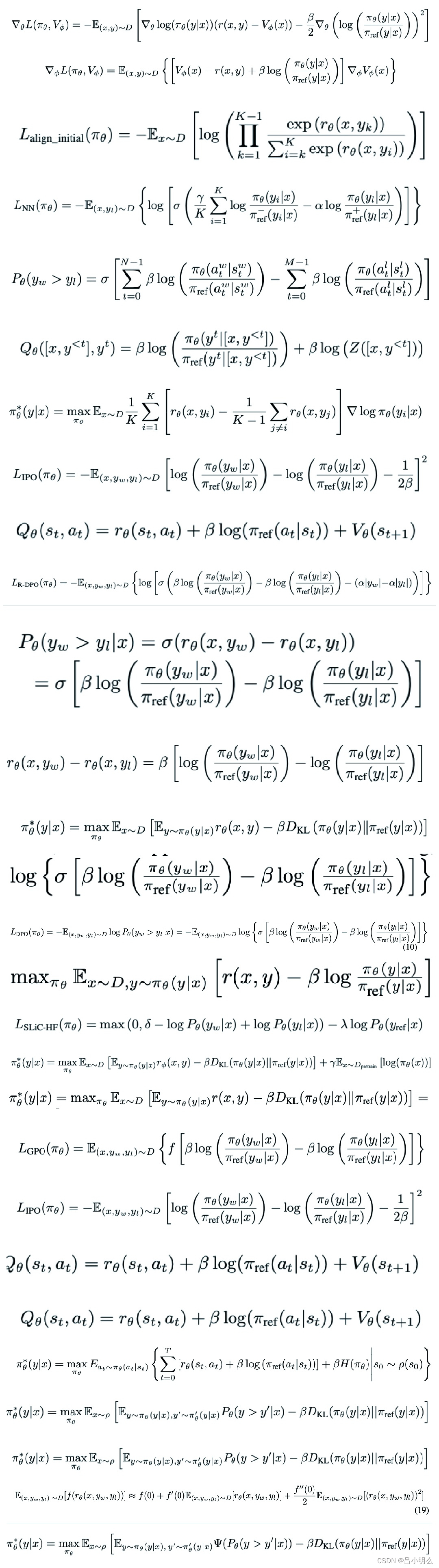
在这里,除了我们不可知的草莓Q糖之外,其它上述思想或方法均是对LLM在某个特定场景的深度推理能力探索的一撇,通过以各种XoT规划形式搭建起的Agent框架,来完成复杂任务的推理过程或用于构建后续模型持续进行过程奖励学习的SFT数据集。然而当前我认为在模型训练机制搭建、推理框架模式、对应的数据生成模拟构造、奖励与反馈机制的完备性上等各项环节在通用性与普适性上并没有形成统一、完备、高效的范式,同时尤其针对后续的模型隐状态的持续强化训练策略并没有相关完备的通用场景验证或技术理论支撑(对比当初ChatGPT论文发布之初相对简单、清晰的Pre-traning→SFT→RLHF模型生产路径)。因此,在「融合RL与LLM思想,探寻世界模型以迈向AGI·中篇」里,针对LLM与RL的融合,对此部分尝试性的进行了一些自己的思考和探索,希望未来能够持续探索并找到能构建出一个全局的认知流形挖掘模式,基于容纳了RL思想的深度探索推理学习范式,以实现LLM将简单粗暴的预训练继续scaling law下去....
感兴趣的大伙可以翻看阅读那篇文章的历史专栏或置顶🔝文章/笔记..















 7429
7429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









